Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Catégoriser le texte à l'aide de la classification de texte () Multi-label
Pour classer les articles et le texte en plusieurs catégories prédéfinies, utilisez le type de tâche de classification de texte à plusieurs étiquettes. Par exemple, vous pouvez utiliser ce type de tâche pour identifier plusieurs émotions véhiculées dans un texte. Les sections suivantes fournissent des informations sur la création d’une tâche de classification de texte à plusieurs étiquettes à partir de la console et de l’API.
Lorsque vous travaillez sur une tâche de classification de texte à plusieurs étiquettes, les collaborateurs doivent choisir toutes les étiquettes applicables, et doivent en choisir au moins une. Lorsque vous créez une tâche à l’aide de ce type de tâche, vous pouvez fournir jusqu’à 50 catégories d’étiquettes.
Amazon SageMaker Ground Truth ne fournit pas de catégorie « aucun » lorsqu'aucune des étiquettes ne s'applique. Pour fournir cette option aux collaborateurs, incluez une étiquette similaire à « aucune » ou « autre » lorsque vous créez une tâche de classification de texte à plusieurs étiquettes.
Pour imposer aux collaborateurs de choisir une seule étiquette pour chaque sélection de document ou de texte, utilisez le type de tâche Catégorisation de texte à l’aide de la classification de texte (à étiquette unique).
Important
Si vous créez manuellement un fichier manifeste source, utilisez "source" pour identifier le texte à étiqueter. Pour de plus amples informations, veuillez consulter Données d’entrée.
