Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Vous pouvez utiliser l'interface utilisateur Web d'Apache Spark pour surveiller et déboguer AWS Glue Tâches ETL exécutées sur AWS Glue système de tâches, ainsi que les applications Spark exécutées sur AWS Glue points de terminaison du développement. L'interface utilisateur Spark vous permet de vérifier les éléments suivants pour chaque tâche :
-
La chronologie des événements de chaque phase Spark
-
Un graphe orienté acyclique (DAG) de la tâche
-
Les plans physiques et logiques des requêtes SparkSQL
-
Les variables environnementales Spark sous-jacentes pour chaque tâche
Pour plus d'informations sur l'utilisation de l'interface utilisateur web Spark, consultez l'Interface utilisateur web
Vous pouvez voir l'interface utilisateur de Spark dans la AWS Glue console. Ceci est disponible lorsqu'une AWS Glue tâche s'exécute sur des versions AWS Glue 3.0 ou ultérieures avec des journaux générés au format standard (plutôt qu'ancien), qui est le format par défaut pour les nouvelles tâches. Si vos fichiers journaux sont supérieurs à 0,5 Go, vous pouvez activer la prise en charge des journaux progressifs pour les exécutions de tâches sur les versions AWS Glue 4.0 ou ultérieures afin de simplifier l'archivage, l'analyse et le dépannage des journaux.
Vous pouvez activer l'interface utilisateur Spark à l'aide du AWS Glue console ou le AWS Command Line Interface (AWS CLI). Lorsque vous activez l'interface utilisateur Spark, AWS Glue Tâches ETL et applications Spark sur AWS Glue les points de terminaison de développement peuvent sauvegarder les journaux d'événements Spark à un emplacement que vous spécifiez dans Amazon Simple Storage Service (Amazon S3). Vous pouvez utiliser les journaux d’événements sauvegardés dans Amazon S3 avec l’interface utilisateur Spark à la fois en temps réel, lorsque la tâche est en cours de fonctionnement, et une fois celle-ci terminée. Tant que les journaux restent dans Amazon S3, l'interface utilisateur Spark de la AWS Glue console peut les consulter.
Autorisations
Pour utiliser l'interface utilisateur Spark dans la AWS Glue console, vous pouvez utiliser UseGlueStudio ou ajouter tous les services individuels APIs. Tous APIs sont nécessaires pour utiliser complètement l'interface utilisateur Spark, mais les utilisateurs peuvent accéder aux fonctionnalités de SparkUI en ajoutant son service APIs dans leur autorisation IAM pour un accès détaillé.
RequestLogParsingest le plus critique car il effectue l'analyse des journaux. Le reste APIs est destiné à la lecture des données analysées respectives. Permet par exemple d'GetStagesaccéder aux données relatives à toutes les étapes d'une tâche Spark.
La liste des services Spark UI APIs UseGlueStudio mappés se trouve ci-dessous dans l'exemple de politique. La politique ci-dessous permet d'utiliser uniquement les fonctionnalités de l'interface utilisateur de Spark. Pour ajouter d'autres autorisations, comme Amazon S3 et IAM, consultez la section Création de politiques IAM personnalisées pour. AWS Glue Studio
La liste des services Spark UI APIs mappés se UseGlueStudio trouve ci-dessous dans l'exemple de politique. Lorsque vous utilisez une API de service Spark UI, utilisez l'espace de noms suivant : glue:<ServiceAPI>
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowGlueStudioSparkUI",
"Effect": "Allow",
"Action": [
"glue:RequestLogParsing",
"glue:GetLogParsingStatus",
"glue:GetEnvironment",
"glue:GetJobs",
"glue:GetJob",
"glue:GetStage",
"glue:GetStages",
"glue:GetStageFiles",
"glue:BatchGetStageFiles",
"glue:GetStageAttempt",
"glue:GetStageAttemptTaskList",
"glue:GetStageAttemptTaskSummary",
"glue:GetExecutors",
"glue:GetExecutorsThreads",
"glue:GetStorage",
"glue:GetStorageUnit",
"glue:GetQueries",
"glue:GetQuery"
],
"Resource": [
"*"
]
}
]
}
Limites
-
L'interface utilisateur Spark de la AWS Glue console n'est pas disponible pour les exécutions de tâches effectuées avant le 20 novembre 2023 car elles sont dans l'ancien format de journal.
