Après mûre réflexion, nous avons décidé de mettre fin à Amazon Kinesis Data Analytics SQL pour les applications en deux étapes :
1. À compter du 15 octobre 2025, vous ne pourrez plus créer de nouveaux Kinesis Data Analytics SQL pour les applications.
2. Nous supprimerons vos candidatures à compter du 27 janvier 2026. Vous ne serez pas en mesure de démarrer ou d'utiliser votre Amazon Kinesis Data Analytics SQL pour les applications. Support ne sera plus disponible pour Amazon Kinesis Data Analytics à partir SQL de cette date. Pour de plus amples informations, veuillez consulter Arrêt d'Amazon Kinesis Data Analytics SQL pour applications.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Exemples de migration vers le service géré pour Apache Flink Studio
Après mûre réflexion, nous avons décidé de mettre fin à Amazon Kinesis Data Analytics SQL pour les applications. Pour vous aider à planifier et à migrer hors d'Amazon Kinesis Data Analytics SQL pour les applications, nous supprimerons progressivement l'offre sur une période de 15 mois. Il y a deux dates importantes à noter, le 15 octobre 2025 et le 27 janvier 2026.
-
À compter du 15 octobre 2025, vous ne pourrez plus créer de nouveaux Amazon Kinesis Data Analytics SQL pour les applications.
-
Nous supprimerons vos candidatures à compter du 27 janvier 2026. Vous ne serez pas en mesure de démarrer ou d'utiliser votre Amazon Kinesis Data Analytics SQL pour les applications. Support ne sera plus disponible pour Amazon Kinesis Data Analytics SQL pour les applications à partir de cette date. Pour en savoir plus, consultez Arrêt d'Amazon Kinesis Data Analytics SQL pour applications.
Nous vous recommandons d'utiliser Amazon Managed Service pour Apache Flink. Il allie facilité d'utilisation et fonctionnalités analytiques avancées, vous permettant de créer des applications de traitement de flux en quelques minutes.
Cette section fournit des exemples de code et d'architecture pour vous aider à transférer vos charges de travail Amazon Kinesis Data Analytics SQL pour applications vers Managed Service for Apache Flink.
Pour plus d'informations, consultez également ce billet de AWS blog : Migrer d'Amazon Kinesis Data Analytics SQL for Applications vers un service géré pour Apache Flink
Cette section fournit des conversions de requêtes que vous pouvez utiliser pour les cas d’utilisation courants lors de la migration de vos charges de travail vers le service géré pour Apache Flink Studio ou le service géré pour Apache Flink.
Avant d'explorer ces exemples, nous vous recommandons de consulter d'abord l'article Utilisation d'un bloc-notes Studio avec un service géré pour Apache Flink.
Recréation de Kinesis Data Analytics SQL pour les requêtes dans Managed Service pour Apache Flink Studio
Les options suivantes fournissent des traductions des requêtes courantes SQL de l'application Kinesis Data Analytics vers le service géré pour Apache Flink Studio.
Si vous souhaitez transférer des charges de travail utilisant Random Cut Forest de Kinesis Analytics vers Managed Service SQL for Apache Flink, AWS ce billet de blog
Voir Converting- KDASQL -KDAStudio/
Dans l’exercice suivant, vous allez modifier votre flux de données afin d’utiliser le service géré Amazon pour Apache Flink Studio. Cela impliquera également de passer d’Amazon Kinesis Data Firehose à Amazon Kinesis Data Streams.
Nous partageons d'abord une SQL architecture typiqueKDA, avant de montrer comment vous pouvez la remplacer à l'aide d'Amazon Managed Service pour Apache Flink Studio et Amazon Kinesis Data Streams. Vous pouvez également lancer le AWS CloudFormation modèle ici
Amazon Kinesis Data Analytics SQL - et Amazon Kinesis Data Firehose
Voici le flux architectural d'Amazon Kinesis Data SQL Analytics :
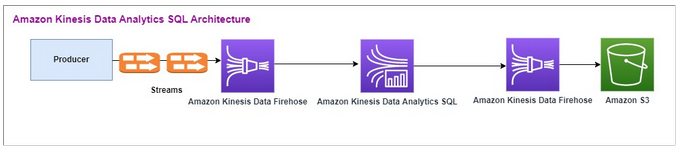
Nous examinons d'abord la configuration d'un ancien Amazon Kinesis Data Analytics SQL et d'Amazon Kinesis Data Firehose. Le cas d’utilisation concerne un marché boursier sur lequel des données commerciales, notamment des données de symbole boursier et de cours des actions, sont transmises depuis des sources externes aux systèmes Amazon Kinesis. Amazon Kinesis Data Analytics SQL for utilise le flux d'entrée pour exécuter des requêtes fenêtrées, telles que la fenêtre Tumblingmax, afin de déterminer le volume des transactions et min le cours des transactions sur une fenêtre d'une minute pour chaque ticker boursier. average
Amazon Kinesis Data Analytics SQL est configuré pour ingérer les données d'Amazon Kinesis Data Firehose. API Après le traitement, Amazon Kinesis Data Analytics envoie SQL les données traitées à un autre Amazon Kinesis Data Firehose, qui enregistre ensuite le résultat dans un compartiment Amazon S3.
