Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Paralléliser les tâches
Pour optimiser les performances, il est important de paralléliser les tâches de chargement et de transformation des données. Comme nous l'avons indiqué dans la section Rubriques clés d'Apache Spark, le nombre de partitions résilientes d'ensembles de données distribués (RDD) est important, car il détermine le degré de parallélisme. Chaque tâche créée par Spark correspond à une RDD partition sur une base 1:1. Pour obtenir les meilleures performances, vous devez comprendre comment le nombre de RDD partitions est déterminé et comment ce nombre est optimisé.
Si le parallélisme n'est pas suffisant, les symptômes suivants seront enregistrés dans les CloudWatchmétriques et dans l'interface utilisateur de Spark.
CloudWatch métriques
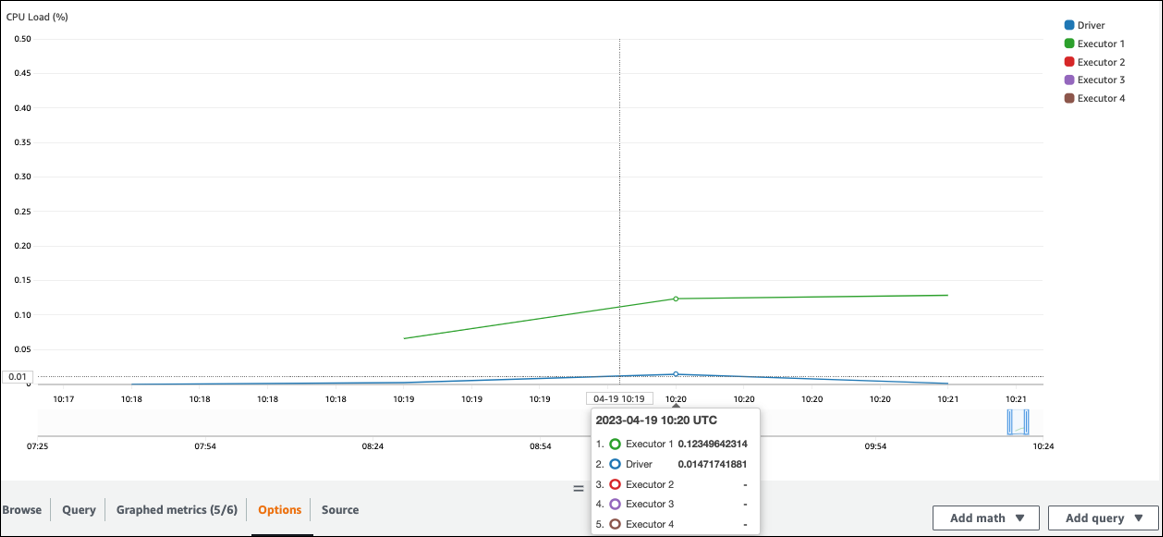
Vérifiez la CPUcharge et l'utilisation de la mémoire. Si certains exécuteurs ne traitent pas pendant une phase de votre travail, il convient d'améliorer le parallélisme. Dans ce cas, pendant la période visualisée, l'exécuteur 1 exécutait une tâche, mais pas les autres exécuteurs (2, 3 et 4). Vous pouvez en déduire que le pilote Spark n'a pas assigné de tâches à ces exécuteurs.
Interface utilisateur Spark
Dans l'onglet Stage de l'interface utilisateur de Spark, vous pouvez voir le nombre de tâches d'une étape. Dans ce cas, Spark n'a effectué qu'une seule tâche.

En outre, la chronologie des événements montre qu'Executor 1 traite une tâche. Cela signifie que le travail de cette étape a été entièrement effectué sur un exécuteur, tandis que les autres étaient inactifs.

Si vous observez ces symptômes, essayez les solutions suivantes pour chaque source de données.
Paralléliser le chargement de données depuis Amazon S3
Pour paralléliser les chargements de données depuis Amazon S3, vérifiez d'abord le nombre de partitions par défaut. Vous pouvez ensuite déterminer manuellement un nombre cible de partitions, mais veillez à ne pas en avoir trop.
