Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
AWS Glue components
AWS Glue fournit une console et des opérations d'API pour configurer et gérer votre charge de travail d'extraction, de transformation et de chargement (ETL). Vous pouvez utiliser les opérations d'API via plusieurs SDK spécifiques au langage et le AWS Command Line Interface ().AWS CLI Pour plus d'informations sur l'utilisation du AWS CLI, reportez-vous à la section Référence des AWS CLI commandes.
AWS Glue utilise le AWS Glue Data Catalog pour stocker les métadonnées relatives aux sources de données, aux transformations et aux cibles. Le Catalogue de données est un remplacement instantané du métastore Apache Hive. AWS Glue Jobs system Il fournit une infrastructure gérée pour définir, planifier et exécuter des opérations ETL sur vos données. Pour plus d'informations sur l' AWS Glue API, consultezAWS Glue API.
AWS Glue console
Vous utilisez la AWS Glue console pour définir et orchestrer votre flux de travail ETL. La console appelle plusieurs opérations d'API dans AWS Glue Data Catalog et AWS Glue Jobs system pour effectuer les tâches suivantes :
-
Définissez AWS Glue des objets tels que des tâches, des tables, des robots d'exploration et des connexions.
-
Planifier l’exécution des crawlers.
-
Définir les événements ou planifications des déclencheurs de tâche.
-
Recherchez et filtrez des listes d' AWS Glue objets.
-
Modifier les scripts de transformation.
AWS Glue Data Catalog
AWS Glue Data Catalog Il s'agit de votre magasin de métadonnées techniques permanent dans le AWS cloud.
Chaque AWS compte en possède un AWS Glue Data Catalog par AWS région. Chaque catalogue de données est un ensemble hautement évolutif de tableaux organisés en bases de données. Une table est une représentation par métadonnées d'un ensemble de données structurées ou semi-structurées stockées dans des sources telles qu'Amazon RDS, le système de fichiers distribué Apache Hadoop, Amazon OpenSearch Service, etc. AWS Glue Data Catalog Il fournit un référentiel uniforme dans lequel des systèmes disparates peuvent stocker et rechercher des métadonnées afin de suivre les données dans des silos de données. Vous pouvez ensuite utiliser les métadonnées pour interroger et transformer ces données de manière cohérente dans une grande variété d’applications.
Vous utilisez le catalogue de données ainsi que les Gestion des identités et des accès AWS politiques et Lake Formation pour contrôler l'accès aux tables et aux bases de données. Pour ce faire, vous pouvez autoriser différents groupes de votre entreprise à publier les données en toute sécurité à l’échelle de l’organisation tout en protégeant au maximum les informations sensibles.
Le catalogue de données, ainsi que Lake Formation, vous fournissent également des fonctionnalités complètes d'audit et de gouvernance, avec un suivi des modifications de schéma et des contrôles d'accès aux données. CloudTrail Cela permet de s’assurer que les données ne sont pas modifiées de façon inappropriée ou partagées par inadvertance.
Pour plus d’informations sur la sécurisation et l’audit du AWS Glue Data Catalog, consultez :
-
AWS Lake Formation – Pour en savoir plus, consultez Présentation d’ AWS Lake Formation dans le Guide du développeur AWS Lake Formation .
-
CloudTrail— Pour plus d'informations, voir Qu'est-ce que c'est CloudTrail ? dans le guide de AWS CloudTrail l'utilisateur.
Voici d'autres AWS services et projets open source qui utilisent : AWS Glue Data Catalog
-
Amazon Athena – Pour plus d’informations, veuillez consulter la rubrique Présentation des tables, des bases de données et du catalogue de données dans le Guide de l’utilisateur Amazon Athena.
-
Amazon Redshift Spectrum Pour en savoir plus, consultez la rubrique Utilisation d’Amazon Redshift Spectrum pour interroger des données externes dans le Guide du développeur de base de données Amazon Redshift.
-
Amazon EMR — Pour plus d'informations, consultez les Resource-Based politiques d'utilisation relatives à l'accès à Amazon EMR dans le guide de gestion AWS Glue Data Catalog Amazon EMR.
-
AWS Glue Data Catalog client pour le métastore Apache Hive — Pour plus d'informations sur ce GitHub projet, voir AWS Glue Data Catalog Client pour le métastore Apache
Hive.
