Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation des blocs-notes Jupyter auto-hébergés
Vous pouvez héberger et gérer Jupyter ou des JupyterLab blocs-notes sur une EC2 instance Amazon ou sur votre propre cluster Amazon EKS en tant que bloc-notes Jupyter auto-hébergé. Vous pouvez ensuite exécuter des charges de travail interactives avec vos blocs-notes Jupyter auto-hébergés. Les sections suivantes décrivent le processus de configuration et de déploiement d'un bloc-notes Jupyter auto-hébergé sur un cluster Amazon EKS.
Création d'un bloc-notes Jupyter auto-hébergé sur un cluster EKS
Création d’un groupe de sécurité
Avant de créer un point de terminaison interactif et d'exécuter un Jupyter ou un JupyterLab bloc-notes auto-hébergé, vous devez créer un groupe de sécurité pour contrôler le trafic entre votre bloc-notes et le point de terminaison interactif. Pour utiliser la EC2 console Amazon ou le EC2 SDK Amazon pour créer le groupe de sécurité, reportez-vous aux étapes décrites dans la section Créer un groupe de sécurité dans le guide de l' EC2 utilisateur Amazon. Vous devez créer le groupe de sécurité dans le VPC où vous souhaitez déployer votre serveur de bloc-notes.
Pour suivre l'exemple de ce guide, utilisez le même VPC que votre cluster Amazon EKS. Si vous souhaitez héberger votre bloc-notes dans un VPC différent de celui de votre cluster Amazon EKS, vous devrez peut-être créer une connexion d'appairage entre les deux. VPCs Pour savoir comment créer une connexion d'appairage entre deux personnes VPCs, consultez la section Créer une connexion d'appairage VPC dans le guide de démarrage Amazon VPC.
Vous avez besoin de l'identifiant du groupe de sécurité pour créer un point de terminaison interactif Amazon EMR on EKS à l'étape suivante.
Création d'un point de terminaison interactif Amazon EMR on EKS
Après avoir créé un groupe de sécurité pour votre bloc-notes, suivez les étapes décrites dans Création d'un point de terminaison interactif pour votre cluster virtuel pour créer un point de terminaison interactif. Vous devez fournir l'identifiant du groupe de sécurité que vous avez créé pour votre bloc-notes dans Création d’un groupe de sécurité.
Insérez l'ID de sécurité your-notebook-security-group-id à la place des paramètres de remplacement de configuration suivants :
--configuration-overrides '{ "applicationConfiguration": [ { "classification": "endpoint-configuration", "properties": { "notebook-security-group-id": "your-notebook-security-group-id" } } ], "monitoringConfiguration": { ...'
Récupération de l'URL du serveur de passerelle de votre point de terminaison interactif
Après avoir créé un point de terminaison interactif, récupérez l'URL du serveur de passerelle à l'aide de la commande describe-managed-endpoint de la AWS CLI. Vous avez besoin de cette URL pour connecter votre bloc-notes au point de terminaison. L'URL du serveur de passerelle est un point de terminaison privé.
aws emr-containers describe-managed-endpoint \ --regionregion\ --virtual-cluster-idvirtualClusterId\ --idendpointId
Au départ, votre point de terminaison se trouve dans CREATINGétat. Après quelques minutes, il passe au ACTIVEétat. Lorsque le point final est ACTIVE, il est prêt à être utilisé.
Prenez note de l'attribut serverUrl renvoyé par la commande aws emr-containers
describe-managed-endpoint à partir du point de terminaison actif. Vous avez besoin de cette URL pour connecter votre bloc-notes au point de terminaison lorsque vous déployez votre Jupyter ou votre bloc-notes auto-hébergé. JupyterLab
Récupération d'un jeton d'authentification pour la connexion au point de terminaison interactif
Pour vous connecter à un point de terminaison interactif depuis un Jupyter ou un JupyterLab bloc-notes, vous devez générer un jeton de session avec l'GetManagedEndpointSessionCredentialsAPI. Le jeton sert de preuve d'authentification pour la connexion au serveur de point de terminaison interactif.
