Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Augmenter la capacité du cluster
Si votre travail prend trop de temps, mais que les exécuteurs consomment suffisamment de ressources et que Spark crée un volume important de tâches par rapport aux cœurs disponibles, pensez à augmenter la capacité du cluster. Pour déterminer si cela est approprié, utilisez les mesures suivantes.
CloudWatch métriques
-
Vérifiez l'utilisation de la CPUcharge et de la mémoire pour déterminer si les exécuteurs consomment suffisamment de ressources.
-
Vérifiez la durée de la tâche pour déterminer si le temps de traitement est trop long pour atteindre vos objectifs de performance.
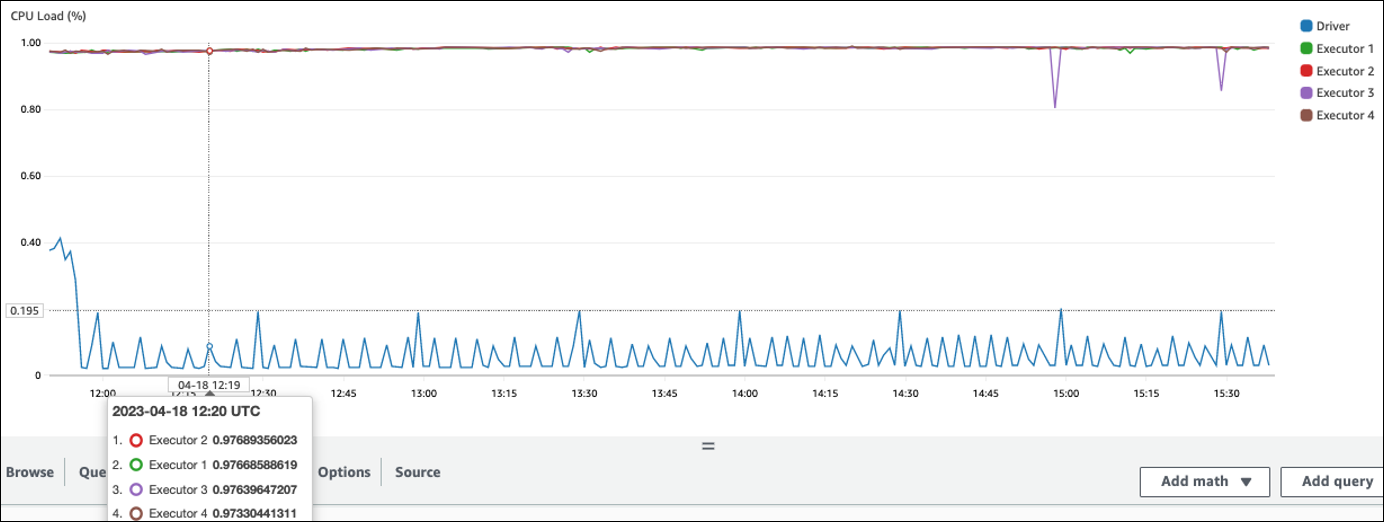
Dans l'exemple suivant, quatre exécuteurs exécutent une CPU charge supérieure à 97 %, mais le traitement n'est pas terminé au bout de trois heures environ.
Note
Si CPU la charge est faible, vous ne bénéficierez probablement pas de l'augmentation de la capacité du cluster.
Interface utilisateur Spark
Dans l'onglet Job ou Stage, vous pouvez voir le nombre de tâches pour chaque tâche ou étape. Dans l'exemple suivant, Spark a créé 58100 des tâches.

Dans l'onglet Exécuteur, vous pouvez voir le nombre total d'exécuteurs et de tâches. Dans la capture d'écran suivante, chaque exécuteur Spark possède quatre cœurs et peut effectuer quatre tâches simultanément.
