Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Qu'est-ce que Step Functions ?
Gestion de l'état et transformation des données
Découvrez comment transmettre des données entre états avec des variables et transformer des données avec JSONata.
Avec AWS Step Functions, vous pouvez créer des flux de travail, également appelés flux de travailMachines d'état, pour créer des applications distribuées, automatiser des processus, orchestrer des microservices et créer des pipelines de données et d'apprentissage automatique.
Step Functions est basé sur des machines à états et des tâches. Dans Step Functions, les machines à états sont appelées flux de travail, qui sont une série d'étapes pilotées par des événements. Chaque étape d'un flux de travail est appelée état. Par exemple, un état de tâche représente une unité de travail exécutée par un autre AWS service, comme l'appel d'un autre service Service AWS ou d'une API. Les instances de flux de travail exécutant des tâches sont appelées exécutions dans Step Functions.
Le travail dans les tâches de votre machine à états peut également être effectué à l'aide de travailleurs Activités qui existent en dehors de Step Functions.

Dans la console Step Functions, vous pouvez visualiser, modifier et déboguer le flux de travail de votre application. Vous pouvez examiner l'état de chaque étape de votre flux de travail pour vous assurer que votre application s'exécute dans l'ordre et comme prévu.
Selon votre cas d'utilisation, vous pouvez demander à Step Functions d'appeler AWS des services, tels que Lambda, pour effectuer des tâches. Vous pouvez utiliser les AWS services de contrôle Step Functions, par exemple AWS Glue pour créer des flux de travail d'extraction, de transformation et de chargement. Vous pouvez également créer des flux de travail automatisés à long terme pour les applications qui nécessitent une interaction humaine.
Pour une liste complète des AWS régions dans lesquelles Step Functions est disponible, consultez le tableau des AWS
régions
Apprenez à utiliser Step Functions
Commencez par le Didacticiel de démarrage contenu de ce guide. Pour les sujets avancés et les cas d'utilisation, consultez les modules de The Step Functions Workshop
Types de flux de travail standard et express
Step Functions propose deux types de flux de travail :
-
Les flux de travail standard sont idéaux pour les flux de travail auditables de longue durée, car ils affichent l'historique d'exécution et le débogage visuel.
Les flux de travail standard ne sont exécutés qu'une seule fois et peuvent durer jusqu'à un an. Cela signifie que chaque étape d'un flux de travail standard ne sera exécutée qu'une seule fois.
-
Les flux de travail Express sont idéaux pour les high-event-rate charges de travail, telles que le traitement des données en streaming et l'ingestion de données IoT.
Les at-least-onceflux de travail Express s'exécutent et peuvent s'exécuter pendant cinq minutes au maximum. Cela signifie qu'une ou plusieurs étapes d'un flux de travail express peuvent potentiellement être exécutées plusieurs fois, chaque étape du flux de travail étant exécutée au moins une fois.
| Flux de travail standard | Flux de travail express |
|---|---|
| Taux d'exécution de 2 000 par seconde | Taux d'exécution de 100 000 par seconde |
| Taux de transition entre États de 4 000 par seconde | Taux de transition entre États presque illimité |
| Tarification en fonction de la transition entre États | Tarification en fonction du nombre et de la durée des exécutions |
| Afficher l'historique d'exécution et le débogage visuel | Afficher l'historique d'exécution et le débogage visuel en fonction du niveau de journalisation |
| Voir l'historique des exécutions dans Step Functions |
Envoyer l'historique des exécutions à CloudWatch |
| Support des intégrations avec tous les services. Support d'intégrations optimisées avec certains services. |
Support des intégrations avec tous les services. |
| Modèle de réponse aux demandes de support pour tous les services Support : modèles Run a Job et/ou Wait for Callback dans des services spécifiques (voir la section suivante pour plus de détails) |
Modèle de réponse aux demandes de support pour tous les services |
Pour plus d'informations sur la tarification de Step Functions et le choix du type de flux de travail, consultez les pages suivantes :
Intégration avec d’autres services
Step Functions s'intègre à de nombreux AWS services. Pour appeler d'autres AWS services, vous pouvez utiliser deux types d'intégration :
-
AWS Les intégrations du SDK permettent d'appeler n'importe quel AWS service directement depuis votre machine d'état, vous donnant ainsi accès à des milliers d'actions d'API.
-
Les intégrations optimisées fournissent des options personnalisées pour utiliser ces services dans vos machines d'état.
Pour combiner Step Functions avec d'autres services, il existe trois modèles d'intégration de services :
-
Réponse à la demande (par défaut)
Appelez un service et laissez Step Functions passer à l'état suivant après avoir reçu une réponse HTTP.
-
Appelez un service et demandez à Step Functions d'attendre qu'une tâche soit terminée.
-
Attendez un rappel avec un jeton de tâche (. waitForTaskJeton)
Appelez un service avec un jeton de tâche et demandez à Step Functions d'attendre que le jeton de tâche revienne avec un rappel.
Les flux de travail standard et les flux de travail express prennent en charge les mêmes intégrations, mais pas les mêmes modèles d'intégration.
