Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Sujets clés d'Apache Spark
Cette section explique les concepts de base d'Apache Spark et les principaux sujets relatifs à l'optimisation AWS Glue des performances d'Apache Spark. Il est important de comprendre ces concepts et sujets avant de discuter de stratégies de réglage réelles.
Architecture
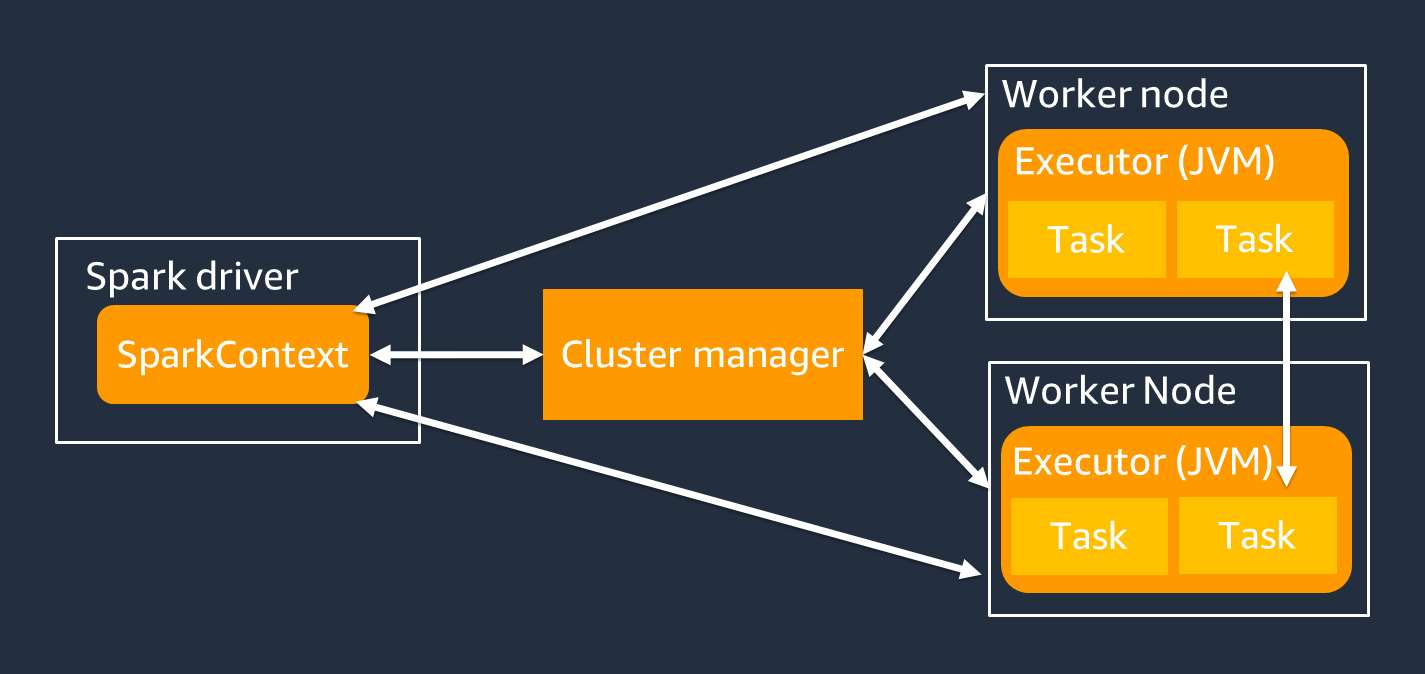
Le pilote Spark est principalement chargé de diviser votre application Spark en tâches pouvant être exécutées par des travailleurs individuels. Le pilote Spark a les responsabilités suivantes :
-
Exécution
main()de votre code -
Génération de plans d'exécution
-
Provisionner les exécuteurs Spark conjointement avec le gestionnaire de cluster, qui gère les ressources du cluster
-
Planification de tâches et demande de tâches pour les exécuteurs Spark
-
Gestion de la progression et de la reprise des tâches
Vous utilisez un SparkContext objet pour interagir avec le pilote Spark lors de l'exécution de votre tâche.
Un exécuteur Spark est un outil destiné à conserver des données et à exécuter des tâches transmises par le pilote Spark. Le nombre d'exécuteurs Spark augmentera ou diminuera en fonction de la taille de votre cluster.