Dans ce cas, vous utilisez Amazon Kinesis Data Generator. Amazon Kinesis Data Generator vous permet d’envoyer des données de test à vos flux de diffusion Amazon Kinesis Data Streams ou Amazon Kinesis Data Firehose. Pour commencer, suivez les instructions ici
Une fois le AWS CloudFormation modèle exécuté, la section de sortie fournit l'URL d'Amazon Kinesis Data Generator. Connectez-vous au portail à l’aide de l’identifiant utilisateur et du mot de passe Cognito que vous avez définis ici
Vous trouverez ci-dessous un exemple de charge utile utilisant Amazon Kinesis Data Generator. Le générateur de données cible les flux Amazon Kinesis Firehose en entrée pour diffuser les données en continu. Le SDK client Amazon Kinesis peut également envoyer des données provenant d'autres producteurs.
2023-02-17 09:28:07.763,"AAPL",5032023-02-17 09:28:07.763, "AMZN",3352023-02-17 09:28:07.763, "GOOGL",1852023-02-17 09:28:07.763, "AAPL",11162023-02-17 09:28:07.763, "GOOGL",1582
Ce qui suit JSON est utilisé pour générer une série aléatoire d'heure et de date de transaction, de code boursier et de cours de l'action :
date.now(YYYY-MM-DD HH:mm:ss.SSS), "random.arrayElement(["AAPL","AMZN","MSFT","META","GOOGL"])", random.number(2000)
Une fois que vous avez choisi Envoyer les données, le générateur commence à envoyer des données fictives.
Les systèmes externes transmettent les données à Amazon Kinesis Data Firehose. À l'aide d'Amazon Kinesis Data Analytics SQL for Applications, vous pouvez analyser les données de streaming selon SQL les normes. Le service vous permet de créer et d'exécuter SQL du code sur des sources de streaming pour effectuer des analyses de séries chronologiques, alimenter des tableaux de bord en temps réel et créer des métriques en temps réel. Amazon Kinesis Data Analytics SQL for Applications peut créer un flux de destination SQL à partir de requêtes sur le flux d'entrée et envoyer le flux de destination à un autre Amazon Kinesis Data Firehose. L’Amazon Kinesis Data Firehose de destination peut envoyer les données analytiques à Amazon S3 en dernière étape.
Amazon Kinesis Data Analytics SQL : le code existant est basé sur une extension SQL de Standard.
Vous utilisez la requête suivante dans Amazon Kinesis Data Analytics SQL -. Vous créez d’abord un flux de destination pour la sortie de requête. Ensuite, vous PUMP utiliseriez un objet du référentiel Amazon Kinesis Data Analytics (une extension de SQL la norme) qui fournit une fonctionnalité de requête INSERT INTO stream SELECT ... FROM continue, permettant ainsi de saisir les résultats d'une requête en continu dans un flux nommé.
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (EVENT_TIME TIMESTAMP, INGEST_TIME TIMESTAMP, TICKER VARCHAR(16), VOLUME BIGINT, AVG_PRICE DOUBLE, MIN_PRICE DOUBLE, MAX_PRICE DOUBLE); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM STEP("SOURCE_SQL_STREAM_001"."tradeTimestamp" BY INTERVAL '60' SECOND) AS EVENT_TIME, STEP("SOURCE_SQL_STREAM_001".ROWTIME BY INTERVAL '60' SECOND) AS "STREAM_INGEST_TIME", "ticker", COUNT(*) AS VOLUME, AVG("tradePrice") AS AVG_PRICE, MIN("tradePrice") AS MIN_PRICE, MAX("tradePrice") AS MAX_PRICEFROM "SOURCE_SQL_STREAM_001" GROUP BY "ticker", STEP("SOURCE_SQL_STREAM_001".ROWTIME BY INTERVAL '60' SECOND), STEP("SOURCE_SQL_STREAM_001"."tradeTimestamp" BY INTERVAL '60' SECOND);
Ce qui précède SQL utilise deux fenêtres temporelles : tradeTimestamp celle qui provient de la charge utile du flux entrant et ROWTIME.tradeTimestamp est également appelée Event Time ouclient-side time. Il est souvent préférable d'utiliser cette heure dans les analyses car il s'agit du moment où un événement s'est produit. Cependant, de nombreuses sources d'événements, telles que les téléphones mobiles et les clients web, n'ont pas horloges fiables, ce qui peut entraîner des heures inexactes. En outre, des problèmes de connectivité peuvent provoquer le fait que des enregistrements figurant dans un flux ne sont pas dans le même ordre que celui où les événements se sont produits.
