Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Vous pouvez créer des tâches Extract-transform-load (ETL) qui s'exécutent continu et consomment des données provenant de sources en streaming telles que Amazon Kinesis Data Streams, Apache Kafka et Amazon Managed Streaming for Apache Kafka (Amazon MSK). Les tâches nettoient et transforment les données, puis chargent les résultats dans les lacs de données Amazon S3 ou les magasins de données JDBC.
En outre, vous pouvez produire des données pour des flux Amazon Kinesis Data Streams. Cette fonctionnalité n'est disponible que lors de l'écriture de AWS Glue scripts. Pour de plus amples informations, veuillez consulter Connexions Kinesis.
Par défaut, AWS Glue traite et écrit les données dans des fenêtres de 100 secondes. Cela permet de traiter les données de manière efficace et d'effectuer des agrégations sur les données qui arrivent plus tard que prévu. Vous pouvez modifier la taille de cette fenêtre temporelle pour augmenter la ponctualité ou la précision de l'agrégation. AWS Glue les tâches de streaming utilisent des points de contrôle plutôt que des signets de tâches pour suivre les données lues.
Note
AWS Glue facture toutes les heures pour les tâches ETL diffusées en continu pendant leur exécution.
Cette vidéo aborde les défis liés aux coûts du streaming ETL et les fonctionnalités de réduction des coûts dans AWS Glue.
La création d'une tâche ETL en streaming implique les étapes suivantes :
-
Pour une source de streaming Apache Kafka, créez un AWS Glue connexion à la source Kafka ou au cluster Amazon MSK.
-
Créez manuellement une table du catalogue de données pour la source en streaming.
-
Créez une tâche ETL pour la source de données de streaming. Définissez des propriétés de tâche spécifiques au streaming et fournissez votre propre script ou modifiez éventuellement le script généré.
Pour de plus amples informations, veuillez consulter Streaming d'ETL en AWS Glue.
Lorsque vous créez une tâche ETL de streaming pour Amazon Kinesis Data Streams, il n'est pas nécessaire de créer un AWS Glue connexion. Toutefois, s'il existe une connexion attachée au AWS Glue une tâche ETL de streaming utilisant Kinesis Data Streams comme source, puis un point de terminaison de cloud privé virtuel (VPC) vers Kinesis est requis. Pour plus d’informations, consultez Création d’un point de terminaison d’interface dans le Guide de l’utilisateur Amazon VPC. Lorsque vous spécifiez un Amazon Kinesis Data Streams dans un autre compte, vous devez configurer les rôles et les stratégies pour autoriser l'accès entre comptes. Pour de plus amples informations, veuillez consulter la rubrique Exemple : Lire à partir d'un flux Kinesis dans un autre compte.
AWS Glue les tâches ETL de streaming peuvent détecter automatiquement les données compressées, les décompresser de manière transparente, effectuer les transformations habituelles sur la source d'entrée et les charger dans le magasin de sortie.
AWS Glue prend en charge la décompression automatique pour les types de compression suivants en fonction du format d'entrée :
| Type de compression | Fichier Avro | Référence Avro | JSON | CSV | Grok |
|---|---|---|---|---|---|
| BZIP2 | Oui | Oui | Oui | Oui | Oui |
| GZIP | Non | Oui | Oui | Oui | Oui |
| SNAPPY | Oui (format Snappy brut) | Oui (format Snappy encadré) | Oui (format Snappy encadré) | Oui (format Snappy encadré) | Oui (format Snappy encadré) |
| XZ | Oui | Oui | Oui | Oui | Oui |
| ZSTD | Oui | Non | Non | Non | Non |
| DEFLATE | Oui | Oui | Oui | Oui | Oui |
Rubriques
Création d'un AWS Glue connexion pour un flux de données Apache Kafka
Pour lire un flux Apache Kafka, vous devez créer un AWS Glue connexion.
Pour créer un AWS Glue connexion pour une source Kafka (console)
Ouvrez la AWS Glue console à l'adresse https://console.aws.amazon.com/glue/
. -
Dans le volet de navigation, sous Data catalog (Catalogue de données), choisissez Connections (Connexions).
