Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
REL10-BP01 Déploiement de la charge de travail sur plusieurs emplacements
Distribuez les données et les ressources de charge de travail sur plusieurs zones de disponibilité ou, si nécessaire, entre Régions AWS.
L’un des principes fondamentaux de la conception de services dans AWS est d’éviter les points de défaillance uniques, y compris l’infrastructure physique sous-jacente. AWS fournit des ressources et des services de cloud computing à l’échelle mondiale, sur plusieurs sites géographiques appelés régions. Chaque région est physiquement et logiquement indépendante et se compose de trois zones de disponibilité (AZ) ou plus. Les zones de disponibilité sont géographiquement proches les unes des autres, mais sont physiquement séparées et isolées. La répartition de vos charges de travail entre les zones de disponibilité et les régions vous permet de réduire le risque de menaces telles que les incendies, les inondations, les catastrophes météorologiques, les tremblements de terre et les erreurs humaines.
Créez une stratégie de localisation pour assurer une haute disponibilité adaptée à vos charges de travail.
Résultat escompté : les charges de travail de production sont réparties entre plusieurs zones de disponibilité (AZ) ou régions afin de garantir la tolérance aux pannes et la haute disponibilité.
Anti-modèles courants :
-
Votre charge de travail de production n’existe que dans une seule zone de disponibilité.
-
Vous mettez en œuvre une architecture multirégionale alors qu’une architecture multi-AZ répondrait aux exigences.
-
Vos déploiements ou vos données sont désynchronisés, ce qui entraîne une dérive de la configuration ou une sous-réplication des données.
-
Vous ne tenez pas compte des dépendances entre les composants de l’application si les exigences en matière de résilience et de multi-localisation diffèrent entre ces composants.
Avantages liés au respect de cette bonne pratique :
-
Votre charge de travail est plus résiliente face aux incidents, tels que les pannes d’alimentation, les défaillances de contrôle environnemental, les catastrophes naturelles, les pannes de service en amont ou les problèmes réseau affectant une zone de disponibilité ou une région entière.
-
Vous pouvez accéder à un inventaire plus large d’instances Amazon EC2 et réduire le risque d’exceptions InsufficientCapacityExceptions (ICE) lors du lancement de types d’instances EC2 spécifiques.
Niveau d’exposition au risque si cette bonne pratique n’est pas respectée : élevé
Directives d’implémentation
Déployez et gérez toutes les charges de travail de production dans au moins deux zones de disponibilité (AZ) d’une région.
Utilisation de plusieurs zones de disponibilité
Les zones de disponibilité sont des lieux d’hébergement de ressources qui sont physiquement séparés les uns des autres afin d’éviter les défaillances corrélées dues à des risques tels que les incendies, les inondations et les tornades. Chaque zone de disponibilité possède une infrastructure physique indépendante comprenant des connexions électriques, des sources d’alimentation de secours, des services mécaniques et une connectivité réseau. Cette disposition limite les défaillances d’un de ces composants à la seule zone de disponibilité affectée. Par exemple, si un incident à l’échelle de la zone de disponibilité rend les instances EC2 indisponibles dans la zone de disponibilité affectée, vos instances situées dans une autre zone de disponibilité restent disponibles.
Bien que physiquement séparées, les zones de disponibilité situées dans la même Région AWS sont suffisamment proches pour fournir une mise en réseau à haut débit et à faible latence (moins de dix millisecondes). Vous pouvez répliquer les données de manière synchrone entre les zones de disponibilité pour la plupart des charges de travail sans affecter de manière significative l’expérience utilisateur. Cela signifie que vous pouvez utiliser les zones de disponibilité d’une région dans une configuration active/active ou active/veille.
