Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Isolation des données
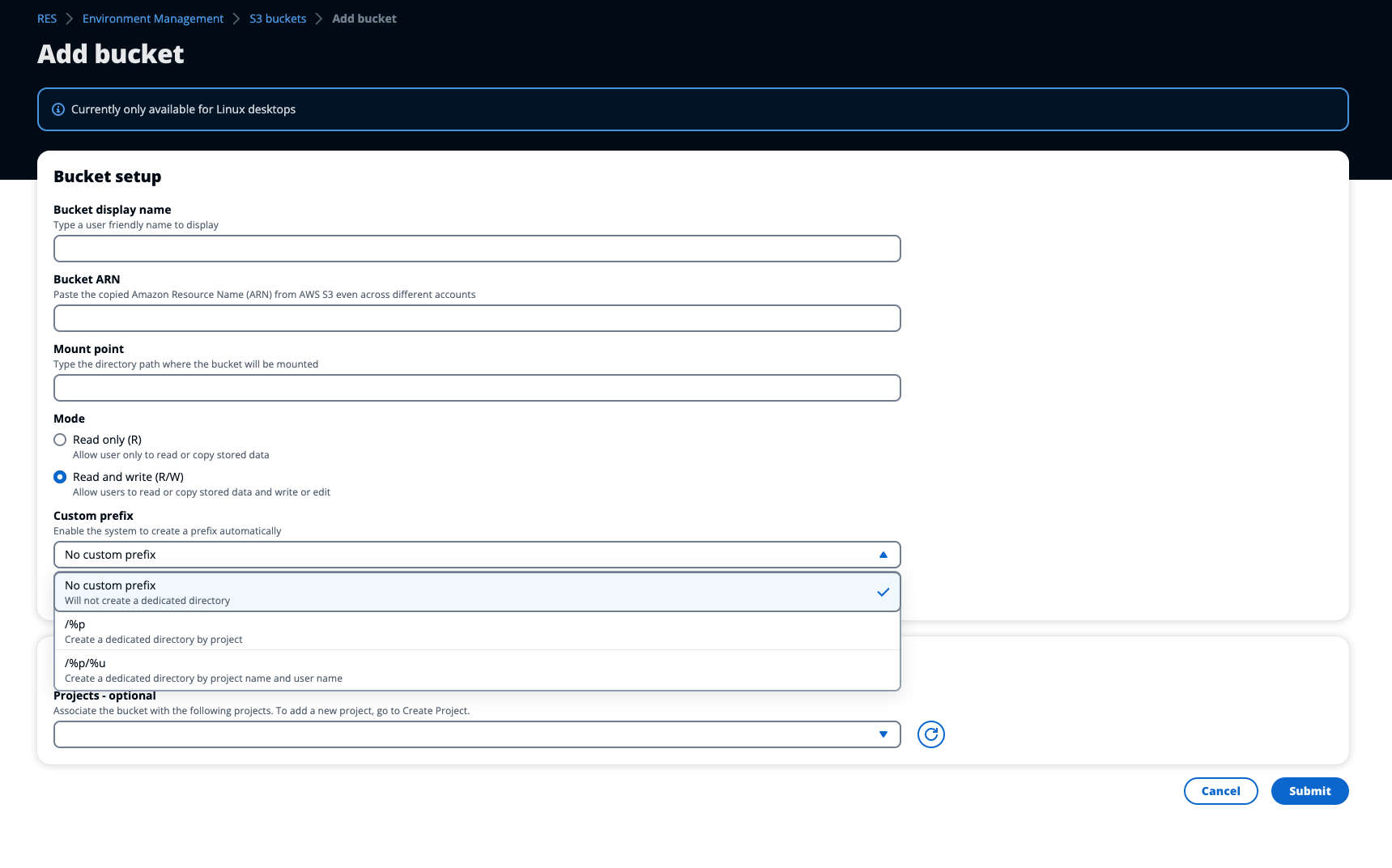
Lorsque vous ajoutez un compartiment S3 à RES, vous avez la possibilité d'isoler les données qu'il contient pour des projets et des utilisateurs spécifiques. Sur la page Ajouter un compartiment, vous pouvez sélectionner un mode Read Only (R) ou Read and Write (R/W).
