Après mûre réflexion, nous avons décidé de mettre fin à Amazon Kinesis Data Analytics pour les applications SQL :
1. À compter du 1er septembre 2025, nous ne fournirons aucune correction de bogue pour les applications Amazon Kinesis Data Analytics for SQL, car leur support sera limité, compte tenu de l'arrêt prochain.
2. À compter du 15 octobre 2025, vous ne pourrez plus créer de nouvelles applications Kinesis Data Analytics for SQL.
3. Nous supprimerons vos candidatures à compter du 27 janvier 2026. Vous ne serez pas en mesure de démarrer ou d'utiliser vos applications Amazon Kinesis Data Analytics for SQL. Support ne sera plus disponible pour Amazon Kinesis Data Analytics for SQL à partir de cette date. Pour de plus amples informations, veuillez consulter Arrêt d'Amazon Kinesis Data Analytics pour les applications SQL.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Exemple : transformation DateTime des valeurs
Amazon Kinesis Data Analytics prend en charge la conversion de colonnes en horodatages. Par exemple, vous pouvez utiliser votre propre horodatage dans le cadre d’une clause GROUP BY en tant qu’autre fenêtre temporelle, en plus de la colonne ROWTIME. Kinesis Data Analytics fournit des opérations et des fonctions SQL pour gérer les champs de date et d’heure.
-
Opérateurs de date et d’heure : Vous pouvez effectuer des opérations arithmétiques sur les dates, les heures et les types de données d’intervalle. Pour plus d’informations, consultez la section Opérateurs de date, d’horodatage et d’intervalle dans le manuel Référence SQL du service géré Amazon pour Apache Flink.
-
Fonctions SQL : Ces fonctions incluent les fonctions suivantes. Pour plus d’informations, consultez la section Fonctions de date et d’heure dans le manuel Référence SQL du service géré Amazon pour Apache Flink.
-
EXTRACT(): Extrait un champ d'une expression de date, d'heure, d'horodatage ou d'intervalle. -
CURRENT_TIME: Renvoie l’heure à laquelle la requête s’exécute (UTC). -
CURRENT_DATE: Renvoie la date à laquelle la requête s’exécute (UTC). -
CURRENT_TIMESTAMP: Renvoie l'horodatage du moment où lorsque la requête s'exécute (UTC). -
LOCALTIME: Renvoie l’heure en cours à laquelle la requête s’exécute telle que définie par l’environnement d’exécution de Kinesis Data Analytics (UTC). -
LOCALTIMESTAMP: Renvoie l’horodatage actuel, tel que défini par l’environnement d’exécution de Kinesis Data Analytics (UTC).
-
-
Extensions SQL : Ces extensions incluent les extensions suivantes. Pour plus d’informations, consultez les sections Fonctions de date et d’heure et Fonctions de conversion de date et d’heure dans le manuel Référence SQL du service géré Amazon pour Apache Flink.
-
CURRENT_ROW_TIMESTAMP: Renvoie un nouvel horodatage pour chaque ligne du flux. -
TSDIFF: Renvoie la différence entre deux horodatages en millisecondes. -
CHAR_TO_DATE: Convertit une chaîne en date. -
CHAR_TO_TIME: Convertit une chaîne en heure. -
CHAR_TO_TIMESTAMP: Convertit une chaîne en horodatage. -
DATE_TO_CHAR: Convertit une date en chaîne. -
TIME_TO_CHAR: Convertit une heure en chaîne. -
TIMESTAMP_TO_CHAR: Convertit un horodatage en chaîne.
-
La plupart des fonctions SQL précédentes utilisent un format pour convertir les colonnes. Le format est flexible. Par exemple, vous pouvez spécifier le format yyyy-MM-dd hh:mm:ss pour convertir une chaîne d'entrée 2009-09-16 03:15:24 en horodatage. Pour plus d’informations, consultez la section Char vers Timestamp(Sys) dans le manuel Référence SQL du service géré Amazon pour Apache Flink.
Exemples : Transformation de dates
Dans cet exemple, vous écrivez les enregistrements suivants dans un flux de données Amazon Kinesis.
{"EVENT_TIME": "2018-05-09T12:50:41.337510", "TICKER": "AAPL"} {"EVENT_TIME": "2018-05-09T12:50:41.427227", "TICKER": "MSFT"} {"EVENT_TIME": "2018-05-09T12:50:41.520549", "TICKER": "INTC"} {"EVENT_TIME": "2018-05-09T12:50:41.610145", "TICKER": "MSFT"} {"EVENT_TIME": "2018-05-09T12:50:41.704395", "TICKER": "AAPL"} ...
Vous créez ensuite une application Kinesis Data Analytics dans la console, avec le flux Kinesis comme source de streaming. Le processus de découverte lit les exemples d'enregistrements de la source de diffusion et déduit un schéma intégré à l'application avec une deux colonnes (EVENT_TIME et TICKER), comme illustré.
