Après mûre réflexion, nous avons décidé de mettre fin à Amazon Kinesis Data Analytics SQL pour les applications en deux étapes :
1. À compter du 15 octobre 2025, vous ne pourrez plus créer de nouveaux Kinesis Data Analytics SQL pour les applications.
2. Nous supprimerons vos candidatures à compter du 27 janvier 2026. Vous ne serez pas en mesure de démarrer ou d'utiliser votre Amazon Kinesis Data Analytics SQL pour les applications. Support ne sera plus disponible pour Amazon Kinesis Data Analytics à partir SQL de cette date. Pour de plus amples informations, veuillez consulter Arrêt d'Amazon Kinesis Data Analytics SQL pour applications.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Applications Amazon Kinesis Data Analytics pour SQL : fonctionnement
Note
Après le 12 septembre 2023, vous ne pourrez plus créer de nouvelles applications en utilisant Kinesis Data Firehose comme source si vous n’utilisez pas déjà Kinesis Data Analytics pour SQL. Pour plus d’informations, consultez Limites .
Une application est la ressource principale d’Amazon Kinesis Data Analytics que vous pouvez créer dans votre compte. Vous pouvez créer et gérer des applications à l'aide de l' AWS Management Console API ou de l'API Kinesis Data Analytics. Kinesis Data Analytics fournit des opérations d’API pour gérer les applications. Pour obtenir une liste d'opérations d'API, consultez Actions.
Les applications Kinesis Data Analytics lisent et traitent en continu les données de streaming en temps réel. Vous écrivez le code d'application à l'aide de SQL pour traiter les données de diffusion entrantes et produire la sortie. Kinesis Data Analytics écrit ensuite la sortie vers une destination configurée. Le graphique suivant illustre une architecture d'applications typique.
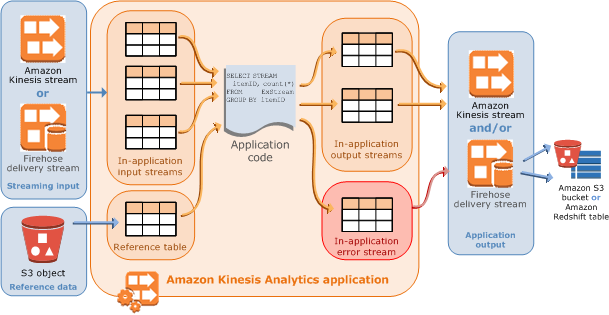
Chaque application possède un nom, une description, un ID de version et un statut. Amazon Kinesis Data Analytics attribue un ID de version lorsque vous créez une application pour la première fois. Cet ID de version est mis à jour lorsque vous mettez à jour une configuration d'application. Par exemple, si vous ajoutez une configuration d’entrée, si vous ajoutez ou supprimez une source de données de référence, si vous ajoutez ou supprimez une configuration de sortie, ou si vous mettez à jour le code d’application, Kinesis Data Analytics met à jour l’ID de version de l’application actuel. Kinesis Data Analytics gère également les horodatages des moments où une application a été créée et mise à jour pour la dernière fois.
En plus de ces propriétés de base, chaque application comprend les éléments suivants :
-
Entrée : La source de streaming pour votre application. Vous pouvez sélectionner un flux de données Kinesis ou un flux de diffusion de données Firehose comme source de diffusion. Dans la configuration d'entrée, vous mappez la source de diffusion à un flux d'entrée intégré à l'application. Le flux intégré à l'application s'apparente à une table mise à jour en continu sur laquelle vous pouvez effectuer les opérations
SELECTetINSERT SQL. Dans votre code d'application, vous pouvez créer des flux intégrés à l'application supplémentaires pour stocker des résultats de requête intermédiaires.Vous pouvez partitionner le cas échéant une source de diffusion unique en plusieurs flux d'entrée intégrés à l'application pour améliorer le débit. Pour plus d’informations, consultez Limites et Configuration de l'entrée de l'application.
Amazon Kinesis Data Analytics fournit une colonne d’horodatage dans chaque flux d’application, appelée Horodatages et colonne ROWTIME. Vous pouvez utiliser cette colonne dans des requêtes à fenêtres temporelles. Pour de plus amples informations, veuillez consulter Requêtes à fenêtres.
