Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Commencer à utiliser Amazon EMR sur EKS
Cette rubrique vous aide à commencer à utiliser Amazon EMR EKS en déployant une application Spark sur un cluster virtuel. Il inclut les étapes permettant de configurer les autorisations appropriées et de démarrer une tâche. Avant de commencer, assurez-vous d'avoir terminé les étapes de Configuration d'Amazon EMR sur EKS. Cela vous permet d'obtenir des outils tels que la AWS CLI configuration avant de créer votre cluster virtuel. Pour d'autres modèles qui peuvent vous aider à démarrer, consultez notre guide EMR des meilleures pratiques en matière de conteneurs
Lors des étapes de configuration, vous aurez besoin des informations suivantes :
-
ID de cluster virtuel pour le EKS cluster Amazon et l'espace de noms Kubernetes enregistrés auprès d'Amazon EMR
Important
Lors de la création d'un EKS cluster, veillez à utiliser m5.xlarge comme type d'instance, ou tout autre type d'instance doté d'un niveau supérieur et d'une capacité de mémoire supérieureCPU. L'utilisation d'un type d'instance dont la mémoire est inférieure CPU à m5.xlarge peut entraîner l'échec de la tâche en raison de l'insuffisance des ressources disponibles dans le cluster.
-
Nom du IAM rôle utilisé pour l'exécution de la tâche
-
Étiquette de sortie pour la EMR version Amazon (par exemple,
emr-6.4.0-latest) -
Cibles de destination pour la journalisation et la surveillance :
-
Nom du groupe de CloudWatch journaux Amazon et préfixe du flux de journaux
-
Emplacement Amazon S3 pour stocker les journaux des événements et des conteneurs
-
Important
Amazon EMR on EKS Jobs utilise Amazon CloudWatch et Amazon S3 comme cibles de destination pour la surveillance et la journalisation. Vous pouvez suivre l'avancement des tâches et résoudre les échecs en consultant les journaux des tâches envoyés à ces destinations. Pour activer la journalisation, la IAM politique associée au IAM rôle d'exécution des tâches doit disposer des autorisations requises pour accéder aux ressources cibles. Si la IAM politique ne dispose pas des autorisations requises, vous devez suivre les étapes décrites dans Mise à jour la politique d'approbation du rôle d'exécution des tâches Configurer une tâche exécutée pour utiliser les journaux Amazon S3 et Configurer une tâche exécutée pour utiliser les CloudWatch journaux avant d'exécuter cet exemple de tâche.
Exécution d'une application Spark
Suivez les étapes ci-dessous pour exécuter une application Spark simple sur Amazon EMR surEKS. Le fichier d'application entryPoint d'une application Spark Python se trouve à l'adresse s3://. Le REGION.elasticmapreduce/emr-containers/samples/wordcount/scripts/wordcount.pyREGION est la région dans laquelle réside votre cluster EKS virtuel AmazonEMR, telle que us-east-1.
-
Mettez à jour la IAM politique du rôle d'exécution des tâches avec les autorisations requises, comme le montrent les déclarations de politique suivantes.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "ReadFromLoggingAndInputScriptBuckets", "Effect": "Allow", "Action": [ "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::*.elasticmapreduce", "arn:aws:s3:::*.elasticmapreduce/*", "arn:aws:s3:::amzn-s3-demo-destination-bucket", "arn:aws:s3:::amzn-s3-demo-destination-bucket/*", "arn:aws:s3:::amzn-s3-demo-logging-bucket", "arn:aws:s3:::amzn-s3-demo-logging-bucket/*" ] }, { "Sid": "WriteToLoggingAndOutputDataBuckets", "Effect": "Allow", "Action": [ "s3:PutObject", "s3:DeleteObject" ], "Resource": [ "arn:aws:s3:::amzn-s3-demo-destination-bucket/*", "arn:aws:s3:::amzn-s3-demo-logging-bucket/*" ] }, { "Sid": "DescribeAndCreateCloudwatchLogStream", "Effect": "Allow", "Action": [ "logs:CreateLogStream", "logs:DescribeLogGroups", "logs:DescribeLogStreams" ], "Resource": [ "arn:aws:logs:*:*:*" ] }, { "Sid": "WriteToCloudwatchLogs", "Effect": "Allow", "Action": [ "logs:PutLogEvents" ], "Resource": [ "arn:aws:logs:*:*:log-group:my_log_group_name:log-stream:my_log_stream_prefix/*" ] } ] }-
La première déclaration
ReadFromLoggingAndInputScriptBucketsde cette politique accorde àListBucketetGetObjectsl'accès aux compartiments Amazon S3 suivants :-
REGION.elasticmapreduceentryPoint. -
amzn-s3-demo-destination-bucket‐ un compartiment que vous définissez pour vos données de sortie. -
amzn-s3-demo-logging-bucket‐ un compartiment que vous définissez pour vos données de journalisation.
