Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Le langage DQDL (Data Quality Definition Language) est un langage spécifique au domaine que vous utilisez pour définir des règles pour AWS Glue Data Quality.
Ce guide présente les concepts clés de DQDL pour vous aider à vous familiariser avec ce langage. Il fournit également une référence pour les types de règles DQDL, avec syntaxe et exemples. Avant d'utiliser ce guide, nous vous recommandons de vous familiariser avec AWS Glue Data Quality. Pour de plus amples informations, veuillez consulter AWS Glue Qualité des données.
Note
DynamicRules ne sont pris en charge que dans AWS Glue ETL.
Table des matières
Syntaxe DQDL
Un document DQDL est sensible à la casse et contient un jeu de règles, qui regroupe les règles individuelles de qualité des données. Pour construire un jeu de règles, vous devez créer une liste nommée Rules (en majuscules), délimitée par une paire de crochets. La liste doit contenir une ou plusieurs règles DQDL séparées par des virgules, comme dans l'exemple suivant.
Rules = [
IsComplete "order-id",
IsUnique "order-id"
]Structure des règles
La structure d'une règle DQDL dépend du type de la règle. Toutefois, les règles DQDL respectent généralement le format suivant.
<RuleType> <Parameter> <Parameter> <Expression>
RuleType est le nom sensible à la casse du type de règle que vous souhaitez configurer. Par exemple, IsComplete, IsUnique ou CustomSql. Les paramètres varient en fonction du type de règle. Pour obtenir une référence complète des types de règles DQDL et de leurs paramètres, consultez Référence du type de règle DQDL.
Règles composites
DQDL prend en charge les opérateurs logiques suivants que vous pouvez utiliser pour combiner des règles. Ces règles sont appelées règles composites.
- and
-
L'opérateur logique
andgénèretruesi et seulement si les règles qu'il connecte sonttrue. Sinon, la règle combinée génèrefalse. Chaque règle que vous connectez à l'opérateuranddoit être entourée de parenthèses.L'exemple suivant utilise l'opérateur
andpour combiner deux règles DQDL.(IsComplete "id") and (IsUnique "id") - or
-
L'opérateur logique
orgénèretruesi et seulement si une ou plusieurs des règles qu'il connecte sonttrue. Chaque règle que vous connectez à l'opérateurordoit être entourée de parenthèses.L'exemple suivant utilise l'opérateur
orpour combiner deux règles DQDL.(RowCount "id" > 100) or (IsPrimaryKey "id")
Le même opérateur peut être utilisé pour connecter plusieurs règles. La combinaison de règles suivante est donc autorisée.
(Mean "Star_Rating" > 3) and (Mean "Order_Total" > 500) and (IsComplete "Order_Id")Vous pouvez combiner les opérateurs logiques en une seule expression. Par exemple :
(Mean "Star_Rating" > 3) and ((Mean "Order_Total" > 500) or (IsComplete "Order_Id"))Vous pouvez également créer des règles imbriquées plus complexes.
(RowCount > 0) or ((IsComplete "colA") and (IsUnique "colA"))Comment fonctionnent les règles composites
Par défaut, les règles composites sont évaluées en tant que règles individuelles pour l'ensemble de données ou de la table, puis les résultats sont combinés. En d'autres termes, il évalue d'abord l'ensemble de la colonne, puis applique l'opérateur. Ce comportement par défaut est expliqué ci-dessous à l'aide d'un exemple :
# Dataset
+------+------+
|myCol1|myCol2|
+------+------+
| 2| 1|
| 0| 3|
+------+------+
# Overall outcome
+----------------------------------------------------------+-------+
|Rule |Outcome|
+----------------------------------------------------------+-------+
|(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)|Failed |
+----------------------------------------------------------+-------+
Dans l'exemple ci-dessus, AWS Glue Data Quality évalue d'abord (ColumnValues "myCol1" > 1) ce qui entraînera un échec. Ensuite, il évaluera (ColumnValues "myCol2" > 2) ce qui échouera également. La combinaison des deux résultats sera considérée comme un échec.
Toutefois, si vous préférez un comportement de type SQL, dans lequel vous devez évaluer la ligne entière, vous devez définir explicitement le ruleEvaluation.scope paramètre comme indiqué additionalOptions dans l'extrait de code ci-dessous.
object GlueApp {
val datasource = glueContext.getCatalogSource(
database="<db>",
tableName="<table>",
transformationContext="datasource"
).getDynamicFrame()
val ruleset = """
Rules = [
(ColumnValues "age" >= 26) OR (ColumnLength "name" >= 4)
]
"""
val dq_results = EvaluateDataQuality.processRows(
frame=datasource,
ruleset=ruleset,
additionalOptions=JsonOptions("""
{
"compositeRuleEvaluation.method":"ROW"
}
"""
)
)
}
Dans AWS Glue Data Catalog, vous pouvez facilement configurer cette option dans l'interface utilisateur, comme indiqué ci-dessous.
