Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Amazon Keyspaces : comment ça marche
Amazon Keyspaces élimine les frais administratifs liés à la gestion de Cassandra. Pour comprendre pourquoi, il est utile de commencer par l'architecture de Cassandra, puis de la comparer à celle d'Amazon Keyspaces.
Rubriques
High-level architecture : Apache Cassandra contre Amazon Keyspaces
Apache Cassandra traditionnelle est déployée dans un cluster composé d'un ou plusieurs nœuds. Vous êtes responsable de la gestion de chaque nœud et de l'ajout et de la suppression de nœuds à mesure que votre cluster évolue.
Un programme client accède à Cassandra en se connectant à l'un des nœuds et en émettant des instructions Cassandra Query Language (CQL). CQL est similaire à SQL, le langage populaire utilisé dans les bases de données relationnelles. Même si Cassandra n'est pas une base de données relationnelle, CQL fournit une interface familière pour interroger et manipuler des données dans Cassandra.
Le diagramme suivant montre un cluster Apache Cassandra simple, composé de quatre nœuds.
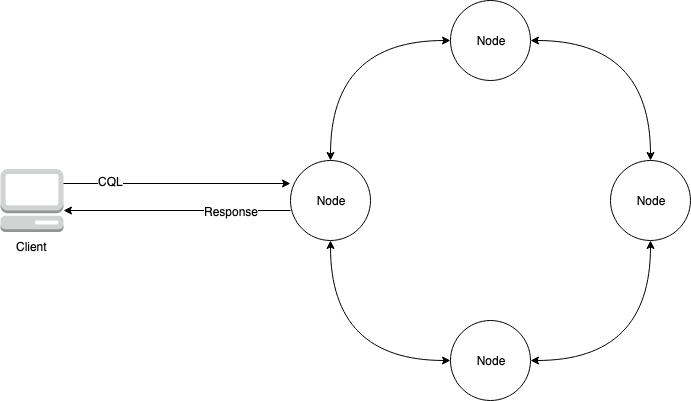
Un déploiement Cassandra de production peut être composé de centaines de nœuds, s'exécutant sur des centaines d'ordinateurs physiques dans un ou plusieurs centres de données physiques. Cela peut entraîner un fardeau opérationnel pour les développeurs d'applications qui doivent allouer, corriger et gérer des serveurs en plus de l'installation, de la maintenance et de l'exploitation des logiciels.
Avec Amazon Keyspaces (pour Apache Cassandra), vous n'avez pas besoin de provisionner, de patcher ou de gérer des serveurs. Vous pouvez donc vous concentrer sur le développement de meilleures applications. Amazon Keyspaces propose deux modes de capacité de débit pour les lectures et les écritures : à la demande et provisionné. Vous pouvez choisir le mode de capacité de débit de votre table pour optimiser le prix des lectures et des écritures en fonction de la prévisibilité et de la variabilité de votre charge de travail.
Avec le mode à la demande, vous ne payez que les lectures et les écritures que votre application effectue. Il n'est pas nécessaire de spécifier à l'avance la capacité de débit de votre table. Amazon Keyspaces gère le trafic de vos applications presque instantanément, qu'il augmente ou diminue, ce qui en fait une bonne option pour les applications dont le trafic est imprévisible.
Le mode de capacité allouée permet d’optimiser le débit si vous disposez d’un trafic d’application prévisible et pouvez prévoir les besoins en capacité de votre table. Avec le mode de capacité allouée, vous spécifiez le nombre de lectures et d'écritures par seconde dont vous pensez que votre application aura besoin. Vous pouvez augmenter et diminuer automatiquement la capacité allouée de votre table en activant la mise à l'échelle automatique.
Vous pouvez modifier le mode de capacité de votre table une fois par jour à mesure que vous en apprendrez plus sur les schémas de trafic de votre charge de travail, ou si vous prévoyez avoir une forte explosion de trafic, par exemple en raison d'un événement majeur qui, selon vous, entraînera beaucoup de trafic de table. Pour de plus amples informations sur l'allocation de capacité en lecture et en écriture, reportez-vous à la section Configurer les modes de read/write capacité dans Amazon Keyspaces.
Amazon Keyspaces (pour Apache Cassandra) stocke trois copies de vos données dans plusieurs zones de disponibilité pour des raisons de durabilité et de haute disponibilité
Le schéma suivant montre l'architecture d'Amazon Keyspaces.