-
Choisissez Add connection (Ajouter une connexion), et dans la page Set up your connection's properties (Configurer les propriétés de votre connexion), saisissez un nom de connexion.
Note
Pour plus d'informations sur la spécification des propriétés de connexion, veuillez consulter Propriétés de connexion AWS Glue.
-
Pour Type de connexion, choisissez Kafka.
-
Pour les serveurs bootstrap Kafka URLs, entrez l'hôte et le numéro de port des courtiers bootstrap pour votre cluster Amazon MSK ou votre cluster Apache Kafka. Utilisez uniquement des points de terminaison utilisant le protocole TLS (Transport Layer Security) pour établir la connexion initiale au cluster Kafka. Les points de terminaison en texte brut ne sont pas pris en charge.
Voici un exemple de liste de paires de nom d'hôte et de numéro de port pour un cluster Amazon MSK.
myserver1.kafka.us-east-1.amazonaws.com:9094,myserver2.kafka.us-east-1.amazonaws.com:9094, myserver3.kafka.us-east-1.amazonaws.com:9094Pour plus d'informations sur l'obtention des informations du broker d'amorçage, veuillez consulter la rubrique Obtenir les brokers d'amorçage pour un cluster Amazon MSK dans le Guide du développeur Amazon Managed Streaming for Apache Kafka.
-
Si vous souhaitez une connexion sécurisée à la source de données Kafka, sélectionnez Require SSL connection (Connexion SSL obligatoire), et pour Kafka private CA certificate location (Emplacement du certificat d'autorité de certification privée Kafka), entrez un chemin d'accès Amazon S3 valide vers un certificat SSL personnalisé.
Pour une connexion SSL à Kafka autogérée, le certificat personnalisé est obligatoire. Il est facultatif pour Amazon MSK.
Pour plus d'informations sur la spécification d'un certificat personnalisé pour Kafka, consulter AWS Glue Propriétés de connexion SSL.
-
Utilisez AWS Glue Studio la AWS CLI pour spécifier une méthode d'authentification du client Kafka. Pour y accéder, AWS Glue Studio AWS Gluesélectionnez dans le menu ETL du volet de navigation de gauche.
Pour plus d'informations sur les méthodes d'authentification client Kafka, consultez AWS Glue Propriétés de connexion Kafka pour l'authentification du client .
-
Saisissez éventuellement une description, puis choisissez Suivant.
-
Pour un cluster Amazon MSK, spécifiez son Virtual Private Cloud (VPC), son sous-réseau et son groupe de sécurité. Les informations du VPC sont facultatives pour Kafka autogéré.
-
Choisissez Next (Suivant) pour vérifier toutes les propriétés de connexion, puis choisissez Finish (Terminer).
Pour plus d'informations sur AWS Glue connexions, voirConnexion aux données.
AWS Glue Propriétés de connexion Kafka pour l'authentification du client
- Authentification SASL/GSSAPI (Kerberos)
-
Le choix de cette méthode d'authentification vous permettra de spécifier les propriétés Kerberos.
- Kerberos Keytab
-
Choisissez l'emplacement du fichier keytab. Un keytab stocke les clés à long terme pour un ou plusieurs principaux. Pour en savoir plus, consultez Documentation du MIT Kerberos : Keytab
. - Fichier Kerberos krb5.conf
-
Choisissez le fichier krb5.conf. Il contient le domaine par défaut (un réseau logique, similaire à un domaine, qui définit un groupe de systèmes sous le même KDC) et l'emplacement du serveur KDC. Pour en savoir plus, consultez Documentation MIT Kerberos : krb5.conf
. - Principal Kerberos et nom de service Kerberos
-
Saisissez le principal Kerberos et le nom de service Kerberos. Pour plus d'informations, consultez MIT Kerberos Documentation: Kerberos principal
(Documentation du MIT Kerberos : principal Kerberos). - Authentification SASL/SCRAM-SHA-512
-
Le choix de cette méthode d'authentification vous permettra de spécifier les informations d'identification d'authentification.