Note
Un exécuteur Spark possède plusieurs emplacements, de sorte que plusieurs tâches peuvent être traitées en parallèle. Spark prend en charge une tâche pour chaque cœur de processeur virtuel (vCPU) par défaut. Par exemple, si un exécuteur possède quatre cœurs de processeur, il peut exécuter quatre tâches simultanément.
Ensemble de données distribué résilient
Spark effectue la tâche complexe de stockage et de suivi de grands ensembles de données entre les exécuteurs Spark. Lorsque vous écrivez du code pour des tâches Spark, vous n'avez pas à vous soucier des détails du stockage. Spark fournit l'abstraction du jeu de données distribué résilient (RDD), qui est un ensemble d'éléments qui peuvent être utilisés en parallèle et qui peuvent être partitionnés entre les exécuteurs Spark du cluster.
La figure suivante montre la différence entre la manière de stocker les données en mémoire lorsqu'un script Python est exécuté dans son environnement typique et lorsqu'il est exécuté dans le framework Spark (PySpark).
![Python val [1,2,3 N], Apache Spark rdd = sc.parallelize [1,2,3 N].](images/store-data-memory.png)
-
Python — L'écriture
val = [1,2,3...N]dans un script Python permet de conserver les données en mémoire sur la seule machine sur laquelle le code est exécuté. -
PySpark— Spark fournit la structure de données RDD pour charger et traiter les données distribuées dans la mémoire sur plusieurs exécuteurs Spark. Vous pouvez générer un RDD avec un code tel que
rdd = sc.parallelize[1,2,3...N], et Spark peut automatiquement distribuer et conserver les données en mémoire entre plusieurs exécuteurs Spark.Dans de nombreux AWS Glue jobs, vous utilisez RDDs through AWS Glue DynamicFrameset Spark DataFrames. Il s'agit d'abstractions qui vous permettent de définir le schéma des données dans un RDD et d'effectuer des tâches de niveau supérieur avec ces informations supplémentaires. Du fait de leur utilisation RDDs interne, les données sont distribuées de manière transparente et chargées sur plusieurs nœuds dans le code suivant :
-
DynamicFrame
dyf= glueContext.create_dynamic_frame.from_options( 's3', {"paths": [ "s3://<YourBucket>/<Prefix>/"]}, format="parquet", transformation_ctx="dyf" ) -
DataFrame
df = spark.read.format("parquet") .load("s3://<YourBucket>/<Prefix>")
-
Un RDD possède les caractéristiques suivantes :
-
RDDs se composent de données divisées en plusieurs parties appelées partitions. Chaque exécuteur Spark stocke une ou plusieurs partitions en mémoire, et les données sont réparties entre plusieurs exécuteurs.
-
RDDs sont immuables, ce qui signifie qu'ils ne peuvent pas être modifiés après leur création. Pour modifier a DataFrame, vous pouvez utiliser des transformations définies dans la section suivante.
-
RDDs répliquez les données sur les nœuds disponibles, afin qu'ils puissent récupérer automatiquement les données en cas de défaillance des nœuds.
Évaluation paresseuse
RDDs prennent en charge deux types d'opérations : les transformations, qui créent un nouvel ensemble de données à partir d'un ensemble de données existant, et les actions, qui renvoient une valeur au programme pilote après avoir exécuté un calcul sur l'ensemble de données.
-
Transformations : étant RDDs immuables, vous ne pouvez les modifier qu'à l'aide d'une transformation.
Par exemple,
mapil s'agit d'une transformation qui fait passer chaque élément de l'ensemble de données par le biais d'une fonction et renvoie un nouveau RDD représentant les résultats. Notez que lamapméthode ne renvoie pas de sortie. Spark stocke la transformation abstraite pour le futur, au lieu de vous laisser interagir avec le résultat. Spark n'agira pas sur les transformations tant que vous n'aurez pas appelé une action. -
Actions — À l'aide de transformations, vous élaborez votre plan de transformation logique. Pour lancer le calcul, vous devez exécuter une action telle que
write,countshow, oucollect.Toutes les transformations dans Spark sont paresseuses, en ce sens qu'elles ne calculent pas leurs résultats immédiatement. Spark mémorise plutôt une série de transformations appliquées à certains ensembles de données de base, tels que les objets Amazon Simple Storage Service (Amazon S3). Les transformations sont calculées uniquement lorsqu'une action nécessite le renvoi d'un résultat au pilote. Cette conception permet à Spark de fonctionner plus efficacement. Par exemple, considérez la situation dans laquelle un ensemble de données créé par le biais de la
maptransformation n'est consommé que par une transformation qui réduit considérablement le nombre de lignes, telle quereduce. Vous pouvez ensuite transmettre le plus petit jeu de données qui a subi les deux transformations au pilote, au lieu de transmettre le plus grand jeu de données mappé.