Déterminer le nombre de partitions par défaut
Pour Amazon S3, le nombre initial de RDD partitions Spark (chacune correspondant à une tâche Spark) est déterminé par les caractéristiques de votre ensemble de données Amazon S3 (par exemple, le format, la compression et la taille). Lorsque vous créez un AWS Glue DynamicFrame ou un Spark DataFrame à partir d'CSVobjets stockés dans Amazon S3, le nombre initial de RDD partitions (NumPartitions) peut être approximativement calculé comme suit :
-
Taille de l'objet <= 64 Mo :
NumPartitions = Number of Objects -
Taille de l'objet > 64 Mo :
NumPartitions = Total Object Size / 64 MB -
Non séparable (gzip) :
NumPartitions = Number of Objects
Comme indiqué dans la section Réduire la quantité de données numérisées, Spark divise les grands objets S3 en divisions qui peuvent être traitées en parallèle. Lorsque la taille de l'objet est supérieure à la taille de la division, Spark divise l'objet et crée une RDD partition (et une tâche) pour chaque division. La taille fractionnée de Spark dépend du format de vos données et de votre environnement d'exécution, mais il s'agit d'une approximation de départ raisonnable. Certains objets sont compressés à l'aide de formats de compression non séparables tels que gzip. Spark ne peut donc pas les diviser.
La NumPartitions valeur peut varier en fonction du format de vos données, de la compression, de AWS Glue la version, du nombre de AWS Glue travailleurs et de la configuration de Spark.
Par exemple, lorsque vous chargez un seul csv.gz objet de 10 Go à l'aide d'un Spark DataFrame, le pilote Spark ne crée qu'une seule RDD partition (NumPartitions=1) car gzip n'est pas divisible. Cela entraîne une charge importante sur un exécuteur Spark en particulier et aucune tâche n'est assignée aux autres exécuteurs, comme décrit dans la figure suivante.
Vérifiez le nombre réel de tâches (NumPartitions) pour l'étape df.rdd.getNumPartitions() dans l'onglet Spark Web UI Stage, ou exécutez votre code pour vérifier le parallélisme.
Lorsque vous trouvez un fichier gzip de 10 Go, vérifiez si le système qui génère ce fichier peut le générer dans un format divisible. Si ce n'est pas possible, vous devrez peut-être augmenter la capacité du cluster pour traiter le fichier. Pour exécuter des transformations efficaces sur les données que vous avez chargées, vous devez rééquilibrer l'RDDensemble des travailleurs de votre cluster en utilisant la répartition.
Déterminer manuellement un nombre cible de partitions
En fonction des propriétés de vos données et de l'implémentation de certaines fonctionnalités par Spark, vous risquez de vous retrouver avec une faible NumPartitions valeur, même si le travail sous-jacent peut toujours être parallélisé. S'il NumPartitions est trop petit, exécutez-le df.repartition(N) pour augmenter le nombre de partitions afin que le traitement puisse être réparti entre plusieurs exécuteurs Spark.
Dans ce cas, l'exécution df.repartition(100) passera NumPartitions de 1 à 100, ce qui créera 100 partitions de vos données, chacune dotée d'une tâche pouvant être assignée aux autres exécuteurs.
L'opération repartition(N) divise l'ensemble des données de manière égale (10 Go/100 partitions = 100 Mo/partition), évitant ainsi le biais des données vers certaines partitions.
Note
Lorsqu'une opération de shuffle telle qu'elle join est exécutée, le nombre de partitions augmente ou diminue dynamiquement en fonction de la valeur de spark.sql.shuffle.partitions ou. spark.default.parallelism Cela facilite un échange de données plus efficace entre les exécuteurs Spark. Pour plus d'informations, consultez la documentation de Spark
Lorsque vous déterminez le nombre cible de partitions, votre objectif est de maximiser l'utilisation des AWS Glue travailleurs provisionnés. Le nombre de AWS Glue travailleurs et le nombre de tâches Spark sont liés par le nombre devCPUs. Spark prend en charge une tâche pour chaque CPU vcore. Dans AWS Glue la version 3.0 ou ultérieure, vous pouvez calculer un nombre cible de partitions à l'aide de la formule suivante.
