Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisez l'algorithme de SageMaker prévision AI DeePar
L'algorithme de prévision DeePar d'Amazon SageMaker AI est un algorithme d'apprentissage supervisé permettant de prévoir des séries chronologiques scalaires (unidimensionnelles) à l'aide de réseaux neuronaux récurrents (RNN). Les méthodes de prévisions classiques, telles qu'ARIMA (modèle autorégressif à moyennes mobiles intégré) ou ETS (lissage exponentiel), associent un modèle unique à chaque série chronologique, puis utilisent ce modèle pour extrapoler l'avenir de la série chronologique.
Néanmoins, dans la plupart des applications, vous pouvez avoir de nombreuses séries chronologiques semblables dans un ensemble d'unités transversales (par exemple, l'exigence de différents produits, la charge des serveurs, les demandes de pages web, etc.). Pour ce type d'application, il peut être bénéfique d'entraîner un seul modèle commun pour toutes les séries chronologiques. DeepAR observe cette approche. Lorsque votre jeu de données contient des centaines de séries chronologiques connexes, DeepAR surpasse les méthodes ARIMA et ETS standard. Vous pouvez également utiliser le modèle entraîné afin de générer des prévisions pour les nouvelles séries chronologiques similaires à celles sur lesquelles l'entraînement a eu lieu.
L'entrée d'entraînement pour l'algorithme DeepAR est constituée d'une ou de plusieurs séries chronologiques target générées par le même processus ou par des processus similaires. Sur la base de cet ensemble de données d'entrée, l'algorithme forme un modèle qui en apprend une approximation process/processes et l'utilise pour prédire l'évolution de la série chronologique cible. Chaque série temporelle cible peut éventuellement être associée à un vecteur de fonctions de catégorie statiques (indépendantes du temps) fourni par le champ cat et à un vecteur de séries temporelles dynamiques (dépendantes du temps) fourni par le champ dynamic_feat. SageMaker L'IA entraîne le modèle DeePar en échantillonnant de manière aléatoire des exemples d'entraînement à partir de chaque série chronologique cible de l'ensemble de données d'entraînement. Chaque exemple d'entraînement se compose d'une paire de fenêtres de contexte et de prédiction adjacentes avec des longueurs prédéfinies fixes. Utilisez l'hyperparamètre context_length pour contrôler jusqu'où peut remonter le réseau dans le passé. Utilisez l'hyperparamètre prediction_length pour contrôler jusqu'où peuvent porter les prédictions futures. Pour de plus amples informations, veuillez consulter Fonctionnement de l'algorithme DeepAR.
Rubriques
Input/Output Interface pour l'algorithme DeePar
DeepAR prend en charge deux canaux de données. Le canal train obligatoire décrit le jeu de données d'entraînement. Le canal test facultatif décrit un jeu de données que l'algorithme utilise afin d'évaluer la précision du modèle après l'entraînement. Vous pouvez fournir des jeux de données d'entraînement et de test au format JSON Lines
Lorsque vous spécifiez les chemins d'accès aux données d'entraînement et de test, vous pouvez spécifier un fichier ou un répertoire unique qui contient plusieurs fichiers, qui peuvent être stockés dans les sous-répertoires. Si vous spécifiez un répertoire, DeepAR utilise tous les fichiers du répertoire comme entrées pour le canal correspondant, à l'exception de ceux qui commencent par un point (.) ou qui sont nommés _SUCCESS. Vous pouvez ainsi utiliser directement les dossiers de sortie générés par les tâches Spark comme canaux d'entrée pour vos tâches d'entraînement DeepAR.
