Avis de fin de support : le 7 octobre 2026,AWS le support de.AWS IoT Greengrass Version 1 Après le 7 octobre 2026, vous ne pourrez plus accéder aux AWS IoT Greengrass V1 ressources. Pour plus d'informations, rendez-vous sur Migrer depuis AWS IoT Greengrass Version 1.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Exportez les flux de données vers le AWS Cloud (CLI)
Ce didacticiel explique comment utiliser le AWS CLI pour configurer et déployer un AWS IoT Greengrass groupe avec le gestionnaire de flux activé. Le groupe contient une fonction Lambda définie par l'utilisateur qui écrit dans un flux dans le gestionnaire de flux, qui est ensuite exportée automatiquement vers le. AWS Cloud
Le gestionnaire de flux rend l'ingestion, le traitement et l'exportation de flux de données volumineux plus efficaces et plus fiables. Dans ce didacticiel, vous allez créer une fonction TransferStream Lambda qui consomme des données IoT. La fonction Lambda utilise le SDK AWS IoT Greengrass Core pour créer un flux dans le gestionnaire de flux, puis y lire et écrire. Le gestionnaire de flux exporte ensuite le flux vers Kinesis Data Streams. Le schéma suivant illustre ce flux de travail.
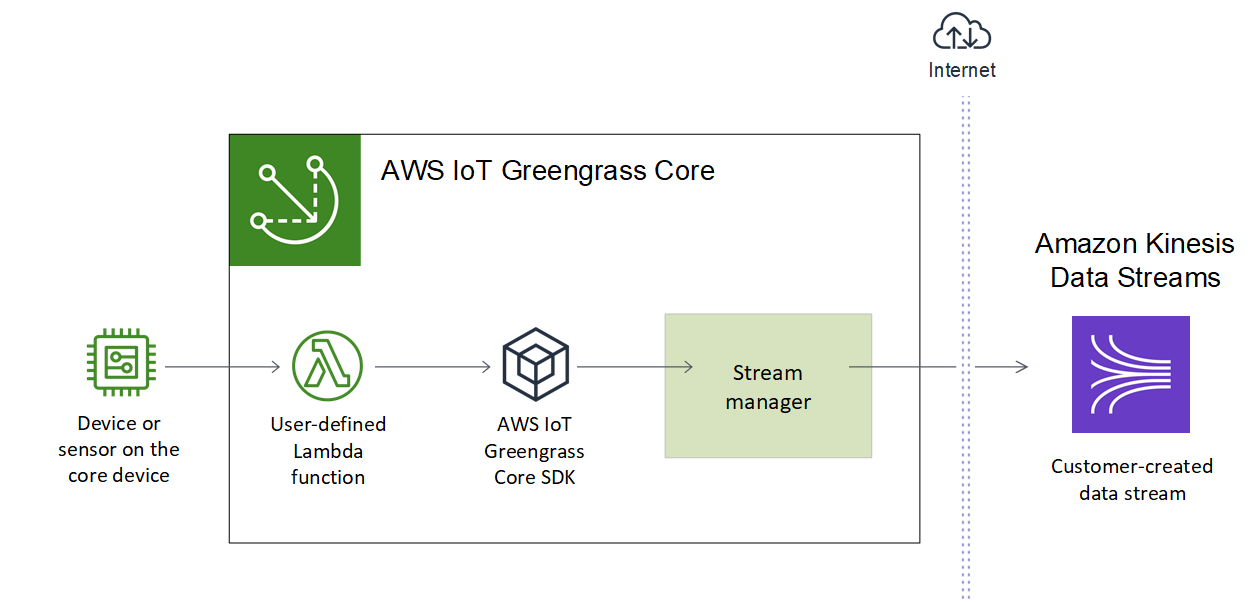
L'objectif de ce didacticiel est de montrer comment les fonctions Lambda définies par l'utilisateur utilisent StreamManagerClient l'objet du SDK Core pour interagir avec AWS IoT Greengrass le gestionnaire de flux. Pour des raisons de simplicité, la fonction Python Lambda que vous créez pour ce didacticiel génère des données de périphérique simulées.