AWS Glue chenilles et classificateurs
AWS Glue vous permet également de configurer des robots d'exploration capables de scanner les données dans toutes sortes de référentiels, de les classer, d'en extraire des informations de schéma et de stocker les métadonnées automatiquement dans le. AWS Glue Data Catalog Ils AWS Glue Data Catalog peuvent ensuite être utilisés pour guider les opérations ETL.
Pour de plus amples informations sur la configuration des crawlers et des classifieurs, veuillez consulter Utilisation de robots pour alimenter le catalogue de données. Pour plus d'informations sur la programmation des robots d'exploration et des classificateurs à l'aide de l' AWS Glue API, consultez. API de classifieurs et d'crawlers
AWS Glue Opérations ETL
À l'aide des métadonnées du catalogue de données, AWS Glue vous pouvez générer automatiquement des scripts Scala ou PySpark (l'API Python pour Apache Spark) avec des AWS Glue extensions que vous pouvez utiliser et modifier pour effectuer diverses opérations ETL. Par exemple, vous pouvez extraire, nettoyer et transformer les données brutes, puis stocker le résultat dans un référentiel différent, où il peut être interrogé et analysé. Un tel script peut convertir un fichier CSV sous une forme relationnelle et l’enregistrer dans Amazon Redshift.
Pour plus d'informations sur l'utilisation des fonctionnalités AWS Glue ETL, consultezProgrammation de scripts Spark.
Streaming d'ETL en AWS Glue
AWS Glue vous permet d'effectuer des opérations ETL sur des données en streaming à l'aide de tâches exécutées en continu. AWS Glue L'ETL de streaming repose sur le moteur de streaming structuré Apache Spark et peut ingérer des flux provenant d'Amazon Kinesis Data Streams, d'Apache Kafka et d'Amazon Managed Streaming for Apache Kafka (Amazon MSK). ETL de streaming peut nettoyer et transformer les données de streaming et les charger dans des magasins de données Amazon S3 ou JDBC. Utilisez Streaming ETL in AWS Glue pour traiter les données d'événements telles que les flux IoT, les flux de clics et les journaux réseau.
Si vous connaissez le schéma de la source de données de streaming, vous pouvez le spécifier dans une table du catalogue de données. Sinon, vous pouvez activer la détection de schéma dans la tâche ETL de streaming. La tâche détermine ensuite automatiquement le schéma à partir des données entrantes.
La tâche ETL de streaming peut utiliser à la fois des transformations AWS Glue intégrées et des transformations natives d'Apache Spark Structured Streaming. Pour plus d'informations, consultez la section Opérations relatives au streaming DataFrames/Datasets
Pour de plus amples informations, veuillez consulter Diffusion de jobs ETL dans AWS Glue.
Le AWS Glue système d'emplois
AWS Glue Jobs system Il fournit une infrastructure gérée pour orchestrer votre flux de travail ETL. Vous pouvez créer des tâches AWS Glue qui automatisent les scripts que vous utilisez pour extraire, transformer et transférer des données vers différents emplacements. Les tâches peuvent être programmées et chaînées, ou elles peuvent être déclenchées par des événements tels que l’arrivée de nouvelles données.
Pour plus d'informations sur l'utilisation du AWS Glue Jobs system, consultezContrôle AWS Glue. Pour plus d’informations sur la programmation à l’aide de l’API AWS Glue Jobs system , consultez API de tâches.
Composants ETL visuels
AWS Glue vous permet de créer des tâches ETL via un canevas visuel que vous pouvez manipuler.
