Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Optimisez les shuffles
Certaines opérations, telles que join() etgroupByKey(), nécessitent que Spark effectue un shuffle. Le shuffle est le mécanisme utilisé par Spark pour redistribuer les données afin qu'elles soient regroupées différemment selon les partitions. RDD Le remaniement peut aider à remédier aux problèmes de performance. Cependant, comme le shuffling implique généralement de copier des données entre les exécuteurs Spark, le shuffle est une opération complexe et coûteuse. Par exemple, les shuffles génèrent les coûts suivants :
-
E/S de disque :
-
Génère un grand nombre de fichiers intermédiaires sur le disque.
-
-
E/S réseau :
-
Nécessite de nombreuses connexions réseau (Nombre de connexions =
Mapper × Reducer). -
Les enregistrements étant agrégés dans de nouvelles RDD partitions qui peuvent être hébergées sur un autre exécuteur Spark, une fraction importante de votre ensemble de données peut être déplacée entre les exécuteurs Spark sur le réseau.
-
-
CPUet charge de la mémoire :
-
Trie les valeurs et fusionne des ensembles de données. Ces opérations sont planifiées sur l'exécuteur testamentaire, ce qui impose une lourde charge à celui-ci.
-
Le shuffle est l'un des principaux facteurs de dégradation des performances de votre application Spark. Lors du stockage des données intermédiaires, cela peut épuiser de l'espace sur le disque local de l'exécuteur, ce qui entraîne l'échec de la tâche Spark.
Vous pouvez évaluer les performances de votre shuffle dans les CloudWatch métriques et dans l'interface utilisateur de Spark.
CloudWatch métriques
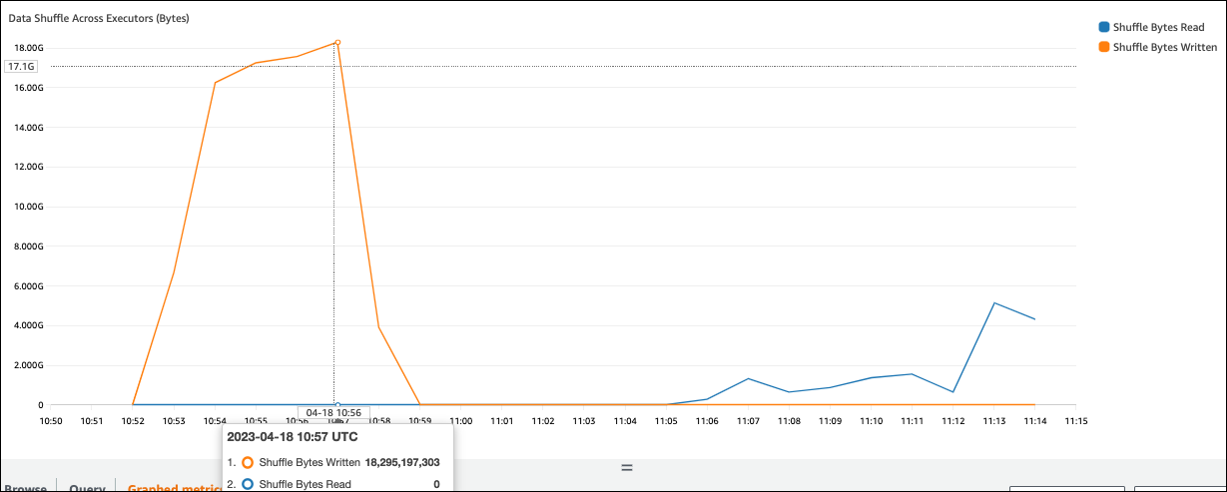
Si la valeur écrite de Shuffle Bytes est élevée par rapport à Shuffle Bytes Read, votre tâche Spark peut utiliser des opérations de brassagejoin() groupByKey()
Interface utilisateur Spark
Dans l'onglet Stage de l'interface utilisateur de Spark, vous pouvez vérifier les valeurs Shuffle Read Size/Records. Vous pouvez également le voir dans l'onglet Exécuteurs.