Vous pouvez configurer une source de données de référence pour enrichir votre flux de données d'entrée au sein de l'application. Celle-ci crée une table de référence intégrée à l'application. Vous devez stocker vos données de référence en tant qu'objet dans votre compartiment S3. Lorsque l’application démarre, Amazon Kinesis Data Analytics lit l’objet Amazon S3 et crée une table intégrée à l’application. Pour de plus amples informations, veuillez consulter Configuration de l'entrée de l'application.
-
Code d’application : Ensemble d’instructions SQL qui traite une entrée et produit une sortie. Vous pouvez écrire des instructions SQL sur des flux et des tables de référence intégrés à l'application. Vous pouvez également écrire des requêtes JOIN pour combiner des données provenant de ces deux sources.
Pour plus d’informations sur les éléments du langage SQL pris en charge par Kinesis Data Analytics, consultez la Référence SQL Amazon Kinesis Data Analytics.
Dans sa forme la plus simple, le code d'application peut être une instruction SQL unique qui effectue une sélection à partir d'une entrée de diffusion et insère les résultats dans une sortie de diffusion. Il peut également s'agir d'un ensemble d'instructions SQL où la sortie d'un flux alimente l'entrée de l'instruction SQL suivante. En outre, vous pouvez écrire un code d'application pour scinder un flux d'entrée en plusieurs flux. Vous pouvez ensuite appliquer des requêtes supplémentaires pour traiter ces flux. Pour de plus amples informations, veuillez consulter Code d'application.
-
Sortie : Dans le code d’application, les résultats d’une requête sont transmis à des flux intégrés à l’application. Dans votre code d'application, vous pouvez créer un ou plusieurs flux intégrés à l'application pour stocker des résultats intermédiaires. Vous pouvez ensuite configurer, le cas échéant, une sortie d'application pour conserver des données des flux intégrés à l'application qui contiennent votre sortie d'application (également appelés flux de sortie intégrés à l'application) dans des destinations externes. Les destinations externes peuvent être un flux de diffusion Firehose ou un flux de données Kinesis. Notez les points suivants à propos de ces destinations :
-
Vous pouvez configurer un flux de diffusion Firehose pour écrire les résultats sur Amazon S3, Amazon Redshift ou OpenSearch Amazon Service (ServiceOpenSearch ).
-
Vous pouvez également écrire une sortie d’application dans une destination personnalisée, au lieu d’Amazon S3 ou Amazon Redshift. Pour ce faire, vous devez spécifier un flux de données Kinesis comme destination dans votre configuration de sortie. Ensuite, vous configurez AWS Lambda pour interroger le flux et appeler votre fonction Lambda. Le code de votre fonction Lambda reçoit des données de flux comme entrée. Dans le code de votre fonction Lambda, vous pouvez écrire les données entrantes dans votre destination personnalisée. Pour plus d'informations, consultez Utilisation AWS Lambda avec Amazon Kinesis Data Analytics.
Pour de plus amples informations, veuillez consulter Configuration de la sortie d'application.
-
En outre, notez les éléments suivants :
-
Amazon Kinesis Data Analytics a besoin d’autorisations pour lire les enregistrements à partir d’une source de streaming et écrire la sortie d’application dans les destinations externes. Vous utilisez des rôles IAM pour accorder ces autorisations.
-
Kinesis Data Analytics fournit automatiquement un flux d’erreurs intégré à l’application pour chaque application. Si votre application rencontre des problèmes lors du traitement de certains enregistrements (par exemple en raison d'une incompatibilité de type ou d'une arrivée tardive), ces enregistrements seront écrits dans le flux d'erreurs. Vous pouvez configurer la sortie d’application pour demander à Kinesis Data Analytics de conserver les données du flux d’erreurs dans une destination externe pour une évaluation plus approfondie. Pour de plus amples informations, veuillez consulter Gestion des erreurs.
-
Amazon Kinesis Data Analytics s’assure que vos enregistrements de sortie d’application sont écrits dans la destination configurée. Il utilise un modèle de traitement et de diffusion « au moins une fois », même en cas d'interruption de l'application. Pour de plus amples informations, veuillez consulter Modèle de diffusion pour la conservation de la sortie d'application dans une destination externe.