Les flux intégrés à l’application incluent également une colonne spéciale appelée ROWTIME. Celle-ci stocke un horodatage quand Amazon Kinesis Data Analytics insère une ligne dans le premier flux intégré à l’application. ROWTIME reflète l’horodatage du moment où Amazon Kinesis Data Analytics a inséré un enregistrement dans le premier flux intégré à l’application après la lecture de la source de streaming. Cette valeur ROWTIME est ensuite gérée tout au long de votre application.
Le SQL détermine le nombre de tickers sous forme devolume, minmax, et le average prix sur un intervalle de 60 secondes.
L'utilisation de chacun de ces types d'heure dans des requêtes à fenêtres temporelles présente des avantages et des inconvénients. Sélectionnez un ou plusieurs de ces types d’heure, et une stratégie pour traiter les inconvénients pertinents en fonction du scénario d’utilisation.
Une stratégie à deux fenêtres utilise deux types d’heure, ROWTIME et l’un des autres types d’heure, comme l’heure de l’événement.
-
Utilisez
ROWTIMEcomme première fenêtre, qui contrôle la fréquence à laquelle la requête émet les résultats, comme illustré dans l'exemple suivant. Cette valeur n'est pas utilisée comme une heure logique. -
Utilisez l'un des autres types d'heure comme heure logique à associer à vos analyses. Cette heure représente le moment où l'événement s'est produit. Dans l'exemple suivant, l'objectif de l'analyse est de regrouper les enregistrements et de renvoyer un comptage par symbole boursier.
Service géré Amazon pour Apache Flink Studio
Dans l’architecture mise à jour, vous remplacez Amazon Kinesis Data Firehose par Amazon Kinesis Data Streams. Amazon Kinesis Data Analytics SQL for Applications est remplacé par Amazon Managed Service pour Apache Flink Studio. Le code Apache Flink est exécuté de manière interactive dans un bloc-notes Apache Zeppelin. Le service géré Amazon pour Apache Flink Studio envoie les données commerciales agrégées vers un compartiment Amazon S3 en vue de leur stockage. Les étapes sont indiquées ci-dessous :
Voici le flux architectural du service géré Amazon pour Apache Flink Studio :

Créer un flux de données Kinesis
Pour créer un flux de données avec la console
-
Dans la barre de navigation, développez le sélecteur de région et choisissez une région.
-
Choisissez Create data stream (Créer un flux de données).
-
Sur la page Créer un flux Kinesis, saisissez le nom de votre flux de données, puis acceptez le mode de capacité à la demande par défaut.
En mode à la demande, vous pouvez ensuite choisir Créer un flux Kinesis pour créer votre flux de données.
Dans la page Flux Kinesis, la valeur Statut de votre flux est En création lorsque le flux est en cours de création. Lorsque le flux est à prêt à être utilisé, le statut passe à Actif.
-
Choisissez le nom de votre flux. La page Détails du flux affiche un récapitulatif de la configuration de flux, ainsi que des informations de surveillance.
-
Dans le générateur de données Amazon Kinesis, remplacez le flux ou le flux de diffusion par le nouveau flux Amazon Kinesis Data Streams : _ _. TRADE SOURCE STREAM
JSONet la charge utile sera la même que celle que vous avez utilisée pour Amazon Kinesis Data Analytics-. SQL Utilisez le générateur de données Amazon Kinesis pour produire des exemples de données de charge utile de trading et ciblez le flux de STREAM données TRADE_ SOURCE _ pour cet exercice :
{{date.now(YYYY-MM-DD HH:mm:ss.SSS)}}, "{{random.arrayElement(["AAPL","AMZN","MSFT","META","GOOGL"])}}", {{random.number(2000)}} -
AWS Management Console Accédez à Managed Service for Apache Flink, puis choisissez Create application.
-
Dans le panneau de navigation à gauche, sélectionnez Blocs-notes Studio, puis Créer un bloc-notes Studio.
-
Saisissez un nom pour le bloc-notes Studio.
-
Sous Base de données AWS Glue, indiquez une base de données AWS Glue existante qui définira les métadonnées de vos sources et destinations. Si vous n'avez pas de AWS Glue base de données, choisissez Create et procédez comme suit :
-
Dans la console AWS Glue, choisissez Databases sous Catalogue de données dans le menu de gauche.
-
Sélectionnez Créer une base de données.
-
Sur la page Créer une base de données, saisissez un nom pour la base de données. Dans la section Emplacement - facultatif, choisissez Parcourir Amazon S3 et sélectionnez le compartiment Amazon S3. Si vous n'avez pas de compartiment Amazon S3 déjà configuré, vous pouvez ignorer cette étape et y revenir plus tard.
-
(Facultatif). Saisissez une description pour la base de données.
-
Choisissez Créer une base de données.
-
-
Choisissez Créer un bloc-notes.
-
Une fois votre bloc-notes créé, choisissez Exécuter.