Terminologie des applications Spark
Cette section couvre la terminologie de l'application Spark. Le pilote Spark crée un plan d'exécution et contrôle le comportement des applications dans plusieurs abstractions. Les termes suivants sont importants pour le développement, le débogage et le réglage des performances avec l'interface utilisateur Spark.
-
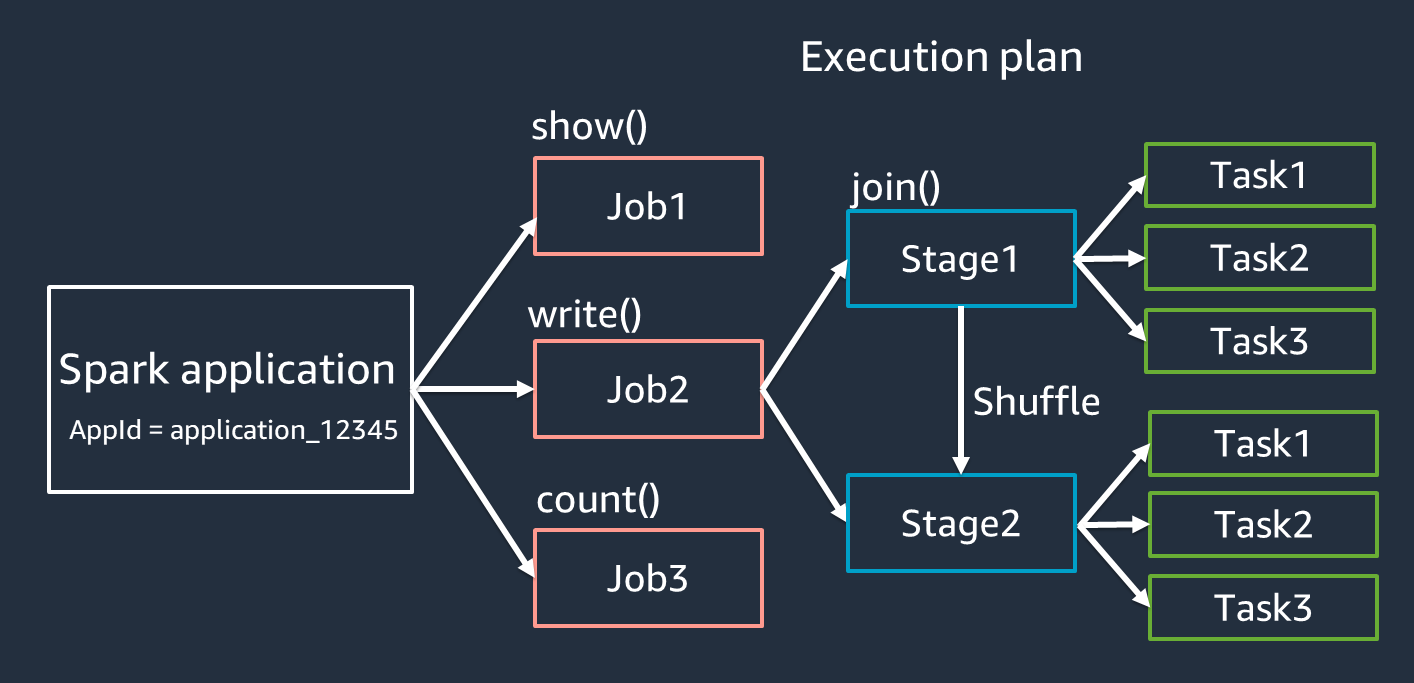
Application : basée sur une session Spark (contexte Spark). Identifié par un identifiant unique tel que
<application_XXX>. -
Emplois : basés sur les actions créées pour un RDD. Une tâche comprend une ou plusieurs étapes.
