Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Résolution des problèmes liés à Amazon DataZone
Si vous rencontrez des problèmes de refus d'accès ou des difficultés similaires lorsque vous travaillez avec Amazon, DataZone consultez les rubriques de cette section.
Résolution des problèmes liés aux autorisations de AWS Lake Formation pour Amazon DataZone
Cette section contient des instructions de résolution des problèmes que vous pourriez rencontrer lorsque vousConfigurer les autorisations de Lake Formation pour Amazon DataZone.
| Message d'erreur dans le portail de données | Résolution |
|---|---|
|
Impossible d'assumer le rôle d'accès aux données. |
Cette erreur s'affiche lorsqu'Amazon n' DataZone est pas en mesure de supposer AmazonDataZoneGlueDataAccessRoleque vous avez utilisé pour activer le DefaultDataLakeBlueprintdans votre compte. Pour résoudre le problème, accédez à la console AWS IAM du compte sur lequel se trouve votre ressource de données et assurez-vous qu'il existe AmazonDataZoneGlueDataAccessRoleune relation de confiance appropriée avec le responsable du DataZone service Amazon. Pour de plus amples informations, consultez AmazonDataZoneGlueAccess- <region>- <domainId>. |
|
Le rôle d'accès aux données ne dispose pas des autorisations nécessaires pour lire les métadonnées de la ressource à laquelle vous essayez de vous abonner. |
Cette erreur s'affiche lorsqu'Amazon assume le AmazonDataZoneGlueDataAccessRolerôle DataZone avec succès, mais que celui-ci ne dispose pas des autorisations nécessaires. Pour résoudre le problème, accédez à la console AWS IAM du compte auquel se trouve votre ressource de données et assurez-vous que le rôle est AmazonDataZoneGlueManageAccessRolePolicyassocié à ce dernier. Pour de plus amples informations, veuillez consulter AmazonDataZoneGlueAccess- <region>- <domainId>. |
|
L'actif est un lien vers une ressource. Amazon DataZone ne prend pas en charge les abonnements à des liens vers des ressources. |
Cette erreur s'affiche lorsque la ressource que vous essayez de publier sur Amazon DataZone est un lien de ressource vers une table AWS Glue. |
|
L'actif n'est pas géré par AWS Lake Formation. |
Cette erreur indique que les autorisations de AWS Lake Formation ne sont pas appliquées à la ressource que vous souhaitez publier. Cela peut se produire dans les cas suivants.
|
|
Le rôle Data Access ne dispose pas des autorisations Lake Formation nécessaires pour accorder l'accès à cette ressource. |
Cette erreur indique que le AmazonDataZoneGlueDataAccessRolefichier que vous utilisez pour activer le DefaultDataLakeBlueprintdans votre compte ne dispose pas des autorisations nécessaires pour qu'Amazon puisse DataZone gérer les autorisations sur l'actif publié. Vous pouvez résoudre le problème soit en l'ajoutant en AmazonDataZoneGlueDataAccessRoletant qu'administrateur de AWS Lake Formation, soit en accordant les autorisations suivantes AmazonDataZoneGlueDataAccessRoleà la ressource que vous souhaitez publier.
|
Résolution des problèmes liés à la liaison des actifs Amazon DataZone Lineage avec des ensembles de données en amont
Cette section contient des instructions de résolution des problèmes que vous pourriez rencontrer avec Amazon DataZone Lineage. Pour certains événements d'exécution de AWS Glue lignage ouvert liés à Amazon Redshift, vous constaterez peut-être que le lignage des actifs n'est pas lié à un ensemble de données en amont. Cette rubrique explique les scénarios et quelques approches pour atténuer les problèmes. Pour plus d'informations sur le lignage, voirLignage des données sur Amazon DataZone.
SourceIdentifier sur un nœud de lignée
L'sourceIdentifierattribut d'un nœud de lignée représente les événements qui se produisent sur un ensemble de données. Pour plus d'informations, consultez la section Attributs clés dans les nœuds de lignage.