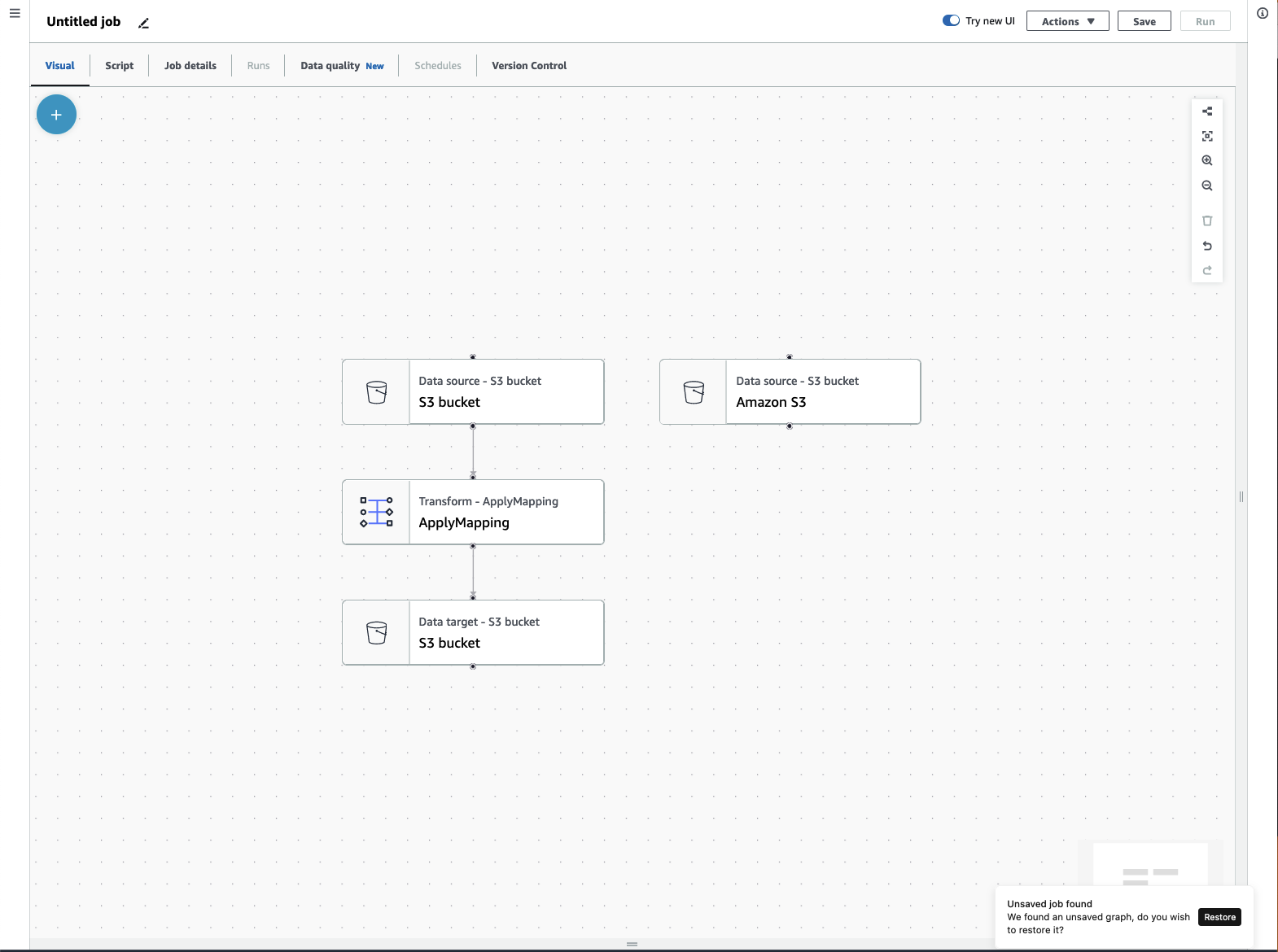
Menu de tâches ETL
Les options du menu situées en haut du canevas vous permettent d’accéder aux différentes vues et aux détails de configuration de votre tâche.
-
Visuel : le canevas de l’éditeur de tâche visuel. C’est ici que vous pouvez ajouter des nœuds pour créer une tâche.
-
Script : représentation par script de votre tâche ETL. AWS Glue génère le script en fonction de la représentation visuelle de votre travail. Vous pouvez également modifier votre script ou le télécharger.
Note
Si vous choisissez de modifier le script, l’expérience de création de tâches est définitivement convertie en mode script uniquement. Ensuite, vous ne pourrez plus utiliser l’éditeur visuel pour modifier la tâche. Vous devez ajouter toutes les sources de tâches, les transformations et les cibles, et apporter toutes les modifications nécessaires à l’aide de l’éditeur visuel avant de choisir de modifier le script.