- AWS Secrets Manager
-
Recherchez votre jeton dans la zone Search (Rechercher) en saisissant son nom ou son ARN.
- Nom d'utilisateur et mot de passe du fournisseur directement
-
Recherchez votre jeton dans la zone Search (Rechercher) en saisissant son nom ou son ARN.
- Authentification SSL client
-
Le choix de cette méthode d'authentification vous permet de sélectionner l'emplacement du centre de stockage des clés client Kafka en naviguant sur Amazon S3. Vous pouvez également entrer le mot de passe du centre de stockage des clés client Kafka et le mot de passe de la clé client Kafka.
- Authentification IAM
-
Cette méthode d'authentification ne nécessite aucune spécification supplémentaire et n'est applicable que lorsque la source de diffusion en direct est MSK Kafka.
- Authentification SASL/PLAIN
-
Le choix de cette méthode d'authentification vous permet de spécifier des informations d'authentification.
Création d'un tableau de catalogue de données pour une source en streaming
Une table du catalogue de données qui spécifie les propriétés du flux de données source, y compris le schéma de données, peut être créée manuellement pour une source de streaming. Cette table est utilisée comme source de données pour la tâche ETL en streaming.
Si vous ne connaissez pas le schéma des données dans le flux de données source, vous pouvez créer la table sans schéma. Ensuite, lorsque vous créez la tâche ETL de streaming, vous pouvez activer AWS Glue fonction de détection de schéma. AWS Glue détermine le schéma à partir des données de streaming.
Utilisation de la AWS Glue console
Note
Vous ne pouvez pas utiliser la AWS Lake Formation console pour créer la table ; vous devez utiliser AWS Glue console.
Tenez également compte des informations suivantes pour les sources en streaming au format Avro ou pour les données de journal auxquelles vous pouvez appliquer des modèles Grok.
Rubriques
Source de données Kinesis
Lors de la création de la table, définissez les propriétés de streaming ETL suivantes (console).
- Type de source
-
Kinesis
- Pour une source Kinesis dans le même compte :
-
- Région
-
AWS Région dans laquelle réside le service Amazon Kinesis Data Streams. Le nom de la région et du flux Kinesis sont convertis en un ARN de flux.
Exemple : https://kinesis.us-east-1.amazonaws.com
- Nom du flux Kinesis
-
Nom du flux comme décrit dans Création d'un flux dans le Guide du développeur d'Amazon Kinesis Data Streams.
- Pour obtenir une source Kinesis dans un autre compte, reportez-vous à Cet exemple pour configurer les rôles et les stratégies pour autoriser un accès entre comptes. Configurez ces paramètres :
-
- ARN du flux de diffusion
-
ARN du flux de données Kinesis auprès duquel le consommateur est enregistré. Pour plus d'informations, consultez les sections Amazon Resource Names (ARNs) et AWS Service Namespaces dans le Références générales AWS.
- ARN du rôle assumé
-
Amazon Resource Name (ARN) du rôle à assumer.
- Nom de la séance (facultatif)
-
Identifiant de la séance du rôle assumé.
Utilisez le nom de séance de rôle pour identifier de manière unique une séance lorsque le même rôle est assumé par différents principaux ou pour différentes raisons. Dans les scénarios impliquant plusieurs comptes, le nom de séance de rôle est visible et peut être enregistré par le compte propriétaire du rôle. Le nom de la séance de rôle est également utilisé dans l'ARN du principal de rôle présumé. Cela signifie que les demandes d'API inter-comptes ultérieures utilisant les informations d'identification de sécurité temporaires exposeront le nom de session du rôle au compte externe dans ses AWS CloudTrail journaux.
