Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Motif CQRS
Le modèle de ségrégation des responsabilités des requêtes de commande (CQRS) sépare la mutation des données, ou la partie commande d'un système, de la partie requête. Vous pouvez utiliser le modèle CQRS pour séparer les mises à jour et les requêtes si les exigences en matière de débit, de latence ou de cohérence sont différentes. Le modèle CQRS divise l'application en deux parties, le côté commande et le côté requête, comme le montre le schéma suivant. Le côté commande gère createupdate, et delete demande. Le côté requête exécute la query partie en utilisant les répliques de lecture.
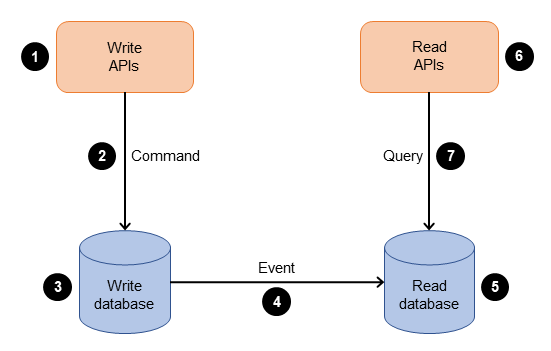
Le schéma montre le processus suivant :
-
L'entreprise interagit avec l'application en envoyant des commandes via une API. Les commandes sont des actions telles que la création, la mise à jour ou la suppression de données.
-
L'application traite la commande entrante côté commande. Cela implique de valider, d'autoriser et d'exécuter l'opération.
-
L'application conserve les données de la commande dans la base de données d'écriture (commande).
-
Une fois la commande stockée dans la base de données d'écriture, des événements sont déclenchés pour mettre à jour les données dans la base de données de lecture (requête).
-
La base de données de lecture (requête) traite et conserve les données. Les bases de données de lecture sont conçues pour être optimisées pour répondre aux exigences spécifiques des requêtes.
-
L'entreprise interagit avec les API de lecture pour envoyer des requêtes au côté requête de l'application.
-
L'application traite la requête entrante côté requête et extrait les données de la base de données lue.
Vous pouvez implémenter le modèle CQRS en utilisant différentes combinaisons de bases de données, notamment :
-
Utilisation des bases de données du système de gestion de base de données relationnelle (RDBMS) à la fois du côté commande et du côté requête. Les opérations d'écriture sont dirigées vers la base de données principale et les opérations de lecture peuvent être acheminées vers des répliques de lecture. Exemple : Amazon RDS lit des répliques
-
Utilisation d'une base de données RDBMS côté commande et d'une base de données NoSQL côté requête. Exemple : Moderniser les anciennes bases de données à l'aide de l'approvisionnement en événements et du CQRS
avec AWS DMS -
Utilisation de bases de données NoSQL à la fois du côté commande et du côté requête. Exemple : création d'un magasin d'événements CQRS avec Amazon DynamoDB
-
Utilisation d'une base de données NoSQL côté commande et d'une base de données RDBMS côté requête, comme indiqué dans l'exemple suivant.
Dans l'illustration suivante, un magasin de données NoSQL, tel que DynamoDB, est utilisé pour optimiser le débit d'écriture et fournir des fonctionnalités de requête flexibles. Cela permet d'obtenir une évolutivité d'écriture élevée sur les charges de travail dont les modèles d'accès sont bien définis lorsque vous ajoutez des données. Une base de données relationnelle, telle qu'Amazon Aurora, fournit des fonctionnalités de requête complexes. Un flux DynamoDB envoie des données à une fonction Lambda qui met à jour la table Aurora.
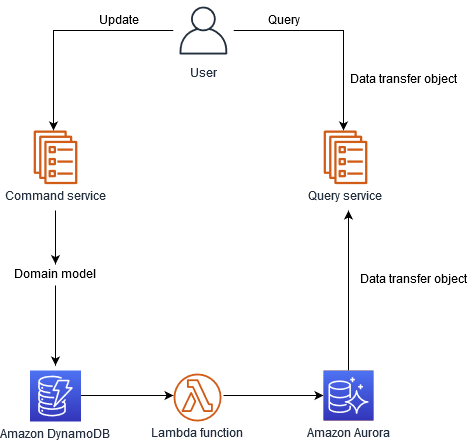
La mise en œuvre du modèle CQRS avec DynamoDB et Aurora offre les principaux avantages suivants :
-
DynamoDB est une base de données NoSQL entièrement gérée capable de gérer de gros volumes d'opérations d'écriture. Aurora offre une évolutivité de lecture élevée pour les requêtes complexes du côté des requêtes.
-
DynamoDB fournit un accès aux données à faible latence et à haut débit, ce qui le rend idéal pour gérer les opérations de commande et de mise à jour, et les performances d'Aurora peuvent être affinées et optimisées pour les requêtes complexes.
-
DynamoDB et Aurora proposent des options sans serveur, qui permettent à votre entreprise de payer les ressources en fonction de leur utilisation uniquement.
-
DynamoDB et Aurora sont des services entièrement gérés, qui réduisent la charge opérationnelle liée à la gestion des bases de données, aux sauvegardes et à l'évolutivité.
Vous devriez envisager d'utiliser le modèle CQRS si :
-
Vous avez implémenté le modèle de base de données par service et souhaitez joindre des données provenant de plusieurs microservices.
-
Vos charges de travail de lecture et d'écriture ont des exigences distinctes en matière de scalabilité, de latence et de cohérence.
-
La cohérence éventuelle est acceptable pour les requêtes de lecture.
Important
Le modèle CQRS aboutit généralement à une cohérence éventuelle entre les magasins de données.
