Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Apprentissage par renforcement dans AWS DeepRacer
Dans le cadre de l'apprentissage par renforcement, un agent, tel qu'un DeepRacer véhicule AWS physique ou virtuel, dont l'objectif est d'atteindre un objectif, interagit avec un environnement afin de maximiser la récompense totale de l'agent. L'agent effectue une action, guidé par une politique appelée politique, à un état donné de l'environnement et atteint un nouvel état. Une récompense immédiate est associée à toutes les actions. La récompense est une mesure de l'intérêt de l'action. Cette récompense immédiate doit être renvoyée par l'environnement.
L'objectif de l'apprentissage par renforcement dans AWS DeepRacer est d'apprendre la politique optimale dans un environnement donné. L'apprentissage est un processus itératif par tâtonnement (essais et erreurs). L'agent effectue une action initiale aléatoire afin d'atteindre un nouvel état. Ensuite, l'agent itère l'étape du nouvel état à l'état suivant. Au fil du temps, l'agent découvre des actions qui permettent d'obtenir les récompenses à long terme maximales. L'interaction de l'agent d'un état initial à un état final est appelé un épisode.
Le schéma suivant illustre ce processus d'apprentissage :
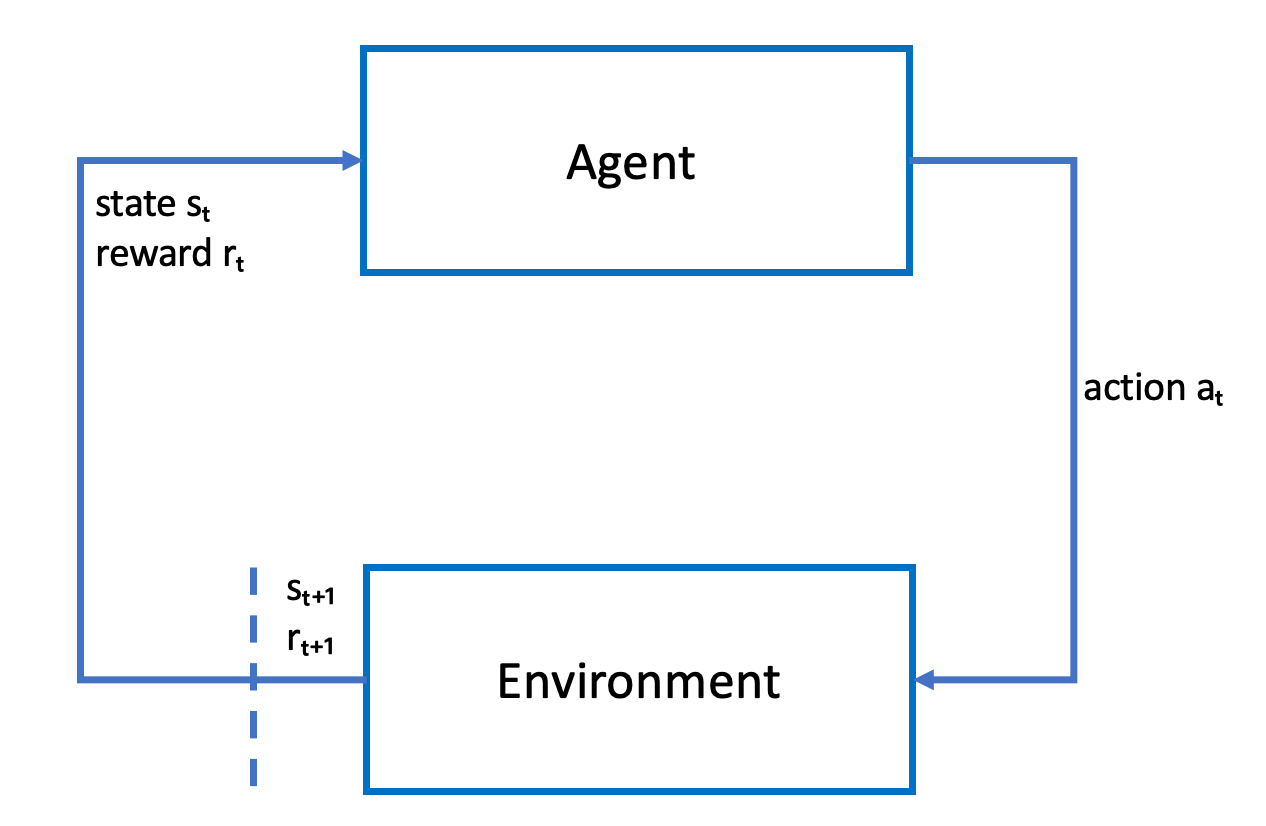
L'agent incarne un réseau neuronal qui représente une fonction pour se rapprocher de la politique de l'agent. L'image de la caméra avant du véhicule constitue l'état de l'environnement et l'action de l'agent est définie par la vitesse et les angles de direction de l'agent.
L'agent reçoit des récompenses positives s'il reste sur la piste jusqu'à l'arrivée et des récompenses négatives s'il sort de la piste. Un épisode commence à un point donné sur la piste et se termine lorsque l'agent sort de la piste ou termine un tour.
Note
À proprement parler, l'état de l'environnement fait référence à tous les éléments applicables. Par exemple, la position du véhicule sur la piste ainsi que la forme de la piste. L'image transmise par la caméra montée à l'avant du véhicule ne capture pas l'état complet de l'environnement. Pour cette raison, l'environnement est considéré comme partiellement observé et l'entrée de l'agent est appelée observation plutôt que état. Pour des raisons de simplicité, nous utilisons indifféremment les termes état et observation dans la présente documentation.
La formation de l'agent dans un environnement simulé présente les avantages suivants :
-
La simulation permet d'évaluer la progression de l'agent et d'identifier les sorties de piste pour calculer une récompense.
-
La simulation évite au formateur de devoir effectuer des tâches fastidieuses pour réinitialiser le véhicule à chaque fois qu'il sort de la piste, comme c'est le cas dans un environnement physique.
-
La simulation peut accélérer la formation.
-
La simulation permet de mieux contrôler les conditions environnementales, par exemple en sélectionnant différents circuits, arrière-plans et conditions du véhicule.
L'alternative à l'apprentissage par renforcement est l'apprentissage supervisé, également appelé apprentissage par imitation. Ici, un ensemble de données connu (de tuples [image, action]) collecté à partir d'un environnement donné est utilisé pour former l'agent. Les modèles qui sont formés via l'apprentissage par imitation peuvent être appliqués à la conduite autonome. Ils sont performants uniquement lorsque les images de la caméra ressemblent aux images de l'ensemble de données de la formation. Pour que la conduite soit fiable, les ensembles de données de la formation doivent être exhaustifs. Par opposition, l'apprentissage par renforcement ne nécessite pas ces efforts d'étiquetage importants et peut être formé entièrement en simulation. Étant donné que l'apprentissage par renforcement commence avec des actions aléatoires, l'agent apprend différentes conditions d'environnement et de piste. Cela rend le modèle entraîné robuste.