Dans la capture d'écran suivante, chaque exécuteur échange environ 18,6 Go/402 000 enregistrements avec le processus de shuffle, pour une taille totale de lecture par shuffle d'environ 75 Go).
La colonne Shuffle Spill (Disk) indique qu'une grande quantité de mémoire est déversée sur le disque, ce qui peut entraîner un encombrement du disque ou un problème de performance.

Si vous observez ces symptômes et que l'étape prend trop de temps par rapport à vos objectifs de performance, ou si elle échoue Out Of Memory ou comporte No space
left on device des erreurs, envisagez les solutions suivantes.
Optimisez la jointure
L'join()opération, qui consiste à joindre des tables, est l'opération de shuffle la plus couramment utilisée, mais elle constitue souvent un goulot d'étranglement en termes de performances. L'adhésion étant une opération coûteuse, nous vous recommandons de ne pas l'utiliser, sauf si elle est essentielle aux besoins de votre entreprise. Vérifiez que vous utilisez efficacement votre pipeline de données en vous posant les questions suivantes :
-
Recalculez-vous une jointure qui est également effectuée dans d'autres tâches que vous pouvez réutiliser ?
-
Est-ce que vous vous joignez pour convertir les clés étrangères en valeurs qui ne sont pas utilisées par les consommateurs de votre sortie ?
Après avoir confirmé que vos opérations d'adhésion sont essentielles aux besoins de votre entreprise, consultez les options suivantes pour optimiser votre adhésion de manière à répondre à vos exigences.
Utilisez le pushdown avant de rejoindre
Filtrez les lignes et les colonnes inutiles DataFrame avant d'effectuer une jointure. Cela présente les avantages suivants :
-
Réduit le volume de transfert de données pendant le shuffle
-
Réduit la quantité de traitement dans l'exécuteur Spark
-
Réduit la quantité de données numérisées
# Default df_joined = df1.join(df2, ["product_id"]) # Use Pushdown df1_select = df1.select("product_id","product_title","star_rating").filter(col("star_rating")>=4.0) df2_select = df2.select("product_id","category_id") df_joined = df1_select.join(df2_select, ["product_id"])
Utiliser DataFrame Join
Essayez d'utiliser un Spark de haut niveau APIdyf.toDF(). Comme indiqué dans la section Sujets clés d'Apache Spark, ces opérations de jointure internes tirent parti de l'optimisation des requêtes par l'optimiseur Catalyst.
Mélangez et diffusez des jointures de hachage et des indices
Spark prend en charge deux types de jointure : la jointure automatique et la jointure par hachage par diffusion. Une jointure par hachage de diffusion ne nécessite pas de brassage et peut nécessiter moins de traitement qu'une jointure aléatoire. Cependant, cela ne s'applique que lorsque vous joignez une petite table à une grande. Lorsque vous joignez une table pouvant tenir dans la mémoire d'un seul exécuteur Spark, pensez à utiliser une jointure par hachage de diffusion.
Le schéma suivant montre la structure de haut niveau et les étapes d'une jointure par hachage de diffusion et d'une jointure aléatoire.