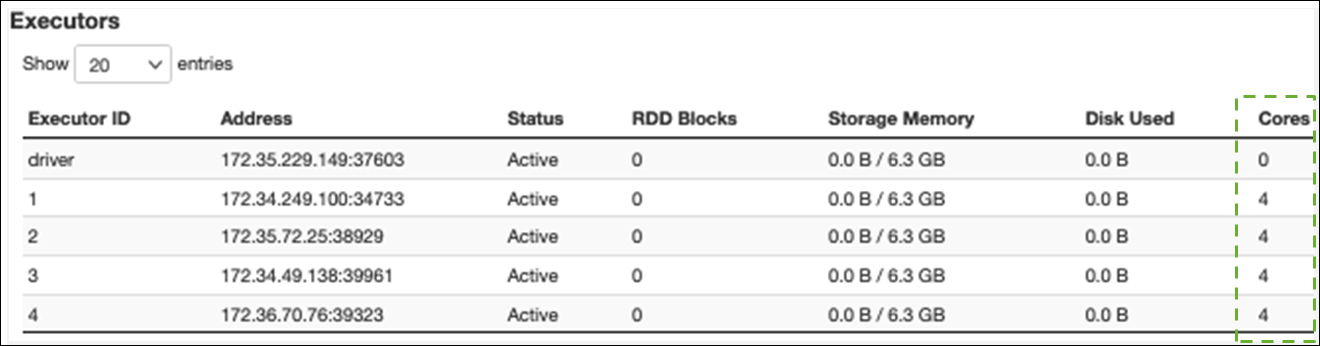
Dans cet exemple, le nombre de tâches Spark () 58100) est bien supérieur aux 16 tâches que les exécuteurs peuvent traiter simultanément (4 exécuteurs × 4 cœurs).
Si vous observez ces symptômes, envisagez de redimensionner le cluster. Vous pouvez augmenter la capacité du cluster à l'aide des options suivantes :
-
Enable AWS Glue Auto Scaling — Auto Scaling est disponible pour vos tâches AWS Glue d'extraction, de transformation, de chargement (ETL) et de streaming dans AWS Glue la version 3.0 ou ultérieure. AWS Glue ajoute et supprime automatiquement des travailleurs du cluster en fonction du nombre de partitions à chaque étape ou de la vitesse à laquelle les microbatches sont générés lors de l'exécution de la tâche.
Si vous observez une situation dans laquelle le nombre de travailleurs n'augmente pas même si Auto Scaling est activé, envisagez d'ajouter des travailleurs manuellement. Notez toutefois que le dimensionnement manuel pour une étape peut entraîner l'inactivité de nombreux travailleurs au cours des étapes ultérieures, ce qui coûte plus cher pour un gain de performance nul.
Après avoir activé Auto Scaling, vous pouvez voir le nombre d'exécuteurs dans les métriques des CloudWatch exécuteurs. Utilisez les mesures suivantes pour surveiller la demande d'exécuteurs dans les applications Spark :
-
glue.driver.ExecutorAllocationManager.executors.numberAllExecutors -
glue.driver.ExecutorAllocationManager.executors.numberMaxNeededExecutors
Pour plus d'informations sur les métriques, consultez la section Surveillance AWS Glue à l'aide CloudWatch des métriques Amazon.
-
-
Élargissement : augmentation du nombre de AWS Glue travailleurs — Vous pouvez augmenter manuellement le nombre de AWS Glue travailleurs. Ajoutez des travailleurs uniquement jusqu'à ce que vous observiez des travailleurs inactifs. À ce stade, l'ajout de travailleurs augmentera les coûts sans améliorer les résultats. Pour plus d'informations, consultez Paralléliser les tâches.
-
Élargissement : utilisez un type de travail plus important : vous pouvez modifier manuellement le type d'instance de vos AWS Glue collaborateurs afin d'utiliser des travailleurs dotés d'un plus grand nombre de cœurs, de mémoire et d'espace de stockage. Les types de travailleurs plus importants vous permettent d'effectuer une mise à l'échelle verticale et d'exécuter des tâches d'intégration de données intensives, telles que des transformations de données gourmandes en mémoire, des agrégations asymétriques et des contrôles de détection d'entités impliquant des pétaoctets de données.
La mise à l'échelle est également utile dans les cas où le pilote Spark a besoin d'une capacité plus importante, par exemple parce que le plan de requêtes de tâches est assez volumineux. Pour plus d'informations sur les types de travailleurs et leurs performances, consultez le billet de blog consacré au AWS Big Data Scale your AWS Glue for Apache Spark jobs with new larger worker types G.4X et G.8X
. L'utilisation de travailleurs de plus grande taille peut également réduire le nombre total de travailleurs nécessaires, ce qui augmente les performances en réduisant le remaniement dans les opérations intensives telles que les jointures.