-
Une fois le bloc-notes démarré avec succès, lancez un bloc-notes Zeppelin en choisissant Ouvrir dans Apache Zeppelin.
-
Sur la page Zeppelin Notebook, choisissez Créer une nouvelle note et nommez-la. MarketDataFeed
Le SQL code Flink est expliqué ci-dessous, mais voici d'abord à quoi ressemble un écran d'ordinateur portable Zeppelin
Code de service géré Amazon pour Apache Flink Studio
Le service géré Amazon pour Apache Flink Studio utilise les blocs-notes Zeppelin pour exécuter le code. Pour cet exemple, le mappage est effectué avec du code SSQL basé sur Apache Flink 1.13. Le code du carnet Zeppelin est affiché ci-dessous, bloc par bloc.
Avant d’exécuter du code dans votre bloc-notes Zeppelin, les commandes de configuration Flink doivent être exécutées. Si vous devez modifier un paramètre de configuration après avoir exécuté du code (ssql, Python ou Scala), vous devez arrêter et redémarrer votre bloc-notes. Dans cet exemple, vous devez définir le point de contrôle. Un point de contrôle est nécessaire pour diffuser des données vers un fichier dans Amazon S3. Cela permet de transférer vers un fichier la diffusion de données vers Amazon S3. L'instruction suivante définit l'intervalle à 5 000 millisecondes.
%flink.conf execution.checkpointing.interval 5000
%flink.conf indique que ce bloc est constitué d’instructions de configuration. Pour plus d'informations sur la configuration de Flink, y compris le pointage de contrôle, voir Apache Flink
La table d'entrée pour la source Amazon Kinesis Data Streams est créée avec le code Flink ssql suivant. Notez que le champ TRADE_TIME enregistre la date et l’heure de création par le générateur de données.
%flink.ssql DROP TABLE IF EXISTS TRADE_SOURCE_STREAM; CREATE TABLE TRADE_SOURCE_STREAM (--`arrival_time` TIMESTAMP(3) METADATA FROM 'timestamp' VIRTUAL, TRADE_TIME TIMESTAMP(3), WATERMARK FOR TRADE_TIME as TRADE_TIME - INTERVAL '5' SECOND,TICKER STRING,PRICE DOUBLE, STATUS STRING)WITH ('connector' = 'kinesis','stream' = 'TRADE_SOURCE_STREAM', 'aws.region' = 'us-east-1','scan.stream.initpos' = 'LATEST','format' = 'csv');
Vous pouvez afficher le flux d’entrée avec cette instruction :
%flink.ssql(type=update)-- testing the source stream select * from TRADE_SOURCE_STREAM;
Avant d’envoyer les données agrégées à Amazon S3, vous pouvez les afficher directement dans le service géré Amazon pour Apache Flink Studio à l’aide d’une requête de sélection à fenêtres bascules. Cela agrège les données de trading dans une fenêtre de temps d'une minute. Notez que l’instruction %flink.ssql doit avoir une désignation (type=update) :
%flink.ssql(type=update) select TUMBLE_ROWTIME(TRADE_TIME, INTERVAL '1' MINUTE) as TRADE_WINDOW, TICKER, COUNT(*) as VOLUME, AVG(PRICE) as AVG_PRICE, MIN(PRICE) as MIN_PRICE, MAX(PRICE) as MAX_PRICE FROM TRADE_SOURCE_STREAMGROUP BY TUMBLE(TRADE_TIME, INTERVAL '1' MINUTE), TICKER;
Vous pouvez ensuite créer une table de destination dans Amazon S3. Vous devez utiliser un filigrane. Un filigrane est une mesure de progression qui indique un instant donné à partir duquel vous êtes certain qu’aucun autre événement retardé ne se produira. L’objectif du filigrane est de prendre en compte les arrivées tardives. L’intervalle ‘5’ Second permet aux transactions d’entrer dans le flux Amazon Kinesis Data Streams avec 5 secondes de retard et d’être incluses si elles sont horodatées dans cette fenêtre. Pour plus d'informations, consultez la section Génération de filigranes
%flink.ssql(type=update) DROP TABLE IF EXISTS TRADE_DESTINATION_S3; CREATE TABLE TRADE_DESTINATION_S3 ( TRADE_WINDOW_START TIMESTAMP(3), WATERMARK FOR TRADE_WINDOW_START as TRADE_WINDOW_START - INTERVAL '5' SECOND, TICKER STRING, VOLUME BIGINT, AVG_PRICE DOUBLE, MIN_PRICE DOUBLE, MAX_PRICE DOUBLE) WITH ('connector' = 'filesystem','path' = 's3://trade-destination/','format' = 'csv');
Cette instruction insère les données dans le code TRADE_DESTINATION_S3. TUMPLE_ROWTIME correspond à l’horodatage de la limite supérieure incluse de la fenêtre bascule.