Par défaut, le modèle DeepAR détermine le format d'entrée à partir de l'extension du fichier (.json, .json.gz ou .parquet) dans le chemin d'entrée spécifié. Si le chemin d'accès ne se termine pas par l'une de ces extensions, vous devez spécifier le format explicitement dans le kit SDK Python. Utilisez le paramètre content_type de la classe s3_input
Les enregistrements dans vos fichiers d'entrée doivent contenir les champs suivants :
-
startUne chaîne au formatYYYY-MM-DD HH:MM:SS. L'horodatage de début ne peut pas contenir d'informations sur le fuseau horaire. -
target—Un ensemble de valeurs à virgule flottante ou de nombres entiers qui représentent les séries temporelles. Vous pouvez encoder les valeurs manquantes comme des littérauxnull, sous la forme de chaînes"NaN"dans JSON ou encore sous la forme de valeurs à virgule flottantenandans Parquet. -
dynamic_feat(facultatif)—Tableau de tableaux de valeurs à virgule flottante ou de nombres entiers qui représente le vecteur de séries temporelles de fonctions personnalisées (fonctions dynamiques). Si vous définissez ce champ, tous les enregistrements doivent avoir le même nombre de tableaux internes (le même nombre de séries chronologiques de caractéristiques). En outre, chaque tableau interne doit avoir la même longueur que la valeurtargetassociée plusprediction_length. Les valeurs manquantes ne sont pas prises en charge dans les caractéristiques. Par exemple, si la série chronologique cible représente la demande de différents produits,dynamic_featpeut être associé à une série chronologique booléenne qui indique si une promotion a été appliquée (1) pour le produit ou non (0) :{"start": ..., "target": [1, 5, 10, 2], "dynamic_feat": [[0, 1, 1, 0]]} -
cat(facultatif)—Tableau des fonctions catégorielles qui peuvent être utilisées pour encoder les groupes auxquels appartient l'enregistrement. Les caractéristiques catégorielles doivent être encodées sous la forme d'une séquence basée sur 0 de nombres entiers positifs. Par exemple, le domaine catégoriel {R, G, B} peut être encodé sous la forme {0, 1, 2}. Toutes les valeurs issues de chaque domaine catégoriel doivent être représentées dans le jeu de données d'entraînement. En effet, l'algorithme DeepAR peut établir ses prévisions uniquement pour les catégories qui ont été observées au cours de l'entraînement. En outre, chaque caractéristique catégorielle est intégrée dans un espace dimensionnel inférieur dont la dimensionnalité est contrôlée par l'hyperparamètreembedding_dimension. Pour de plus amples informations, veuillez consulter Hyperparamètres DeepAR.
Si vous utilisez un fichier JSON, il doit être au format JSON Lines
{"start": "2009-11-01 00:00:00", "target": [4.3, "NaN", 5.1, ...], "cat": [0, 1], "dynamic_feat": [[1.1, 1.2, 0.5, ...]]} {"start": "2012-01-30 00:00:00", "target": [1.0, -5.0, ...], "cat": [2, 3], "dynamic_feat": [[1.1, 2.05, ...]]} {"start": "1999-01-30 00:00:00", "target": [2.0, 1.0], "cat": [1, 4], "dynamic_feat": [[1.3, 0.4]]}
Dans cet exemple, chaque série chronologique possède deux caractéristiques catégorielles associées et une caractéristique de série chronologique.
Pour Parquet, vous utilisez les trois mêmes champs en tant que colonnes. En outre, "start" peut être le type datetime. Vous pouvez compresser les fichiers Parquet à l'aide de gzip (gzip) ou de la bibliothèque de compression Snappy (snappy).
Si l'algorithme est entraîné sans champs cat et dynamic_feat, il apprend un modèle « global », qui est un modèle indépendant de l'identité spécifique de la série chronologique cible au moment de l'inférence et est déterminé uniquement sur sa forme.
Si le modèle est conditionné sur les données des fonctions dynamic_feat et cat fournies pour chaque série chronologique, la prédiction sera probablement influencée par la nature de la série chronologique avec les fonctions cat correspondantes. Par exemple, si la série chronologique target représente la demande de vêtements, vous pouvez associer un vecteur bidimensionnel cat qui encode le type de vêtement (par exemple, 0 = chaussures, 1 = robes) dans le premier composant et la couleur du vêtement (par exemple, 0 = rouge, 1 = bleu) dans le deuxième composant. Un exemple d'entrée se présente comme suit :
{ "start": ..., "target": ..., "cat": [0, 0], ... } # red shoes { "start": ..., "target": ..., "cat": [1, 1], ... } # blue dress
Au moment de l'inférence, vous pouvez demander des prédictions pour des cibles avec des valeurs cat qui sont des combinaisons des valeurs cat observées dans les données d'entraînement, par exemple :
{ "start": ..., "target": ..., "cat": [0, 1], ... } # blue shoes { "start": ..., "target": ..., "cat": [1, 0], ... } # red dress
Les consignes suivantes s'appliquent aux données d'entraînement :
-
L'heure de début et la durée de la série chronologique peuvent varier. Par exemple, en marketing, les produits entrent souvent dans un catalogue de vente au détail à des dates différentes, de sorte que leurs dates de début diffèrent. Mais toutes les séries doivent avoir la même fréquence, le même nombre de fonctions de catégorie et le même nombre de fonctions dynamiques.