-
Détails de la tâche : l’onglet Informations de la tâche vous permet de configurer votre tâche en définissant les propriétés de la tâche. Il existe des propriétés de base, telles que le nom et la description de votre tâche, le rôle IAM, le type de tâche, la version AWS Glue, la langue, le type de travailleur, le nombre de travailleurs, le signet de la tâche, l’exécution flexible, le nombre de suppressions et le délai d’expiration de la tâche, ainsi que des propriétés avancées, telles que les connexions, les bibliothèques, les paramètres de la tâche et les balises.
-
Exécutions : après l’exécution de votre tâche, vous pouvez accéder à cet onglet pour consulter vos précédentes exécutions de tâches.
-
Qualité des données : la qualité des données évalue et contrôle la qualité de vos ressources de données. Vous pouvez en savoir plus sur l’utilisation de la qualité des données dans cet onglet et ajouter une transformation de qualité des données à votre tâche.
-
Calendriers : les tâches que vous avez planifiées apparaissent dans cet onglet. Si aucun calendrier n’est associé à cette tâche, cet onglet n’est pas accessible.
-
Contrôle de version : vous pouvez utiliser Git avec votre tâche en la configurant dans un référentiel Git.
Panneaux ETL visuels
Lorsque vous travaillez dans le canevas, plusieurs panneaux sont disponibles pour vous aider à configurer vos nœuds ou à prévisualiser vos données et à visualiser le schéma de sortie.
-
Propriétés : le panneau Propriétés apparaît lorsque vous choisissez un nœud sur votre canevas.
-
Aperçu des données : le panneau Aperçu des données fournit un aperçu de la sortie des données afin que vous puissiez prendre des décisions avant d’exécuter votre tâche et d’examiner votre sortie.
-
Schéma de sortie : l’onglet Schéma de sortie vous permet de visualiser et de modifier le schéma de vos nœuds de transformation.
Redimensionnement des panneaux
Vous pouvez redimensionner le panneau Propriétés sur le côté droit de l’écran et le panneau inférieur qui contient les onglets Aperçu des données et Schéma de sortie en cliquant sur le bord du panneau et en le faisant glisser vers la gauche et la droite ou vers le haut et le bas.
-
Panneau Propriétés : redimensionnez le panneau Propriétés en cliquant et en faisant glisser le bord du canevas sur le côté droit de l’écran, puis en le faisant glisser vers la gauche pour augmenter sa largeur. Par défaut, le panneau est réduit et lorsqu’un nœud est sélectionné, le panneau Propriétés s’ouvre à sa taille par défaut.
-
Panneau Aperçu des données et Schéma de sortie : redimensionnez le panneau inférieur en cliquant et en faisant glisser le bord inférieur du canevas en bas de l’écran, puis en le faisant glisser vers le haut pour augmenter sa hauteur. Par défaut, le panneau est réduit et lorsqu’un nœud est sélectionné, le panneau inférieur s’ouvre à sa taille par défaut.
Canevas de tâche
Vous pouvez ajouter, supprimer et des move/reorder nœuds directement sur le canevas Visual ETL. Considérez-le comme votre espace de travail pour créer une tâche ETL entièrement fonctionnelle qui commence par une source de données et peut se terminer par une cible de données.
Lorsque vous travaillez avec des nœuds sur le canevas, vous disposez d’une barre d’outils qui vous permet d’effectuer des zooms avant et arrière, de supprimer des nœuds, d’établir ou de modifier des connexions entre les nœuds, de modifier l’orientation du flux de travail et d’annuler ou de rétablir une action.

La barre d’outils flottante est ancrée dans le coin supérieur droit du canevas et contient plusieurs images qui effectuent des actions :
-
Icône de mise en page : la première icône de la barre d’outils est l’icône de mise en page. Par défaut, la direction des tâches visuelles est de haut en bas. Elle réorganise la direction de votre tâche visuelle en disposant les nœuds horizontalement de gauche à droite. Cliquez à nouveau sur l’icône de mise en page pour revenir de haut en bas.
-
Icône de recentrage : l’icône de recentrage modifie l’affichage du canevas en le centrant. Vous pouvez l’utiliser pour des tâches importantes pour revenir à la position centrale.
-
Icône de zoom avant : l’icône de zoom avant agrandit la taille des nœuds du canevas.