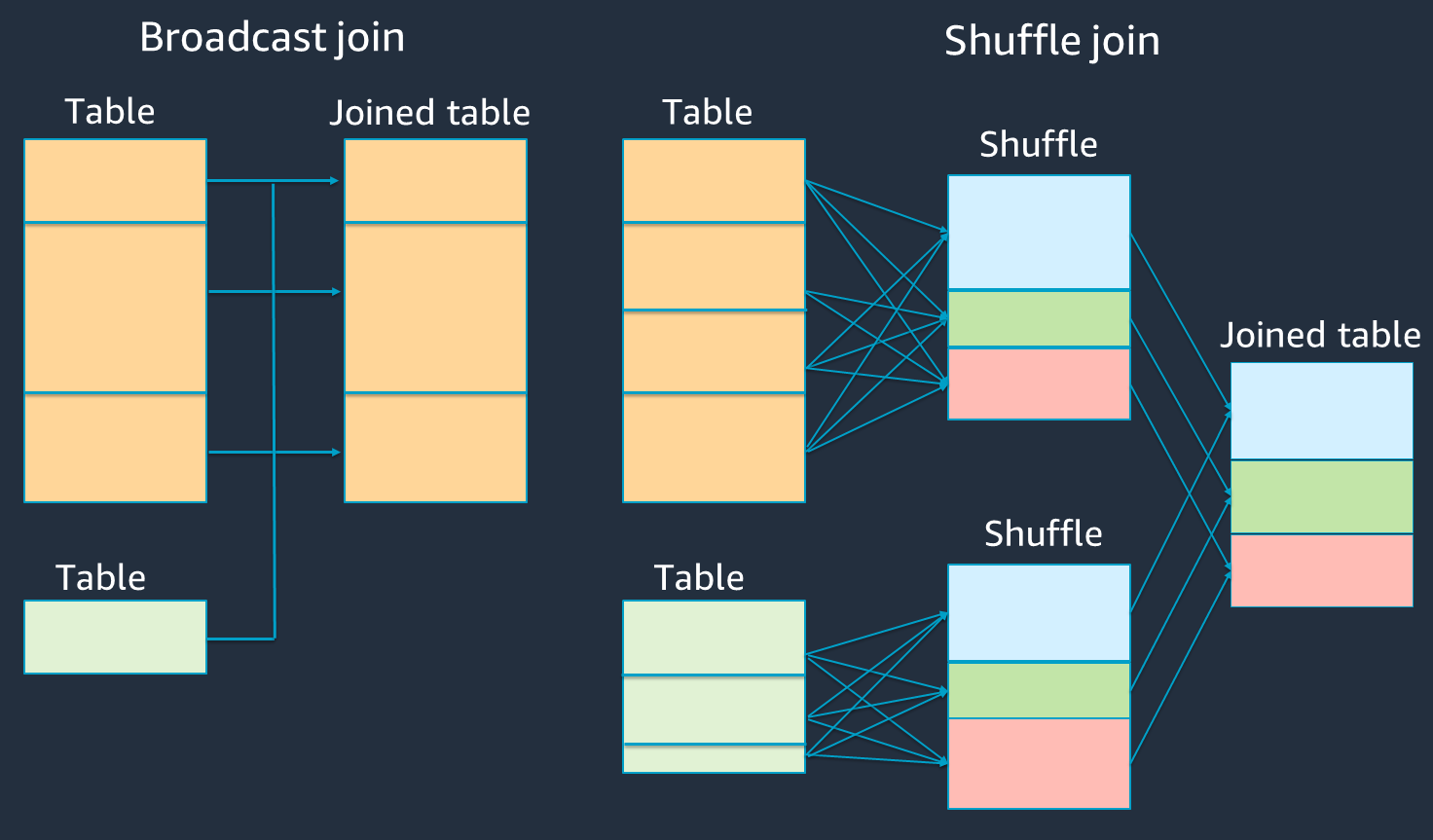
Les détails de chaque jointure sont les suivants :
-
Joindre le shuffle :
-
La jointure par hachage aléatoire joint deux tables sans les trier et répartit la jointure entre les deux tables. Il convient aux jointures de petites tables qui peuvent être stockées dans la mémoire de l'exécuteur Spark.
-
La jointure sort-merge distribue les deux tables à joindre par clé et les trie avant de les joindre. Il convient aux assemblages de grandes tables.
-
-
Jointure par hachage de diffusion :
-
Une jointure par hachage de diffusion pousse le plus petit RDD ou la table vers chacun des nœuds de travail. Il effectue ensuite une combinaison côté carte avec chaque partition de la plus grande RDD ou de la table.
Il convient aux jointures lorsque l'une de vos RDDs tables peut tenir en mémoire ou peut être conçue pour tenir en mémoire. Il est avantageux d'effectuer une jointure par hachage de diffusion lorsque cela est possible, car cela ne nécessite pas de shuffle. Vous pouvez utiliser un indice de jointure pour demander une participation à une diffusion auprès de Spark comme suit.