-
-
La deuxième déclaration
WriteToLoggingAndOutputDataBucketsde cette politique accorde à la tâche l'autorisation d'écrire des données dans vos compartiments de sortie et de journalisation, respectivement. -
La troisième déclaration
DescribeAndCreateCloudwatchLogStreamaccorde à la tâche l'autorisation de décrire et de créer Amazon CloudWatch Logs. -
La quatrième déclaration
WriteToCloudwatchLogsaccorde l'autorisation d'écrire des journaux dans un groupe de CloudWatch journaux Amazon nomménom_mon_groupe_journalmy_log_stream_prefix
-
-
Pour exécuter une application Spark Python, utilisez la commande ci-dessous. Remplacez tous les remplaçables
red italicizedvaleurs avec des valeurs appropriées. LeREGIONest la région dans laquelle réside votre cluster EKS virtuel AmazonEMR, telle queus-east-1.aws emr-containers start-job-run \ --virtual-cluster-idcluster_id\ --namesample-job-name\ --execution-role-arnexecution-role-arn\ --release-labelemr-6.4.0-latest\ --job-driver '{ "sparkSubmitJobDriver": { "entryPoint": "s3://REGION.elasticmapreduce/emr-containers/samples/wordcount/scripts/wordcount.py", "entryPointArguments": ["s3://amzn-s3-demo-destination-bucket/wordcount_output"], "sparkSubmitParameters": "--conf spark.executor.instances=2 --conf spark.executor.memory=2G --conf spark.executor.cores=2 --conf spark.driver.cores=1" } }' \ --configuration-overrides '{ "monitoringConfiguration": { "cloudWatchMonitoringConfiguration": { "logGroupName": "my_log_group_name", "logStreamNamePrefix": "my_log_stream_prefix" }, "s3MonitoringConfiguration": { "logUri": "s3://amzn-s3-demo-logging-bucket" } } }'Les données de sortie de cette tâche seront disponibles à l'adresse
s3://.amzn-s3-demo-destination-bucket/wordcount_outputVous pouvez également créer un JSON fichier avec des paramètres spécifiques pour l'exécution de votre tâche. Exécutez ensuite la
start-job-runcommande avec un chemin d'accès au JSON fichier. Pour de plus amples informations, veuillez consulter Soumission d'une tâche exécutée avec StartJobRun. Pour plus d'informations sur la configuration des paramètres d'exécution des tâches, consultez Options de configuration d'une exécution de tâche. -
Pour exécuter une SQL application Spark, utilisez la commande suivante. Remplacez tous les
red italicizedvaleurs avec des valeurs appropriées. LeREGIONest la région dans laquelle réside votre cluster EKS virtuel AmazonEMR, telle queus-east-1.aws emr-containers start-job-run \ --virtual-cluster-idcluster_id\ --namesample-job-name\ --execution-role-arnexecution-role-arn\ --release-labelemr-6.7.0-latest\ --job-driver '{ "sparkSqlJobDriver": { "entryPoint": "s3://query-file.sql", "sparkSqlParameters": "--conf spark.executor.instances=2 --conf spark.executor.memory=2G --conf spark.executor.cores=2 --conf spark.driver.cores=1" } }' \ --configuration-overrides '{ "monitoringConfiguration": { "cloudWatchMonitoringConfiguration": { "logGroupName": "my_log_group_name", "logStreamNamePrefix": "my_log_stream_prefix" }, "s3MonitoringConfiguration": { "logUri": "s3://amzn-s3-demo-logging-bucket" } } }'Un exemple de fichier de SQL requête est présenté ci-dessous. Vous devez disposer d'un magasin de fichiers externe, tel que S3, où les données des tables sont stockées.