Lorsque vous utilisez l' AWS IoT Greengrass API, qui inclut les commandes Greengrass dans AWS CLI, pour créer un groupe, le gestionnaire de flux est désactivé par défaut. Pour activer le gestionnaire de flux sur votre cœur, vous créez une version de définition de fonction qui inclut la fonction GGStreamManager Lambda du système et une version de groupe qui fait référence à la nouvelle version de définition de fonction. Vous déployez ensuite le groupe.
Conditions préalables
Pour suivre ce didacticiel, vous devez disposer des éléments suivants :
-
Un groupe Greengrass et un noyau Greengrass (v1.10 ou version ultérieure). Pour plus d'informations sur la création d'un groupe et d'un noyau Greengrass, consultez. Démarrage avec AWS IoT Greengrass Le didacticiel de mise en route inclut également les étapes d'installation du logiciel AWS IoT Greengrass Core.
Note
Le gestionnaire de flux n'est pas pris en charge sur OpenWrt les distributions.
-
L'environnement d'exécution Java 8 (JDK 8) installé sur l'appareil principal (noyau).
-
Pour les Debian-based distributions (y compris Raspbian) ou Ubuntu-based les distributions, exécutez la commande suivante :
sudo apt install openjdk-8-jdk -
Pour les Hat-based distributions Red (y compris Amazon Linux), exécutez la commande suivante :
sudo yum install java-1.8.0-openjdkPour de plus amples informations, veuillez consulter How to download and install prebuilt OpenJDK packages
sur le site web OpenJDK.
-
-
AWS IoT Greengrass SDK de base pour Python v1.5.0 ou version ultérieure. Pour l'utiliser
StreamManagerClientdans le SDK de AWS IoT Greengrass base pour Python, vous devez :-
Installez Python 3.7 ou version ultérieure sur le périphérique principal.
-
Incluez le SDK et ses dépendances dans votre package de déploiement de fonctions Lambda. Des instructions sont fournies dans ce didacticiel.
Astuce
Vous pouvez utiliser
StreamManagerClientavec Java ou NodeJS. Pour un exemple de code, consultez le SDK AWS IoT Greengrass Core pour Java AWS IoT Greengrass et le SDK Node.js Corepour plus de détails. GitHub -
-
Un flux de destination nommé
MyKinesisStreamcréé dans Amazon Kinesis Data Streams au Région AWS même titre que votre groupe Greengrass. Pour plus d'informations, consultez la section Créer un flux dans le manuel Amazon Kinesis Developer Guide.Note
Dans ce didacticiel, le gestionnaire de flux exporte les données vers Kinesis Data Streams, ce qui entraîne des frais pour Compte AWS votre. Pour plus d'informations sur les tarifs, consultez la section Tarification de Kinesis Data Streams
. Pour éviter des frais, vous pouvez exécuter ce didacticiel sans créer de flux de données Kinesis. Dans ce cas, vous devez vérifier dans les journaux que le gestionnaire de flux a tenté d'exporter le flux vers Kinesis Data Streams.
-
Une politique IAM ajoutée à Rôle de groupe Greengrass celle qui autorise l'
kinesis:PutRecordsaction sur le flux de données cible, comme indiqué dans l'exemple suivant :
-
Ils AWS CLI sont installés et configurés sur votre ordinateur. Pour plus d'informations, voir Installation AWS Command Line Interface et configuration du AWS CLI dans le guide de AWS Command Line Interface l'utilisateur.
Les exemples de commandes de ce didacticiel sont écrits pour Linux et d'autres Unix-based systèmes. Si vous utilisez Windows, consultez la section Spécification de valeurs de paramètres pour l'interface de ligne de AWS commande pour plus d'informations sur les différences de syntaxe.
Si la commande contient une chaîne JSON, le didacticiel fournit un exemple qui possède le fichier JSON sur une seule ligne. Sur certains systèmes, il peut être plus efficace de modifier et d'exécuter des commandes utilisant ce format.
Le didacticiel contient les étapes détaillées suivantes :
Le didacticiel devrait prendre environ 30 minutes.