-
Réorganisez le fichier d'entraînement par rapport à la position de la série chronologique dans le fichier. En d'autres termes, les séries chronologiques doivent se produire dans un ordre aléatoire dans le fichier.
-
Veillez à définir correctement le champ
start. L'algorithme utilise l'horodatagestartpour obtenir les caractéristiques internes. -
Si vous utilisez des caractéristiques catégorielles (
cat), toutes les séries chronologiques doivent avoir le même nombre de caractéristiques catégorielles. Si le jeu de données contient le champcat, l'algorithme l'utilise et extrait la cardinalité des groupes à partir du jeu de données. Par défaut,cardinalityest"auto". Si le jeu de données contient le champcat, mais que vous ne souhaitez pas l'utiliser, vous pouvez le désactiver en définissantcardinalitysur"". Si un modèle a été entraîné à l'aide d'une variablecat, vous devez l'inclure pour l'inférence. -
Si votre jeu de données contient le champ
dynamic_feat, l'algorithme l'utilise automatiquement. Toutes les séries chronologiques doivent contenir le même nombre de séries chronologiques de caractéristiques. Les points temporels dans chaque série chronologique de caractéristiques correspondent un-à-un aux points temporels dans la cible. En outre, l'entrée dans le champdynamic_featdoit avoir la même longueur quetarget. Si le jeu de données contient le champdynamic_feat, mais que vous ne souhaitez pas l'utiliser, vous pouvez le désactiver en définissantnum_dynamic_featsur"". Si le modèle a été entraîné avec le champdynamic_feat, vous devez fournir ce champ pour l'inférence. En outre, chaque caractéristique doit avoir la longueur de la cible fournie plus la longueurprediction_length. En d'autres termes, vous devez préciser la valeur de la caractéristique à l'avenir.
Si vous spécifiez des données de canal de test facultatif, l'algorithme DeepAR évalue le modèle entraîné avec différentes métriques de précision. Il calcule l'erreur quadratique moyenne (RMSE, Root Mean Square Error) sur les données de test comme suit :
![Formule RMSE : Sqrt (1/nT(Sum [i, t] (y-hat (i, t) -y (i, t)) ^2)).](images/deepar-1.png)
yi,t correspond à la valeur réelle de la série temporelle i à l'instant t et ŷi,t correspond à la prédiction moyenne. La somme porte sur la totalité des n séries chronologiques de l'ensemble de test et sur les derniers points temporels T pour chaque série chronologique, où Τ correspond à la période de prévision. Vous spécifiez la longueur de la période de prévision en définissant l'hyperparamètre prediction_length. Pour de plus amples informations, veuillez consulter Hyperparamètres DeepAR.
En outre, l'algorithme évalue la précision de la distribution de prévision d'après la perte de quantile pondérée. Pour un quantile de la plage [0, 1], la perte de quantile pondérée est définie comme suit :
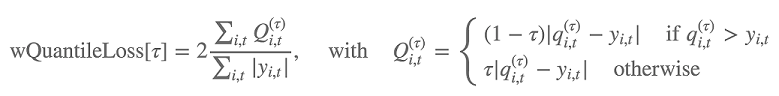
qi,t(τ) est le quantile τ de la distribution que le modèle prévoit. Afin de spécifier les quantiles pour lesquels calculer la perte, définissez l'hyperparamètre test_quantiles. En outre, la moyenne des pertes de quantiles prescrites est signalée dans les journaux d'entraînement. Pour plus d'informations, consultez Hyperparamètres DeepAR.
Pour l'inférence, DeepAR accepte le format JSON et les champs suivants :
-
"instances", qui comprend une ou plusieurs séries chronologiques au format JSON Lines -
Un nom de
"configuration", qui inclut les paramètres pour la génération de la prévision
Pour de plus amples informations, veuillez consulter Formats d'inférence DeepAR.