# DataFrame from pySpark.sql.functions import broadcast df_joined= df_big.join(broadcast(df_small), right_df[key] == left_df[key], how='inner') -- SparkSQL SELECT /*+ BROADCAST(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key;Pour plus d'informations sur les conseils de jointure, consultez la section Conseils de jointure
.
-
Dans la AWS Glue version 3.0 et les versions ultérieures, vous pouvez tirer parti des jointures par hachage diffusées automatiquement en activant l'exécution adaptative des requêtes
Dans la AWS Glue version 3.0, vous pouvez activer l'exécution adaptative des requêtes en configurantspark.sql.adaptive.enabled=true. L'exécution adaptative des requêtes est activée par défaut dans AWS Glue 4.0.
Vous pouvez définir des paramètres supplémentaires relatifs aux shuffles et aux jointures de hachage diffusées :
-
spark.sql.adaptive.localShuffleReader.enabled -
spark.sql.adaptive.autoBroadcastJoinThreshold
Pour plus d'informations sur les paramètres associés, consultez la section Conversion d'une jointure sort-merge en une jointure de diffusion
Dans la AWS Glue version 3.0 ou ultérieure, vous pouvez utiliser d'autres astuces de jointure pour le shuffle afin d'ajuster votre comportement.
-- Join Hints for shuffle sort merge join SELECT /*+ SHUFFLE_MERGE(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; SELECT /*+ MERGEJOIN(t2) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; SELECT /*+ MERGE(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; -- Join Hints for shuffle hash join SELECT /*+ SHUFFLE_HASH(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; -- Join Hints for shuffle-and-replicate nested loop join SELECT /*+ SHUFFLE_REPLICATE_NL(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key;
Utilisez le buketing
La jointure tri-fusion nécessite deux phases : mélanger et trier, puis fusionner. Ces deux phases peuvent surcharger l'exécuteur Spark OOM et entraîner des problèmes de performances lorsque certains exécuteurs fusionnent et que d'autres trient simultanément. Dans de tels cas, il peut être possible de se joindre efficacement en utilisant le buketing
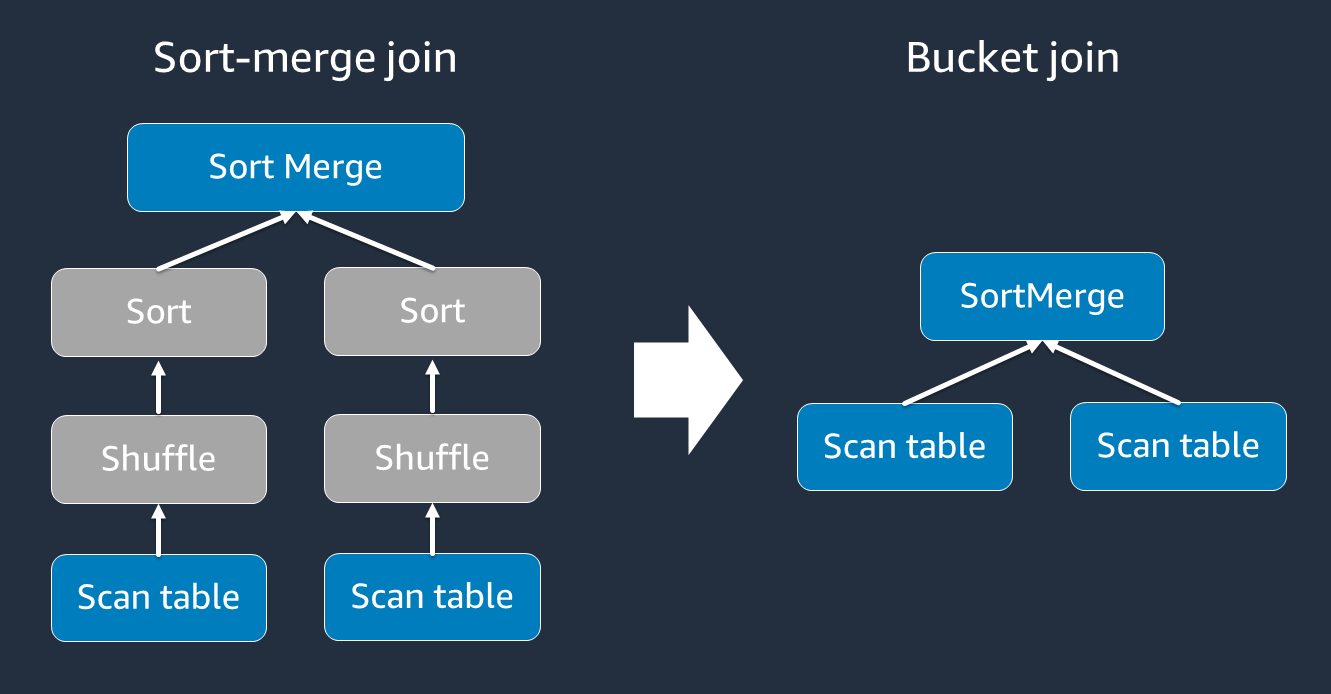
Les tableaux à compartiments sont utiles dans les cas suivants :
-
Des données fréquemment jointes via la même clé, telles que
