Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Tutoriel : Ingestion de données dans un domaine à l'aide d'Amazon OpenSearch Ingestion
Ce didacticiel explique comment utiliser Amazon OpenSearch Ingestion pour configurer un pipeline simple et ingérer des données dans un domaine Amazon OpenSearch Service. Un pipeline est une ressource qu' OpenSearch Ingestion approvisionne et gère. Vous pouvez utiliser un pipeline pour filtrer, enrichir, transformer, normaliser et agréger les données à des fins d'analyse et de visualisation en aval dans OpenSearch Service.
Ce didacticiel vous explique les étapes de base nécessaires à la mise en service rapide d'un pipeline. Pour des instructions plus complètes, voirCréation de pipelines.
Dans le cadre de ce didacticiel, vous suivrez les étapes suivantes :
Dans le didacticiel, vous allez créer les ressources suivantes :
-
Un domaine nommé dans
ingestion-domainlequel le pipeline écrit -
Un pipeline nommé
ingestion-pipeline
Autorisations requises
Pour terminer ce didacticiel, votre utilisateur ou votre rôle doit être associé à une politique basée sur l'identité avec les autorisations minimales suivantes. Ces autorisations vous permettent de créer un rôle de pipeline et d'associer une politique (iam:Create*etiam:Attach*), de créer ou de modifier un domaine (es:*) et d'utiliser des pipelines (osis:*).
Étape 1 : Création du rôle de pipeline
Tout d'abord, créez un rôle que le pipeline assumera afin d'accéder au récepteur du domaine de OpenSearch service. Vous allez inclure ce rôle dans la configuration du pipeline plus loin dans ce didacticiel.
Pour créer le rôle de pipeline
-
Ouvrez la Gestion des identités et des accès AWS console à l'adresse https://console.aws.amazon.com/iamv2/
. -
Choisissez Politiques, puis choisissez Créer une politique.
-
Dans ce didacticiel, vous allez ingérer des données dans un domaine appelé
ingestion-domain, que vous allez créer à l'étape suivante. Sélectionnez JSON et collez la politique suivante dans l'éditeur.your-account-idSi vous souhaitez écrire des données dans un domaine existant, remplacez-les
ingestion-domainpar le nom de votre domaine.Note
Pour simplifier ce didacticiel, nous utilisons une politique d'accès étendue. Dans les environnements de production, nous vous recommandons toutefois d'appliquer une politique d'accès plus restrictive à votre rôle de pipeline. Pour un exemple de politique fournissant les autorisations minimales requises, voirAccorder aux OpenSearch pipelines Amazon Ingestion l'accès aux domaines.
-
Choisissez Next, puis Next, et nommez votre pipeline de politiques.
-
Choisissez Create Policy (Créer une politique).
-
Créez ensuite un rôle et associez-y la politique. Cliquez sur Rôles, puis sur Créer un rôle.
-
Choisissez Politique de confiance personnalisée et collez la politique suivante dans l'éditeur :
-
Choisissez Suivant. Recherchez et sélectionnez ensuite pipeline-policy (que vous venez de créer).
-
Choisissez Next et nommez le rôle PipelineRole.
-
Choisissez Créer un rôle.
N'oubliez pas le nom de ressource Amazon (ARN) du rôle (par exemple,arn:aws:iam::). Vous en aurez besoin lors de la création de votre pipeline.your-account-id:role/PipelineRole
Étape 2 : créer un domaine
Tout d'abord, créez un nom de domaine dans ingestion-domain lequel les données seront ingérées.
Accédez à la console Amazon OpenSearch Service à l'https://console.aws.amazon.com/aos/home
-
Exécute la OpenSearch version 1.0 ou ultérieure, ou Elasticsearch 7.4 ou version ultérieure
-
Utilise l'accès public
-
N'utilise pas de contrôle d'accès détaillé
Note
Ces exigences visent à garantir la simplicité de ce didacticiel. Dans les environnements de production, vous pouvez configurer un domaine avec un accès VPC à l'aide d'un contrôle and/or d'accès précis. Pour utiliser un contrôle d'accès précis, voir Cartographier le rôle du pipeline.
Le domaine doit disposer d'une politique d'accès qui accorde l'autorisation au rôle OpenSearchIngestion-PipelineRole IAM, que le OpenSearch service créera pour vous à l'étape suivante. Le pipeline assumera ce rôle afin d'envoyer des données au récepteur de domaine.