-
L'interface utilisateur Spark de la AWS Glue console prend en charge les journaux AWS Glue évolutifs pour la version 4.0, tels que ceux générés par défaut dans les tâches de streaming. La somme maximale de tous les fichiers d'événements enregistrés générés est de 2 Go. Pour les AWS Glue tâches ne prenant pas en charge les journaux cumulés, la taille maximale du fichier journal des événements pris en charge par SparkUI est de 0,5 Go.
-
L'interface utilisateur Spark sans serveur n'est pas disponible pour les journaux d'événements Spark stockés dans un compartiment Amazon S3 auquel seul votre VPC peut accéder.
Exemple : interface utilisateur web Apache Spark
Cet exemple vous montre comment utiliser l’interface utilisateur Spark pour comprendre vos performances pour la tâche. Les captures d’écran montrent l’interface utilisateur web Spark telle que fournie par un serveur d’historique Spark autogéré. L'interface utilisateur Spark de la AWS Glue console fournit des vues similaires. Pour plus d'informations sur l'utilisation de l'interface utilisateur web Spark, consultez l'Interface utilisateur web
Voici un exemple d’application Spark qui lit à partir de deux sources de données, effectue une transformation de jointure et écrit le tout dans Amazon S3 au format Parquet.
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.functions import count, when, expr, col, sum, isnull
from pyspark.sql.functions import countDistinct
from awsglue.dynamicframe import DynamicFrame
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'])
df_persons = spark.read.json("s3://awsglue-datasets/examples/us-legislators/all/persons.json")
df_memberships = spark.read.json("s3://awsglue-datasets/examples/us-legislators/all/memberships.json")
df_joined = df_persons.join(df_memberships, df_persons.id == df_memberships.person_id, 'fullouter')
df_joined.write.parquet("s3://aws-glue-demo-sparkui/output/")
job.commit()La visualisation DAG suivante montre les différentes phases de cette tâche Spark.
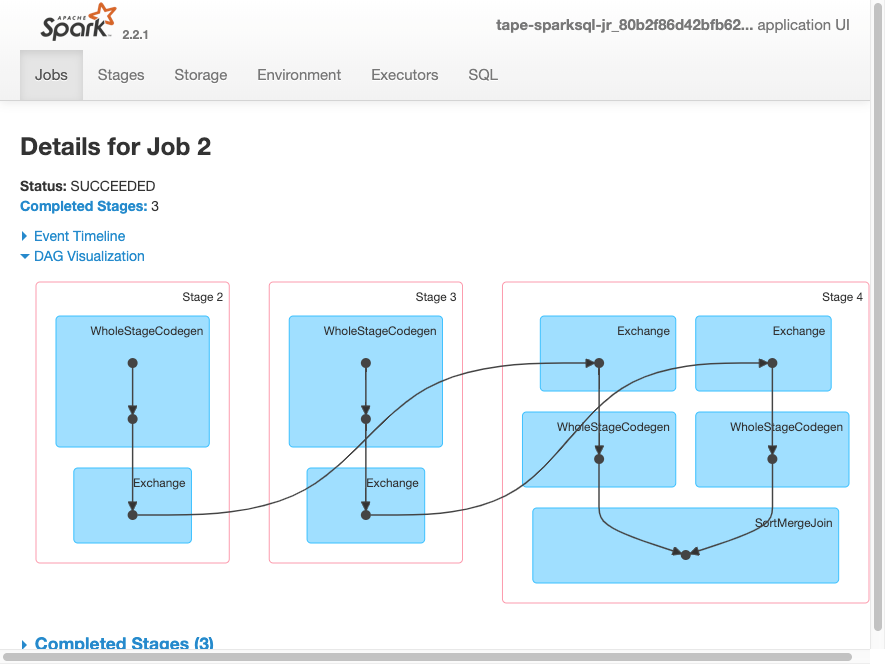
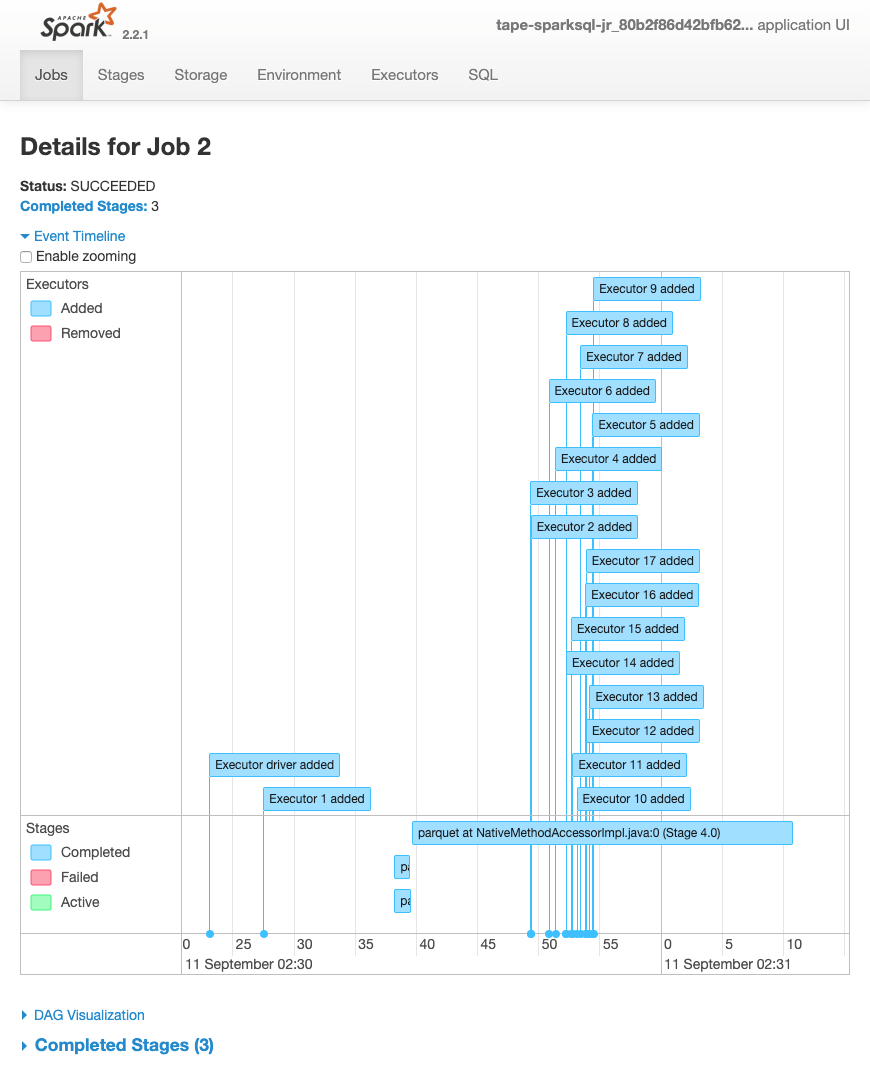
La chronologie d'événements suivante pour une tâche montre le début, l'exécution et la résiliation de différents exécuteurs Spark.
L'écran suivant montre les détails des plans de requête SparkSQL :
-
Plan logique analysé
-
Plan logique d'analyse
-
Plan logique optimisé
-
Plan physique d'exécution

Rubriques