%flink.ssql(type=update) insert into TRADE_DESTINATION_S3 select TUMBLE_ROWTIME(TRADE_TIME, INTERVAL '1' MINUTE), TICKER, COUNT(*) as VOLUME, AVG(PRICE) as AVG_PRICE, MIN(PRICE) as MIN_PRICE, MAX(PRICE) as MAX_PRICE FROM TRADE_SOURCE_STREAM GROUP BY TUMBLE(TRADE_TIME, INTERVAL '1' MINUTE), TICKER;
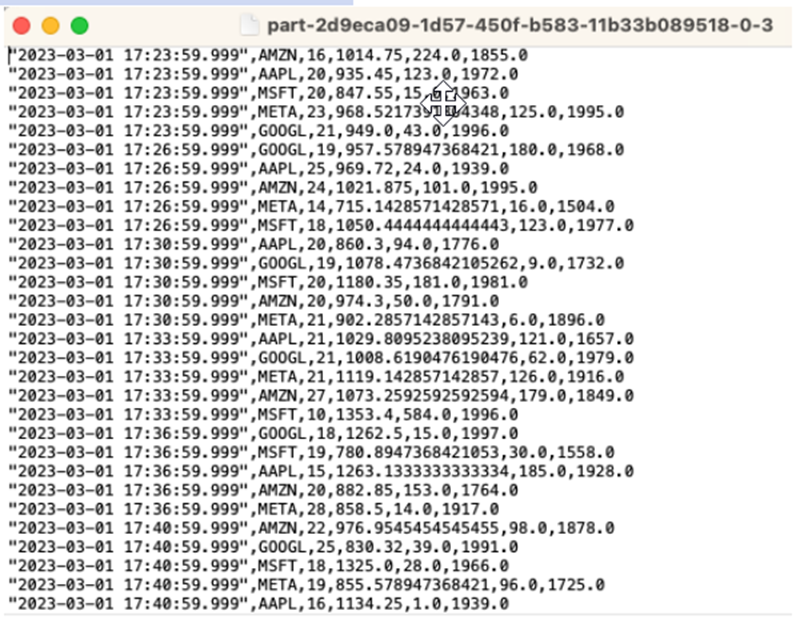
Exécutez votre instruction pendant 10 à 20 minutes afin d’accumuler des données dans Amazon S3. Puis annulez l’instruction.
Cela ferme le fichier dans Amazon S3 afin qu’il soit consultable.
Voici à quoi ressemble le contenu :
Vous pouvez utiliser le modèle AWS CloudFormation
AWS CloudFormation créera les ressources suivantes dans votre AWS compte :
-
Amazon Kinesis Data Streams
-
Service géré Amazon pour Apache Flink Studio
-
AWS Glue base de données
-
Compartiment Amazon S3
-
IAMrôles et politiques permettant à Amazon Managed Service pour Apache Flink Studio d'accéder aux ressources appropriées
Importez le bloc-notes et remplacez le nom du compartiment Amazon S3 par le nouveau compartiment Amazon S3 créé par AWS CloudFormation.

Voir plus
Voici quelques ressources supplémentaires que vous pouvez utiliser pour en savoir plus sur l'utilisation du service géré pour Apache Flink Studio :
L'objectif de ce modèle est de montrer comment tirer parti UDFs des blocs-notes Zeppelin de Kinesis Data Analytics-Studio pour traiter les données du flux Kinesis. Le service géré pour Apache Flink Studio utilise Apache Flink pour fournir des fonctionnalités analytiques avancées, notamment une sémantique de traitement unique, des fenêtres temporelles, une extensibilité grâce à des fonctions définies par l'utilisateur et des intégrations client, une prise en charge linguistique impérative, un état durable des applications, une mise à l'échelle horizontale, la prise en charge de plusieurs sources de données, des intégrations extensibles, etc. Ils sont essentiels pour garantir l'exactitude, l'exhaustivité, la cohérence et la fiabilité du traitement des flux de données et ne sont pas disponibles avec Amazon Kinesis Data Analytics SQL pour.
Dans cet exemple d'application, nous allons montrer comment tirer parti UDFs du bloc-notes KDA -Studio Zeppelin pour traiter les données du flux Kinesis. Les blocs-notes Studio pour Kinesis Data Analytics vous permettent d'interroger des flux de données de manière interactive en temps réel, et de créer et d'exécuter facilement des applications de traitement de flux à l'aide de standardsSQL, Python et Scala. En quelques clics AWS Management Console, vous pouvez lancer un bloc-notes sans serveur pour interroger des flux de données et obtenir des résultats en quelques secondes. Pour plus d’informations, consultez Utilisation d’un bloc-notes Studio avec Kinesis Data Analytics pour Apache Flink.