Étape 1 : Création d'un package de déploiement de fonctions Lambda
Au cours de cette étape, vous allez créer un package de déploiement de fonctions Lambda qui contient le code de fonction Python et ses dépendances. Vous téléchargerez ce package ultérieurement lorsque vous créerez la fonction Lambda dans. AWS Lambda La fonction Lambda utilise le SDK AWS IoT Greengrass Core pour créer et interagir avec des flux locaux.
Note
Vos fonctions Lambda définies par l'utilisateur doivent utiliser AWS IoT Greengrass le SDK Core pour interagir avec le gestionnaire de flux. Pour de plus amples informations sur les conditions requises pour le gestionnaire de flux Greengrass, veuillez consulter les conditions requises pour le gestionnaire de flux Greengrass.
-
Téléchargez le SDK AWS IoT Greengrass de base pour Python v1.5.0 ou version ultérieure.
-
Décompressez le package téléchargé pour obtenir le kit SDK. Le kit SDK est représenté par le dossier
greengrasssdk. -
Installez les dépendances du package à inclure avec le SDK dans votre package de déploiement de fonctions Lambda.
-
Accédez au répertoire SDK qui contient le fichier
requirements.txt. Ce fichier répertorie les dépendances. -
Installez les dépendances du kit SDK. Par exemple, exécutez la commande
pipsuivante pour les installer dans le répertoire en cours :pip install --target . -r requirements.txt
-
-
Enregistrez la fonction de code Python suivante dans un fichier local nommé
transfer_stream.py.Astuce
import asyncio import logging import random import time from greengrasssdk.stream_manager import ( ExportDefinition, KinesisConfig, MessageStreamDefinition, ReadMessagesOptions, ResourceNotFoundException, StrategyOnFull, StreamManagerClient, ) # This example creates a local stream named "SomeStream". # It starts writing data into that stream and then stream manager automatically exports # the data to a customer-created Kinesis data stream named "MyKinesisStream". # This example runs forever until the program is stopped. # The size of the local stream on disk will not exceed the default (which is 256 MB). # Any data appended after the stream reaches the size limit continues to be appended, and # stream manager deletes the oldest data until the total stream size is back under 256 MB. # The Kinesis data stream in the cloud has no such bound, so all the data from this script is # uploaded to Kinesis and you will be charged for that usage. def main(logger): try: stream_name = "SomeStream" kinesis_stream_name = "MyKinesisStream" # Create a client for the StreamManager client = StreamManagerClient() # Try deleting the stream (if it exists) so that we have a fresh start try: client.delete_message_stream(stream_name=stream_name) except ResourceNotFoundException: pass exports = ExportDefinition( kinesis=[KinesisConfig(identifier="KinesisExport" + stream_name, kinesis_stream_name=kinesis_stream_name)] ) client.create_message_stream( MessageStreamDefinition( name=stream_name, strategy_on_full=StrategyOnFull.OverwriteOldestData, export_definition=exports ) ) # Append two messages and print their sequence numbers logger.info( "Successfully appended message to stream with sequence number %d", client.append_message(stream_name, "ABCDEFGHIJKLMNO".encode("utf-8")), ) logger.info( "Successfully appended message to stream with sequence number %d", client.append_message(stream_name, "PQRSTUVWXYZ".encode("utf-8")), ) # Try reading the two messages we just appended and print them out logger.info( "Successfully read 2 messages: %s", client.read_messages(stream_name, ReadMessagesOptions(min_message_count=2, read_timeout_millis=1000)), ) logger.info("Now going to start writing random integers between 0 and 1000 to the stream") # Now start putting in random data between 0 and 1000 to emulate device sensor input while True: logger.debug("Appending new random integer to stream") client.append_message(stream_name, random.randint(0, 1000).to_bytes(length=4, signed=True, byteorder="big")) time.sleep(1) except asyncio.TimeoutError: logger.exception("Timed out while executing") except Exception: logger.exception("Exception while running") def function_handler(event, context): return logging.basicConfig(level=logging.INFO) # Start up this sample code main(logger=logging.getLogger()) -
Compressez les éléments suivants dans un fichier nommé
transfer_stream_python.zip. Il s'agit de votre package de déploiement de fonctions Lambda.-
transfer_stream.py. Logique d'application.
-
greengrasssdk. Bibliothèque requise pour les fonctions Python Greengrass Lambda qui publient des messages MQTT.