La commande suivante est expliquée plus en détail avec un exemple de résultat ci-dessous.
aws emr-containers get-managed-endpoint-session-credentials \ --endpoint-identifierendpointArn\ --virtual-cluster-identifiervirtualClusterArn\ --execution-role-arnexecutionRoleArn\ --credential-type "TOKEN" \ --duration-in-secondsdurationInSeconds\ --regionregion
endpointArn-
L'ARN de votre point de terminaison. Vous pouvez trouver l'ARN dans le résultat d'un appel
describe-managed-endpoint. virtualClusterArn-
L'ARN du cluster virtuel.
executionRoleArn-
L'ARN du rôle d'exécution.
durationInSeconds-
La durée en secondes pendant laquelle le jeton est valide. La durée par défaut est de 15 minutes (
900) et la durée maximale est de 12 heures (43200). region-
La même région que votre point de terminaison.
Votre résultat devrait ressembler à l'exemple suivant. Prenez note de la session-token
{
"id": "credentialsId",
"credentials": {
"token": "session-token"
},
"expiresAt": "2022-07-05T17:49:38Z"
}Exemple : déploiement d'un JupyterLab bloc-notes
Une fois les étapes ci-dessus terminées, vous pouvez essayer cet exemple de procédure pour déployer un JupyterLab bloc-notes dans le cluster Amazon EKS avec votre point de terminaison interactif.
-
Créez un espace de noms pour exécuter le serveur de bloc-notes.
-
Créez un fichier local,
notebook.yaml, avec le contenu suivant. Le contenu du fichier est décrit ci-dessous.apiVersion: v1 kind: Pod metadata: name: jupyter-notebook namespace:namespacespec: containers: - name: minimal-notebook image: jupyter/all-spark-notebook:lab-3.1.4 # open source image ports: - containerPort: 8888 command: ["start-notebook.sh"] args: ["--LabApp.token=''"] env: - name: JUPYTER_ENABLE_LAB value: "yes" - name: KERNEL_LAUNCH_TIMEOUT value: "400" - name: JUPYTER_GATEWAY_URL value: "serverUrl" - name: JUPYTER_GATEWAY_VALIDATE_CERT value: "false" - name: JUPYTER_GATEWAY_AUTH_TOKEN value: "session-token"Si vous déployez le bloc-notes Jupyter sur un cluster Fargate, étiquetez le pod Jupyter avec une étiquette
role, comme indiqué dans l'exemple ci-dessous :... metadata: name: jupyter-notebook namespace: default labels: role:example-role-name-labelspec: ...namespace-
L'espace de noms Kubernetes dans lequel le bloc-notes est déployé.
serverUrl-
Attribut
serverUrlrenvoyé par la commandedescribe-managed-endpointdans Récupération de l'URL du serveur de passerelle de votre point de terminaison interactif . session-token-
Attribut
session-tokenrenvoyé par la commandeget-managed-endpoint-session-credentialsdans Récupération d'un jeton d'authentification pour la connexion au point de terminaison interactif. KERNEL_LAUNCH_TIMEOUT-
Durée en secondes pendant laquelle le point de terminaison interactif attend l'arrivée du noyau RUNNINGétat. Veillez à ce que le lancement du noyau ait suffisamment de temps pour se terminer en définissant le délai de lancement du noyau sur une valeur appropriée (400 secondes au maximum).