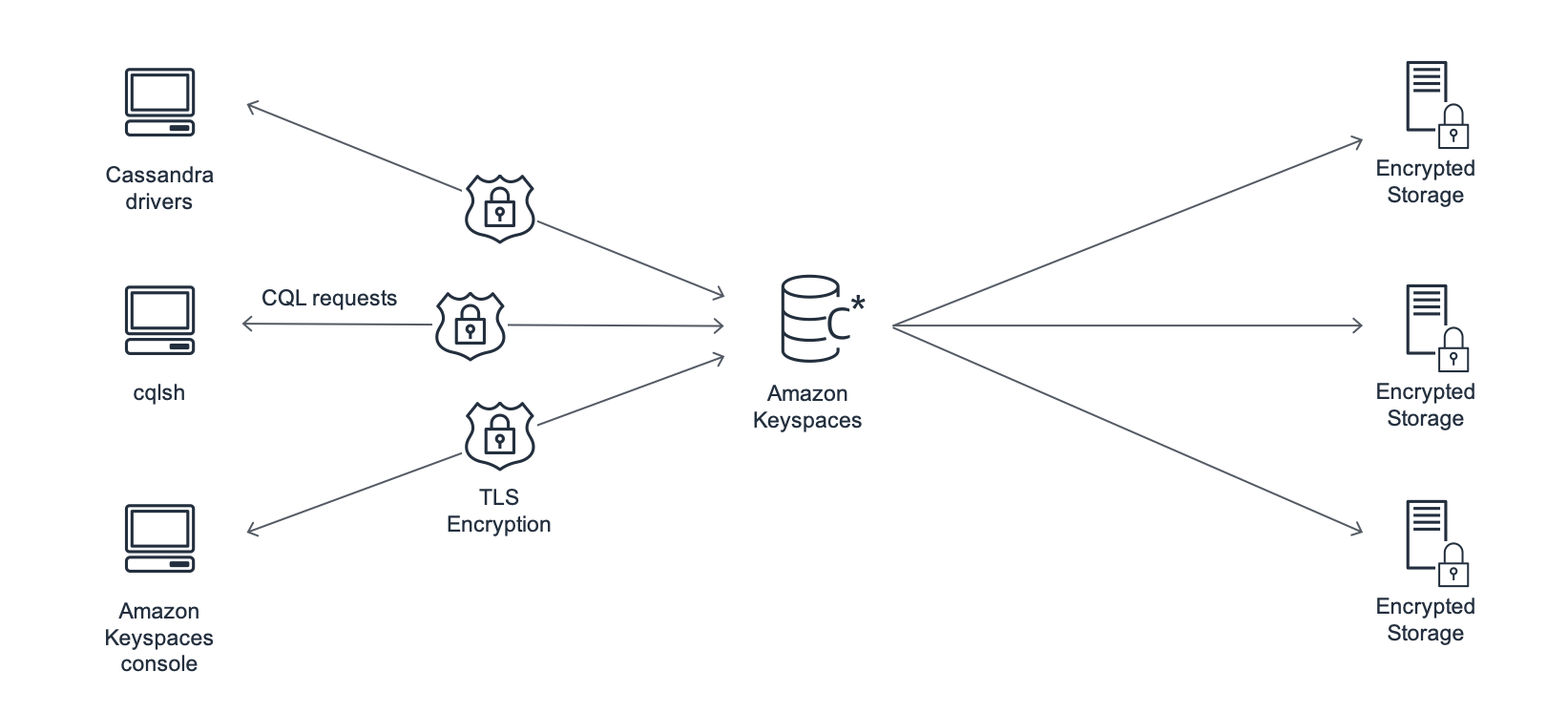
Un programme client accède à Amazon Keyspaces en se connectant à un point de terminaison prédéterminé (nom d'hôte et numéro de port) et en émettant des instructions CQL. Pour obtenir la liste des points de terminaison disponibles, reportez-vous à la section Points de terminaison de service pour Amazon Keyspaces.
Modèle de données Cassandra
La façon dont vous modélisez vos données pour votre analyse de rentabilisation est essentielle pour optimiser les performances d'Amazon Keyspaces. Un modèle de données de médiocre qualité peut considérablement dégrader les performances.
Même si CQL ressemble à SQL, les backends de Cassandra et des bases de données relationnelles sont très différents et doivent être abordés différemment. Voici quelques-unes des questions les plus importantes à considérer :
- Stockage
-
Vous pouvez visualiser vos données Cassandra dans des tables, chaque ligne représentant un enregistrement et chaque colonne un champ dans cet enregistrement.