Bonnes pratiques relatives à l'utilisation de l'algorithme DeepAR
Lorsque vous préparez vos données en séries chronologiques, suivez ces bonnes pratiques afin d'obtenir les meilleurs résultats :
-
Sauf lorsque vous fractionnez votre jeu de données à des fins d'entraînement et de tests, vous devez toujours fournir l'ensemble des séries chronologiques pour l'entraînement et les tests, ainsi que lorsque vous appelez le modèle pour l'inférence. Quelle que soit la façon dont vous définissez
context_length, ne fractionnez pas les séries chronologiques et n'en fournissez pas uniquement une partie. Le modèle utilise les points de données en amont de la valeur définie danscontext_lengthpour la caractéristique des valeurs décalées. -
Lors du réglage d'un modèle DeepAR, vous pouvez fractionner le jeu de données afin de créer un jeu de données d'entraînement et un autre de test. Lors d'une évaluation type, vous devez tester le modèle pour les mêmes séries chronologiques que celles utilisées pour l'entraînement, mais à des points temporels
prediction_lengthfuturs situés immédiatement après le dernier point temporel visible pendant l'entraînement. Vous pouvez créer des jeux de données d'entraînement et de test qui satisfont à ce critère en utilisant l'intégralité du jeu de données (la longueur totale de toutes les séries chronologiques disponibles) en tant qu'ensemble de test et en supprimant les derniers pointsprediction_lengthde chaque série chronologique pour l'entraînement. Pendant l'entraînement, le modèle ne détecte pas les valeurs cibles aux points temporels pour lesquels il est évalué pendant le test. Durant le test, l'algorithme retient les derniers pointsprediction_lengthde chaque série chronologique de l'ensemble de test, puis génère une prédiction. Ensuite, il compare la prévision avec les valeurs retenues. Vous pouvez créer des évaluations plus complexes en répétant plusieurs fois les séries chronologiques dans l'ensemble de test, mais en les fractionnant à différents points de terminaison. Avec cette approche, la moyenne des métriques de précision est calculée d'après plusieurs prévisions à différents points temporels. Pour de plus amples informations, veuillez consulter Réglage d'un modèle DeepAR. -
Pour le paramètre
prediction_length, évitez d'utiliser des valeurs très élevées (>400), car elles ralentissent le modèle et le rendent moins précis. Si vous souhaitez procéder à des prédictions plus lointaines, envisagez de regrouper vos données à une fréquence plus basse. Par exemple, utilisez5minplutôt que1min. -
Puisque des décalages sont utilisés, un modèle peut remonter dans les séries chronologiques au-delà de la valeur indiquée pour
context_length. Par conséquent, vous n'avez pas besoin de définir ce paramètre sur une valeur élevée. Il est recommandé de commencer par la valeur que vous avez définie pourprediction_length. -
Il est recommandé d'entraîner un modèle DeepAR sur toutes les séries chronologiques disponibles. Un modèle DeepAR entraîné sur une seule série chronologique peut fonctionner correctement. Toutefois, les algorithmes de prévision standard, tels que ARIMA ou ETS, peuvent fournir des résultats plus précis. Lorsque votre jeu de données contient des centaines de séries chronologiques connexes, l'algorithme DeepAR commence à surpasser les méthodes standard. Actuellement, DeepAR exige qu'il y ait au moins 300 observations disponibles sur l'ensemble des séries chronologiques d'entraînement.
Recommandations pour l'instance EC2 relatives à l'algorithme DeepAR
Vous pouvez entraîner DeepAR sur une ou plusieurs instances d'UC et de processeur graphique (GPU). Nous vous recommandons de commencer par une seule instance d'UC (par exemple, ml.c4.2xlarge ou ml.c4.4xlarge), puis de passer à des instances GPU et à plusieurs instances d'UC uniquement lorsque cela est nécessaire. Le recours à plusieurs GPU et à plusieurs instances d'UC améliore le débit uniquement pour les plus grands modèles (avec plusieurs cellules par couche et plusieurs couches) et pour les tailles de mini-lots importantes (par exemple, taille supérieure à 512).
Pour l'inférence, DeepAR prend en charge uniquement les instances d'UC.
Le fait de spécifier des valeurs context_length, prediction_length, num_cells, num_layers ou mini_batch_size élevées peut générer des modèles trop volumineux pour les petites instances. Dans ce cas, utilisez un type d'instance plus grand ou réduisez les valeurs de ces paramètres. Ce problème survient également fréquemment lors de l'exécution de tâches de réglage d'hyperparamètre. Dans ce cas, utilisez un type d'instance suffisamment volumineux pour la tâche de réglage des modèles et envisagez de limiter les valeurs supérieures des paramètres critiques afin d'éviter l'échec des tâches.
Exemples de blocs-notes DeepAR
Pour un exemple de bloc-notes expliquant comment préparer un ensemble de données chronologiques pour entraîner l'algorithme SageMaker AI DeePar et comment déployer le modèle entraîné pour effectuer des inférences, consultez la démo de DeePar sur le jeu de données sur l'électricité, qui illustre les fonctionnalités avancées de DeePar sur un ensemble de données
Pour plus d'informations sur l'algorithme Amazon SageMaker AI DeePar, consultez les articles de blog suivants :