Les opérations du gestionnaire de flux sont disponibles dans la version 1.5.0 ou ultérieure du SDK AWS IoT Greengrass Core pour Python.
-
Les dépendances que vous avez installées pour le SDK AWS IoT Greengrass Core pour Python (par exemple, les
cbor2répertoires).
Lorsque vous créez le fichier
zip, incluez uniquement ces éléments, et non le dossier conteneur. -
Étape 2 : création d’une fonction Lambda
-
Créez un rôle IAM afin de pouvoir transmettre l'ARN du rôle lors de la création de la fonction.
Note
AWS IoT Greengrass n'utilise pas ce rôle car les autorisations pour vos fonctions Greengrass Lambda sont spécifiées dans le rôle du groupe Greengrass. Dans le cadre de ce didacticiel, vous créez un rôle vide.
-
Copiez la
Arnà partir de la sortie. -
Utilisez l' AWS Lambda API pour créer la
TransferStreamfonction. La commande suivante suppose que le fichier ZIP se trouve dans le répertoire actuel.-
Remplacez
role-arnpar l’Arnque vous avez copié.
aws lambda create-function \ --function-name TransferStream \ --zip-file fileb://transfer_stream_python.zip \ --rolerole-arn\ --handler transfer_stream.function_handler \ --runtime python3.7 -
-
Publiez une version de la fonction.
aws lambda publish-version --function-name TransferStream --description 'First version' -
Créez un alias pour la version publiée.
Les groupes Greengrass peuvent référencer une fonction Lambda par alias (recommandé) ou par version. L'utilisation d'un alias facilite la gestion des mises à jour du code, car vous n'avez pas à modifier votre table d'abonnement ou la définition de groupe lorsque le code de fonction est mis à jour. Au lieu de cela, il vous suffit de pointer l'alias vers la nouvelle version de la fonction.
aws lambda create-alias --function-name TransferStream --name GG_TransferStream --function-version 1Note
AWS IoT Greengrass ne prend pas en charge les alias Lambda pour les versions $LATEST.
-
Copiez la
AliasArnà partir de la sortie. Vous utilisez cette valeur lorsque vous configurez la fonction pour AWS IoT Greengrass.
Vous êtes maintenant prêt à configurer la fonction pour AWS IoT Greengrass.
Étape 3 : Créer une version et une définition de fonction
Cette étape crée une version de définition de fonction qui fait référence à la fonction GGStreamManager Lambda du système et à votre fonction Lambda définie par TransferStream l'utilisateur. Pour activer le gestionnaire de flux lorsque vous utilisez l' AWS IoT Greengrass API, votre version de définition de fonction doit inclure la GGStreamManager fonction.
-
Créez une définition de fonction avec une version initiale contenant le système et les fonctions Lambda définies par l'utilisateur.
La version de définition suivante active le gestionnaire de flux avec les paramètres par défaut. Pour configurer des paramètres personnalisés, vous devez définir des variables d'environnement pour les paramètres du gestionnaire de flux correspondants. Pour un exemple, voirPour activer, désactiver ou configurer le gestionnaire de flux (CLI). AWS IoT Greengrass utilise les paramètres par défaut pour les paramètres omis.
MemorySizedevrait être au moins128000.Pinneddoit être réglé surtrue.Note
Une fonction Lambda de longue durée (ou épinglée) démarre automatiquement après AWS IoT Greengrass le démarrage et continue de s'exécuter dans son propre conteneur. Cela contraste avec une fonction Lambda à la demande, qui démarre lorsqu'elle est invoquée et s'arrête lorsqu'il ne reste plus aucune tâche à exécuter. Pour de plus amples informations, veuillez consulter Configuration du cycle de vie pour les fonctions Greengrass Lambda.
-
Remplacez
arbitrary-function-idpar un nom pour la fonction, tel questream-manager. -
alias-arnRemplacez-le par celuiAliasArnque vous avez copié lorsque vous avez créé l'alias de la fonctionTransferStreamLambda.