# Calculate NumPartitions by WorkerType numExecutors = (NumberOfWorkers - 1) numSlotsPerExecutor = 4 if WorkerType is G.1X 8 if WorkerType is G.2X 16 if WorkerType is G.4X 32 if WorkerType is G.8X NumPartitions = numSlotsPerExecutor * numExecutors # Example: Glue 4.0 / G.1X / 10 Workers numExecutors = ( 10 - 1 ) = 9 # 1 Worker reserved on Spark Driver numSlotsPerExecutor = 4 # G.1X has 4 vCpu core ( Glue 3.0 or later ) NumPartitions = 9 * 4 = 36
Dans cet exemple, chaque worker G-1X fournit quatre CPU cœurs en v à un exécuteur Spark ()spark.executor.cores = 4. Spark prend en charge une tâche pour chaque v CPU Core, de sorte que les exécuteurs G-1X Spark peuvent exécuter quatre tâches simultanément ()numSlotPerExecutor. Ce nombre de partitions permet d'utiliser pleinement le cluster si les tâches prennent le même temps. Cependant, certaines tâches prennent plus de temps que d'autres, ce qui crée des cœurs inactifs. Si tel est le cas, envisagez de multiplier numPartitions par 2 ou 3 pour répartir et planifier efficacement les tâches fastidieuses.
Trop de partitions
Un nombre excessif de partitions entraîne un nombre excessif de tâches. Cela entraîne une charge importante sur le pilote Spark en raison de la surcharge liée au traitement distribué, comme les tâches de gestion et l'échange de données entre les exécuteurs Spark.
Si le nombre de partitions de votre travail est nettement supérieur au nombre de partitions cible, envisagez de réduire le nombre de partitions. Vous pouvez réduire les partitions en utilisant les options suivantes :
-
Si la taille de vos fichiers est très petite, utilisez AWS Glue groupFiles. Vous pouvez réduire le parallélisme excessif résultant du lancement d'une tâche Apache Spark pour traiter chaque fichier.
-
coalesce(N)À utiliser pour fusionner des partitions. Il s'agit d'un procédé peu coûteux. Lorsque vous réduisez le nombre de partitions,coalesce(N)il est préférable de le fairerepartition(N), car ilrepartition(N)effectue un shuffle pour répartir de manière égale le nombre d'enregistrements dans chaque partition. Cela augmente les coûts et les frais de gestion. -
Utilisez l'exécution adaptative des requêtes dans Spark 3.x. Comme indiqué dans la section Rubriques clés d'Apache Spark, Adaptive Query Execution fournit une fonction permettant de fusionner automatiquement le nombre de partitions. Vous pouvez utiliser cette approche lorsque vous ne pouvez pas connaître le nombre de partitions tant que vous n'avez pas effectué l'exécution.
Paralléliser le chargement des données depuis JDBC
Le nombre de RDD partitions Spark est déterminé par la configuration. Notez que par défaut, une seule tâche est exécutée pour analyser l'intégralité d'un ensemble de données source par le biais d'une SELECT requête.
