Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Même si l'exécution d'un robot est la méthode recommandée pour inventorier les données de vos magasins de données, vous pouvez y ajouter des tables de métadonnées AWS Glue Data Catalog manuellement. Cette approche vous permet de mieux contrôler les définitions des métadonnées et de les personnaliser en fonction de vos besoins spécifiques.
Vous pouvez également ajouter des tables au catalogue de données manuellement de la manière suivante :
-
Utilisez la commande AWS Glue console pour créer manuellement une table dans le AWS Glue Data Catalog. Pour de plus amples informations, veuillez consulter Création de tables à l'aide de la console.
-
Utilisez l'opération
CreateTablede l'AWS Glue API pour créer une table dans le AWS Glue Data Catalog. Pour de plus amples informations, veuillez consulter CreateTable action (Python : créer_table). -
Utilisez AWS CloudFormation des modèles. Pour de plus amples informations, veuillez consulter AWS CloudFormation pour AWS Glue.
Lorsque vous définissez une table manuellement à l'aide de la console ou d’une API, vous spécifiez le schéma de table et la valeur d'un champ de classification qui indique le type et le format des données de la source de données. Si un crawler crée la table, le format et le schéma des données sont déterminés par un classifieur intégré ou un classifieur personnalisé. Pour plus d'informations sur la création d'une table à l'aide du AWS Glue console, voirCréation de tables à l'aide de la console.
Rubriques
Partitions de table
Un AWS Glue La définition d'un dossier Amazon Simple Storage Service (Amazon S3) peut décrire une table partitionnée. Par exemple, pour améliorer la performance des requêtes, une table partitionnée peut séparer les données mensuelles dans différents fichiers en utilisant le nom du mois en tant que clé. Entrée AWS Glue, les définitions de table incluent la clé de partitionnement d'une table. Lorsque AWS Glue évalue les données contenues dans les dossiers Amazon S3 pour cataloguer une table, il détermine si une table individuelle ou partitionnée est ajoutée.
Vous pouvez créer des index de partition sur une table pour récupérer un sous-ensemble des partitions au lieu de charger toutes les partitions de la table. Pour en savoir plus sur l'utilisation des index de partition, consultez Création d'index de partition .
Toutes les conditions suivantes doivent être remplies pour AWS Glue pour créer une table partitionnée pour un dossier Amazon S3 :
-
Les schémas des fichiers sont similaires, tels que déterminés par AWS Glue.
-
Le format de données des fichiers est le même.
-
Le format de compression des fichiers est le même.
Par exemple, imaginons que vous possédez un compartiment Amazon S3 nommé my-app-bucket, où vous stockez des données de vente d'applications iOS et Android. Les données sont partitionnées par année, mois et jour. Les fichiers de données pour les ventes iOS et Android ont le même schéma, format de données et format de compression. Dans le AWS Glue Data Catalog, le AWS Glue crawler crée une définition de table avec des clés de partitionnement pour l'année, le mois et le jour.
La liste Amazon S3 my-app-bucket suivante présente certaines partitions. Le symbole = est utilisé pour attribuer des valeurs de clé de partition.
my-app-bucket/Sales/year=2010/month=feb/day=1/iOS.csv
my-app-bucket/Sales/year=2010/month=feb/day=1/Android.csv
my-app-bucket/Sales/year=2010/month=feb/day=2/iOS.csv
my-app-bucket/Sales/year=2010/month=feb/day=2/Android.csv
...
my-app-bucket/Sales/year=2017/month=feb/day=4/iOS.csv
my-app-bucket/Sales/year=2017/month=feb/day=4/Android.csv
Liens de ressources de table
| Le AWS Glue la console a été récemment mise à jour. La version actuelle de la console ne prend pas en charge les liens de ressources de table. |
Le catalogue de données peut également contenir des liens de ressources vers des tables. Un lien de ressource de table est un lien vers une table locale ou partagée. Actuellement, vous ne pouvez créer des liens de ressources que dans AWS Lake Formation. Après avoir créé un lien de ressource vers une table, vous pouvez utiliser le nom du lien de ressource partout où vous utiliseriez le nom de la table. Outre les tables que vous possédez ou qui sont partagées avec vous, les liens vers les ressources des tables sont renvoyés glue:GetTables() et apparaissent sous forme d'entrées sur la page Tables du AWS Glue console.
Le catalogue de données peut également contenir des liens de ressources de base de données.
Pour plus d'informations sur les liens de ressources, veuillez consulter la rubrique Création de liens de ressources dans le Guide du développeur AWS Lake Formation .