-
Étapes : basées sur les shuffles créés pour un RDD. Une étape comprend une ou plusieurs tâches. Le shuffle est le mécanisme de Spark pour redistribuer les données afin qu'elles soient regroupées différemment entre les partitions RDD. Certaines transformations, par exemple
join(), nécessitent un remaniement. Les shuffles sont abordés plus en détail dans la section Pratique de réglage Optimize shuffles. -
Tâches — Une tâche est l'unité minimale de traitement planifiée par Spark. Des tâches sont créées pour chaque partition RDD, et le nombre de tâches est le nombre maximum d'exécutions simultanées dans la phase.
Note
Les tâches sont l'élément le plus important à prendre en compte lors de l'optimisation du parallélisme. Le nombre de tâches varie en fonction du nombre de RDD
Parallelism
Spark parallélise les tâches de chargement et de transformation des données.
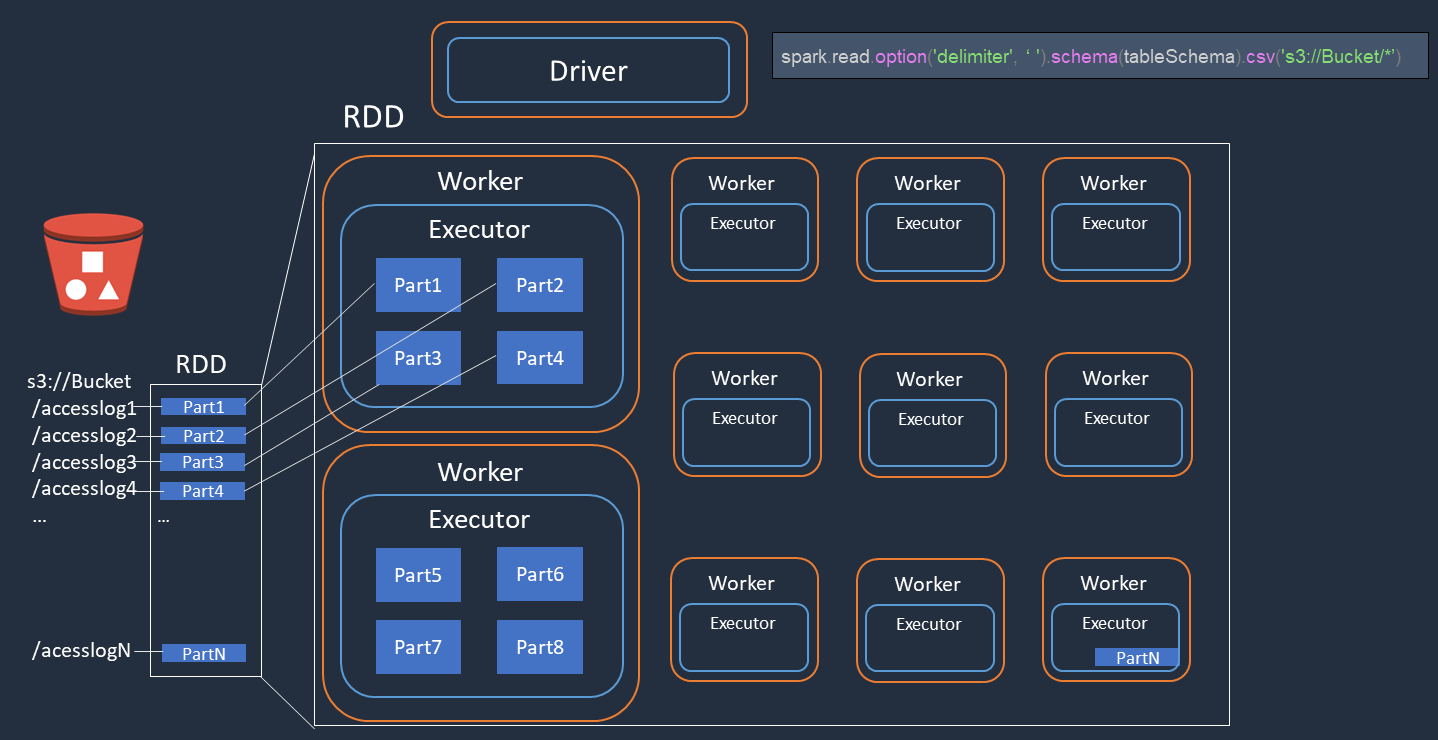
Prenons un exemple dans lequel vous effectuez un traitement distribué de fichiers journaux d'accès (nommésaccesslog1 ... accesslogN) sur Amazon S3. Le schéma suivant montre le flux de traitement distribué.