Note
Timeoutest requis par la version de définition de fonction, maisGGStreamManagerne l'utilise pas. Pour plus d'informations sur les paramètres au niveau du groupeTimeoutet les autres, consultez. Contrôle de l'exécution des fonctions Greengrass Lambda à l'aide d'une configuration spécifique au groupe -
-
Copiez la
LatestVersionArnà partir de la sortie. Vous utilisez cette valeur pour ajouter la version de définition de fonction à la version de groupe que vous déployez pour le noyau.
Étape 4 : Créer une définition et une version de l'enregistreur
Configurez les paramètres de journalisation du groupe. Dans ce didacticiel, vous allez configurer les composants AWS IoT Greengrass du système, les fonctions Lambda définies par l'utilisateur et les connecteurs pour écrire des journaux dans le système de fichiers du périphérique principal. Vous pouvez utiliser les journaux pour résoudre les problèmes que vous rencontrez. Pour de plus amples informations, veuillez consulter Surveillance avec AWS IoT Greengrass journaux.
-
Créez une définition d'enregistreur qui inclut une version initiale.
-
Copiez l'élément
LatestVersionArnde la définition de l'enregistreur à partir de la sortie. Vous utilisez cette valeur pour ajouter la version de la définition de l'enregistreur à la version de groupe que vous déployez sur le noyau.
Étape 5 : Obtenir l'ARN de votre version de définition du noyau
Obtenez l'ARN de la version de définition du noyau pour ensuite l'ajouter à votre nouvelle version de groupe. Pour que vous puissiez déployer une version de groupe, cette dernière doit référencer une version de définition du noyau contenant exactement un noyau.
-
Obtenez les ID du groupe et de la version de groupe Greengrass cible. Cette procédure suppose qu'il s'agit de la dernière version du groupe et du groupe. La requête suivante renvoie le dernier groupe créé.
aws greengrass list-groups --query "reverse(sort_by(Groups, &CreationTimestamp))[0]"Vous pouvez également procéder à une interrogation par nom. Les noms de groupe ne devant pas nécessairement être uniques, plusieurs groupes peuvent être renvoyés.
aws greengrass list-groups --query "Groups[?Name=='MyGroup']"Note
Vous pouvez également trouver ces valeurs dans la AWS IoT console. L'ID du groupe s'affiche sur la page Paramètres du groupe. Les identifiants de version du groupe sont affichés dans l'onglet Déploiements du groupe.
-
Copiez l'
Iddu groupe cible à partir de la sortie. Vous utilisez cela pour obtenir la version de définition du noyau et lorsque vous déployez le groupe. -
Copiez l'élément
LatestVersionà partir de la sortie (ID de la dernière version ajoutée au groupe). Vous utilisez cela pour obtenir la version de la définition du noyau. -
Obtenir l'ARN de la version de la définition du noyau :
-
Obtenez la version de groupe.
-
group-idRemplacez-le par celuiIdque vous avez copié pour le groupe. -
group-version-idRemplacez-le par celuiLatestVersionque vous avez copié pour le groupe.
aws greengrass get-group-version \ --group-idgroup-id\ --group-version-idgroup-version-id -
-
Copiez la
CoreDefinitionVersionArnà partir de la sortie. Vous utilisez cette valeur pour ajouter la version de définition du noyau à la version de groupe que vous déployez sur le noyau.
-
Étape 6 : Créer une version de groupe
Maintenant, vous êtes prêt à créer une version de groupe contenant tous les éléments que vous souhaitez déployer. Pour ce faire, vous devez créer une version de groupe qui fait référence à la version cible de chaque type de composant. Pour ce didacticiel, vous incluez une version de définition du noyau, une version de définition de fonction et une version de définition de l'enregistreur.
-
Créer une version de groupe.
-
group-idRemplacez-le par celuiIdque vous avez copié pour le groupe. -
core-definition-version-arnRemplacez-le par celuiCoreDefinitionVersionArnque vous avez copié pour la version de définition de base. -
function-definition-version-arnRemplacez-le par celuiLatestVersionArnque vous avez copié pour votre nouvelle version de définition de fonction. -
logger-definition-version-arnRemplacez-le par celuiLatestVersionArnque vous avez copié pour votre nouvelle version de définition de l'enregistreur.
aws greengrass create-group-version \ --group-idgroup-id\ --core-definition-version-arncore-definition-version-arn\ --function-definition-version-arnfunction-definition-version-arn\ --logger-definition-version-arnlogger-definition-version-arn -
-
Copiez la
Versionà partir de la sortie. Il s'agit de l'ID de la nouvelle version de groupe.