Création de tables à l'aide de la console
Un tableau figurant dans le AWS Glue Data Catalog est la définition des métadonnées qui représente les données d'un magasin de données. Vous créez des tables lorsque vous exécutez un crawler ; vous pouvez aussi créer une table manuellement dans la console AWS Glue . La liste des tables dans le AWS Glue la console affiche les valeurs des métadonnées de votre table. Les définitions de table vous permettent de spécifier des sources et des cibles lors de la création de tâches ETL (extraction, transformation et chargement).
Note
Avec les récentes modifications apportées à la console de AWS gestion, vous devrez peut-être modifier vos rôles IAM existants pour SearchTablesobtenir l'autorisation. Pour la création de nouveaux rôles, l'autorisation d'API SearchTables a déjà été ajoutée par défaut.
Pour commencer, connectez-vous au AWS Management Console et ouvrez le AWS Glue console à https://console.aws.amazon.com/glue/
Ajout de tableaux sur la console
Pour utiliser un crawler afin d'ajouter des tables, choisissez Add tables (Ajouter des tables), puis Add tables using a crawler (Ajouter des tables à l'aide d'un crawler). Ensuite, suivez les instructions fournies dans l'assistant Add crawler (Ajouter un crawler). Une fois que l'crawler s'exécute, les tables sont ajoutées à l' AWS Glue Data Catalog. Pour de plus amples informations, veuillez consulter Utilisation de robots d'exploration pour alimenter le catalogue de données .
Si vous connaissez les attributs requis pour créer une définition de table Amazon Simple Storage Service (Amazon S3) dans votre Data Catalog, vous pouvez la créer avec l'assistant de table. Choisissez Add tables (Ajouter des tables), Add table manually (Ajouter une table manuellement), et suivez les instructions fournies dans l'assistant Add table (Ajouter une table).
Lors de l'ajout manuel d'une table à l'aide de la console, tenez compte des points suivants :
-
Si vous prévoyez d'accéder à la table depuis Amazon Athena, fournissez un nom contenant uniquement des caractères alphanumériques et des traits de soulignement. Pour plus d'informations, consultez Noms Athena.
-
L'emplacement de vos données sources doit être un chemin d'accès Amazon S3.
-
Le format des données doit correspondre à l'un des formats répertoriés dans l'assistant. La classification correspondante et SerDe les autres propriétés du tableau sont automatiquement renseignées en fonction du format choisi. Vous pouvez définir des tables aux formats suivants :
- Avro
-
Format binaire JSON Apache Avro.
- CSV
-
Valeurs séparées par des caractères. Vous pouvez également spécifier comme délimiteur une virgule, une barre verticale, un point-virgule, une tabulation ou Ctrl-A.
- JSON
-
JavaScript Notation d'objets.
- xml
-
Format XML (Extensible Markup Language). Spécifiez la balise XML qui définit une ligne dans les données. Les colonnes sont définies dans les balises de ligne.
- Parquet
-
Stockage en colonnes Apache Parquet.
- ORC
-
Format de fichier Optimized Row Columnar (ORC). Un format conçu pour stocker efficacement les données Hive.
-
Vous pouvez définir une clé de partition pour la table.
-
Actuellement, les tables partitionnées que vous créez avec la console ne peuvent pas être utilisées dans les tâches ETL.
Attributs des tables
Les attributs suivants font partie des plus importants de votre table :
- Nom
-
Le nom est déterminé lorsque la table est créée, et vous ne pouvez pas le modifier. Vous faites référence à un nom de table dans de nombreux AWS Glue opérations.
- Base de données
-
Objet conteneur dans lequel se trouve votre table. Cet objet contient une organisation de vos tables qui existe au sein de votre magasin de données AWS Glue Data Catalog et qui peut être différente de celle-ci. Lorsque vous supprimez une base de données, toutes les tables que celle-ci contient sont également supprimées de Data Catalog.
- Description
-
Description de la table. Vous pouvez écrire une description vous aidant à comprendre le contenu de la table.
- Format de table
-
Spécifiez la création d'une AWS Glue table standard ou d'une table au format Apache Iceberg.
Le catalogue de données fournit les options d'optimisation des tables suivantes pour gérer le stockage des tables et améliorer les performances des requêtes pour les tables Iceberg.
-
Compaction : les fichiers de données sont fusionnés et réécrits pour supprimer les données obsolètes et consolider les données fragmentées dans des fichiers plus volumineux et plus efficaces.