KERNEL_EXTRA_SPARK_OPTS-
Vous pouvez éventuellement transmettre des configurations Spark supplémentaires pour les noyaux Spark. Définissez cette variable d'environnement avec les valeurs de la propriété de configuration Spark, comme indiqué dans l'exemple ci-dessous :
- name: KERNEL_EXTRA_SPARK_OPTS value: "--conf spark.driver.cores=2 --conf spark.driver.memory=2G --conf spark.executor.instances=2 --conf spark.executor.cores=2 --conf spark.executor.memory=2G --conf spark.dynamicAllocation.enabled=true --conf spark.dynamicAllocation.shuffleTracking.enabled=true --conf spark.dynamicAllocation.minExecutors=1 --conf spark.dynamicAllocation.maxExecutors=5 --conf spark.dynamicAllocation.initialExecutors=1 "
-
Déployez la spécification de pod sur votre cluster Amazon EKS :
kubectl apply -f notebook.yaml -nnamespaceCela démarrera un JupyterLab bloc-notes minimal connecté à votre point de terminaison interactif Amazon EMR on EKS. Attendez que le pod soit RUNNING. Vous pouvez vérifier son état à l'aide de la commande suivante :
kubectl get pod jupyter-notebook -nnamespaceLorsque le pod est prêt, la commande
get podrenvoie un résultat similaire à celui-ci :NAME READY STATUS RESTARTS AGE jupyter-notebook 1/1 Running 0 46s -
Associez le groupe de sécurité du bloc-notes au nœud sur lequel le bloc-notes est programmé.
-
Identifiez d'abord le nœud sur lequel le pod
jupyter-notebookest programmé à l'aide de la commandedescribe pod.kubectl describe pod jupyter-notebook -nnamespace Ouvrez la console Amazon EKS à l'adresse https://console.aws.amazon.com/eks/home#/clusters