account_id -
Chargement de tables cumulatives quotidiennes, telles que les tables de base et de delta qui pourraient être regroupées dans une colonne commune
Vous pouvez créer une table à compartiments en utilisant le code suivant.
df.write.bucketBy(50, "account_id").sortBy("age").saveAsTable("bucketed_table")
Répartition DataFrames sur les clés de jointure avant la jointure
Pour répartir les deux DataFrames sur les clés de jointure avant la jointure, utilisez les instructions suivantes.
df1_repartitioned = df1.repartition(N,"join_key") df2_repartitioned = df2.repartition(N,"join_key") df_joined = df1_repartitioned.join(df2_repartitioned,"product_id")
Cela permettra de partitionner deux (toujours séparément) RDDs sur la clé de jointure avant de lancer la jointure. Si les deux RDDs sont partitionnés sur la même clé avec le même code de partitionnement, il est fort probable que les RDD enregistrements que vous projetez de joindre soient colocalisés sur le même worker avant d'être mélangés pour la jointure. Cela peut améliorer les performances en réduisant l'activité du réseau et le biais des données lors de la jointure.
Surmontez le biais des données
L'asymétrie des données est l'une des causes les plus fréquentes d'engorgement des tâches Spark. Cela se produit lorsque les données ne sont pas réparties uniformément entre les RDD partitions. Cela entraîne des tâches beaucoup plus longues pour cette partition que pour les autres, ce qui retarde le temps de traitement global de l'application.
Pour identifier le biais des données, évaluez les indicateurs suivants dans l'interface utilisateur de Spark :
-
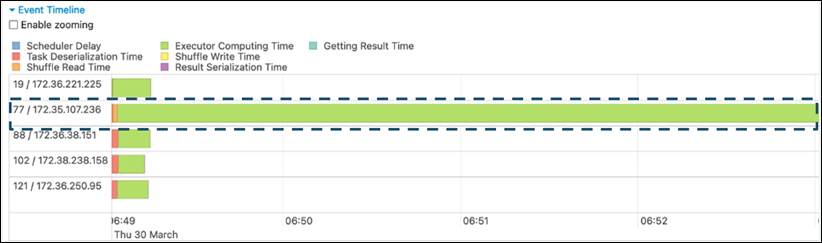
Dans l'onglet Stage de l'interface utilisateur de Spark, examinez la page Chronologie des événements. Vous pouvez voir une répartition inégale des tâches dans la capture d'écran suivante. Les tâches qui sont réparties de manière inégale ou dont l'exécution prend trop de temps peuvent indiquer une distorsion des données.
-
Une autre page importante est celle des métriques récapitulatives, qui présente les statistiques des tâches Spark. La capture d'écran suivante montre les métriques avec des percentiles pour la durée, le temps GC, le déversement (mémoire), le déversement (disque), etc.