Pour définir les propriétés ETL de streaming pour Amazon Kinesis Data Streams (AWS Glue API AWS CLI(ou)
-
Pour configurer les propriétés ETL de streaming pour une source Kinesis dans le même compte, spécifiez les paramètres
streamNameetendpointUrldans la structureStorageDescriptorde l'opération d'APICreateTableou de la commandecreate_tablede la CLI."StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamName": "sample-stream", "endpointUrl": "https://kinesis.us-east-1.amazonaws.com" } ... }Ou, spécifiez le
streamARN."StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamARN": "arn:aws:kinesis:us-east-1:123456789:stream/sample-stream" } ... } -
Pour configurer les propriétés ETL de streaming pour une source Kinesis dans un autre compte, spécifiez les paramètres
streamARN,awsSTSRoleARNetawsSTSSessionName(facultatif) dans la structureStorageDescriptorde l'opération d'APICreateTableou de la commandecreate_tablede la CLI."StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamARN": "arn:aws:kinesis:us-east-1:123456789:stream/sample-stream", "awsSTSRoleARN": "arn:aws:iam::123456789:role/sample-assume-role-arn", "awsSTSSessionName": "optional-session" } ... }
Source de données Kafka
Lors de la création de la table, définissez les propriétés de streaming ETL suivantes (console).
- Type de source
-
Kafka
- Pour une source Kafka :
-
- Nom de la rubrique
-
Nom de la rubrique tel que spécifié dans Kafka.
- Connexion
-
Un AWS Glue connexion qui fait référence à une source Kafka, comme décrit dansCréation d'un AWS Glue connexion pour un flux de données Apache Kafka.
AWS Glue Source de la table de registre des schémas
Pour utiliser AWS Glue Registre des schémas pour les tâches de streaming, suivez les instructions de la section Cas d'utilisation : AWS Glue Data Catalog pour créer ou mettre à jour une table de registre de schéma.
À l'heure actuelle, AWS Glue Le streaming ne prend en charge que le format Glue Schema Registry Avro avec une inférence de schéma définie sur. false
Notes et restrictions pour les sources en streaming Avro
Les notes et restrictions suivantes s'appliquent aux sources en streaming au format Avro :
-
Lorsque la détection du schéma est activée, le schéma Avro doit être inclus dans la charge utile. Lorsqu'elle est désactivée, la charge utile ne doit contenir que des données.
-
Certains types de données Avro ne sont pas pris en charge dans les trames dynamiques. Vous ne pouvez pas spécifier ces types de données lorsque vous définissez le schéma à l'aide de la page Définir un schéma de l'assistant de création de table du AWS Glue console. Lors de la détection de schéma, les types non pris en charge dans le schéma Avro sont convertis en types pris en charge comme suit :