Conservation des instantanés : les instantanés sont des versions horodatées d'une table Iceberg. Les configurations de conservation des instantanés permettent aux clients de définir la durée de conservation des instantanés et le nombre d'instantanés à conserver. La configuration d'un optimiseur de conservation des instantanés peut aider à gérer la charge de stockage en supprimant les anciens instantanés inutiles et leurs fichiers sous-jacents associés.
Suppression de fichiers orphelins — Les fichiers orphelins sont des fichiers qui ne sont plus référencés par les métadonnées de la table Iceberg. Ces fichiers peuvent s'accumuler au fil du temps, en particulier après des opérations telles que la suppression de tables ou l'échec de tâches ETL. L'activation de la suppression des fichiers orphelins permet AWS Glue d'identifier et de supprimer périodiquement ces fichiers inutiles, libérant ainsi de l'espace de stockage.
Pour de plus amples informations, veuillez consulter Optimisation des tables Iceberg.
-
- Configuration d'optimisation
Vous pouvez utiliser les paramètres par défaut ou personnaliser les paramètres pour activer les optimiseurs de table.
- Rôle IAM
Pour exécuter les optimiseurs de table, le service assume un rôle IAM en votre nom. Vous pouvez choisir un rôle IAM à l'aide de la liste déroulante. Assurez-vous que le rôle dispose des autorisations requises pour activer le compactage.
Pour en savoir plus sur les autorisations requises pour le rôle IAM, consultez Conditions préalables requises pour l'optimisation des tables .
- Emplacement
-
Pointeur de l'emplacement des données dans un magasin de données que cette définition de table représente.
- Classification
-
Valeur de catégorie fournie lors de la création de la table. En général, elle est écrite lors de l'exécution d'un crawler et spécifie le format de la source des données.
- Dernière mise à jour
-
Date et heure (UTC) auxquelles cette table a été mise à jour dans Data Catalog.
- Date ajoutée
-
Date et heure (UTC) auxquelles cette table a été ajoutée dans Data Catalog.
- Obsolète
-
If AWS Glue découvre qu'une table du catalogue de données n'existe plus dans son magasin de données d'origine, il la marque comme obsolète dans le catalogue de données. Si vous exécutez une tâche qui fait référence à une table obsolète, la tâche peut échouer. Modifiez les tâches qui font référence à des tables obsolètes pour les supprimer en tant que sources et cibles. Nous vous recommandons de supprimer les tables obsolètes lorsqu'ils ne sont plus nécessaires.
- Connexion
-
If AWS Glue nécessite une connexion à votre banque de données, le nom de la connexion est associé à la table.
Afficher et gérer les détails des tables
Pour afficher les détails d'une table existante, choisissez le nom de la table dans la liste, puis Action, View details (Action, Afficher les détails).
Les détails de la table comprennent les propriétés de votre table et son schéma. Cette vue affiche le schéma de la table, y compris les noms de colonnes dans l'ordre défini pour la table, les types de données et les colonnes de clés pour les partitions. Si une colonne est de type complexe, vous pouvez choisir View properties (Afficher les propriétés) pour afficher les détails de la structure de ce champ, comme illustré dans l'exemple suivant :
{
"StorageDescriptor":
{
"cols": {
"FieldSchema": [
{
"name": "primary-1",
"type": "CHAR",
"comment": ""
},
{
"name": "second ",
"type": "STRING",
"comment": ""
}
]
},
"location": "s3://aws-logs-111122223333-us-east-1",
"inputFormat": "",
"outputFormat": "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat",
"compressed": "false",
"numBuckets": "0",
"SerDeInfo": {
"name": "",
"serializationLib": "org.apache.hadoop.hive.serde2.OpenCSVSerde",
"parameters": {
"separatorChar": "|"
}
},
"bucketCols": [],
"sortCols": [],
"parameters": {},
"SkewedInfo": {},
"storedAsSubDirectories": "false"
},
"parameters": {
"classification": "csv"
}
}Pour plus d'informations sur les propriétés d'une table, comme StorageDescriptor, consultez StorageDescriptor structure.
Pour modifier le schéma d'une table, choisissez Edit schema (Modifier le schéma) pour ajouter et supprimer des colonnes, modifier les noms de colonnes et modifier les types de données.
Pour comparer différentes versions d'une table, y compris son schéma, choisissez Comparer les versions pour voir une side-by-side comparaison des deux versions du schéma d'une table. Pour de plus amples informations, veuillez consulter Comparaison des versions de schéma de table .