Fonctions Lambda utilisées pour le prétraitement et le post-traitement des données dans les applications : KDA SQL
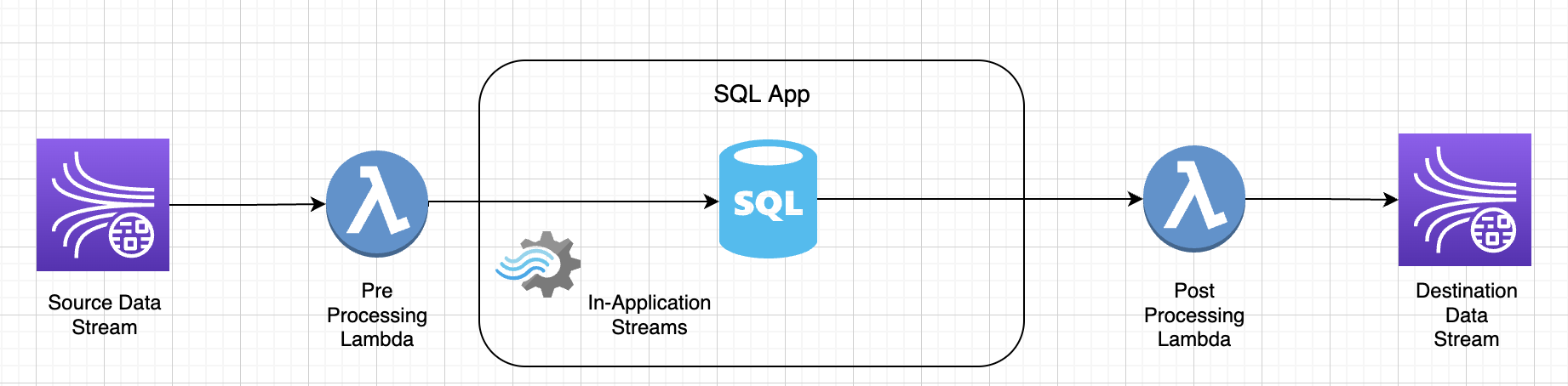
Fonctions définies par l'utilisateur pour le pré/post-traitement des données à l'aide KDA des ordinateurs portables -Studio Zeppelin
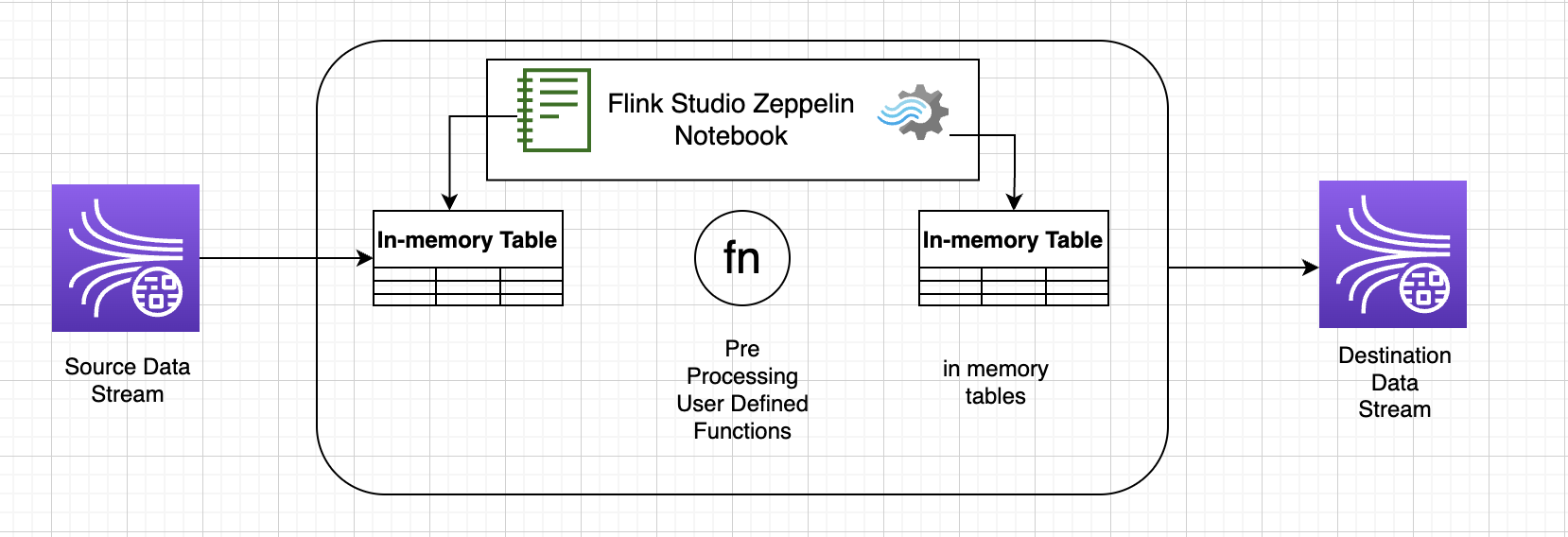
Fonctions définies par l'utilisateur () UDFs
Pour réutiliser une logique métier courante dans un opérateur, il peut être utile de référencer une fonction définie par l’utilisateur afin de transformer votre flux de données. Vous pouvez le faire soit dans le bloc-notes du service géré pour Apache Flink Studio, soit sous forme de fichier jar d’application référencé en externe. L’utilisation de fonctions définies par l’utilisateur peut simplifier les transformations ou les enrichissements de données que vous pouvez effectuer sur des données de streaming.