-
EnumType => StringType -
FixedType => BinaryType -
UnionType => StructType
-
-
Si vous définissez le schéma de table à l'aide de la page Define a schema (Définir un schéma) dans la console, le type de l'élément racine implicite pour le schéma est
record. Si vous voulez un type d'élément racine autre querecord, par exemple,arrayoumap, vous ne pouvez pas spécifier le schéma à l'aide de la page Define a schema (Définir un schéma). Au lieu de cela, vous devez ignorer cette page et spécifier le schéma en tant que propriété de table ou dans le script ETL.-
Pour spécifier le schéma dans les propriétés de la table, complétez l'assistant de création de table, modifiez les détails de la table et ajoutez une nouvelle paire clé-valeur sous Table properties (Propriétés de la table). Utilisez la clé
avroSchemaet saisissez un objet de schéma JSON pour la valeur, comme illustré dans la capture d'écran suivante.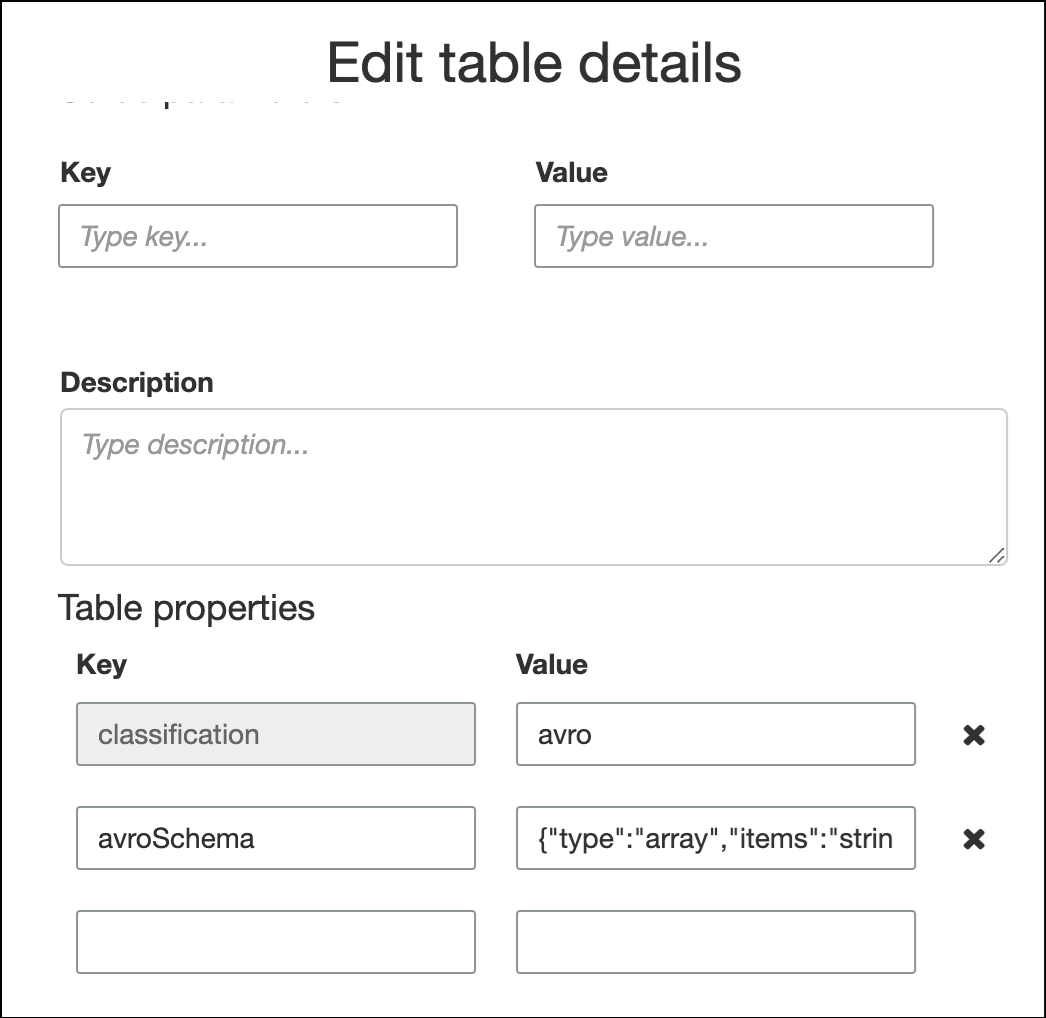
-
Pour spécifier le schéma dans le script ETL, modifiez l'instruction d'affectation
datasource0et ajoutez la cléavroSchemaà l'argumentadditional_options, comme indiqué dans les exemples Python et Scala suivants.SCHEMA_STRING = ‘{"type":"array","items":"string"}’ datasource0 = glueContext.create_data_frame.from_catalog(database = "database", table_name = "table_name", transformation_ctx = "datasource0", additional_options = {"startingPosition": "TRIM_HORIZON", "inferSchema": "false", "avroSchema": SCHEMA_STRING})
-
Application de modèles Grok à des sources de streaming
Vous pouvez créer une tâche ETL en streaming pour une source de données de journalisation et utiliser des modèles Grok pour convertir les journaux en données structurées. La tâche ETL traite ensuite les données en tant que source de données structurée. Vous spécifiez les modèles Grok à appliquer lorsque vous créez la table du catalogue de données pour la source en streaming.
Pour plus d'informations sur les modèles Grok et les valeurs de chaînes de modèle personnalisées, veuillez consulter Écriture de classifieurs personnalisés Grok.
Pour ajouter des modèles Grok au tableau du catalogue de données (console)
-
Utilisez l'assistant de création de table et créez la table avec les paramètres spécifiés dans Création d'un tableau de catalogue de données pour une source en streaming. Spécifiez le format de données en tant que Grok, remplissez le champ Grok pattern (Modèle Grok), et éventuellement ajouter des modèles personnalisés sous Custom patterns (optional) (Modèles personnalisés – facultatif).