. -
Accédez à l'onglet Calcul de votre cluster Amazon EKS et sélectionnez le nœud identifié par la commande
describe pod. Sélectionnez l'identifiant d'instance du nœud. -
Dans le menu Actions, sélectionnez Sécurité > Modifier les groupes de sécurité pour associer le groupe de sécurité que vous avez créé dans Création d’un groupe de sécurité.
-
Si vous déployez le module de bloc-notes Jupyter sur AWS Fargate, créez-en un
SecurityGroupPolicyà appliquer au module de bloc-notes Jupyter avec le libellé du rôle :cat >my-security-group-policy.yaml <<EOF apiVersion: vpcresources.k8s.aws/v1beta1 kind: SecurityGroupPolicy metadata: name:example-security-group-policy-namenamespace: default spec: podSelector: matchLabels: role:example-role-name-labelsecurityGroups: groupIds: -your-notebook-security-group-idEOF
-
-
Maintenant, redirigez le port afin que vous puissiez accéder localement à l' JupyterLab interface :
kubectl port-forward jupyter-notebook 8888:8888 -nnamespaceUne fois que cela est lancé, accédez à votre navigateur local et rendez-vous
localhost:8888pour voir l' JupyterLab interface :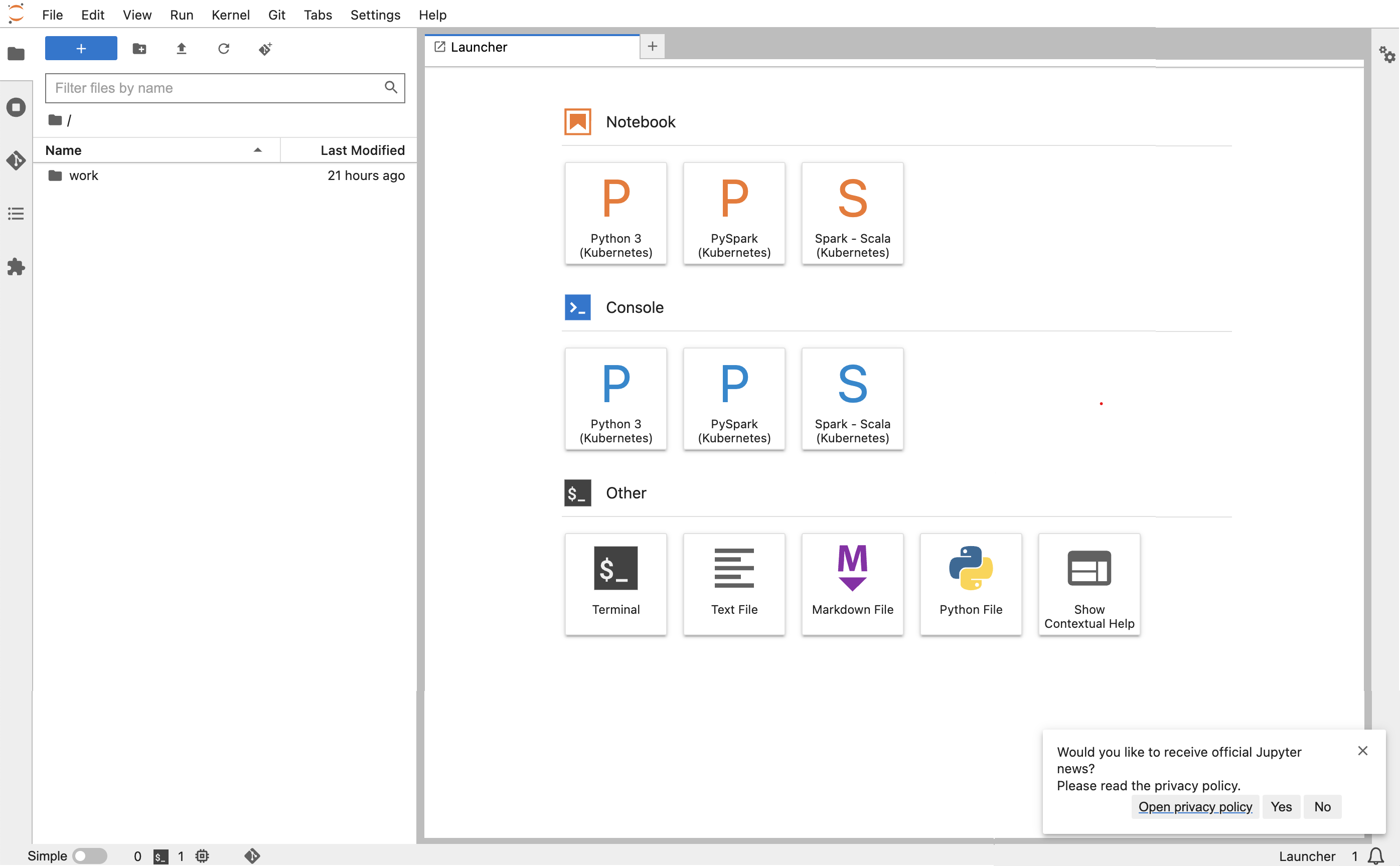
-
À partir de JupyterLab, créez un nouveau bloc-notes Scala. Voici un exemple d'extrait de code que vous pouvez exécuter pour calculer approximativement la valeur de Pi :