- Conception du tableau : première requête
-
Il n'y a pas d'instruction
JOINdans CQL. Par conséquent, vous devez concevoir vos tables en fonction de la forme de vos données et de la manière dont vous devez y accéder pour vos cas d'utilisation professionnels. Cela peut entraîner une dénormalisation avec des données dupliquées. Vous devez concevoir chacune de vos tables spécifiquement pour un modèle d'accès particulier. - Partitions
-
Vos données sont stockées dans des partitions sur le disque. Le nombre de partitions dans lesquelles vos données sont stockées et la façon dont elles sont distribuées entre les partitions sont déterminées par votre clé de partition. La façon dont vous définissez votre clé de partition peut avoir un impact significatif sur les performances de vos requêtes. Pour connaître les bonnes pratiques, consultez Comment utiliser efficacement les clés de partition dans Amazon Keyspaces.
- Clé primaire
-
Dans Cassandra, les données sont stockées sous la forme d'une paire clé-valeur. Chaque table Cassandra doit avoir une clé primaire, qui est la clé unique de chaque ligne de la table. La clé primaire est le composite d'une clé de partition requise et de colonnes de clustering facultatives. Les données qui composent la clé primaire doivent être uniques pour tous les enregistrements d'une table.
-
Clé de partition : la partie clé de partition de la clé primaire est requise et détermine dans quelle partition de votre cluster les données sont stockées. La clé de partition peut être une seule colonne ; il peut aussi s'agir d'une valeur composée de deux colonnes ou plus. Vous utiliseriez une clé de partition composée si une clé de partition à colonne unique se traduisait par une partition unique ou par un très petit nombre de partitions contenant la plupart des données et supportant ainsi la majorité des I/O opérations sur le disque.
-
Colonne de clustering : la partie optionnelle de la colonne de clustering de votre clé primaire détermine la manière dont les données sont regroupées et triées au sein de chaque partition. Si vous incluez une colonne de clustering dans votre clé primaire, la colonne de clustering peut comporter une ou plusieurs colonnes. S'il y a plusieurs colonnes dans la colonne de regroupement, l'ordre de tri est déterminé par l'ordre dans lequel les colonnes sont répertoriées dans la colonne de regroupement, de gauche à droite.
-
Pour plus d'informations sur le design NoSQL et Amazon Keyspaces, consultez. Principales différences et principes de conception de la conception NoSQL Pour plus d'informations sur Amazon Keyspaces et la modélisation des données, consultez. Bonnes pratiques de modélisation des données : recommandations pour la conception de modèles de données
Accès à Amazon Keyspaces depuis une application
Amazon Keyspaces (pour Apache Cassandra) implémente l'API Apache Cassandra Query Language (CQL), afin que vous puissiez utiliser les pilotes CQL et Cassandra que vous utilisez déjà. La mise à jour de votre application est aussi simple que de mettre à jour votre pilote ou votre cqlsh configuration Cassandra pour qu'elle pointe vers le point de terminaison du service Amazon Keyspaces. Pour plus d’informations sur les informations d’identification requises, consultez Création et configuration des AWS informations d'identification pour Amazon Keyspaces.
Note
Pour vous aider à démarrer, vous trouverez des exemples de code de bout en bout pour vous connecter à Amazon Keyspaces à l'aide de différents pilotes clients Cassandra dans le référentiel d'exemples de code Amazon Keyspaces sur. GitHub
Considérez le programme Python suivant, qui se connecte à un cluster Cassandra et interroge une table.
from cassandra.cluster import Cluster #TLS/SSL configuration goes here ksp = 'MyKeyspace' tbl = 'WeatherData' cluster = Cluster(['NNN.NNN.NNN.NNN'], port=NNNN) session = cluster.connect(ksp) session.execute('USE ' + ksp) rows = session.execute('SELECT * FROM ' + tbl) for row in rows: print(row)
Pour exécuter le même programme sur Amazon Keyspaces, vous devez :
-
Ajouter le point de terminaison et le port du cluster : Par exemple, l'hôte peut être remplacé par un point de terminaison de service, tel que
cassandra.us-east-1.amazonaws.com, et le numéro de port par :9142. -
Ajouter la TLS/SSL configuration : pour plus d'informations sur l'ajout de la TLS/SSL configuration permettant de se connecter à Amazon Keyspaces à l'aide d'un pilote Python du client Cassandra, consultez. Utilisation d'un pilote client Cassandra Python pour accéder à Amazon Keyspaces par programmation