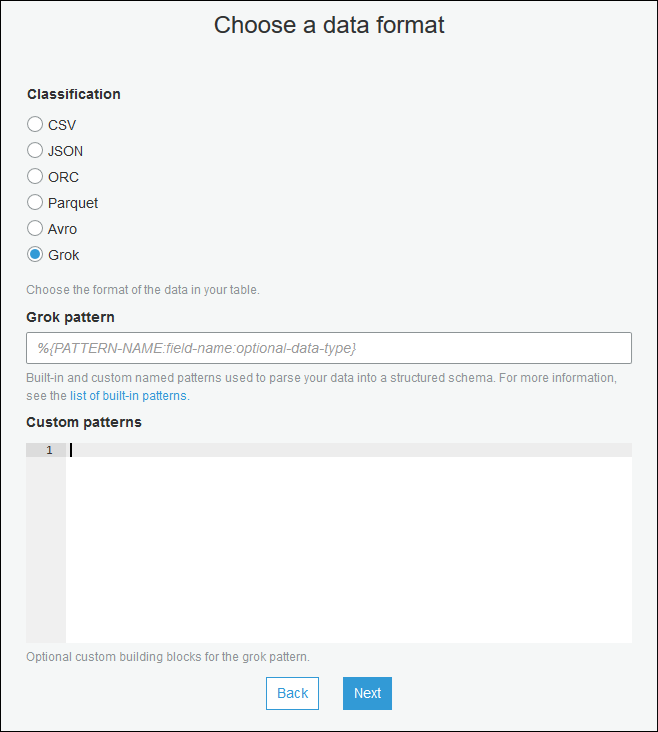
Appuyez sur Entrée après chaque modèle personnalisé.
Pour ajouter des modèles de grok à la table du catalogue de données (AWS Glue API AWS CLI(ou)
-
Ajoutez le paramètre
GrokPatternet, éventuellement, le paramètreCustomPatternsà l'opération d'APICreateTableou à la commandecreate_tablede la CLI."Parameters": { ... "grokPattern": "string", "grokCustomPatterns": "string", ... },Formulez
grokCustomPatternsen tant que chaîne et utilisez « \n » comme séparateur entre les motifs.Voici un exemple de ces paramètres dans un fichier.
"parameters": { ... "grokPattern": "%{USERNAME:username} %{DIGIT:digit:int}", "grokCustomPatterns": "digit \d", ... }
Définition des propriétés de tâche pour une tâche ETL en streaming
Lorsque vous définissez une tâche ETL de streaming dans AWS Glue console, fournissez les propriétés spécifiques aux flux suivantes. Pour obtenir la description d'autres propriétés de la tâche, consulter Définition des propriétés des tâches Spark.
- Rôle IAM
-
Spécifiez le rôle AWS Identity and Access Management (IAM) utilisé pour autoriser les ressources utilisées pour exécuter la tâche, accéder aux sources de streaming et accéder aux magasins de données cibles.
Pour accéder à Amazon Kinesis Data Streams, associez
AmazonKinesisFullAccessAWS la politique gérée au rôle ou associez une politique IAM similaire qui permet un accès plus précis. Pour obtenir des exemples de stratégies, consultez Controlling Access to Amazon Kinesis Data Streams Resources Using IAM (Contrôle de l'accès aux ressources Amazon Kinesis Data Streams à l'aide d'IAM).Pour plus d'informations sur les autorisations relatives à l'exécution de tâches dans AWS Glue, voir Gestion des identités et des accès pour AWS Glue.
- Type
-
Choisissez Spark Streaming.
- AWS Glue version
-
Le AWS Glue version détermine les versions d'Apache Spark, de Python ou de Scala disponibles pour la tâche. Choisissez une sélection qui indique la version de Python ou de Scala disponible pour la tâche. AWS Glue version 2.0 avec prise en charge de Python 3 est la valeur par défaut pour les tâches ETL en streaming.