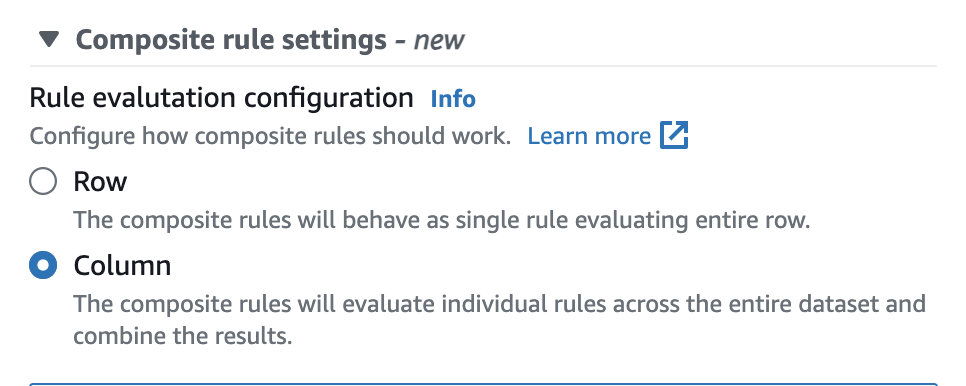
Une fois définies, les règles composites se comporteront comme une règle unique évaluant la ligne entière. L'exemple suivant illustre ce comportement.
# Row Level outcome
+------+------+------------------------------------------------------------+---------------------------+
|myCol1|myCol2|DataQualityRulesPass |DataQualityEvaluationResult|
+------+------+------------------------------------------------------------+---------------------------+
|2 |1 |[(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)]|Passed |
|0 |3 |[(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)]|Passed |
+------+------+------------------------------------------------------------+---------------------------+
Certaines règles ne peuvent pas être prises en charge dans cette fonctionnalité car leur résultat global repose sur des seuils ou des ratios. Ils sont listés ci-dessous.
Règles basées sur les ratios :
-
Intégralité
-
DatasetMatch
-
ReferentialIntegrity
-
Unicité
Règles dépendantes des seuils :
Lorsque les règles suivantes sont incluses dans un seuil, elles ne sont pas prises en charge. Cependant, les règles qui n'impliquent pas with threshold restent prises en charge.
-
ColumnDataType
-
ColumnValues
-
CustomSQL
Expressions
Si un type de règle ne produit pas de réponse booléenne, vous devez fournir une expression en tant que paramètre afin de créer une réponse booléenne. Par exemple, la règle suivante vérifie la moyenne de toutes les valeurs d’une colonne par rapport à une expression afin de renvoyer un résultat vrai ou faux.
Mean "colA" between 80 and 100Certains types de règles tels que IsUnique et IsComplete renvoient déjà une réponse booléenne.
Le tableau suivant répertorie les expressions pouvant être utilisées dans les règles DQDL.
