Après mûre réflexion, nous avons décidé de mettre fin à Amazon Kinesis Data Analytics pour les applications SQL :
1. À compter du 1er septembre 2025, nous ne fournirons aucune correction de bogue pour les applications Amazon Kinesis Data Analytics for SQL, car leur support sera limité, compte tenu de l'arrêt prochain.
2. À compter du 15 octobre 2025, vous ne pourrez plus créer de nouvelles applications Kinesis Data Analytics for SQL.
3. Nous supprimerons vos candidatures à compter du 27 janvier 2026. Vous ne serez pas en mesure de démarrer ou d'utiliser vos applications Amazon Kinesis Data Analytics for SQL. Support ne sera plus disponible pour Amazon Kinesis Data Analytics for SQL à partir de cette date. Pour de plus amples informations, veuillez consulter Arrêt d'Amazon Kinesis Data Analytics pour les applications SQL.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Exemple : Analyse de journaux web (fonction W3C_LOG_PARSE)
Cet exemple utilise la fonction W3C_LOG_PARSE pour transformer une chaîne dans Amazon Kinesis Data Analytics. Vous pouvez utiliser W3C_LOG_PARSE pour formater rapidement des journaux Apache. Pour plus d’informations, consultez la section W3C_LOG_PARSE dans le manuel Référence SQL du service géré Amazon pour Apache Flink.
Dans cet exemple, vous écrivez des enregistrements de journaux dans un flux de données Amazon Kinesis. Les exemples de journaux affichés sont les suivants :
{"Log":"192.168.254.30 - John [24/May/2004:22:01:02 -0700] "GET /icons/apache_pba.gif HTTP/1.1" 304 0"} {"Log":"192.168.254.30 - John [24/May/2004:22:01:03 -0700] "GET /icons/apache_pbb.gif HTTP/1.1" 304 0"} {"Log":"192.168.254.30 - John [24/May/2004:22:01:04 -0700] "GET /icons/apache_pbc.gif HTTP/1.1" 304 0"} ...
Vous créez ensuite une application Kinesis Data Analytics dans la console, avec le flux de données Kinesis comme source de streaming. Le processus de découverte lit les exemples d'enregistrements de la source de diffusion et déduit un schéma intégré à l'application avec une colonne (log), comme illustré ci-après :
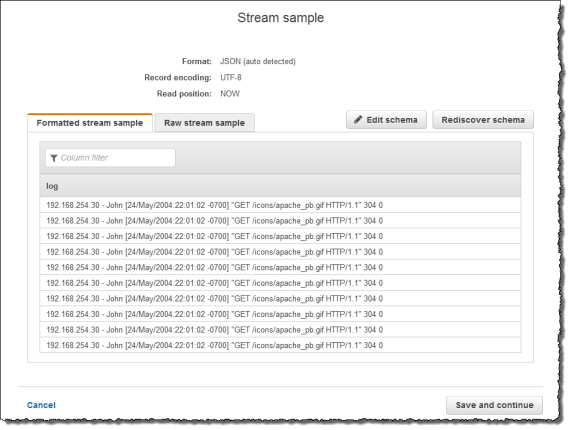
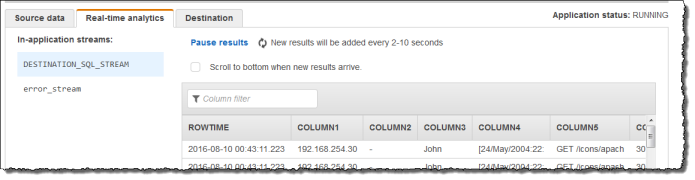
Ensuite, vous utilisez le code d'application avec la fonction W3C_LOG_PARSE pour analyser le journal et créer un autre flux intégré à l'application avec différents champs de journal dans des colonnes distinctes, comme illustré ci-après :
Rubriques
Étape 1 : Création d’un flux de données Kinesis
Créez un flux de données Amazon Kinesis et remplissez les enregistrements de journaux comme suit :
-
Choisissez Data Streams (Flux de données) dans le volet de navigation.
-
Choisissez Create Kinesis stream (Créer un flux Kinesis), puis créez un flux avec une seule partition. Pour de plus amples informations, consultez Créer un flux dans le Guide du développeur Amazon Kinesis Data Streams.
-
Exécutez le code Python suivant pour remplir les exemples d'enregistrements de journal. Ce code simple écrit en continu le même enregistrement de journal dans le flux.
import json import boto3 STREAM_NAME = "ExampleInputStream" def get_data(): return { "log": "192.168.254.30 - John [24/May/2004:22:01:02 -0700] " '"GET /icons/apache_pb.gif HTTP/1.1" 304 0' } def generate(stream_name, kinesis_client): while True: data = get_data() print(data) kinesis_client.put_record( StreamName=stream_name, Data=json.dumps(data), PartitionKey="partitionkey" ) if __name__ == "__main__": generate(STREAM_NAME, boto3.client("kinesis"))
Étape 2 : Création d’une application Kinesis Data Analytics
Créez une application Kinesis Data Analytics comme suit :
Ouvrez le service géré pour la console Apache Flink à l'adresse https://console.aws.amazon.com/kinesisanalytics.
-
Choisissez Create application (Créer une application), saisissez un nom d'application, puis sélectionnez Create application (Créer une application).
-
Sur la page de détails de l'application, choisissez Connect streaming data (Connecter des données de diffusion).
-
Sur la page Connect to source (Se connecter à la source), procédez comme suit :
-
Choisissez le flux que vous avez créé dans la section précédente.
-
Choisissez l'option de création d'un rôle IAM.
-
Choisissez Discover schema (Découvrir le schéma). Attendez que la console affiche le schéma déduit et les exemples d'enregistrements utilisés pour déduire le schéma pour le flux intégré à l'application créé. Le schéma déduit ne comporte qu'une seule colonne.
-
Choisissez Save and continue (Enregistrer et continuer).
-
-
Sur la page de détails de l'application, choisissez Go to SQL editor (Accéder à l'éditeur SQL). Pour lancer l'application, choisissez Yes, start application (Oui, démarrer l'application) dans la boîte de dialogue qui s'affiche.
-
Dans l'éditeur SQL, écrivez le code d'application et vérifiez les résultats comme suit :
-
Copiez le code d'application suivant et collez-le dans l'éditeur.
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" ( column1 VARCHAR(16), column2 VARCHAR(16), column3 VARCHAR(16), column4 VARCHAR(16), column5 VARCHAR(16), column6 VARCHAR(16), column7 VARCHAR(16)); CREATE OR REPLACE PUMP "myPUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM l.r.COLUMN1, l.r.COLUMN2, l.r.COLUMN3, l.r.COLUMN4, l.r.COLUMN5, l.r.COLUMN6, l.r.COLUMN7 FROM (SELECT STREAM W3C_LOG_PARSE("log", 'COMMON') FROM "SOURCE_SQL_STREAM_001") AS l(r); -
Choisissez Save and run SQL (Enregistrer et exécuter SQL). Dans l'onglet Real-time analytics (Analyse en temps réel), vous pouvez voir tous les flux intégrés à l'application que l'application a créés et vérifier les données.
-