- Fenêtre de maintenance
-
Spécifie une fenêtre dans laquelle une tâche de streaming peut être redémarrée. Consultez Fenêtres de maintenance pour le AWS Glue streaming.
- Délai d'expiration de la tâche
-
Vous pouvez saisir une durée en minutes. La valeur par défaut est vide.
Les tâches de streaming doivent avoir un délai d'expiration inférieur à 7 jours ou 10080 minutes.
Lorsque la valeur est laissée vide, la tâche sera redémarrée au bout de 7 jours, si vous n'avez pas défini de fenêtre de maintenance. Si vous avez défini une fenêtre de maintenance, la tâche sera redémarrée pendant la fenêtre de maintenance au bout de 7 jours.
- Source de données
-
Spécifiez la table que vous avez créée dans Création d'un tableau de catalogue de données pour une source en streaming.
- Cible de données
-
Effectuez l’une des actions suivantes :
-
Choisissez Create tables in your data target (Créer des tables dans votre cible de données) et spécifiez les propriétés de cible de données suivantes.
- Banque de données
-
Choisissez Amazon S3 ou JDBC.
- Format
-
Choisissez n'importe quel format. Tous sont pris en charge pour le streaming.
-
Choisissez Use tables in the data catalog and update your data target (Utiliser les tables du catalogue de données et mettre à jour votre cible de données) et choisissez une table pour un magasin de données JDBC.
-
- Définition du schéma en sortie
-
Effectuez l’une des actions suivantes :
-
Choisissez Détecter automatiquement le schéma de chaque enregistrement pour activer la détection du schéma. AWS Glue détermine le schéma à partir des données de streaming.
-
Choisissez Specify output schema for all records (Spécifier le schéma de sortie pour tous les enregistrements) pour utiliser la transformation Apply Mapping (Appliquer le mappage) pour définir le schéma en sortie.
-
- Script
-
Vous pouvez également fournir votre propre script ou modifier le script généré pour effectuer des opérations prises en charge par le moteur Apache Spark Structured Streaming. Pour plus d'informations sur les opérations disponibles, consultez la section Opérations sur le DataFrames streaming/Datasets
.
Restrictions et notes sur ETL en streaming
Gardez à l'esprit les notes et restrictions suivantes :
-
Décompression automatique pour AWS Glue les tâches ETL en streaming ne sont disponibles que pour les types de compression pris en charge. Veuillez prendre en compte les points suivants :
Le format Framed Snappy fait référence au format de trame
officiel pour Snappy. L'algorithme Deflate est pris en charge dans la version 3.0 de Glue et non dans la version 2.0.
-
Lorsque vous utilisez la détection de schéma, vous ne pouvez pas effectuer de jointures de données en streaming.
-
AWS Glue les tâches ETL en streaming ne prennent pas en charge le type de données Union pour AWS Glue Registre de schémas au format Avro.
-
Votre script ETL peut utiliser AWS Glueet les transformations intégrées à Apache Spark Structured Streaming. Pour plus d'informations, voir Opérations sur le DataFrames streaming/Datasets
sur le site Web d'Apache Spark ou. AWS Glue PySpark transforme la référence -
AWS Glue les tâches ETL en streaming utilisent des points de contrôle pour suivre les données lues. Par conséquent, une tâche arrêtée et redémarrée reprend là où elle s'est arrêtée dans le flux. Si vous souhaitez retraiter les données, vous pouvez supprimer le dossier du point de contrôle référencé dans le script.
-
Les signets de tâche ne sont pas pris en charge.
-
Pour utiliser la fonctionnalité de diffusion améliorée de Kinesis Data Streams dans tâche, consultez Utilisation de la diffusion améliorée dans les tâches de streaming Kinesis.
-
Si vous utilisez une table de catalogue de données créée à partir de AWS Glue Registre des schémas, lorsqu'une nouvelle version de schéma est disponible, pour refléter le nouveau schéma, vous devez effectuer les opérations suivantes :
-
Arrêtez les tâches associées à la table.
-
Mettez à jour le schéma de la table Catalogue de données.
-
Redémarrez les tâches associées à la table.
-