-
Les flux de travail standard prennent en charge les intégrations Request Response. Certains services prennent en charge Run a Job (.sync) ou Wait for Callback (. waitForTaskToken), et les deux dans certains cas. Consultez le tableau des intégrations optimisées ci-dessous pour plus de détails.
-
Express Workflows prend uniquement en charge les intégrations Request Response.
Pour vous aider à choisir entre les deux types, voirChoix du type de flux de travail dans Step Functions.
AWS Intégrations du SDK dans Step Functions
| Service intégré | Réponse à la requête | Exécuter un Job - .sync | Attendez le rappel -. waitForTaskJeton |
|---|---|---|---|
| Plus de deux cents services | Standard et Express | Non pris en charge | Standard |
Intégrations optimisées dans Step Functions
| Service intégré | Réponse à la requête | Exécuter un Job - .sync | Attendez le rappel -. waitForTaskJeton |
|---|---|---|---|
| Amazon API Gateway | Standard et Express | Non pris en charge | Standard |
| Amazon Athena | Standard et Express | Standard | Non pris en charge |
| AWS Batch | Standard et Express | Standard | Non pris en charge |
| Amazon Bedrock | Standard et Express | Standard | Standard |
| AWS CodeBuild | Standard et Express | Standard | Non pris en charge |
| Amazon DynamoDB | Standard et Express | Non pris en charge | Non pris en charge |
| Amazon ECS/Fargate | Standard et Express | Standard | Standard |
| Amazon EKS | Standard et Express | Standard | Standard |
| Amazon EMR | Standard et Express | Standard | Non pris en charge |
| Amazon EMR on EKS | Standard et Express | Standard | Non pris en charge |
| Amazon EMR Serverless | Standard et Express | Standard | Non pris en charge |
| Amazon EventBridge | Standard et Express | Non pris en charge | Standard |
| AWS Glue | Standard et Express | Standard | Non pris en charge |
| AWS Glue DataBrew | Standard et Express | Standard | Non pris en charge |
| AWS Lambda | Standard et Express | Non pris en charge | Standard |
| AWS Elemental MediaConvert | Standard et Express | Standard | Non pris en charge |
| Amazon SageMaker AI | Standard et Express | Standard | Non pris en charge |
| Amazon SNS | Standard et Express | Non pris en charge | Standard |
| Amazon SQS | Standard et Express | Non pris en charge | Standard |
| AWS Step Functions | Standard et Express | Standard | Standard |
Exemples de cas d'utilisation pour les flux de travail
Step Functions gère les composants et la logique de votre application, ce qui vous permet d'écrire moins de code et de vous concentrer sur la création et la mise à jour rapides de votre application. L'image suivante montre six cas d'utilisation des flux de travail Step Functions.
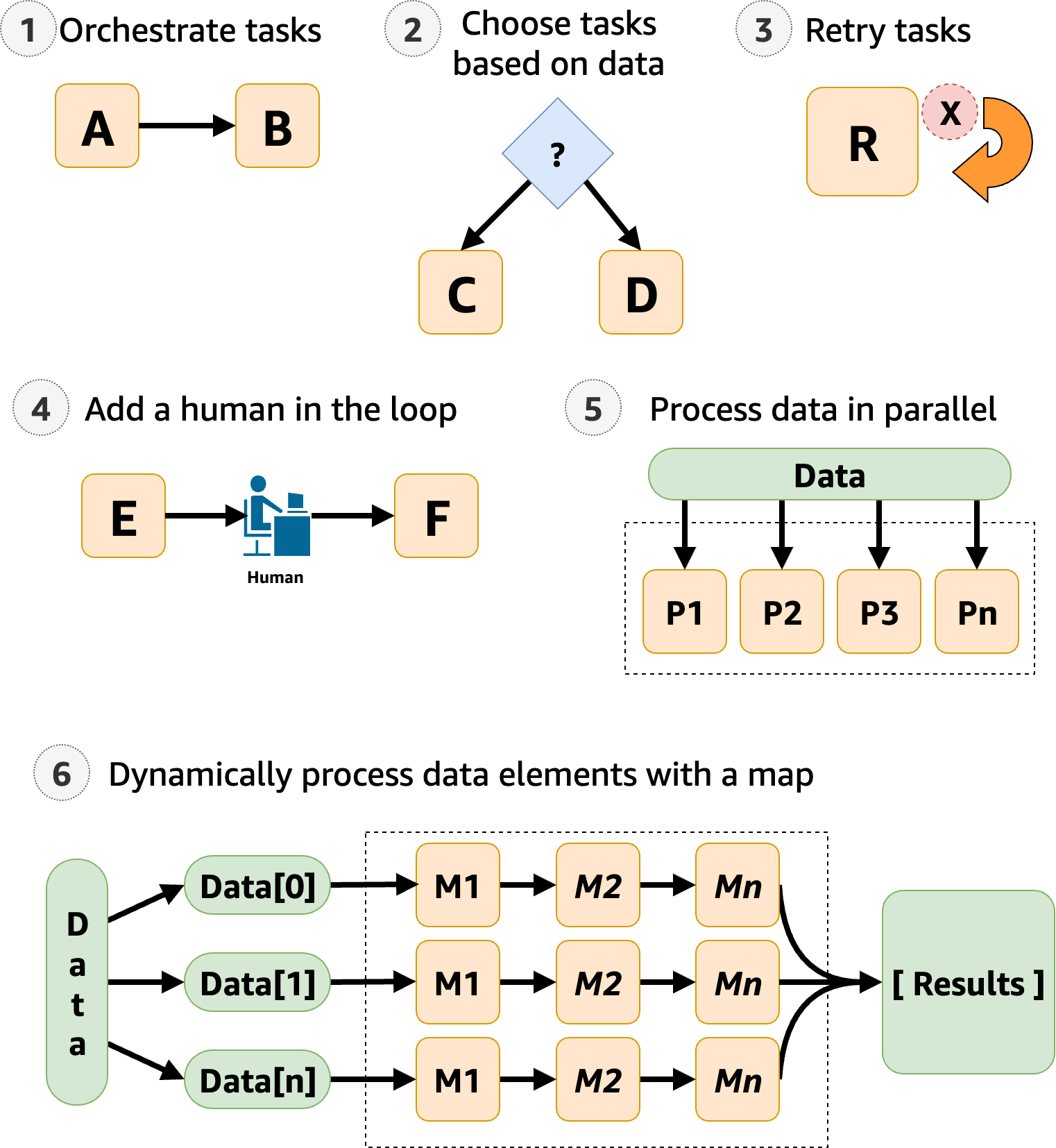
-
Orchestrer les tâches : vous pouvez créer des flux de travail qui orchestrent une série de tâches, ou d'étapes, dans un ordre spécifique. Par exemple, la tâche A peut être une fonction Lambda qui fournit des entrées pour une autre fonction Lambda dans la tâche B. La dernière étape de votre flux de travail fournit le résultat final.
-
Choisissez des tâches en fonction des données — À l'aide d'un