Tous les calculs associés à votre charge de travail doivent être répartis entre les différentes zones de disponibilité. Cela inclut les instances Amazon EC2
Vous devez également répliquer les données pour votre charge de travail et les rendre disponibles dans plusieurs zones de disponibilité. Certains services de données AWS gérés, tels qu’Amazon S3
Si vous utilisez un stockage autogéré, tel que les volumes Amazon Elastic Block Store (EBS)
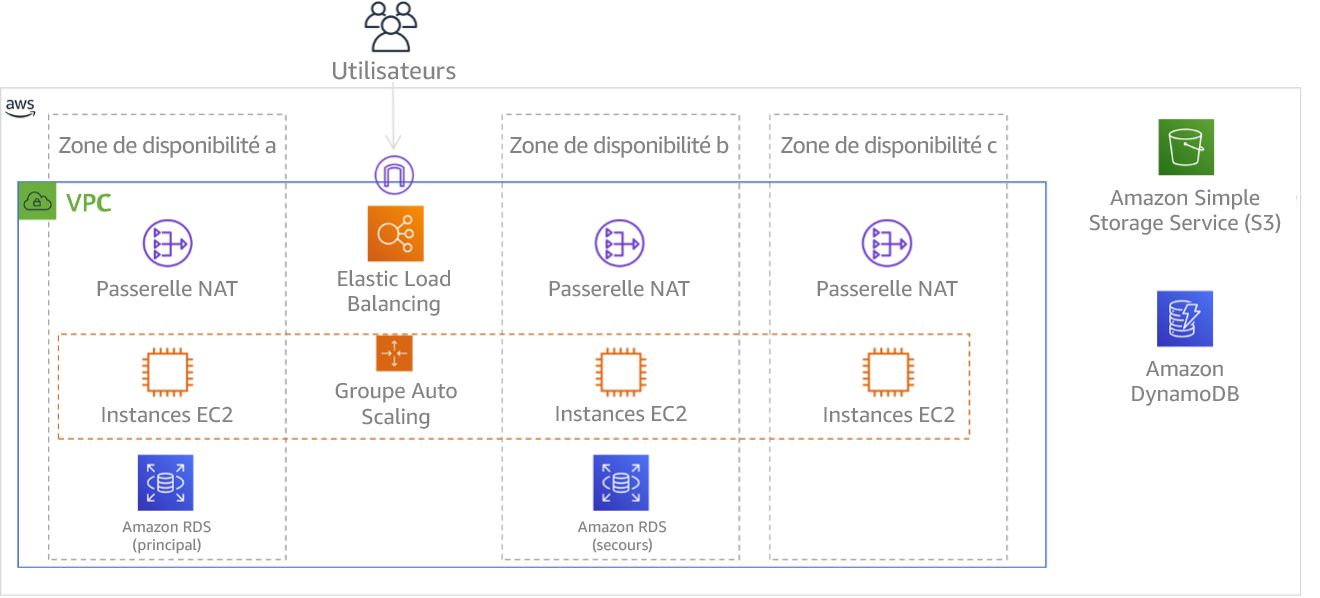
Figure 9 : Architecture multiniveau déployée sur trois zones de disponibilité. Notez qu’Amazon S3 et Amazon DynamoDB comportent toujours automatiquement plusieurs zones de disponibilités. L’ELB est également déployé dans les trois zones.
Utilisation de plusieurs Régions AWS
Si vos charges de travail nécessitent une résilience extrême (telles qu’une infrastructure critique, des applications liées à la santé ou des services répondant à des exigences strictes de disponibilité imposées par le client ou par le législateur), vous pouvez avoir besoin d’une disponibilité supérieure à ce qu’une Région AWS unique peut fournir. Dans ce cas, vous devez déployer et exploiter votre charge de travail sur au moins deux Régions AWS (en supposant que vos exigences en matière de résidence des données le permettent).
Les Régions AWS sont situées dans différentes régions géographiques du monde et sur plusieurs continents. Les Régions AWSprésentent une séparation physique et une isolation encore plus importantes que les zones de disponibilité. À quelques exceptions près, les services AWS profitent de cette conception pour fonctionner de manière totalement indépendante entre les différentes régions (on parle alors de services régionaux). Un service Région AWSal est conçu de manière à ce qu’une défaillance n’ait pas d’impact sur le service dans une autre région.
Lorsque vous gérez votre charge de travail dans plusieurs régions, vous devez prendre en compte des exigences supplémentaires. Les ressources des différentes régions étant séparées et indépendantes les unes des autres, vous devez dupliquer les composants de votre charge de travail dans chaque région. Cela inclut l’infrastructure de base, telle que les VPC, en plus des services de calcul et de données.
REMARQUE : Lorsque vous envisagez une conception multirégionale, vérifiez que votre charge de travail est capable de s’exécuter dans une région unique. Si vous créez des dépendances entre des régions de manière à ce qu’un composant d’une région repose sur des services ou des composants d’une autre région, vous pouvez augmenter le risque de défaillance et affaiblir considérablement votre position en matière de fiabilité.
