Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Chargement des données dans l’ordre de la clé de tri
Si vous chargez vos données dans l'ordre des touches de tri à l'aide d'une COPY commande, vous pouvez réduire, voire supprimer, le besoin de passer le vide.
COPYajoute automatiquement de nouvelles lignes à la zone triée du tableau lorsque toutes les conditions suivantes sont réunies :
-
La table utilise une clé de tri composée avec une seule colonne de tri.
-
La colonne de tri est NOTNULL.
-
La table est triée ou vide à 100 %.
-
Toutes les nouvelles lignes sont plus élevées dans l’ordre de tri que les lignes existantes, y compris les lignes marquées pour la suppression. Dans ce cas, Amazon Redshift utilise les huit premiers octets de la clé de tri pour déterminer l’ordre de tri.
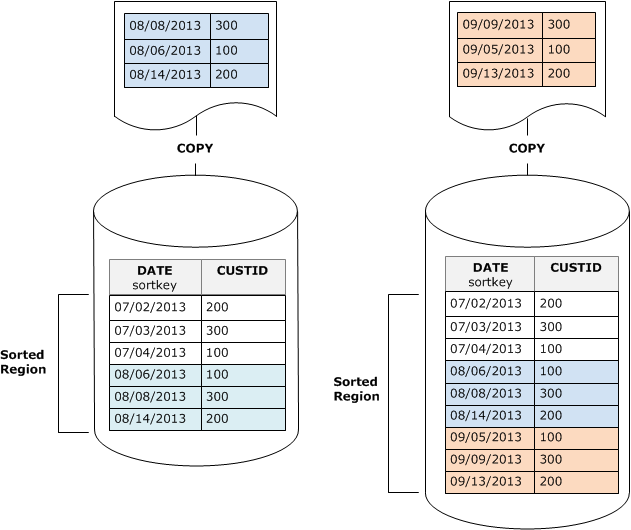
Par exemple, supposons que vous ayez une table qui enregistre les événements clients à l’aide d’un ID client et de l’heure. Si vous triez sur l’ID client, il est probable que la plage des clés de tri des nouvelles lignes ajoutées par les chargements incrémentiels chevauchent la plage existante, comme illustré dans l’exemple précédent, ce qui conduit à une opération VACUUM coûteuse.
Si vous définissez votre clé de tri sur une colonne d’horodatage, vos nouvelles lignes sont ajoutées dans l’ordre de tri à la fin de la table, comme l’illustre le schéma suivant, ce qui rend l’opération VACUUM moins (voire plus du tout) nécessaire.