Dans votre bloc-notes, vous ferez référence à un simple fichier jar d’application Java doté de fonctionnalités permettant d’anonymiser les numéros de téléphone personnels. Vous pouvez également écrire du Python ou du Scala UDFs à utiliser dans le bloc-notes. Nous avons choisi un fichier jar d’application Java pour mettre en évidence la fonctionnalité d’importation d’un fichier jar d’application dans un bloc-notes Pyflink.
Configuration de l’environnement
Pour suivre ce guide et interagir avec vos données de streaming, vous allez utiliser un AWS CloudFormation script pour lancer les ressources suivantes :
-
Flux de données sources et cibles Kinesis
-
Base de données Glue
-
Rôle IAM
-
Service géré pour l’application Apache Flink Studio
-
Fonction Lambda pour démarrer le service géré pour l’application Apache Flink Studio
-
Rôle Lambda pour exécuter la fonction Lambda précédente
-
Ressource personnalisée pour appeler la fonction Lambda
Téléchargez le AWS CloudFormation modèle ici
Créez la AWS CloudFormation pile
-
Accédez à AWS Management Console et choisissez CloudFormationdans la liste des services.
-
Sur la CloudFormationpage, choisissez Stacks, puis Create Stack with new resources (standard).
-
Sur la page Créer une pile, choisissez Télécharger un fichier modèle, puis choisissez le fichier
kda-flink-udf.ymlque vous avez téléchargé précédemment. Chargez le fichier, puis sélectionnez Suivant. -
Donnez un nom au modèle, par exemple pour
kinesis-UDFafin qu’il soit facile à mémoriser, et mettez à jour les paramètres d’entrée tels que input-stream si vous souhaitez un autre nom. Choisissez Suivant. -
Sur la page Configurer les options de pile, ajoutez des balises si vous le souhaitez, puis choisissez Next.
-
Sur la page Révision, cochez les cases permettant la création de IAM ressources, puis choisissez Soumettre.
Le lancement de la AWS CloudFormation pile peut prendre de 10 à 15 minutes selon la région dans laquelle vous le lancez. Une fois que vous voyez le statut CREATE_COMPLETE pour l’ensemble de la pile, vous êtes prêt à continuer.
Utilisation du bloc-notes du service géré pour Apache Flink Studio
Les blocs-notes Studio pour Kinesis Data Analytics vous permettent d'interroger des flux de données de manière interactive en temps réel, et de créer et d'exécuter facilement des applications de traitement de flux à l'aide de standardsSQL, Python et Scala. En quelques clics AWS Management Console, vous pouvez lancer un bloc-notes sans serveur pour interroger des flux de données et obtenir des résultats en quelques secondes.
Un bloc-notes est un environnement de développement basé sur le Web. Grâce aux blocs-notes, vous bénéficiez d’une expérience de développement interactive simple associée aux capacités avancées de traitement des flux de données fournies par Apache Flink. Les blocs-notes Studio utilisent des blocs-notes alimentés par Apache Zeppelin et utilisent Apache Flink comme moteur de traitement des flux. Les blocs-notes Studio combinent parfaitement ces technologies pour rendre les analyses avancées sur les flux de données accessibles aux développeurs de tous niveaux de compétences.
Apache Zeppelin fournit à vos blocs-notes Studio une suite complète d’outils d’analyse, y compris les outils suivants :
-
Visualisation des données
-
Exportation de données dans des fichiers
-
Contrôle du format de sortie pour une analyse simplifiée
Utilisation du bloc-notes
-
Accédez au AWS Management Console et sélectionnez Amazon Kinesis dans la liste des services.
-
Dans le volet de navigation de gauche, choisissez Applications d’analyse, puis Blocs-notes Studio.
-
Vérifiez que le KinesisDataAnalyticsStudiobloc-notes fonctionne.
-
Sélectionnez le bloc-notes, puis choisissez Ouvrir dans Apache Zeppelin.
-
Téléchargez le fichier Data Producer Zeppelin Notebook
que vous utiliserez pour lire et charger des données dans le flux Kinesis. -
Importez le bloc-notes Zeppelin
Data Producer. Assurez-vous de modifier l’entréeSTREAM_NAMEetREGIONdans le code du bloc-notes. Le nom du flux d’entrée se trouve dans la sortie de pile AWS CloudFormation. -
Exécutez le bloc-notes Data Producer en cliquant sur le bouton Exécuter ce paragraphe pour insérer des exemples de données dans le flux de données Kinesis d’entrée.