Création d'une tâche d'étiquetage de classification de Multi-Label texte (console)
Vous pouvez suivre les instructions Création d’une tâche d’étiquetage (Console) pour apprendre à créer une tâche d'étiquetage de classification de texte à étiquettes multiples dans la console Amazon SageMaker AI. À l'étape 10, choisissez Texte dans le menu déroulant des catégories de tâches, puis sélectionnez Classification du texte (Multi-label) comme type de tâche.
Ground Truth fournit une interface utilisateur employé similaire à la suivante pour l’étiquetage des tâches. Lorsque vous créez la tâche d’étiquetage avec la console, vous spécifiez des instructions pour aider les collaborateurs à terminer la tâche et des étiquettes parmi lesquelles ceux-ci peuvent faire leur choix.
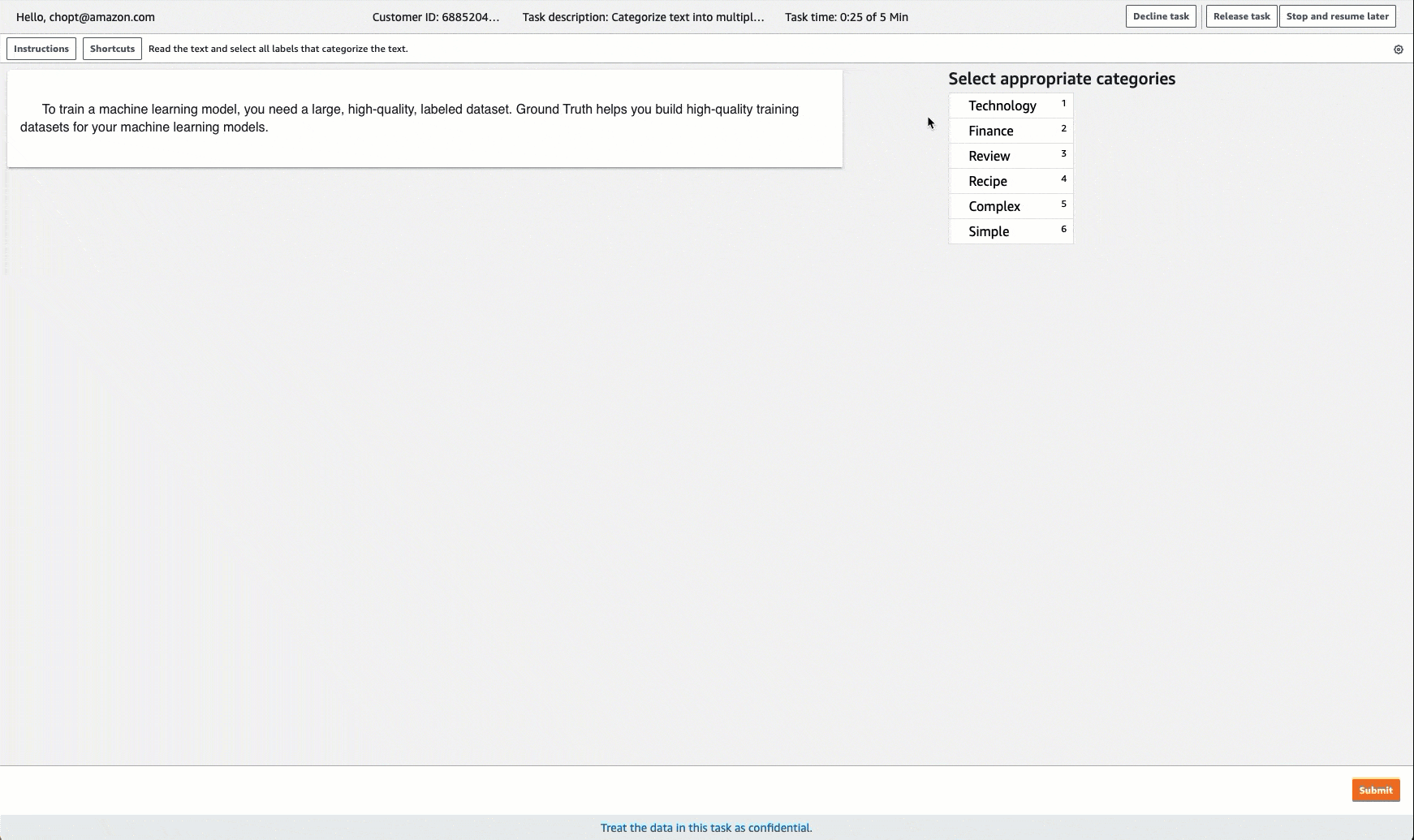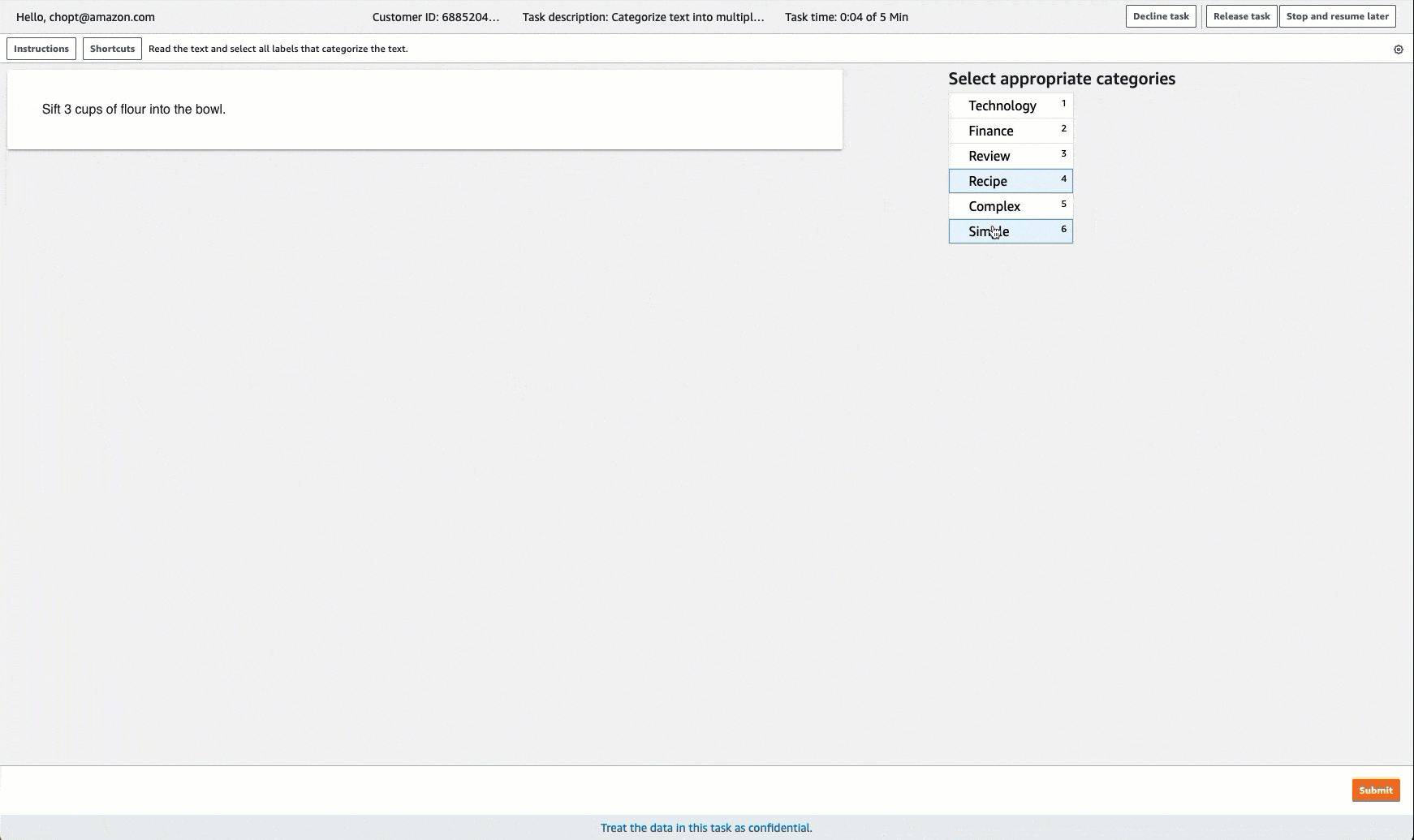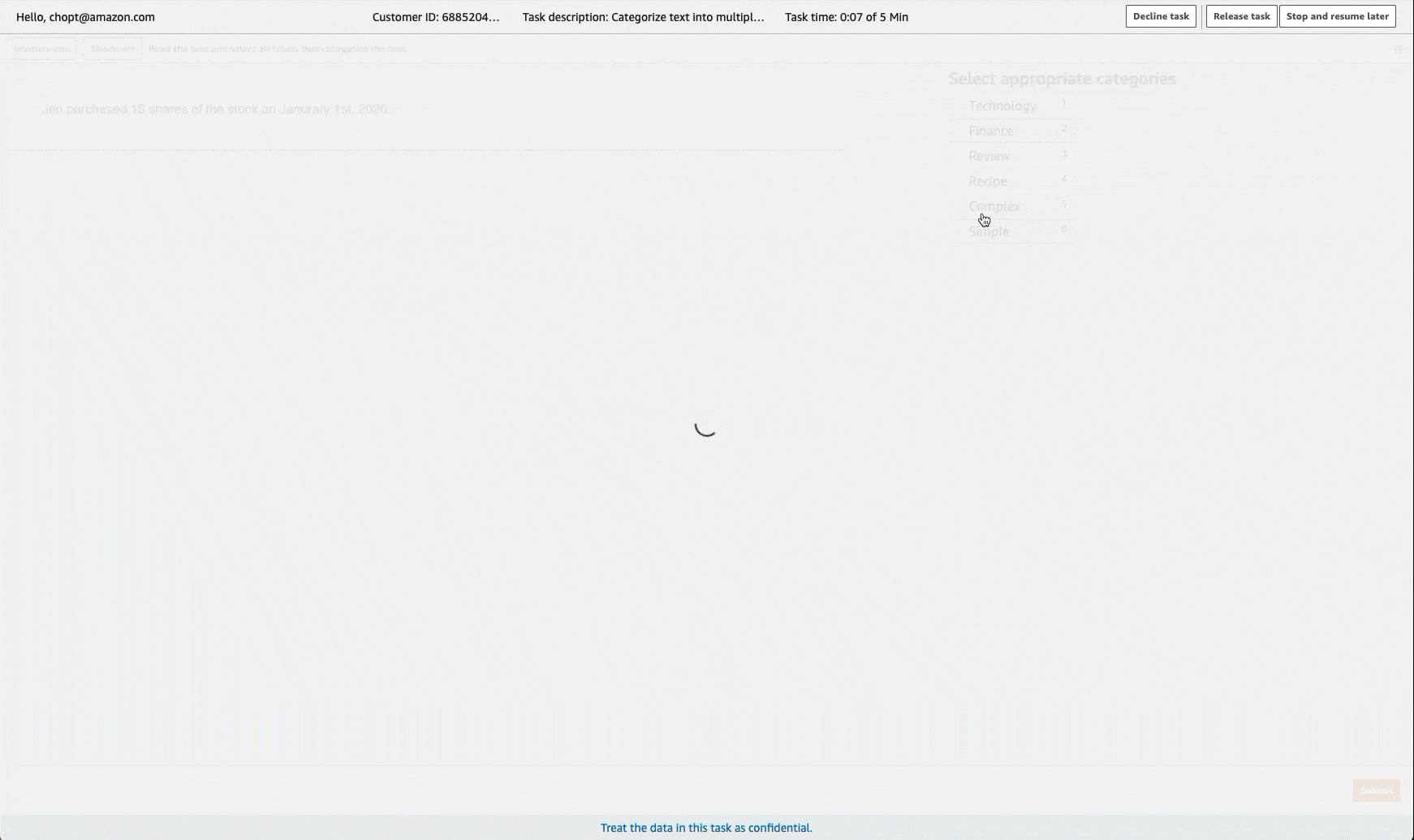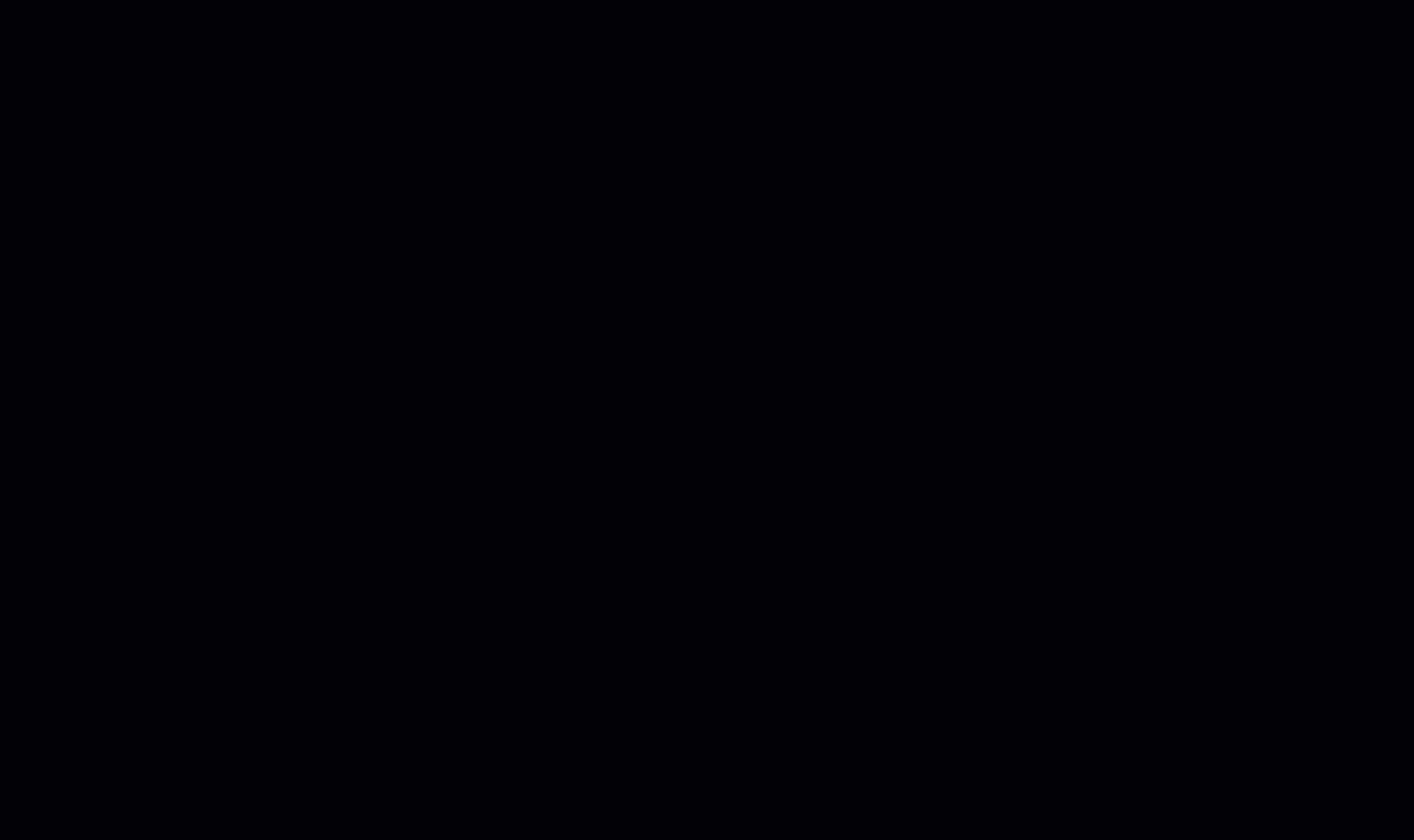
Création d'un Job d'étiquetage de classification de Multi-Label texte (API)
Pour créer une tâche d'étiquetage de classification de texte à étiquettes multiples, utilisez l'opération SageMaker CreateLabelingJob API. Cette API définit cette opération pour tous les AWS SDK. Pour afficher la liste des kits SDK spécifiques à la langue pris en charge pour cette opération, consultez la section Voir aussi de CreateLabelingJob.
Suivez les instructions présentées dans Création d’une tâche d’étiquetage (API) et procédez comme suit pour configurer votre demande :
-
Pre-annotation Les fonctions Lambda pour ce type de tâche se terminent par.