Lecture seule
Si Read Only (R) cette option est sélectionnée, l'isolation des données est appliquée en fonction du préfixe de l'ARN du bucket (Amazon Resource Name). Par exemple, si un administrateur ajoute un bucket à RES à l'aide de l'ARN arn:aws:s3::: et associe ce bucket au projet A et au projet B, les utilisateurs qui lancent VDIs depuis le projet A et le projet B ne peuvent lire que les données situées bucket-name/example-data/bucket-name/example-data
Lisez et écrivez
Si Read and Write (R/W) cette option est sélectionnée, l'isolation des données est toujours appliquée en fonction du préfixe de l'ARN du bucket, comme décrit ci-dessus. Ce mode comporte des options supplémentaires permettant aux administrateurs de fournir un préfixe basé sur des variables pour le compartiment S3. Lorsque cette option Read and Write (R/W) est sélectionnée, une section Préfixe personnalisé devient disponible et propose un menu déroulant avec les options suivantes :
Aucun préfixe personnalisé
/%p
/%p/%u
- Aucune isolation personnalisée des données
-
Lorsque
No custom prefixle préfixe personnalisé est sélectionné, le bucket est ajouté sans aucune isolation de données personnalisée. Cela permet à tous les projets associés au bucket d'avoir un accès en lecture et en écriture. Par exemple, si un administrateur ajoute un bucket à RES à l'aide de l'ARNarn:aws:s3:::avecbucket-nameNo custom prefixselected et associe ce bucket aux projets A et B, les utilisateurs qui le lancent VDIs depuis le projet A et le projet B auront un accès illimité en lecture et en écriture au bucket. - Isolation des données au niveau du projet
-
Lorsque
/%ple préfixe personnalisé est sélectionné, les données du compartiment sont isolées pour chaque projet spécifique qui lui est associé. La%pvariable représente le code du projet. Par exemple, si un administrateur ajoute un bucket à RES en utilisant l'ARNarn:aws:s3:::avecbucket-name/%pselected et un point de montage de/bucket, et qu'il associe ce bucket aux projets A et B, l'utilisateur A du projet A peut y écrire un fichier/bucket. L'utilisateur B du projet A peut également voir le fichier dans lequel l'utilisateur A a écrit/bucket. Toutefois, si l'utilisateur B lance un VDI dans le projet B et y jette un/bucketœil, il ne verra pas le fichier écrit par l'utilisateur A, car les données sont isolées par projet. Le fichier écrit par l'utilisateur A se trouve dans le compartiment S3 sous le préfixe,/ProjectAtandis que l'utilisateur B ne peut y accéder que/ProjectBs'il utilise le fichier VDIs depuis le projet B. - Isolation des données au niveau du projet et de l'utilisateur
-
Lorsque le préfixe personnalisé
/%p/%uest sélectionné, les données du compartiment sont isolées pour chaque projet spécifique et pour chaque utilisateur associé à ce projet. La%pvariable représente le code du projet et%ule nom d'utilisateur. Par exemple, un administrateur ajoute un bucket à RES en utilisant l'ARNarn:aws:s3:::dont le point de montage estbucket-name/%p/%usélectionné et le point de montage est égal à/bucket. Ce compartiment est associé au projet A et au projet B. L'utilisateur A du projet A peut y écrire un fichier/bucket. Contrairement au scénario précédent avec uniquement%pl'isolation, l'utilisateur B ne verra pas dans ce cas le fichier écrit par l'utilisateur A dans le projet A/bucket, car les données sont isolées à la fois par le projet et par l'utilisateur. Le fichier écrit par l'utilisateur A se trouve dans le compartiment S3 sous le préfixe,/ProjectA/UserAtandis que l'utilisateur B ne peut y accéder que/ProjectA/UserBs'il l'utilise VDIs dans le projet A.