Pour faciliter les déploiements multirégionaux et maintenir la cohérence, AWS CloudFormation StackSets peut répliquer l’ensemble de votre infrastructure AWS entre plusieurs régions. AWS CloudFormation
Vous devez également répliquer vos données dans chacune des régions que vous avez choisies. De nombreux services de données AWS gérés offrent une capacité de réplication interrégionale, notamment Amazon S3, Amazon DynamoDB, Amazon RDS, Amazon Aurora, Amazon Redshift, Amazon Elasticache, et Amazon EFS. Les tables globales Amazon DynamoDB
AWS permet également d’acheminer de façon très flexible le trafic de demandes vers vos déploiements régionaux. Par exemple, vous pouvez configurer vos enregistrements DNS à l’aide d’Amazon Route 53
Même si vous choisissez de ne pas opérer dans plusieurs régions pour des raisons de haute disponibilité, considérez plusieurs régions dans le cadre de votre stratégie de reprise après sinistre (DR). Si possible, répliquez les composants et les données de l’infrastructure de votre charge de travail dans une configuration de secours à chaud ou d’environnement en veille dans une région secondaire. Dans cette conception, vous répliquez l’infrastructure de base de la région principale, telle que les VPC, les groupes Auto Scaling, les orchestrateurs de conteneurs et d’autres composants, mais vous configurez les composants de taille variable dans la région de secours (tels que le nombre d’instances EC2 et de réplicas de base de données) de manière à ce qu’ils aient une taille minimale exploitable. Vous organisez également une réplication continue des données de la région principale vers la région de secours. En cas d’incident, vous pouvez augmenter horizontalement ou accroître les ressources de la région de secours, puis la promouvoir en région principale.
Étapes d’implémentation
-
Travaillez avec les parties prenantes de l’entreprise et les experts en résidence des données pour déterminer les Régions AWS qui peuvent être utilisées pour héberger vos ressources et vos données.
-
Travaillez avec les parties prenantes techniques et commerciales pour évaluer votre charge de travail et déterminer si ses besoins de résilience peuvent être satisfaits par une approche multi-AZ (une seule Région AWS) ou s’ils nécessitent une approche multirégionale (si plusieurs régions sont autorisées). L’utilisation de plusieurs régions permet de bénéficier d’une plus grande disponibilité, mais peut entraîner une complexité et des coûts supplémentaires. Tenez compte des facteurs suivants dans votre évaluation :
-
Objectifs commerciaux et exigences des clients : quelle est la durée d’indisponibilité autorisée en cas d’incident affectant la charge de travail dans une zone de disponibilité ou une région ? Évaluez vos objectifs de point de récupération tels qu’ils sont présentés dans REL13-BP01 Définir les objectifs de reprise en termes de durée d’indisponibilité et de perte de données.
-
Exigences relatives à la reprise après sinistre (DR) : contre quel type de sinistre potentiel souhaitez-vous vous assurer ? Envisagez la possibilité d’une perte de données ou d’une indisponibilité à long terme à différents niveaux d’impact, d’une simple zone de disponibilité à une région entière. Si vous répliquez des données et des ressources entre des zones de disponibilité et qu’une seule zone de disponibilité connaît une défaillance prolongée, vous pouvez récupérer le service dans une autre zone de disponibilité. Si vous répliquez des données et des ressources entre plusieurs régions, vous pouvez récupérer le service dans une autre région.
-
-
Déployez vos ressources de calcul dans plusieurs zones de disponibilité.
-
Dans votre VPC, créez plusieurs sous-réseaux dans des zones de disponibilité différentes. Configurez chacune d’elles de manière à ce qu’elle soit suffisamment grande pour accueillir les ressources nécessaires pour répondre à la charge de travail, même en cas d’incident. Pour plus d’informations, consultez REL02-BP03 S’assurer que l’allocation des sous-réseaux IP tient compte de l’expansion et de la disponibilité.
-
Si vous utilisez des instances Amazon EC2, utilisez EC2 Auto Scaling
pour gérer vos instances. Spécifiez les sous-réseaux que vous avez choisis à l’étape précédente lorsque vous créez vos groupes Auto Scaling. -
Si vous utilisez le calcul AWS Fargate pour Amazon ECS ou Amazon EKS, sélectionnez les sous-réseaux que vous avez choisis à la première étape lors de la création d’un service ECS, lancez une tâche ECS ou créez un profil Fargate pour EKS.