-
Le pilote Spark crée un plan d'exécution pour le traitement distribué entre de nombreux exécuteurs Spark.
-
Le pilote Spark attribue des tâches à chaque exécuteur en fonction du plan d'exécution. Par défaut, le pilote Spark crée des partitions RDD (chacune correspondant à une tâche Spark) pour chaque objet S3 (
Part1 ... N). Le pilote Spark assigne ensuite des tâches à chaque exécuteur. -
Chaque tâche Spark télécharge l'objet S3 qui lui est attribué et le stocke en mémoire dans la partition RDD. Ainsi, plusieurs exécuteurs Spark téléchargent et traitent la tâche qui leur est assignée en parallèle.
Pour plus de détails sur le nombre initial de partitions et l'optimisation, consultez la section Paralléliser les tâches.
Optimiseur de catalyseurs
En interne, Spark utilise un moteur appelé optimiseur Catalyst
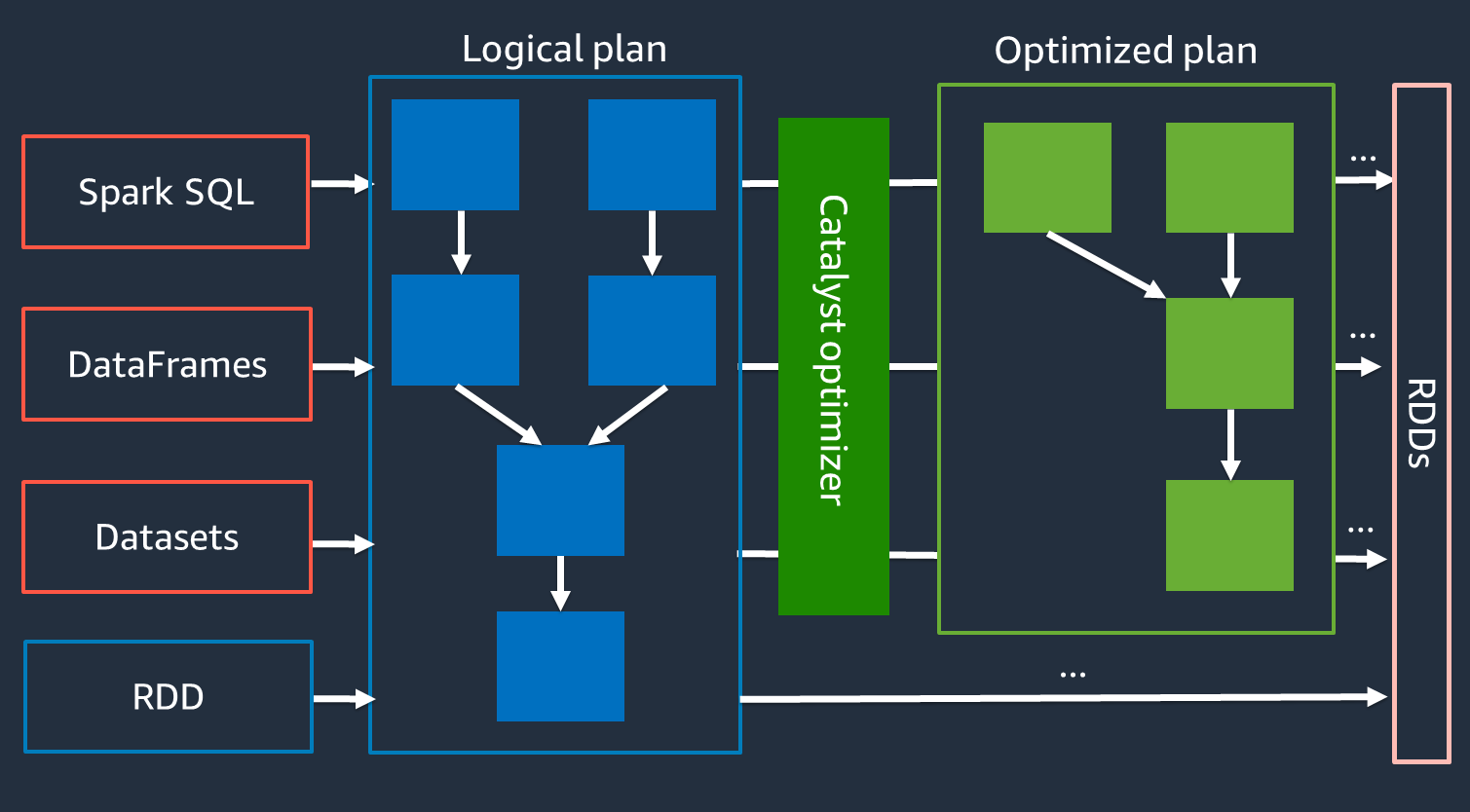
Comme l'optimiseur Catalyst ne fonctionne pas directement avec l'API RDD, les API de haut niveau APIs sont généralement plus rapides que les API RDD de bas niveau. Pour les jointures complexes, l'optimiseur Catalyst peut améliorer considérablement les performances en optimisant le plan d'exécution des tâches. Vous pouvez voir le plan optimisé de votre tâche Spark dans l'onglet SQL de l'interface utilisateur de Spark.
Exécution adaptative des requêtes
L'optimiseur Catalyst effectue l'optimisation de l'exécution par le biais d'un processus appelé Adaptive Query Execution. L'exécution adaptative des requêtes utilise les statistiques d'exécution pour réoptimiser le plan d'exécution des requêtes pendant l'exécution de votre tâche. L'exécution adaptative des requêtes propose plusieurs solutions aux problèmes de performances, notamment la fusion de partitions post-shuffle, la conversion de la jointure par tri-fusion en jointure de diffusion et l'optimisation des jointures asymétriques, comme décrit dans les sections suivantes.
L'exécution adaptative des requêtes est disponible dans la AWS Glue version 3.0 et les versions ultérieures, et elle est activée par défaut dans la AWS Glue version 4.0 (Spark 3.3.0) et les versions ultérieures. L'exécution adaptative des requêtes peut être activée ou désactivée en l'utilisant spark.conf.set("spark.sql.adaptive.enabled",