-
Icône de zoom arrière : l’icône de zoom avant réduit la taille des nœuds du canevas.
-
Icône corbeille : l’icône de corbeille supprime un nœud de la tâche visuelle. Vous devez d’abord sélectionner un nœud.
-
Icône d’annulation : l’icône d’annulation annule la dernière action effectuée sur la tâche visuelle.
-
Icône de rétablissement : l’icône de rétablissement répète la dernière action effectuée sur la tâche visuelle.
Utilisation de la mini-carte

Panneau des ressources
Le panneau des ressources contient toutes les sources de données, les actions de transformation et les connexions disponibles. Ouvrez le panneau des ressources sur le canevas en cliquant sur l’icône « + ». Cela ouvre le panneau des ressources.
Pour fermer le panneau des ressources, cliquez sur la croix, X, dans le coin supérieur droit du panneau des ressources. Le panneau est ainsi masqué jusqu’à ce que vous souhaitiez l’ouvrir à nouveau.
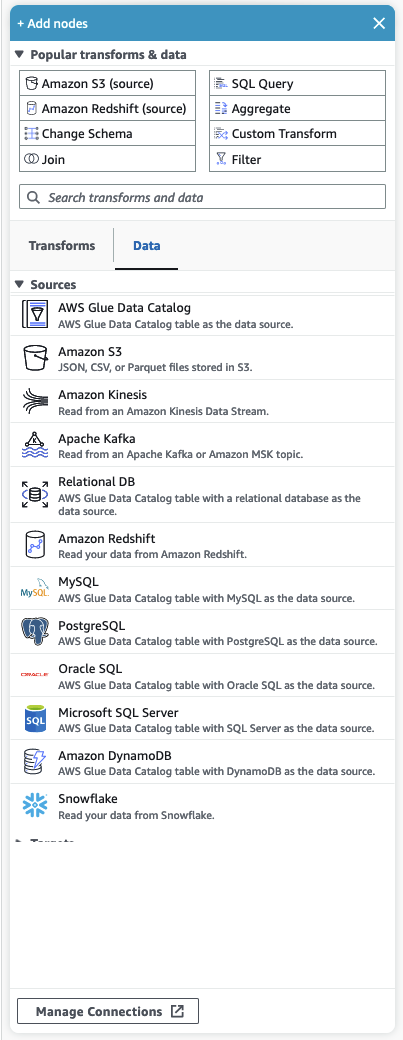
Popular transforme & les données
En haut du panneau se trouve une collection de Transformations et de données populaires. Ces nœuds sont couramment utilisés dans AWS Glue. Choisissez-en un pour l’ajouter au canevas. Vous pouvez également masquer les Transformations et données populaires en cliquant sur le triangle situé à côté de l’en-tête Transformations et données populaires.
Dans la section Transformations et données populaires, vous pouvez rechercher des nœuds de transformations et de source de données. Les résultats apparaissent au fur et à mesure que vous saisissez du texte. Plus vous saisissez de caractères lors de votre requête de recherche, plus la liste des résultats diminuera. Les résultats de recherche sont renseignés à partir de la and/or description du nom du nœud. Choisissez un nœud pour l’ajouter à votre canevas.
Transformations et données
Deux onglets organisent les nœuds en Transformations et Données.
Transformations : lorsque vous choisissez l’onglet Transformations, toutes les transformations disponibles peuvent être sélectionnées. Choisissez une transformation pour l’ajouter au canevas. Vous pouvez également choisir Ajouter une transformation au bas de la liste des transformations, ce qui ouvrira une nouvelle page de documentation sur la création de Transformations visuelles personnalisées. En suivant les étapes, vous pourrez créer vos propres transformations. Vos transformations apparaîtront alors dans la liste des transformations disponibles.
Données : l’onglet de données contient tous les nœuds des Sources et des Cibles. Vous pouvez masquer les sources et les cibles en cliquant sur le triangle situé à côté de l’en-tête sources ou cibles. Vous pouvez afficher les sources et les cibles en cliquant à nouveau sur le triangle. Choisissez un nœud source ou cible pour l’ajouter au canevas. Vous pouvez également choisir Gérer les connexions pour ajouter une nouvelle connexion. Cela ouvrira la page Connecteurs dans la console.