Tout comme AWS Glue DynamicFrames Spark, ils DataFrames prennent en charge le chargement de JDBC données parallélisé sur plusieurs tâches. Cela se fait en utilisant des where prédicats pour diviser une SELECT requête en plusieurs requêtes. Pour paralléliser les lectures depuisJDBC, configurez les options suivantes :
-
Pour AWS Glue DynamicFrame, régler
hashfield(ouhashexpression)ethashpartition. Pour en savoir plus, consultez Reading from JDBC tables in parallel.connection_mysql8_options = { "url": "jdbc:mysql://XXXXXXXXXX.XXXXXXX.us-east-1.rds.amazonaws.com:3306/test", "dbtable": "medicare_tb", "user": "test", "password": "XXXXXXXXX", "hashexpression":"id", "hashpartitions":"10" } datasource0 = glueContext.create_dynamic_frame.from_options( 'mysql', connection_options=connection_mysql8_options, transformation_ctx= "datasource0" ) -
Pour Spark DataFrame, set
numPartitionspartitionColumn,lowerBound, etupperBound. Pour en savoir plus, voir Vers JDBCd'autres bases de données. df = spark.read \ .format("jdbc") \ .option("url", "jdbc:mysql://XXXXXXXXXX.XXXXXXX.us-east-1.rds.amazonaws.com:3306/test") \ .option("dbtable", "medicare_tb") \ .option("user", "test") \ .option("password", "XXXXXXXXXX") \ .option("partitionColumn", "id") \ .option("numPartitions", "10") \ .option("lowerBound", "0") \ .option("upperBound", "1141455") \ .load() df.write.format("json").save("s3://bucket_name/Tests/sparkjdbc/with_parallel/")
Paralléliser le chargement des données depuis DynamoDB lors de l'utilisation du connecteur ETL
Le nombre de RDD partitions Spark est déterminé par le dynamodb.splits paramètre. Pour paralléliser les lectures depuis Amazon DynamoDB, configurez les options suivantes :
-
Augmentez la valeur de
dynamodb.splits. -
Optimisez le paramètre en suivant la formule expliquée dans Types de connexion et options pour ETL in AWS Glue for Spark.
Paralléliser le chargement des données depuis Kinesis Data Streams
Le nombre de RDD partitions Spark est déterminé par le nombre de partitions présentes dans le flux de données source Amazon Kinesis Data Streams. Si votre flux de données ne contient que quelques fragments, il n'y aura que quelques tâches Spark. Cela peut entraîner un faible parallélisme dans les processus en aval. Pour paralléliser les lectures depuis Kinesis Data Streams, configurez les options suivantes :
-
Augmentez le nombre de partitions pour obtenir plus de parallélisme lors du chargement de données depuis Kinesis Data Streams.
-
Si la logique du microlot est suffisamment complexe, envisagez de repartitionner les données au début du lot, après avoir supprimé les colonnes inutiles.
Pour plus d'informations, consultez la section Meilleures pratiques pour optimiser les coûts et les performances des ETL tâches de AWS Glue streaming
Paralléliser les tâches après le chargement des données
Pour paralléliser les tâches après le chargement des données, augmentez le nombre de RDD partitions à l'aide des options suivantes :
-
Répartitionnez les données pour générer un plus grand nombre de partitions, en particulier juste après le chargement initial si le chargement lui-même ne peut pas être parallélisé.
Appelez
repartition()soit en DynamicFrame activant DataFrame, soit en spécifiant le nombre de partitions. En règle générale, deux ou trois fois le nombre de cœurs disponibles est deux ou trois fois supérieur.Cependant, lors de l'écriture d'une table partitionnée, cela peut entraîner une explosion de fichiers (chaque partition peut potentiellement générer un fichier dans chaque partition de table). Pour éviter cela, vous pouvez le répartir DataFrame par colonne. Cela utilise les colonnes de partition de la table afin que les données soient organisées avant d'être écrites. Vous pouvez spécifier un plus grand nombre de partitions sans placer de petits fichiers sur les partitions de la table. Veillez toutefois à éviter toute distorsion des données, dans laquelle certaines valeurs de partition se retrouveraient avec la plupart des données et retarderaient l'exécution de la tâche.
-
En cas de shuffles, augmentez la
spark.sql.shuffle.partitionsvaleur. Cela peut également aider à résoudre les problèmes de mémoire lors du shuffling.Lorsque vous avez plus de 2 001 partitions shuffle, Spark utilise un format de mémoire compressé. Si vous avez un nombre proche de celui-ci, vous souhaiterez peut-être définir une
spark.sql.shuffle.paritionsvaleur supérieure à cette limite pour obtenir une représentation plus efficace.