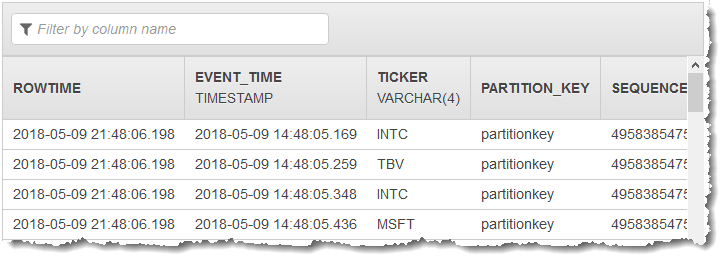
Vous utilisez ensuite le code d'application avec des fonctions SQL pour convertir le champ d'horodatage EVENT_TIME de différentes manières. Puis vous insérez les données obtenues dans un autre flux intégré à l'application, comme indiqué dans la capture d'écran suivante :
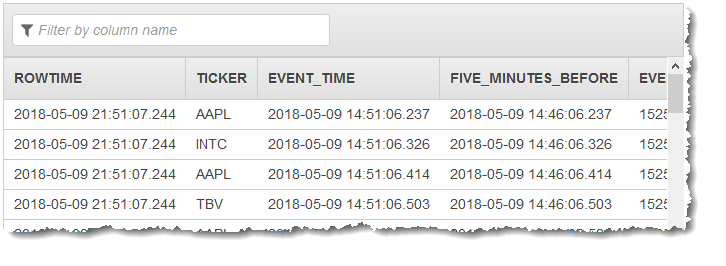
Étape 1 : Création d’un flux de données Kinesis
Créez un flux de données Amazon Kinesis et remplissez-le avec des enregistrements d’heure d’événement et de symbole boursier comme suit :
-
Choisissez Data Streams (Flux de données) dans le volet de navigation.
-
Choisissez Create Kinesis stream (Créer un flux Kinesis), puis créez un flux avec une seule partition.
-
Exécutez le code Python suivant pour remplir le flux avec des exemples de données. Ce code simple écrit un enregistrement en continu avec un symbole boursier aléatoire et l'horodatage actuel dans le flux.
import datetime import json import random import boto3 STREAM_NAME = "ExampleInputStream" def get_data(): return { "EVENT_TIME": datetime.datetime.now().isoformat(), "TICKER": random.choice(["AAPL", "AMZN", "MSFT", "INTC", "TBV"]), "PRICE": round(random.random() * 100, 2), } def generate(stream_name, kinesis_client): while True: data = get_data() print(data) kinesis_client.put_record( StreamName=stream_name, Data=json.dumps(data), PartitionKey="partitionkey" ) if __name__ == "__main__": generate(STREAM_NAME, boto3.client("kinesis"))
Étape 2 : Création d’une application Amazon Kinesis Data Analytics
Créez une application comme suit :
Ouvrez le service géré pour la console Apache Flink à l'adresse https://console.aws.amazon.com/kinesisanalytics.
-
Choisissez Create application (Créer une application), saisissez un nom d'application, puis sélectionnez Create application (Créer une application).
-
Sur la page de détails de l'application, choisissez Connect streaming data (Connecter des données de diffusion) pour vous connecter à la source.
-
Sur la page Connect to source (Se connecter à la source), procédez comme suit :
-
Choisissez le flux que vous avez créé dans la section précédente.
-
Choisissez de créer un rôle IAM.
-
Choisissez Discover schema (Découvrir le schéma). Attendez que la console affiche le schéma déduit et les exemples d'enregistrements qui sont utilisés pour déduire le schéma pour le flux intégré à l'application créé. Le schéma déduit comporte deux colonnes.
-
Choisissez Edit schema (Modifier le schéma). Remplacez le Column type (Type de colonne) de la colonne EVENT_TIME par
TIMESTAMP. -
Choisissez Save schema and update stream samples (Enregistrer le schéma et mettre à jour les exemples de flux). Une fois que la console a enregistré le schéma, choisissez Exit (Quitter).
-
Choisissez Save and continue (Enregistrer et continuer).
-
-
Sur la page de détails de l'application, choisissez Go to SQL editor (Accéder à l'éditeur SQL). Pour lancer l'application, choisissez Yes, start application (Oui, démarrer l'application) dans la boîte de dialogue qui s'affiche.
-
Dans l'éditeur SQL, écrivez le code d'application et vérifiez les résultats comme suit :
-
Copiez le code d'application suivant et collez-le dans l'éditeur.
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" ( TICKER VARCHAR(4), event_time TIMESTAMP, five_minutes_before TIMESTAMP, event_unix_timestamp BIGINT, event_timestamp_as_char VARCHAR(50), event_second INTEGER); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM TICKER, EVENT_TIME, EVENT_TIME - INTERVAL '5' MINUTE, UNIX_TIMESTAMP(EVENT_TIME), TIMESTAMP_TO_CHAR('yyyy-MM-dd hh:mm:ss', EVENT_TIME), EXTRACT(SECOND FROM EVENT_TIME) FROM "SOURCE_SQL_STREAM_001" -
Choisissez Save and run SQL (Enregistrer et exécuter SQL). Dans l'onglet Real-time analytics (Analyse en temps réel), vous pouvez voir tous les flux intégrés à l'application que l'application a créés et vérifier les données.
-