Lorsque les tâches sont réparties uniformément, vous verrez des chiffres similaires dans tous les percentiles. En cas de distorsion des données, vous verrez des valeurs très biaisées dans chaque percentile. Dans l'exemple, la durée de la tâche est inférieure à 13 secondes en min, 25e percentile, médian et 75e percentile. Bien que la tâche Max ait traité 100 fois plus de données que le 75e percentile, sa durée de 6,4 minutes est environ 30 fois plus longue. Cela signifie qu'au moins une tâche (ou jusqu'à 25 % des tâches) a pris beaucoup plus de temps que le reste des tâches.
Si vous constatez une distorsion des données, essayez ce qui suit :
-
Si vous utilisez la AWS Glue version 3.0, activez l'exécution adaptative des requêtes en définissant
spark.sql.adaptive.enabled=true. L'exécution adaptative des requêtes est activée par défaut dans la AWS Glue version 4.0.Vous pouvez également utiliser l'exécution adaptative des requêtes pour le biais des données introduit par les jointures en définissant les paramètres connexes suivants :
-
spark.sql.adaptive.skewJoin.skewedPartitionFactor -
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes -
spark.sql.adaptive.advisoryPartitionSizeInBytes=128m (128 mebibytes or larger should be good) -
spark.sql.adaptive.coalescePartitions.enabled=true (when you want to coalesce partitions)
Pour plus d'informations, consultez la documentation d'Apache Spark
. -
-
Utilisez des clés avec une large plage de valeurs pour les clés de jointure. Dans une jointure aléatoire, les partitions sont déterminées pour chaque valeur de hachage d'une clé. Si la cardinalité d'une clé de jointure est trop faible, la fonction de hachage risque de mal répartir vos données entre les partitions. Par conséquent, si votre application et votre logique métier le permettent, envisagez d'utiliser une clé de cardinalité supérieure ou une clé composite.
# Use Single Primary Key df_joined = df1_select.join(df2_select, ["primary_key"]) # Use Composite Key df_joined = df1_select.join(df2_select, ["primary_key","secondary_key"])
Utiliser le cache
Lorsque vous utilisez le mode répétitif DataFrames, évitez tout remaniement ou calcul supplémentaire en utilisant df.cache() ou df.persist() en mettant en cache les résultats des calculs dans la mémoire et sur le disque de chaque exécuteur Spark. Spark prend également en charge RDDs la persistance sur le disque ou la réplication sur plusieurs nœuds (niveau de stockage
Par exemple, vous pouvez les conserver DataFrames en ajoutantdf.persist(). Lorsque le cache n'est plus nécessaire, vous pouvez l'utiliser unpersist pour supprimer les données mises en cache.
df = spark.read.parquet("s3://<Bucket>/parquet/product_category=Books/") df_high_rate = df.filter(col("star_rating")>=4.0) df_high_rate.persist() df_joined1 = df_high_rate.join(<Table1>, ["key"]) df_joined2 = df_high_rate.join(<Table2>, ["key"]) df_joined3 = df_high_rate.join(<Table3>, ["key"]) ... df_high_rate.unpersist()
Supprimer les actions Spark inutiles
Évitez d'exécuter des actions inutiles telles que countshow, oucollect. Comme indiqué dans la section Sujets clés d'Apache Spark, Spark est paresseux. Chaque transformation RDD peut être recalculée chaque fois que vous exécutez une action dessus. Lorsque vous utilisez de nombreuses actions Spark, plusieurs accès à la source, des calculs de tâches et des exécutions aléatoires pour chaque action sont appelés.
Si vous n'avez pas besoin collect() d'effectuer d'autres actions dans votre environnement commercial, pensez à les supprimer.
Note
Évitez autant que possible d'utiliser Spark collect() dans des environnements commerciaux. L'collect()action renvoie tous les résultats d'un calcul effectué dans l'exécuteur Spark au pilote Spark, ce qui peut entraîner le renvoi d'une OOM erreur par le pilote Spark. Pour éviter toute OOM erreur, Spark définit spark.driver.maxResultSize = 1GB par défaut, ce qui limite la taille maximale des données renvoyées au pilote Spark à 1 Go.