Choiceétat, Step Functions peut prendre des décisions en fonction des données saisies par l'état. Imaginons par exemple qu'un client demande une augmentation de sa limite de crédit. Si la demande dépasse la limite de crédit préapprouvée de votre client, vous pouvez demander à Step Functions d'envoyer la demande de votre client à un responsable pour approbation. Si la demande est inférieure à la limite de crédit préapprouvée par votre client, vous pouvez demander à Step Functions d'approuver automatiquement la demande. -
Gestion des erreurs (
Retry/Catch) — Vous pouvez réessayer les tâches qui ont échoué ou les récupérer et exécuter automatiquement des étapes alternatives.Par exemple, lorsqu'un client demande un nom d'utilisateur, le premier appel à votre service de validation échoue peut-être, de sorte que votre flux de travail peut réessayer la demande. Lorsque la deuxième demande aboutit, le flux de travail peut continuer.
Ou bien, si le client a demandé un nom d'utilisateur non valide ou indisponible, une
Catchdéclaration pourrait mener à une étape du flux de travail de Step Functions qui suggère un autre nom d'utilisateur.Pour des exemples de
RetryetCatch, voirGestion des erreurs dans les flux de travail Step Functions. -
Human in the loop — Step Functions peut inclure des étapes d'approbation humaine dans le flux de travail. Par exemple, imaginez qu'un client d'une banque tente d'envoyer des fonds à un ami. Avec un rappel et un jeton de tâche, vous pouvez demander à Step Functions d'attendre que l'ami du client confirme le transfert, puis Step Functions poursuivra le flux de travail pour informer le client de la banque que le transfert est terminé.
Pour obtenir un exemple, consultez Création d'un exemple de modèle de rappel avec Amazon SQS, Amazon SNS et Lambda.
-
Traiter les données par étapes parallèles — À l'aide d'un
Parallelétat, Step Functions peut traiter les données d'entrée par étapes parallèles. Par exemple, un client peut avoir besoin de convertir un fichier vidéo en plusieurs résolutions d'affichage afin que les spectateurs puissent regarder la vidéo sur plusieurs appareils. Votre flux de travail peut envoyer le fichier vidéo original à plusieurs fonctions Lambda ou utiliser l' AWS Elemental MediaConvert intégration optimisée pour traiter une vidéo dans plusieurs résolutions d'affichage en même temps. -
Traitement dynamique des éléments de données : à l'aide d'un
Mapétat, Step Functions peut exécuter un ensemble d'étapes de flux de travail sur chaque élément d'un ensemble de données. Les itérations s'exécutent en parallèle, ce qui permet de traiter rapidement un ensemble de données. Par exemple, lorsque votre client commande trente articles, votre système doit appliquer le même flux de travail pour préparer chaque article à la livraison. Une fois que tous les articles ont été rassemblés et emballés pour la livraison, l'étape suivante consiste peut-être à envoyer rapidement à votre client un e-mail de confirmation contenant des informations de suivi.Pour un exemple de modèle de démarrage, voirTraitez les données avec une carte.