CREATE DATABASE demo; CREATE EXTERNAL TABLE IF NOT EXISTS demo.amazonreview( marketplace string, customer_id string, review_id string, product_id string, product_parent string, product_title string, star_rating integer, helpful_votes integer, total_votes integer, vine string, verified_purchase string, review_headline string, review_body string, review_date date, year integer) STORED AS PARQUET LOCATION 's3://URI to parquet files'; SELECT count(*) FROM demo.amazonreview; SELECT count(*) FROM demo.amazonreview WHERE star_rating = 3;La sortie de cette tâche sera disponible dans les journaux stdout du pilote dans S3 ou CloudWatch,
monitoringConfigurationselon la configuration. -
Vous pouvez également créer un JSON fichier avec des paramètres spécifiques pour l'exécution de votre tâche. Exécutez ensuite la start-job-run commande avec un chemin d'accès au JSON fichier. Pour plus d'informations, consultez la rubrique Soumission d'une tâche. Pour plus d'informations sur la configuration des paramètres d'exécution d'une tâche, consultez la rubrique Options de configuration d'une exécution de tâche.
Pour suivre la progression de la tâche ou corriger les échecs, vous pouvez inspecter les journaux chargés sur Amazon S3, CloudWatch les journaux ou les deux. Reportez-vous au chemin du journal dans Amazon S3 à la section Configurer l'exécution d'une tâche pour utiliser les journaux S3 et pour les journaux Cloudwatch à la section Configurer une exécution de tâche pour utiliser CloudWatch les journaux. Pour voir les CloudWatch journaux dans Logs, suivez les instructions ci-dessous.
-
Ouvrez la CloudWatch console à l'adresse https://console.aws.amazon.com/cloudwatch/
. -
Dans le volet Navigation, choisissez Journaux. Puis choisissez Groupes de journaux.
-
Choisissez le groupe de journaux EMR sur lequel Amazon doit être connecté, EKS puis consultez les événements du journal chargés.
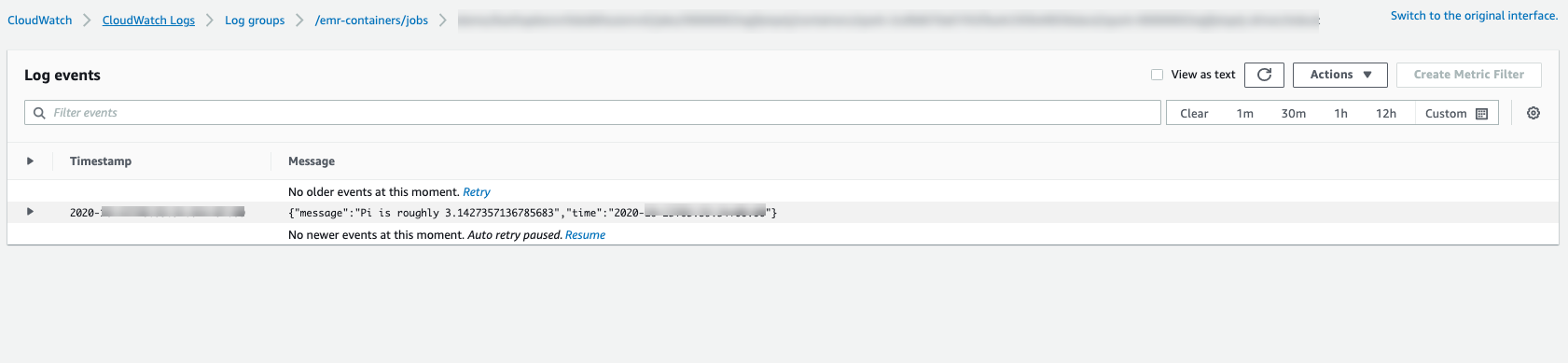
-
Important
Les tâches ont une politique de relance configurée par défaut. Pour plus d'informations sur la modification ou la désactivation de la configuration, consultez la rubrique Utilisation des politiques de relance des tâches.