Étape 7 : Créer un déploiement
Déployer le groupe sur l'appareil principal (noyau)
-
Créez un déploiement .
group-idRemplacez-le par celuiIdque vous avez copié pour le groupe.group-version-idRemplacez-le par celuiVersionque vous avez copié pour la nouvelle version du groupe.
aws greengrass create-deployment \ --deployment-type NewDeployment \ --group-idgroup-id\ --group-version-idgroup-version-id -
Copiez la
DeploymentIdà partir de la sortie. -
Obtenir le statut du déploiement.
group-idRemplacez-le par celuiIdque vous avez copié pour le groupe.deployment-idRemplacez-le par celuiDeploymentIdque vous avez copié pour le déploiement.
aws greengrass get-deployment-status \ --group-idgroup-id\ --deployment-iddeployment-idSi le statut est le cas
Success, le déploiement a réussi. Pour bénéficier d'une aide à la résolution des problèmes, consultez Résolution des problèmes AWS IoT Greengrass.
Étape 8 : Tester l'application
La fonction TransferStream Lambda génère des données d'appareil simulées. Elle écrit des données dans un flux que le gestionnaire de flux exporte vers le flux de données Kinesis cible.
-
Dans la console Amazon Kinesis, sous Kinesis data streams, sélectionnez. MyKinesisStream
Note
Si vous avez exécuté le didacticiel sans flux de données Kinesis cible, recherchez dans le fichier journal le gestionnaire de flux (
GGStreamManager). S'il contientexport stream MyKinesisStream doesn't existdans un message d'erreur, le test est réussi. Cette erreur signifie que le service a essayé d'effectuer une exportation vers le flux mais que le flux n'existe pas. -
Sur la MyKinesisStreampage, choisissez Surveillance. Si le test réussit, vous devriez voir des données dans les graphiques PutRecords . Selon votre connexion, l'affichage des données peut prendre une minute.
Important
Lorsque vous avez terminé le test, supprimez le flux de données Kinesis pour éviter d'entraîner des frais supplémentaires.
Vous pouvez aussi exécuter la commande suivante pour arrêter le démon Greengrass. Cela empêche le noyau d'envoyer des messages jusqu'à ce que vous soyez prêt à continuer le test.
cd /greengrass/ggc/core/ sudo ./greengrassd stop -
Supprimez la fonction TransferStreamLambda du noyau.
Suivez l'Étape 6 : Créer une version de groupe pour créer une nouvelle version de groupe, mais supprimez l'option
--function-definition-version-arndans la commandecreate-group-version. Vous pouvez également créer une version de définition de fonction qui n'inclut pas la fonction TransferStreamLambda.Note
En omettant la fonction
GGStreamManagerLambda du système dans la version du groupe déployé, vous désactivez la gestion des flux sur le cœur.-
Suivez l'Étape 7 : Créer un déploiement pour déployer la nouvelle version du groupe.
Pour afficher les informations de journalisation ou résoudre les problèmes liés aux flux, recherchez les fonctions GGStreamManager et TransferStream dans les journaux. Vous devez être root autorisé à lire AWS IoT Greengrass les journaux du système de fichiers.
TransferStreamécrit les entrées de journal dansgreengrass-root/ggc/var/log/user/region/account-id/TransferStream.logGGStreamManagerécrit les entrées de journal dansgreengrass-root/ggc/var/log/system/GGStreamManager.log
Si vous avez besoin de plus d'informations de dépannage, vous pouvez définir le niveau de journalisation Lambda sur DEBUG, puis créer et déployer une nouvelle version de groupe.
Consultez aussi
-
StreamManagerClient À utiliser pour travailler avec des flux
-
Configurations d'exportation prises en charge AWS Cloud destinations
-
Gestion des identités et des accès AWS commandes (IAM) dans la référence des AWS CLI commandes
-
AWS Lambda commandes dans la référence des AWS CLI commandes
-
AWS IoT Greengrass commandes dans la référence des AWS CLI commandes