Assurez-vous que le domaine applique la politique d'accès au niveau du domaine suivante, qui accorde au rôle de pipeline l'accès au domaine. Remplacez la région et le numéro de compte par les vôtres :
Pour plus d'informations sur la création de politiques d'accès au niveau du domaine, consultez. Resource-based politiques
Si vous avez déjà créé un domaine, ouvrez la console Amazon OpenSearch Service, sélectionnez votre domaine, choisissez l'onglet Configuration de la sécurité, puis choisissez Modifier. Sous Politique d'accès, ajoutez les autorisations ci-dessus pour OpenSearchIngestion-PipelineRole à la politique JSON existante.
Étape 3 : Création d'un pipeline
Maintenant que vous avez un domaine, vous pouvez créer un pipeline.
Pour créer un pipeline
-
Dans la console Amazon OpenSearch Service, choisissez Pipelines dans le volet de navigation de gauche.
-
Choisissez Créer un pipeline.
-
Sélectionnez le pipeline vide, puis sélectionnez Select Blueprint.
-
Dans ce didacticiel, nous allons créer un pipeline simple qui utilise le plugin source HTTP
. Le plugin accepte les données du journal dans un format de tableau JSON. Nous allons spécifier un seul domaine de OpenSearch service comme récepteur et intégrer toutes les données dans l' application_logsindex.Dans le menu Source, choisissez HTTP. Pour le chemin, entrez /logs.
-
Pour simplifier ce didacticiel, nous allons configurer l'accès public pour le pipeline. Pour les options de réseau source, choisissez Accès public. Pour plus d'informations sur la configuration de l'accès au VPC, consultez. Configuration de l'accès VPC pour les pipelines Amazon Ingestion OpenSearch
-
Choisissez Suivant.
-
Pour Processeur, entrez la date et choisissez Ajouter.
-
Activez À partir de l'heure de réception. Conservez les valeurs par défaut de tous les autres paramètres.
-
Choisissez Suivant.
-
Configurez les détails du récepteur. Pour le type de OpenSearch ressource, choisissez Cluster géré. Choisissez ensuite le domaine OpenSearch de service que vous avez créé dans la section précédente.
Dans le champ Nom de l'index, entrez application_logs. OpenSearch L'ingestion crée automatiquement cet index dans le domaine s'il n'existe pas déjà.
-
Choisissez Suivant.
-
Nommez le pipeline ingestion-pipeline. Conservez les paramètres de capacité par défaut.
-
Pour le rôle de pipeline, sélectionnez Créer et utiliser un nouveau rôle de service. Le rôle de pipeline fournit les autorisations requises pour qu'un pipeline puisse écrire sur le récepteur de domaine et lire à partir de sources basées sur le pull. En sélectionnant cette option, vous autorisez OpenSearch Ingestion à créer le rôle pour vous, plutôt que de le créer manuellement dans IAM. Pour de plus amples informations, veuillez consulter Configuration des rôles et des utilisateurs dans Amazon OpenSearch Ingestion.
-
Pour le suffixe du nom du rôle de service, entrez PipelineRole. Dans IAM, le rôle aura le format
arn:aws:iam::.your-account-id:role/OpenSearchIngestion-PipelineRole -
Choisissez Suivant. Passez en revue la configuration de votre pipeline et choisissez Create pipeline. Le pipeline prend 5 à 10 minutes pour devenir actif.
Étape 4 : Ingérer des exemples de données
Lorsque l'état du pipeline est atteintActive, vous pouvez commencer à y ingérer des données. Vous devez signer toutes les requêtes HTTP adressées au pipeline à l'aide de la version 4 de Signature. Utilisez un outil HTTP tel que Postman
Note
Le signataire principal de la demande doit disposer de l'autorisation osis:Ingest IAM.