import scala.math.random import org.apache.spark.sql.SparkSession /** Computes an approximation to pi */ val session = SparkSession .builder .appName("Spark Pi") .getOrCreate() val slices = 2 // avoid overflow val n = math.min(100000L * slices, Int.MaxValue).toInt val count = session.sparkContext .parallelize(1 until n, slices) .map { i => val x = random * 2 - 1 val y = random * 2 - 1 if (x*x + y*y <= 1) 1 else 0 }.reduce(_ + _) println(s"Pi is roughly ${4.0 * count / (n - 1)}") session.stop()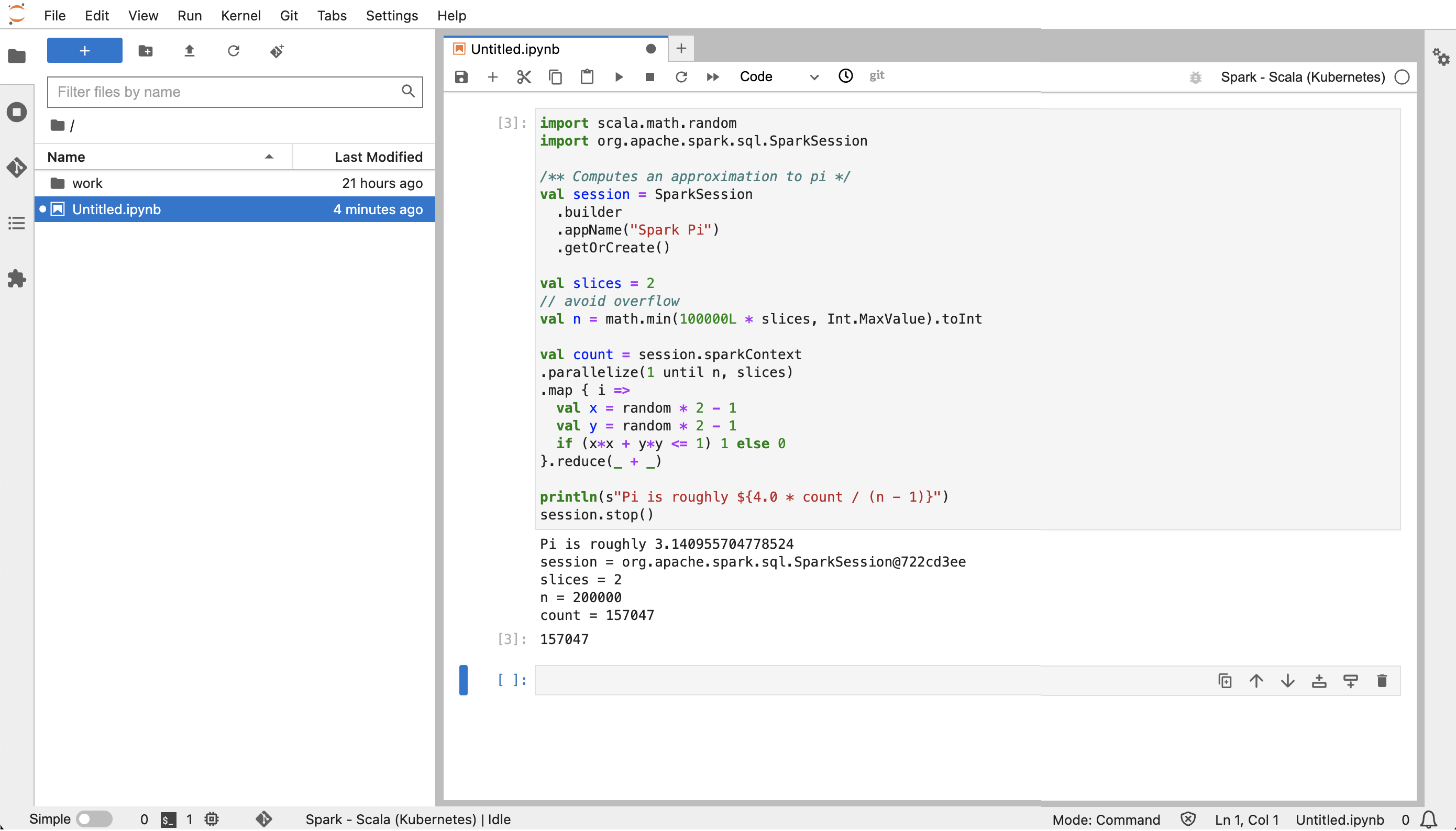
Suppression d'un bloc-notes Jupyter auto-hébergé
Lorsque vous êtes prêt à supprimer votre bloc-notes auto-hébergé, vous pouvez également supprimer le point de terminaison interactif et le groupe de sécurité. Effectuez les actions dans l'ordre suivant :
-
Utilisez la commande suivante pour supprimer le pod
jupyter-notebook:kubectl delete pod jupyter-notebook -nnamespace -
Supprimez ensuite votre point de terminaison interactif à l'aide de la commande
delete-managed-endpoint. Pour savoir comment supprimer un point de terminaison interactif, consultez Suppression d'un point de terminaison interactif. Dans un premier temps, votre point de terminaison se trouvera dans TERMINATINGétat. Une fois que toutes les ressources ont été nettoyées, il passe au TERMINATEDétat. -
Si vous ne prévoyez pas d'utiliser le groupe de sécurité des blocs-notes que vous avez créé dans Création d’un groupe de sécurité pour d'autres déploiements de blocs-notes Jupyter, vous pouvez le supprimer. Consultez Supprimer un groupe de sécurité dans le guide de EC2 l'utilisateur Amazon pour plus d'informations.