PRE-TextMultiClassMultiLabelPour trouver l'ARN Lambda préalable à l'annotation pour votre région PreHumanTaskLambdaArn, consultez. -
Annotation-consolidation Les fonctions Lambda pour ce type de tâche se terminent par.
ACS-TextMultiClassMultiLabelPour trouver l'ARN Lambda de consolidation des annotations pour votre région, consultez. AnnotationConsolidationLambdaArn
Voici un exemple de requête du kit SDK AWS Python (Boto3)
response = client.create_labeling_job( LabelingJobName='example-multi-label-text-classification-labeling-job, LabelAttributeName='label', InputConfig={ 'DataSource': { 'S3DataSource': { 'ManifestS3Uri':'s3://bucket/path/manifest-with-input-data.json'} }, 'DataAttributes': { 'ContentClassifiers': ['FreeOfPersonallyIdentifiableInformation'|'FreeOfAdultContent', ] } }, OutputConfig={ 'S3OutputPath':'s3://bucket/path/file-to-store-output-data', 'KmsKeyId':'string'}, RoleArn='arn:aws:iam::*:role/*, LabelCategoryConfigS3Uri='s3://bucket/path/label-categories.json', StoppingConditions={ 'MaxHumanLabeledObjectCount':123, 'MaxPercentageOfInputDatasetLabeled':123}, HumanTaskConfig={ 'WorkteamArn':'arn:aws:sagemaker:region:*:workteam/private-crowd/*', 'UiConfig': { 'UiTemplateS3Uri':'s3://bucket/path/custom-worker-task-template.html'}, 'PreHumanTaskLambdaArn': 'arn:aws:lambda::function:PRE-TextMultiClassMultiLabel, 'TaskKeywords': ['Text Classification', ], 'TaskTitle':'Multi-label text classification task', 'TaskDescription':'Select all labels that apply to the text shown', 'NumberOfHumanWorkersPerDataObject':123, 'TaskTimeLimitInSeconds':123, 'TaskAvailabilityLifetimeInSeconds':123, 'MaxConcurrentTaskCount':123, 'AnnotationConsolidationConfig': { 'AnnotationConsolidationLambdaArn': 'arn:aws:lambda:us-east-1:432418664414:function:ACS-TextMultiClassMultiLabel' }, Tags=[ { 'Key':'string', 'Value':'string'}, ] )
Création d'un modèle pour la classification de Multi-label texte
Si vous créez une tâche d’étiquetage à l’aide de l’API, vous devez fournir un modèle de tâche d’employé dans UiTemplateS3Uri. Copiez et modifiez le modèle suivant. Modifiez uniquement short-instructions, full-instructions, et header.
Téléchargez ce modèle vers S3 et fournissez l’URI S3 pour ce fichier dans UiTemplateS3Uri.
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script> <crowd-form> <crowd-classifier-multi-select name="crowd-classifier-multi-select" categories="{{ task.input.labels | to_json | escape }}" header="Please identify all classes in the below text" > <classification-target style="white-space: pre-wrap"> {{ task.input.taskObject }} </classification-target> <full-instructions header="Classifier instructions"> <ol><li><strong>Read</strong> the text carefully.</li> <li><strong>Read</strong> the examples to understand more about the options.</li> <li><strong>Choose</strong> the appropriate labels that best suit the text.</li></ol> </full-instructions> <short-instructions> <p>Enter description of the labels that workers have to choose from</p> <p><br></p> <p><br></p><p>Add examples to help workers understand the label</p> <p><br></p><p><br></p><p><br></p><p><br></p><p><br></p> </short-instructions> </crowd-classifier-multi-select> </crowd-form>
Pour savoir comment créer un modèle personnalisé, consultez Flux de travail d’étiquetage personnalisés.
Multi-label Données de sortie de classification de texte
Une fois que vous avez créé une tâche d’étiquetage de classification de texte à plusieurs étiquettes, vos données de sortie seront situées dans le compartiment Amazon S3 spécifié dans le paramètre S3OutputPath lorsque vous utilisez l’API ou dans le champ Output dataset location (Emplacement du jeu de données de sortie) de la section Job overview (Présentation de la tâche) de la console.
Pour en savoir plus sur le fichier manifeste de sortie généré par Ground Truth et sur la structure de fichier que ce dernier utilise pour stocker vos données de sortie, consultez Étiquetage des données de sortie des tâches.
Pour accéder à un exemple de fichiers manifestes en sortie pour la tâche d’étiquetage de classification de texte à plusieurs étiquettes, consultez Multi-label résultat du travail de classification.