Tout d'abord, récupérez l'URL d'ingestion sur la page des paramètres du pipeline :
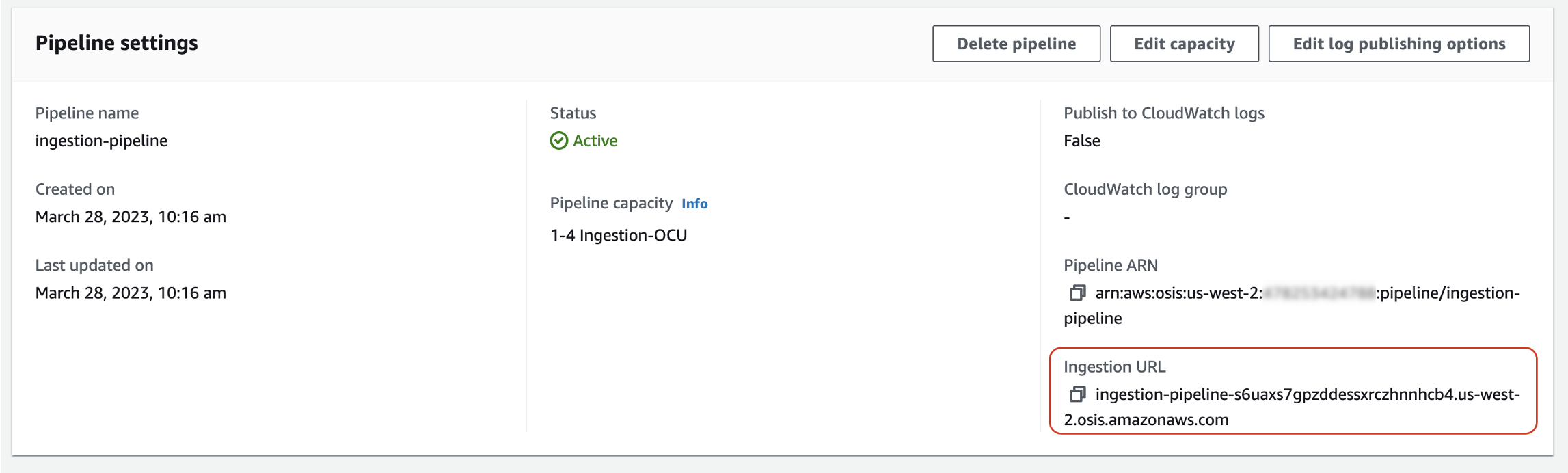
Ensuite, ingérez des exemples de données. La requête suivante utilise awscurl
awscurl --service osis --regionus-east-1\ -X POST \ -H "Content-Type: application/json" \ -d '[{"time":"2014-08-11T11:40:13+00:00","remote_addr":"122.226.223.69","status":"404","request":"GET http://www.k2proxy.com//hello.html HTTP/1.1","http_user_agent":"Mozilla/4.0 (compatible; WOW64; SLCC2;)"}]' \ https://pipeline-endpoint.us-east-1.osis.amazonaws.com/logs
Vous devriez voir une 200 OK réponse. Si vous recevez une erreur d'authentification, cela peut être dû au fait que vous ingérez des données provenant d'un compte distinct de celui dans lequel se trouve le pipeline. Consultez Résoudre les problèmes d'autorisations.
Maintenant, interrogez l'application_logsindex pour vous assurer que votre entrée de journal a été correctement ingérée :
awscurl --service es --regionus-east-1\ -X GET \ https://search-ingestion-domain.us-east-1.es.amazonaws.com/application_logs/_search | json_pp
Exemple de réponse:
{ "took":984, "timed_out":false, "_shards":{ "total":1, "successful":5, "skipped":0, "failed":0 }, "hits":{ "total":{ "value":1, "relation":"eq" }, "max_score":1.0, "hits":[ { "_index":"application_logs", "_type":"_doc", "_id":"z6VY_IMBRpceX-DU6V4O", "_score":1.0, "_source":{ "time":"2014-08-11T11:40:13+00:00", "remote_addr":"122.226.223.69", "status":"404", "request":"GET http://www.k2proxy.com//hello.html HTTP/1.1", "http_user_agent":"Mozilla/4.0 (compatible; WOW64; SLCC2;)", "@timestamp":"2022-10-21T21:00:25.502Z" } } ] } }
Résoudre les problèmes d'autorisations
Si vous avez suivi les étapes du didacticiel et que des erreurs d'authentification persistent lorsque vous essayez d'ingérer des données, cela peut être dû au fait que le rôle qui écrit dans un pipeline se trouve dans un pipeline différent de Compte AWS celui du pipeline lui-même. Dans ce cas, vous devez créer et assumer un rôle qui vous permet spécifiquement d'ingérer des données. Pour obtenir des instructions, veuillez consulter Fournir un accès à l'ingestion entre comptes.
Ressources connexes
Ce didacticiel a présenté un cas d'utilisation simple d'ingestion d'un seul document via HTTP. Dans les scénarios de production, vous allez configurer vos applications clientes (telles que Fluent Bit, Kubernetes ou le OpenTelemetry Collector) pour envoyer des données vers un ou plusieurs pipelines. Vos pipelines seront probablement plus complexes que le simple exemple de ce didacticiel.
Pour commencer à configurer vos clients et à ingérer des données, consultez les ressources suivantes :