| Expression | Description | Exemple |
|---|---|---|
=x |
Correspond à true si la réponse du type de règle est égale àx. |
|
!=x
|
x devient vrai si la réponse du type de règle n'est pas égale àx. |
|
> x |
Correspond à true si la réponse du type de règle est supérieure àx. |
|
< x |
Correspond à true si la réponse du type de règle est inférieure àx. |
|
>= x |
Permet de déterminer true si la réponse du type de règle est supérieure ou égale àx. |
|
<= x |
Permet de déterminer true si la réponse du type de règle est inférieure ou égale àx. |
|
entre x et y |
Se traduit par true si la réponse du type de règle se situe dans une plage spécifiée (exclusif). Utilisez ce type d’expression uniquement pour les types numériques et date. |
|
pas entre x et y |
Prend la valeur true si la réponse du type de règle ne se situe pas dans une plage spécifiée (incluse). Vous ne devez utiliser ce type d'expression que pour les types numériques et les dates. |
|
dans [a, b, c, ...] |
Se traduit par true si la réponse du type de règle se trouve dans le jeu spécifié. |
|
pas dans [a, b, c, ...] |
Résout true si la réponse du type de règle ne se trouve pas dans l'ensemble spécifié. |
|
allumettes /ab+c/i |
Se traduit par true si la réponse du type de règle correspond à une expression régulière. |
|
ne correspond pas /ab+c/i |
Résout true si la réponse du type de règle ne correspond pas à une expression régulière. |
|
now() |
Fonctionne uniquement avec le type de règle ColumnValues pour créer une expression de date. |
|
matches/in […]/not matches/notdans [...] with threshold |
Spécifie le pourcentage de valeurs qui correspondent aux conditions de la règle. Fonctionne uniquement avec ColumnValues les types de CustomSQL règlesColumnDataType, et. |
|
Mots-clés pour NULL, EMPTY et WHITESPACES_ONLY
Si vous souhaitez vérifier si une colonne de chaîne contient une valeur nulle, vide ou une chaîne contenant uniquement des espaces, vous pouvez utiliser les mots clés suivants :
-
NULL/null — Ce mot clé prend la valeur true pour une
nullvaleur d'une colonne de chaîne.ColumnValues "colA" != NULL with threshold > 0.5renverrait vrai si plus de 50 % de vos données ne contiennent pas de valeurs nulles.(ColumnValues "colA" = NULL) or (ColumnLength "colA" > 5)renverrait vrai pour toutes les lignes qui ont une valeur nulle ou dont la longueur est supérieure à 5. Notez que cela nécessitera l'utilisation de l'option « compositeRuleEvaluation .method » = « ROW ». -
EMPTY/empty — Ce mot clé prend la valeur true pour une valeur de chaîne vide (« ») dans une colonne de chaînes. Certains formats de données transforment les valeurs nulles d'une colonne de chaînes en chaînes vides. Ce mot clé permet de filtrer les chaînes vides dans vos données.
(ColumnValues "colA" = EMPTY) or (ColumnValues "colA" in ["a", "b"])renverrait vrai si une ligne est vide, « a » ou « b ». Notez que cela nécessite l'utilisation de l'option « compositeRuleEvaluation .method » = « ROW ». -
WHITESPACES_ONLY/whitespaces_only — Ce mot clé prend la valeur true pour une chaîne contenant uniquement des espaces blancs (« ») dans une colonne de chaîne.
ColumnValues "colA" not in ["a", "b", WHITESPACES_ONLY]renverrait vrai si une ligne n'est ni « a », ni « b », ni simplement des espaces.Règles prises en charge :
Pour une expression numérique ou basée sur une date, si vous souhaitez vérifier si une colonne contient une valeur nulle, vous pouvez utiliser les mots clés suivants.
-
NULL/null — Ce mot clé prend la valeur true pour une valeur nulle dans une colonne de chaîne.
ColumnValues "colA" in [NULL, "2023-01-01"]renverrait vrai si une date de votre colonne est nulle2023-01-01ou nulle.(ColumnValues "colA" = NULL) or (ColumnValues "colA" between 1 and 9)renverrait vrai pour toutes les lignes qui ont une valeur nulle ou dont les valeurs sont comprises entre 1 et 9. Notez que cela nécessitera l'utilisation de l'option « compositeRuleEvaluation .method » = « ROW ».Règles prises en charge :
Filtrer avec la clause Where
Note
La clause Where n'est prise en charge que dans AWS Glue 4.0.
Vous pouvez filtrer vos données lorsque vous créez des règles. Cela est utile lorsque vous souhaitez appliquer des règles conditionnelles.
<DQDL Rule> where "<valid SparkSQL where clause> " Le filtre doit être spécifié avec le where mot clé, suivi d'une instruction SparkSQL valide entre guillemets. ("")
Si vous souhaitez ajouter la clause Where à une règle avec un seuil, la clause Where doit être spécifiée avant la condition de seuil.
<DQDL Rule> where "valid SparkSQL statement>" with threshold <threshold condition>
Avec cette syntaxe, vous pouvez écrire des règles comme les suivantes.
Completeness "colA" > 0.5 where "colB = 10"
ColumnValues "colB" in ["A", "B"] where "colC is not null" with threshold > 0.9
ColumnLength "colC" > 10 where "colD != Concat(colE, colF)" Nous allons vérifier que l'instruction SparkSQL fournie est valide. Si elle n'est pas valide, l'évaluation des règles échouera et nous lancerons IllegalArgumentException l'annonce au format suivant :
Rule <DQDL Rule> where "<invalid SparkSQL>" has provided an invalid where clause :
<SparkSQL Error>Comportement de la clause Where lorsque l'identification des enregistrements d'erreur au niveau des lignes est activée
Avec AWS Glue Data Quality, vous pouvez identifier les enregistrements spécifiques qui ont échoué. Lorsque vous appliquez une clause WHERE à des règles qui prennent en charge les résultats au niveau des lignes, nous étiquetons les lignes filtrées par la clause WHERE comme suitPassed.