-
Pendant le chargement des exemples de données, téléchargez MaskPhoneNumber-Interactive Notebook
, qui lira les données d'entrée, anonymisera les numéros de téléphone du flux d'entrée et stockera les données anonymisées dans le flux de sortie. -
Importez le bloc-notes Zeppelin
MaskPhoneNumber-interactive. -
Exécutez chaque paragraphe du bloc-notes.
-
Au paragraphe 1, vous importez une fonction définie par l'utilisateur pour anonymiser les numéros de téléphone.
%flink(parallelism=1) import com.mycompany.app.MaskPhoneNumber stenv.registerFunction("MaskPhoneNumber", new MaskPhoneNumber()) -
Dans le paragraphe suivant, vous créez une table en mémoire pour lire les données du flux d’entrée. Assurez-vous que le nom du flux et AWS la région sont corrects.
%flink.ssql(type=update) DROP TABLE IF EXISTS customer_reviews; CREATE TABLE customer_reviews ( customer_id VARCHAR, product VARCHAR, review VARCHAR, phone VARCHAR ) WITH ( 'connector' = 'kinesis', 'stream' = 'KinesisUDFSampleInputStream', 'aws.region' = 'us-east-1', 'scan.stream.initpos' = 'LATEST', 'format' = 'json'); -
Vérifiez si les données sont chargées dans la table en mémoire.
%flink.ssql(type=update) select * from customer_reviews -
Invoquez la fonction définie par l’utilisateur pour anonymiser le numéro de téléphone.
%flink.ssql(type=update) select customer_id, product, review, MaskPhoneNumber('mask_phone', phone) as phoneNumber from customer_reviews -
Maintenant que les numéros de téléphone sont masqués, créez une vue avec un numéro masqué.
%flink.ssql(type=update) DROP VIEW IF EXISTS sentiments_view; CREATE VIEW sentiments_view AS select customer_id, product, review, MaskPhoneNumber('mask_phone', phone) as phoneNumber from customer_reviews -
Vérifiez les données.
%flink.ssql(type=update) select * from sentiments_view -
Créez une table en mémoire pour le flux Kinesis en sortie. Assurez-vous que le nom du flux et AWS la région sont corrects.
%flink.ssql(type=update) DROP TABLE IF EXISTS customer_reviews_stream_table; CREATE TABLE customer_reviews_stream_table ( customer_id VARCHAR, product VARCHAR, review VARCHAR, phoneNumber varchar ) WITH ( 'connector' = 'kinesis', 'stream' = 'KinesisUDFSampleOutputStream', 'aws.region' = 'us-east-1', 'scan.stream.initpos' = 'TRIM_HORIZON', 'format' = 'json'); -
Insérez les enregistrements mis à jour dans le flux Kinesis cible.
%flink.ssql(type=update) INSERT INTO customer_reviews_stream_table SELECT customer_id, product, review, phoneNumber FROM sentiments_view -
Affichez et vérifiez les données du flux Kinesis cible.
%flink.ssql(type=update) select * from customer_reviews_stream_table
-
Promotion d’un bloc-notes en tant qu’application
Maintenant que vous avez testé le code de votre bloc-notes de manière interactive, vous allez le déployer en tant qu’application de streaming durable. Vous devez d’abord modifier la configuration de l’application pour indiquer l’emplacement de votre code dans Amazon S3.
-
Sur le AWS Management Console, choisissez votre bloc-notes et dans Déployer en tant que configuration d'application (facultatif), sélectionnez Modifier.
-
Sous Destination du code dans Amazon S3, choisissez le compartiment Amazon S3 créé par les scripts AWS CloudFormation
. Ce processus peut prendre quelques minutes. -
Vous ne pourrez pas promouvoir la note telle quelle. Si vous essayez, vous obtenez une erreur car les instructions
Selectne sont pas prises en charge. Pour éviter ce problème, téléchargez le carnet Zeppelin MaskPhoneNumber -Streaming. -
Importez le bloc-notes Zeppelin
MaskPhoneNumber-streaming. -
Ouvrez la note et choisissez Actions pour KinesisDataAnalyticsStudio.
-
Choisissez Build MaskPhoneNumber -Streaming et exportez vers S3. Assurez-vous de modifier le nom d’application et de ne pas inclure de caractères spéciaux.
-
Choisissez Générer et exporter. La configuration de l’application de streaming prendra quelques minutes.
-
Une fois la génération terminée, choisissez Déployer à l’aide de la console AWS .
-
Sur la page suivante, passez en revue les paramètres et assurez-vous de choisir le bon IAM rôle. Ensuite, choisissez Créer une application de streaming.
-
Après quelques minutes, vous verrez un message indiquant que l’application de streaming a été créée avec succès.
Pour plus d’informations sur le déploiement d’applications à état durable et avec limitations, consultez Déploiement en tant qu’application à état durable.
Nettoyage
Si vous le souhaitez, vous pouvez à présent désinstaller la pile AWS CloudFormation. Cela supprimera tous les services que vous avez configurés précédemment.