Le nœud de lignage représente tous les événements qui se produisent sur le jeu de données ou le travail correspondant. Le nœud de lignée contient un attribut « SourceIdentifier » qui contient l'identifiant du jeu de données/tâches correspondant. Comme nous prenons en charge les événements de lignage ouvert, la sourceIdentifier valeur est renseignée par défaut sous la forme de la combinaison de « namespace » et de « nom » pour un ensemble de données, une tâche et des exécutions de tâches.
Pour AWS des ressources telles qu' AWS Glue Amazon Redshift, il s'sourceIdentifieragirait de l' AWS Glue ARN de la table et de la table Redshift à partir ARNs desquelles Amazon DataZone créera l'événement d'exécution et les autres informations suivantes :
Note
Dans AWS, l'ARN contient des informations telles que l'AccountID, la région, la base de données et la table pour chaque ressource.
OpenLineage l'événement pour ces ensembles de données contient le nom de la base de données et de la table.
La région est capturée dans la facette « propriétés de l'environnement » d'une course. Si ce n'est pas le cas, le système utilise la région indiquée dans les informations d'identification de l'appelant.
AccountId est extrait des informations d'identification de l'appelant.
SourceIdentifier sur les actifs qu'il contient DataZone
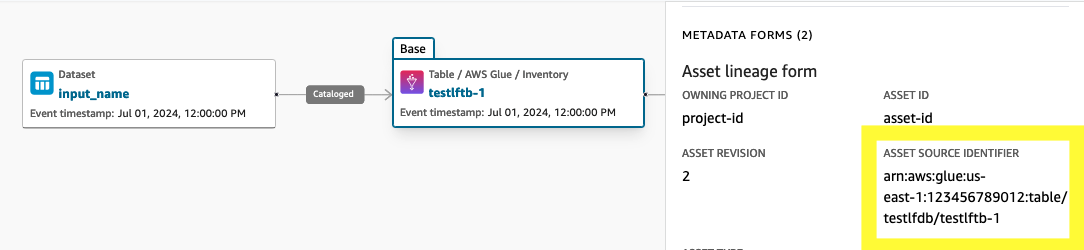
AssetCommonDetailFormpossède un attribut appelé « SourceIdentifier » qui représente l'identifiant de l'ensemble de données représenté par la ressource. Pour que les nœuds de lignage des actifs soient liés à un ensemble de données en amont, l'attribut doit être renseigné avec la valeur correspondant à celle du nœud du jeu de sourceIdentifier données. Si les actifs sont importés par source de données, le flux de travail est automatiquement renseigné sourceIdentifier sous forme de tableau ARN/Redshift ARN, tandis que les autres actifs (y compris les actifs personnalisés) créés via CreateAsset l'API doivent avoir cette valeur renseignée par l'appelant. AWS Glue
Comment Amazon crée-t-il le DataZone SourceIdentifier à partir de l' OpenLineage événement ?
Pour les actifs Redshift AWS Glue et Redshift, ils sourceIdentifier sont conçus à partir de Glue et Redshift. ARNs Voici comment Amazon le DataZone construit :
AWS Glue ARN
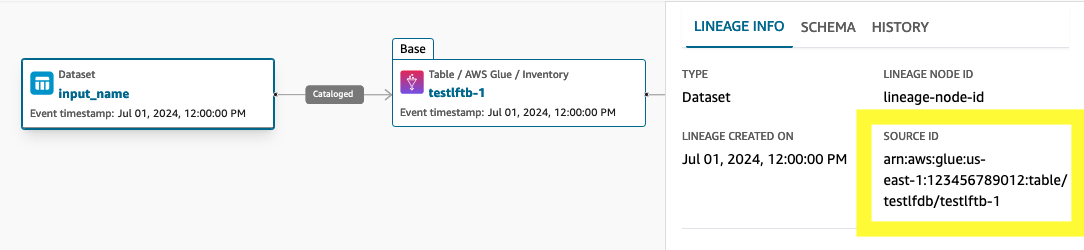
L'objectif est de créer un OpenLineage événement dont le nœud de lignée en sortie sourceIdentifier est :
arn:aws:glue:us-east-1:123456789012:table/testlfdb/testlftb-1
Pour déterminer si une course utilise des données provenant de AWS Glue, recherchez la présence de certains mots clés dans la environment-properties facette. Plus précisément, si l'un de ces champs désignés est présent, le système suppose qu'il RunEvent provient de AWS Glue.