Si vous préférez étiqueter séparément les lignes filtrées comme suitSKIPPED, vous pouvez définir les paramètres suivants additionalOptions pour la tâche ETL.
object GlueApp {
val datasource = glueContext.getCatalogSource(
database="<db>",
tableName="<table>",
transformationContext="datasource"
).getDynamicFrame()
val ruleset = """
Rules = [
IsComplete "att2" where "att1 = 'a'"
]
"""
val dq_results = EvaluateDataQuality.processRows(
frame=datasource,
ruleset=ruleset,
additionalOptions=JsonOptions("""
{
"rowLevelConfiguration.filteredRowLabel":"SKIPPED"
}
"""
)
)
}À titre d'exemple, reportez-vous à la règle et à la trame de données suivantes :
IsComplete att2 where "att1 = 'a'"| id | att1 | att2 | Résultats au niveau des lignes (par défaut) | Résultats au niveau des lignes (option ignorée) | Commentaires |
|---|---|---|---|---|---|
| 1 | a | f | PASSÉ | PASSÉ | |
| 2 | b | d | PASSÉ | SKIPPED | La ligne est filtrée, car elle ne l'att1est pas "a" |
| 3 | a | null | ÉCHEC | ÉCHEC | |
| 4 | a | f | PASSÉ | PASSÉ | |
| 5 | b | null | PASSÉ | SKIPPED | La ligne est filtrée, car elle ne l'att1est pas "a" |
| 6 | a | f | PASSÉ | PASSÉ |
Règles dynamiques
Note
Les règles dynamiques ne sont prises en charge que dans AWS Glue ETL et ne le sont pas dans AWS Glue Data Catalog.
Vous pouvez désormais créer des règles dynamiques pour comparer les métriques actuelles produites par vos règles avec leurs valeurs historiques. Ces comparaisons historiques sont rendues possibles en utilisant l’opérateur last() dans les expressions. Par exemple, la règle RowCount >
last() fonctionne lorsque le nombre de lignes de l’exécution en cours est supérieur au nombre de lignes précédent le plus récent pour le même jeu de données. last() prend un argument de nombre naturel facultatif décrivant le nombre de métriques précédentes à prendre en compte ; last(k) où k
>= 1 renvoyera aux dernières métriques k.
-
Si aucun point de données n’est disponible,
last(k)renverra la valeur par défaut 0,0. -
Si moins de
kmétriques sont disponibles,last(k)renverra toutes les métriques précédentes.
Pour former des expressions valides, utilisez last(k), où k > 1 nécessite une fonction d’agrégation pour réduire plusieurs résultats historiques en un seul nombre. Par exemple, RowCount > avg(last(5)) vérifiera si le nombre de lignes du jeu de données actuel est strictement supérieur à la moyenne des cinq dernières lignes du même jeu de données. RowCount > last(5) générera une erreur, car le nombre de lignes du jeu de données actuel ne peut pas être comparé de manière significative à une liste.
Fonctions d’agrégation prises en charge :
-
avg -
median -
max -
min -
sum -
std(écart-type) -
abs(valeur absolue) -
index(last(k), i)permet de sélectionner laie valeur la plus récente parmi les dernièresk.iest indexé à partir de zéro, doncindex(last(3), 0)renverra le point de données le plus récent etindex(last(3), 3)générera une erreur, car il n’y a que trois points de données et nous essayons d’indexer le 4e le plus récent.
Exemples d'expressions
ColumnCorrelation
ColumnCorrelation "colA" "colB" < avg(last(10))
DistinctValuesCount
DistinctValuesCount "colA" between min(last(10))-1 and max(last(10))+1
La plupart des types de règles comportant des conditions ou des seuils numériques prennent en charge les règles dynamiques. Consultez le tableau fourni, Analyseurs et règles pour vérifier si les règles dynamiques sont disponibles pour le type de règle que vous utilisez.
Exclure les statistiques des règles dynamiques
Vous devrez parfois exclure les statistiques de données de vos calculs de règles dynamiques. Supposons que vous ayez effectué un chargement de données historiques et que vous ne vouliez pas que cela ait un impact sur vos moyennes. Pour ce faire, ouvrez le job dans AWS Glue ETL et choisissez l'onglet Data Quality, puis sélectionnez Statistics et sélectionnez les statistiques que vous souhaitez exclure. Vous pourrez voir un graphique de tendance ainsi qu'un tableau de statistiques. Sélectionnez les valeurs que vous souhaitez exclure, puis choisissez Exclure les statistiques. Désormais, les statistiques exclues ne seront plus incluses dans les calculs de règles dynamiques.