Pour afficher les fichiers qui constituent une partition Amazon S3, sélectionnez View partition (Afficher la partition). Pour les tables Amazon S3, la colonne Key (Clé) affiche les clés de partition qui sont utilisées pour partitionner la table dans le magasin de données source. Le partitionnement permet de diviser une table en parties connexes en fonction des valeurs d'une colonne de clés, telles que la date, l'emplacement ou un service. Pour plus d'informations sur les partitions, effectuez une recherche sur Internet pour en savoir plus sur « le partitionnement Hive ».
Note
Pour obtenir step-by-step des conseils sur l'affichage des détails d'un tableau, consultez le didacticiel Explore le tableau dans la console.
Comparaison des versions de schéma de table
Lorsque vous comparez deux versions de schémas de table, vous pouvez comparer les modifications des lignes imbriquées en développant et en réduisant les lignes imbriquées, comparer les schémas de deux versions et afficher les side-by-side propriétés des tables. side-by-side
Pour comparer les versions
-
À partir du AWS Glue console, choisissez Tables, puis Actions et sélectionnez Comparer les versions.
-
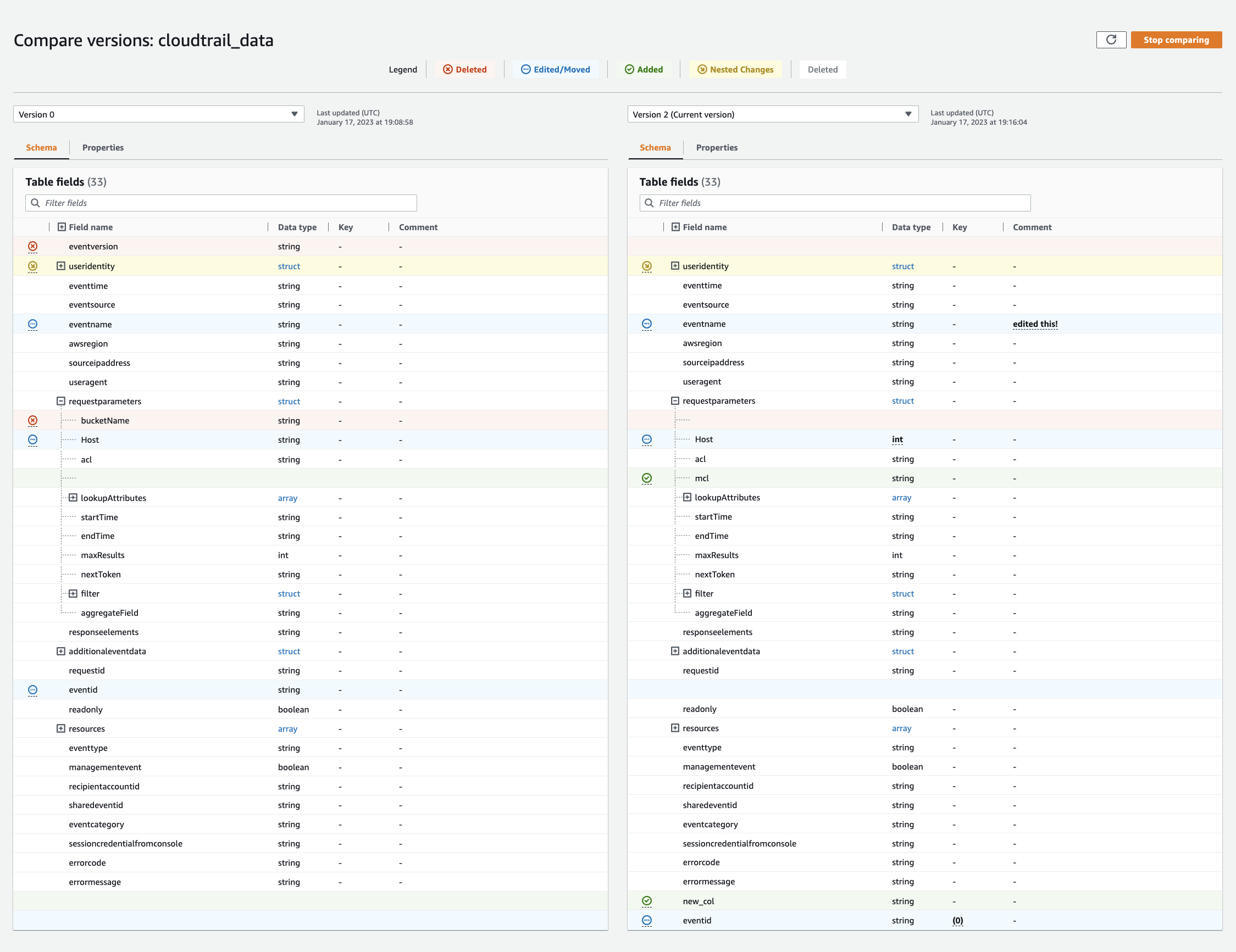
Choisissez une version à comparer en sélectionnant le menu déroulant des versions. Lorsque vous comparez des schémas, l'onglet Schéma est surligné en orange.