GLUE_VERSION
CRITÈRES_COMMANDE_COLLE
GLUE_PYTHON_VERSION
"run": { "runId":"4e3da9e8-6228-4679-b0a2-fa916119fthr", "facets":{ "environment-properties":{ "_producer":"https://github.com/OpenLineage/OpenLineage/tree/1.9.1/integration/spark", "_schemaURL":"https://openlineage.io/spec/2-0-2/OpenLineage.json#/$defs/RunFacet", "environment-properties":{ "GLUE_VERSION":"3.0", "GLUE_COMMAND_CRITERIA":"glueetl", "GLUE_PYTHON_VERSION":"3" } } }
Pour une AWS Glue exécution, vous pouvez utiliser le nom de la symlinks facette pour obtenir le nom de la base de données et de la table, qui peuvent être utilisés pour créer l'ARN.
Vous devez vous assurer que le nom est databaseName.tableName :
"symlinks": { "_producer":"https://github.com/OpenLineage/OpenLineage/tree/1.9.1/integration/spark", "_schemaURL":"https://openlineage.io/spec/facets/1-0-0/SymlinksDatasetFacet.json#/$defs/SymlinksDatasetFacet", "identifiers":[ { "namespace":"s3://object-path", "name":"testlfdb.testlftb-1", "type":"TABLE" } ] }
Exemple d'événement COMPLET :
{ "eventTime":"2024-07-01T12:00:00.000000Z", "producer":"https://github.com/OpenLineage/OpenLineage/tree/1.9.1/integration/glue", "schemaURL":"https://openlineage.io/spec/2-0-2/OpenLineage.json#/$defs/RunEvent", "eventType":"COMPLETE", "run": { "runId":"4e3da9e8-6228-4679-b0a2-fa916119fthr", "facets":{ "environment-properties":{ "_producer":"https://github.com/OpenLineage/OpenLineage/tree/1.9.1/integration/spark", "_schemaURL":"https://openlineage.io/spec/2-0-2/OpenLineage.json#/$defs/RunFacet", "environment-properties":{ "GLUE_VERSION":"3.0", "GLUE_COMMAND_CRITERIA":"glueetl", "GLUE_PYTHON_VERSION":"3" } } } }, "job":{ "namespace":"namespace", "name":"job_name", "facets":{ "jobType":{ "_producer":"https://github.com/OpenLineage/OpenLineage/tree/1.9.1/integration/glue", "_schemaURL":"https://openlineage.io/spec/facets/2-0-2/JobTypeJobFacet.json#/$defs/JobTypeJobFacet", "processingType":"BATCH", "integration":"glue", "jobType":"JOB" } } }, "inputs":[ { "namespace":"namespace", "name":"input_name" } ], "outputs":[ { "namespace":"namespace.output", "name":"output_name", "facets":{ "symlinks":{ "_producer":"https://github.com/OpenLineage/OpenLineage/tree/1.9.1/integration/spark", "_schemaURL":"https://openlineage.io/spec/facets/1-0-0/SymlinksDatasetFacet.json#/$defs/SymlinksDatasetFacet", "identifiers":[ { "namespace":"s3://object-path", "name":"testlfdb.testlftb-1", "type":"TABLE" } ] } } } ] }
Sur la base de l'OpenLineageévénement soumis, le nœud sourceIdentifier de lignée de sortie sera :
arn:aws:glue:us-east-1:123456789012:table/testlfdb/testlftb-1
Le nœud de lignage en sortie sera connecté au nœud de lignage d'un actif où l'actif est sourceIdentifier :
arn:aws:glue:us-east-1:123456789012:table/testlfdb/testlftb-1
Amazon Redshift (ARN)
L'objectif est de créer un OpenLineage événement dont le nœud de lignée en sortie sourceIdentifier est :
arn:aws:redshift:us-east-1:123456789012:table/workgroup-20240715/tpcds_data/public/dws_tpcds_7
Le système détermine si une entrée ou une sortie est stockée dans Redshift en fonction de l'espace de noms. Plus précisément, si l'espace de noms commence par redshift ://ou contient les chaînes redshift-serverless.amazonaws.com ou redshift.amazonaws.com s'il s'agit d'une ressource Redshift.