Analyseurs
Note
Les analyseurs ne sont pas pris en charge dans AWS Glue Data Catalog.
Les règles DQDL utilisent des fonctions appelées analyseurs pour rassembler des informations sur vos données. Ces informations sont utilisées par l’expression booléenne d’une règle afin de décider si cette dernière doit être considérée comme réussie ou échouée. Par exemple, la RowCount règle RowCount > 5 utilisera un analyseur de nombre de lignes pour découvrir le nombre de lignes de votre ensemble de données et comparer ce nombre à l'expression > 5 pour vérifier s'il existe plus de cinq lignes dans le jeu de données actuel.
Il est parfois préférable, plutôt que de créer des règles, de créer des analyseurs et de les configurer pour qu’ils génèrent des statistiques utiles à la détection d’anomalies. Dans de tels cas, vous pouvez créer des analyseurs. Les analyseurs se distinguent des règles de la manière suivante.
| Caractéristiques | Analyseurs | Règles |
|---|---|---|
| Partie du jeu de règles | Oui | Oui |
| Génère des statistiques | Oui | Oui |
| Génère des observations | Oui | Oui |
| Peut évaluer et affirmer une condition | Non | Oui |
| Vous pouvez configurer des actions telles que l’arrêt des tâches en cas d’échec ou la poursuite du traitement des tâches | Non | Oui |
Les analyseurs peuvent exister indépendamment sans règles, vous offrant ainsi la possibilité de les configurer rapidement et de créer progressivement des règles de qualité des données.
Certains types de règles peuvent être saisis dans le bloc Analyzers de votre jeu de règles afin d’exécuter les règles nécessaires aux analyseurs et rassembler des informations sans avoir à valider une quelconque condition. Certains analyseurs ne sont pas associés à des règles et ne peuvent être saisis que dans le bloc Analyzers. Le tableau ci-dessous précise pour chaque élément s’il est pris en charge en tant que règle ou en tant qu’analyseur autonome, avec des informations supplémentaires pour chaque type de règle.
Exemple d'ensemble de règles avec analyseur
Le jeu de règles suivant utilise :
-
une règle dynamique permettant de vérifier si la croissance d’un jeu de données est supérieure à sa moyenne mobile au cours des trois dernières exécutions de tâches
-
un analyseur
DistinctValuesCountpermettant d’enregistrer le nombre de valeurs distinctes dans la colonneNamedu jeu de données -
un analyseur
ColumnLengthpermettant de suivre la tailleNameminimale et maximale au fil du temps
Les résultats des métriques de l’analyseur peuvent être consultés dans l’onglet Qualité des données de votre exécution de tâche.
Rules = [
RowCount > avg(last(3))
]
Analyzers = [
DistinctValuesCount "Name",
ColumnLength "Name"
]
AWS Glue Data Quality prend en charge les analyseurs suivants.
| Nom de l'analyseur | Fonctionnalité |
|---|---|
RowCount |
Calcule le nombre de lignes pour un ensemble de données |
Completeness |
Calcule le pourcentage de complétude d'une colonne |
Uniqueness |
Calcule le pourcentage d'unicité d'une colonne |
Mean |
Calcule la moyenne d'une colonne numérique |
Sum |
Calcule la somme d'une colonne numérique |
StandardDeviation |
Calcule l'écart type d'une colonne numérique |
Entropy |
Calcule l'entropie d'une colonne numérique |
DistinctValuesCount |
Calcule le nombre de valeurs distinctes dans une colonne |
UniqueValueRatio |
Calcule le ratio de valeurs uniques dans une colonne |
ColumnCount |
Calcule le nombre de colonnes d'un ensemble de données |
ColumnLength |
Calcule la longueur d'une colonne |
ColumnValues |
Calcule le minimum et le maximum pour les colonnes numériques. Calcule le minimum ColumnLength et le maximum ColumnLength pour les colonnes non numériques |
ColumnCorrelation |
Calcule les corrélations de colonnes pour des colonnes données |
CustomSql |
Calcule les statistiques renvoyées par le CustomSQL |
AllStatistics |
Calcule les statistiques suivantes :
|
Commentaires
Vous pouvez utiliser le caractère « # » pour ajouter un commentaire à votre document DQDL. Tout ce qui se trouve après le caractère « # » et jusqu'à la fin de la ligne est ignoré par DQDL.
Rules = [
# More items should generally mean a higher price, so correlation should be positive
ColumnCorrelation "price" "num_items" > 0
]