-
Lorsque vous comparez des tables entre deux versions, les schémas des tables s'affichent à gauche et à droite de l'écran. Cela vous permet de déterminer visuellement les modifications en comparant le nom de colonne, le type de données, la clé et les champs de commentaire side-by-side. En cas de modification, une icône colorée indique le type de modification apportée.
-
Supprimé : représenté par une icône rouge, indique l'endroit où la colonne a été supprimée d'une version précédente du schéma de table.
-
Modifié ou déplacé : représenté par une icône bleue, indique l'endroit où la colonne a été modifiée ou déplacée dans une version plus récente du schéma de table.
-
Ajouté : représenté par une icône verte, indique l'endroit où la colonne a été ajoutée à une version plus récente du schéma de table.
-
Modifications imbriquées : représentées par une icône jaune, indiquent où se trouvent les modifications dans la colonne imbriquée. Choisissez la colonne à développer et affichez les colonnes qui ont été supprimées, modifiées, déplacées ou ajoutées.
-
-
Utilisez la barre de recherche des champs de filtre pour afficher les champs en fonction des caractères que vous saisissez ici. Si vous saisissez un nom de colonne dans l'une ou l'autre des versions de table, les champs filtrés s'affichent dans les deux versions de la table pour vous indiquer l'emplacement des modifications.
-
Pour comparer les propriétés, cliquez sur l'onglet Propriétés.
-
Pour arrêter la comparaison des versions, choisissez Arrêter la comparaison pour revenir à la liste des tables.
Mise à jour de tables Data Catalog créées manuellement à l’aide d’crawlers
Vous souhaiterez peut-être créer des AWS Glue Data Catalog tables manuellement, puis les mettre à jour avec AWS Glue chenilles. Les crawlers respectant un calendrier peuvent ajouter de nouvelles partitions et mettre à jour les tables avec des modifications de schéma. Cela s'applique également aux tables migrées depuis un métastore Apache Hive.
Pour ce faire, lorsque vous définissez un crawler, au lieu de spécifier un ou plusieurs magasins de données en tant que source d'une analyse, vous spécifiez une ou plusieurs tables Data Catalog existantes. L'crawler analyse ensuite les magasins de données spécifiés par les tables du catalogue. Dans ce cas, aucune nouvelle table n’est créée ; au lieu de cela, vos tables créées manuellement sont mises à jour.
Voici d'autres raisons qui peuvent vous amener à vouloir créer manuellement des tables de catalogue et spécifier les tables de catalogue en tant qu'crawler source :
-
Vous voulez choisir le nom de la table de catalogue et de ne pas vous fier à l'algorithme d'attribution de noms de la table de catalogue.
-
Vous souhaitez empêcher de nouvelles tables d'être créées au cas où des fichiers dont le format pourrait perturber la détection de partition soient enregistrés par erreur dans le chemin de la source de données.
Pour de plus amples informations, veuillez consulter Étape 2 : Choisir des sources de données et des classificateurs..
Propriétés de la table Catalogue de données
Les propriétés de table, ou paramètres, comme on les appelle dans la AWS CLI, sont des chaînes de clés et de valeurs non validées. Vous pouvez définir vos propres propriétés sur la table pour prendre en charge les utilisations du Catalogue de données en dehors d' AWS Glue. D'autres services utilisant le catalogue de données peuvent également le faire. AWS Glue définit certaines propriétés de table lors de l'exécution de jobs ou de robots d'exploration. Sauf indication contraire, ces propriétés sont destinées à un usage interne. Nous ne garantissons pas le fait qu'elles continueront d'exister sous leur forme actuelle, et nous ne garantissons pas le comportement du produit si ces propriétés sont modifiées manuellement.
Pour plus d'informations sur les propriétés de table définies par AWS Glue les robots d'exploration, consultezParamètres définis sur les tables du Catalogue de données par un Crawler.