"outputs": [ { "namespace":"redshift://workgroup-20240715.123456789012.us-east-1.redshift.amazonaws.com:5439", "name":"tpcds_data.public.dws_tpcds_7" } ]
Notez que l'espace de noms doit être au format suivant :
provider://{cluster_identifier}.{region_name}:{port}
Pour redshift-serverless :
"outputs": [ { "namespace":"redshift://workgroup-20240715.123456789012.us-east-1.redshift-serverless.amazonaws.com:5439", "name":"tpcds_data.public.dws_tpcds_7" } ]
Les résultats sont les suivants sourceIdentifier
arn:aws:redshift-serverless:us-east-1:123456789012:table/workgroup-20240715/tpcds_data/public/dws_tpcds_7
Sur la base de l' OpenLineage événement soumis, le nœud de lignage sourceIdentifier à mapper vers un nœud de lignage en aval (c'est-à-dire une sortie de l'événement) est le suivant :
arn:aws:redshift-serverless:us-e:us-east-1:123456789012:table/workgroup-20240715/tpcds_data/public/dws_tpcds_7
Il s'agit du mappage qui vous permet de visualiser le lignage d'un actif dans le catalogue.
Approche alternative
Lorsqu'aucune des conditions ci-dessus n'est remplie, le système utilise l'espace de noms/name pour construire : sourceIdentifier
"inputs": [ { "namespace":"arn:aws:redshift:us-east-1:123456789012:table", "name":"workgroup-20240715/tpcds_data/public/dws_tpcds_7" } ], "outputs": [ { "namespace":"arn:aws:glue:us-east-1:123456789012:table", "name":"testlfdb/testlftb-1" } ]
Résolution d'un manque d'amont pour le nœud de traçabilité des actifs
Si vous ne voyez pas l'amont du nœud de lignage des actifs, vous pouvez effectuer les opérations suivantes pour déterminer pourquoi il n'est pas lié au jeu de données :
Invoquez
GetAssettout en fournissant ledomainIdetassetId:aws datazone get-asset --domain-identifier <domain-id> --identifier <asset-id>La réponse apparaît comme suit :
{ ..... "formsOutput": [ ..... { "content": "{\"sourceIdentifier\":\"arn:aws:glue:eu-west-1:123456789012:table/testlfdb/testlftb-1\"}", "formName": "AssetCommonDetailsForm", "typeName": "amazon.datazone.AssetCommonDetailsFormType", "typeRevision": "6" }, ..... ], "id": "<asset-id>", .... }Appelez
GetLineageNodepour obtenir le nœudsourceIdentifierde lignée de l'ensemble de données. Comme il n'existe aucun moyen d'obtenir directement le nœud de lignage pour le nœud de jeu de données correspondant, vous pouvez commencerGetLineageNodepar :aws datazone get-lineage-node --domain-identifier <domain-id> --identifier <job_namespace>.<job_name>/<run_id> if you are using the getting started scripts, job name and run ID are printed in the console and namespace is "default". Otherwise you can get these values from run event content.L'exemple de réponse se présente comme suit :
{ ..... "downstreamNodes": [ { "eventTimestamp": "2024-07-24T18:08:55+08:00", "id": "afymge5k4v0euf" } ], "formsOutput": [ <some forms corresponding to run and job> ], "id": "<system generated node-id for run>", "sourceIdentifier": "default.redshift.create/2f41298b-1ee7-3302-a14b-09addffa7580", "typeName": "amazon.datazone.JobRunLineageNodeType", .... "upstreamNodes": [ { "eventTimestamp": "2024-07-24T18:08:55+08:00", "id": "6wf2z27c8hghev" }, { "eventTimestamp": "2024-07-24T18:08:55+08:00", "id": "4tjbcsnre6banb" } ] }Appelez
