Amazon Redshift ne prendra plus en charge l'utilisation des UDF Python après le 30 juin 2026. Nous allons commencer à l'appliquer par étapes. Pour plus d'informations sur les options de fin de vie et de migration de Python, consultez le billet de blog
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation de la vue SVL_QUERY_SUMMARY
Pour analyser les informations récapitulatives sur la requête par flux à l’aide de SVL_QUERY_SUMMARY, procédez comme suit :
-
Exécutez la requête suivante pour déterminer l’ID de votre requête :
select query, elapsed, substring from svl_qlog order by query desc limit 5;Examinez le texte de la requête tronquée dans le champ
substringpour déterminer quelle valeur dequeryreprésente votre requête. Si vous avez exécuté la requête plusieurs fois, utilisez la valeur dequeryde la ligne avec la valeur deelapsedinférieure. Il s’agit de la ligne de la version compilée. Si vous avez exécuté un grand nombre de requêtes, vous pouvez augmenter la valeur utilisée par la clause LIMIT utilisée pour vous assurer que votre requête est incluse. -
Sélectionnez les lignes de SVL_QUERY_SUMMARY pour votre requête. Ordonnez les résultats par flux, par segment et par étape :
select * from svl_query_summary where query = MyQueryID order by stm, seg, step;Voici un exemple de résultat.
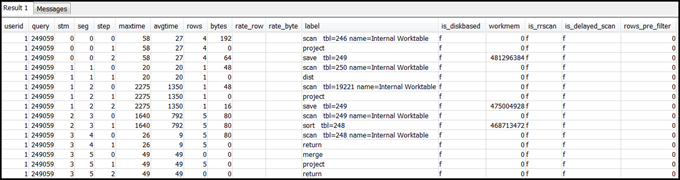
-
Mappe les étapes aux opérations du plan de requête à l’aide des informations de Mappage du plan de requête au résumé de la requête. Elles doivent avoir à peu près les mêmes valeurs pour les lignes et les octets (lignes * largeur dans le plan de requête). Si ce n’est pas le cas, consultez Statistiques de table manquantes ou obsolètes pour connaître les solutions recommandées.
-
Vérifiez si le champ
is_diskbaseda une valeur det(true) pour n’importe quelle étape. Les hachages, les agrégats et les tris sont les opérateurs susceptibles d’écrire des données sur le disque si le système ne dispose pas de suffisamment de mémoire allouée pour le traitement des requêtes.Si
is_diskbaseda la valeur true, consultez Mémoire insuffisante allouée à la requête pour connaître les solutions recommandées. -
Passez en revue les valeurs des
labelchamps et vérifiez s'il existe une AGG-DIST-AGG séquence quelconque dans les étapes. Sa présence indique une agrégation en deux étapes, ce qui est onéreux. Pour résoudre ce problème, modifiez la clause GROUP BY pour utiliser la clé de distribution (la première clé, s’il y en a plusieurs). -
Vérifiez la valeur de
maxtimede chaque segment (identique à toutes les étapes du segment). Identifiez le segment ayant la valeur demaxtimela plus élevée et vérifiez les étapes de ce segment pour les opérateurs suivants.Note
Une valeur de
maxtimeélevée n’indique pas nécessairement de problème avec le segment. Malgré une valeur élevée, le temps de traitement du segment pourrait ne pas avoir été long. Tous les segments d’un flux sont chronométrés ensemble. Toutefois, certains segments en aval ne sont peut-être pas en mesure de s’exécuter tant qu’ils n’obtiennent pas de données de ceux situés en amont. Cela peut donner l’impression qu’ils ont pris beaucoup de temps, car leur valeurmaxtimeinclura leur temps d’attente et leur temps de traitement.-
BCAST ou DIST : dans ces cas, la valeur de
maxtimeélevée peut être le résultat d’une redistribution d’un grand nombre de lignes. Pour connaître les solutions recommandées, consultez Distribution des données sous-optimales. -
HJOIN (jointure par hachage) : si l’étape en question a une valeur très élevée dans le champ
rowspar rapport à la valeur derowsdans l’étape RETURN finale dans la requête, consultez Joindre par hachage pour connaître les solutions recommandées. -
SCAN/SORT: recherchez une séquence d'étapes SCAN, SORT, SCAN, MERGE juste avant une étape de jointure. Ce modèle indique que des données non triées sont analysées, triées, puis fusionnées avec la région triée de la table.
Vérifiez si la valeur des lignes de l’étape SCAN est très élevée par rapport à la valeur des lignes de l’étape RETURN finale dans la requête. Ce modèle indique que le moteur d’exécution analyse des lignes qui sont ignorées par la suite, ce qui est inefficace. Pour connaître les solutions recommandées, consultez Prédicat pas assez restrictif.
Si la valeur
maxtimede l’étape SCAN est élevée, consultez Clause WHERE sous-optimale pour connaître les solutions recommandées.Si la valeur
rowsde l’étape SORT n’est pas égale à zéro, consultez Lignes non triées ou mal triées pour connaître les solutions recommandées.
-
-
Vérifiez les valeurs
rowsetbytesdes étapes 5 à 10 précédant l’étape RETURN finale pour savoir quelle est la quantité de données renvoyée au client. Ce processus peut être complexe.Par exemple, dans l’exemple de requête récapitulative suivant, la troisième étape PROJECT fournit une valeur de
rows, mais pas une valeur debytes. Les étapes précédentes avec la même valeur derowsvous permettront de trouver l’étape SCAN qui fournit des informations sur les lignes et les octets :Voici un exemple de résultat.
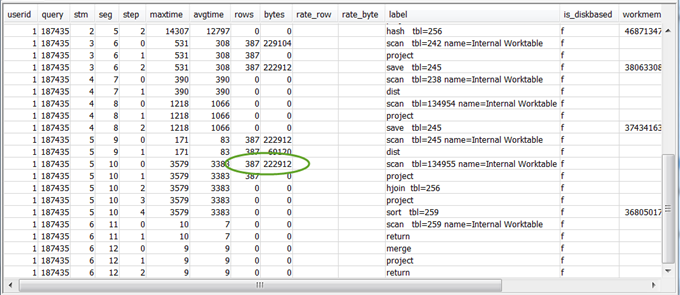
Si vous renvoyez un volume inhabituellement élevé de données, consultez Ensemble de résultats très volumineux pour connaître les solutions recommandées.
-
Vérifiez si la valeur de
bytesest élevée par rapport à la valeur derowspour n’importe quelle étape, par rapport aux autres étapes. Ce modèle peut indiquer que vous sélectionnez un grand nombre de colonnes. Pour connaître les solutions recommandées, consultez Longue liste SELECT.