"true") dans votre code.
Cloisons post-shuffle fusionnées
Cette fonctionnalité réduit les partitions RDD (coalesce) après chaque shuffle en fonction des statistiques de sortie. map Cela simplifie le réglage du numéro de partition shuffle lors de l'exécution de requêtes. Il n'est pas nécessaire de définir un numéro de partition shuffle adapté à votre ensemble de données. Spark peut choisir le numéro de partition shuffle approprié lors de l'exécution une fois que vous avez un nombre initial de partitions shuffle suffisamment important.
La fusion des partitions post-shuffle est activée lorsque les deux sont activées spark.sql.adaptive.enabled et spark.sql.adaptive.coalescePartitions.enabled sont définies sur true. Pour plus d'informations, consultez la documentation d'Apache Spark
Conversion d'une jointure sort-merge en jointure de diffusion
Cette fonctionnalité reconnaît lorsque vous joignez deux ensembles de données de taille sensiblement différente et adopte un algorithme de jointure plus efficace basé sur ces informations. Pour plus de détails, consultez la documentation d'Apache Spark
Optimisation des jointures asymétriques
L'asymétrie des données est l'un des obstacles les plus courants pour les tâches Spark. Il décrit une situation dans laquelle les données sont orientées vers des partitions RDD spécifiques (et, par conséquent, vers des tâches spécifiques), ce qui retarde le temps de traitement global de l'application. Cela peut souvent dégrader les performances des opérations de jointure. La fonction d'optimisation des jointures asymétriques gère dynamiquement l'asymétrie des jointures par tri-fusion en divisant (et en répliquant si nécessaire) les tâches asymétriques en tâches à peu près de même taille.
Cette fonctionnalité est activée lorsqu'elle spark.sql.adaptive.skewJoin.enabled est définie sur true. Pour plus de détails, consultez la documentation d'Apache Spark