GetLineageNodeà nouveau en transmettant l'identifiant du downstream/upstream nœud (qui, selon vous, devrait être lié au nœud de ressource) car celui-ci correspond à l'ensemble de données :Exemple de commande utilisant l'exemple de réponse ci-dessus :
aws datazone get-lineage-node --domain-identifier <domain-id> --identifier afymge5k4v0eufCela renvoie les détails du nœud de lignée correspondant à l'ensemble de données : afymge5k4v0euf
{ ..... "domainId": "dzd_cklzc5s2jcr7on", "downstreamNodes": [], "eventTimestamp": "2024-07-24T18:08:55+08:00", "formsOutput": [ ..... ], "id": "afymge5k4v0euf", "sourceIdentifier": "arn:aws:redshift:us-east-1:123456789012:table/workgroup-20240715/tpcds_data/public/dws_tpcds_7", "typeName": "amazon.datazone.DatasetLineageNodeType", "typeRevision": "1", .... "upstreamNodes": [ ... ] }Comparez le nœud
sourceIdentifierde ce jeu de données et la réponse deGetAsset. S'ils ne sont pas liés, ils ne correspondront pas et ne seront donc pas visibles dans l'interface utilisateur du lignage.
Scénarios et mesures d'atténuation non correspondants
Voici les scénarios les plus courants dans lesquels ils ne correspondent pas, ainsi que les mesures d'atténuation possibles :
Cause première : les tables sont présentes dans un compte différent de celui du compte de DataZone domaine Amazon.
Atténuation : vous pouvez invoquer l'PostLineageEventopération depuis un compte associé. Comme l'ARN est sélectionné accountId à partir des informations d'identification de l'appelant, vous pouvez assumer le rôle depuis le compte contenant les tables lorsque vous exécutez le script de démarrage ou que vous l'PostLineageEventinvoquez. Cela aidera à construire ARNs correctement les nœuds d'actifs et à établir des liens avec eux.
Cause première : L'ARN de Redshift table/views contient Redshift/Redshift-Serverless en fonction de l'espace de noms et des attributs de nom des informations de jeu de données correspondantes lors de l'événement d'exécution. OpenLineage
Atténuation : comme il n'existe aucun moyen déterministe de savoir si le nom donné appartient à un cluster ou à un groupe de travail, nous utilisons l'heuristique suivante :
Si le « nom » correspondant à l'ensemble de données contient
redshift-serverless.amazonaws.com« », nous utilisons redshift-serverless dans l'ARN, sinon la valeur par défaut est « redshift ».Ce qui précède signifie que les alias sur les noms de groupes de travail ne fonctionneront pas.
Cause première : les ensembles de données en amont ne sont pas correctement liés pour les actifs personnalisés.
Atténuation : assurez-vous de renseigner le sourceIdentifier champ sur la ressource en invoquantCreateAsset/CreateAssetRevisionqui correspond au nœud sourceIdentifier du jeu de données (qui serait<namespace>/<name>pour les nœuds personnalisés).