-
Si vous utilisez des fonctions AWS Lambda qui doivent être exécutées dans votre VPC, sélectionnez les sous-réseaux que vous avez choisis à la première étape lors de la création de la fonction Lambda. Pour toutes les fonctions qui n’ont pas de configuration VPC, AWS Lambda gère automatiquement la disponibilité pour vous.
-
Placez des redirecteurs de trafic tels que des équilibreurs de charge devant vos ressources de calcul. Si l’équilibrage de charge entre zones est activé, les équilibreurs AWS Application Load Balancers et Network Load Balancers détectent quand des cibles telles que des instances et des conteneurs EC2 sont inaccessibles en raison d’une altération de la zone de disponibilité et redirigent le trafic vers des cibles situées dans des zones de disponibilité saines. Si vous désactivez l’équilibrage de charge entre zones, utilisez Amazon Application Recovery Controller (ARC) pour fournir une fonctionnalité de changement de zone. Si vous utilisez un équilibreur de charge tiers ou si vous avez implémenté vos propres équilibreurs de charge, configurez-les avec plusieurs front ends répartis dans différentes zones de disponibilité.
-
-
Répliquez les données de votre charge de travail sur plusieurs zones de disponibilité.
-
Si vous utilisez un service de données AWS géré tel qu’Amazon RDS, Amazon ElastiCache ou Amazon FSx, étudiez son guide de l’utilisateur pour comprendre ses capacités de réplication de données et de résilience. Activez la réplication et le basculement entre zones de disponibilité si nécessaire.
-
Si vous utilisez des services de stockage AWS gérés tels qu’Amazon S3, Amazon EFS et Amazon FSx, évitez d’utiliser des configurations mono-AZ ou à zone unique pour des données qui requièrent une durabilité élevée. Utilisez une configuration multi-AZ pour ces services. Consultez le guide de l’utilisateur du service correspondant pour déterminer si la réplication multi-AZ est activée par défaut ou si vous devez l’activer.
-
Si vous exécutez une base de données, une file d’attente ou un autre service de stockage autogéré, organisez la réplication multi-AZ conformément aux instructions ou aux bonnes pratiques de l’application. Familiarisez-vous avec les procédures de basculement de votre application.
-
-
Configurez votre service DNS pour détecter une altération de la zone de disponibilité et rediriger le trafic vers une zone de disponibilité saine. Amazon Route 53, lorsqu’il est utilisé en combinaison avec des Elastic Load Balancers, peut le faire automatiquement. Route 53 peut également être configuré avec des enregistrements de basculement qui utilisent la surveillance de l’état pour répondre aux requêtes avec uniquement des adresses IP saines. Pour tous les enregistrements DNS utilisés pour le basculement, spécifiez une faible valeur de durée de vie (TTL) (par exemple, 60 secondes ou moins) afin d’éviter que la mise en cache des enregistrements n’entrave la reprise (les enregistrements d’alias Route 53 fournissent des durées de vie (TTL) appropriées pour vous).
Étapes supplémentaires lors de l’utilisation de plusieurs Régions AWS
-
Répliquez l’ensemble du code d’application et de système d’exploitation (OS) utilisé par votre charge de travail dans les régions que vous avez sélectionnées. Répliquez les images Amazon Machine Image (AMI) utilisées par vos instances EC2, si nécessaire, à l’aide de solutions telles qu’Amazon EC2 Image Builder. Répliquez les images de conteneur stockées dans des registres à l’aide de solutions telles que la réplication entre régions Amazon ECR. Activez la réplication régionale pour tous les compartiments Amazon S3 utilisés pour stocker les ressources d’application.
-
Déployez vos ressources de calcul et vos métadonnées de configuration (telles que les paramètres stockés dans AWS Systems Manager Parameter Store) dans plusieurs régions. Utilisez les mêmes procédures que celles décrites dans les étapes précédentes, mais répliquez la configuration pour chaque région que vous utilisez pour votre charge de travail. Utilisez des solutions d’infrastructure en tant que code, telles qu’AWS CloudFormation pour reproduire uniformément les configurations entre les régions. Si vous utilisez une région secondaire dans une configuration d’environnement en veille pour la reprise après sinistre, vous pouvez réduire le nombre de vos ressources de calcul à une valeur minimale afin de réduire les coûts, avec une augmentation correspondante du temps de reprise.
-
Répliquez vos données de votre région principale vers vos régions secondaires.
-
Les tables globales Amazon DynamoDB fournissent des réplicas globaux de vos données sur lesquels vous pouvez écrire depuis n’importe quelle région prise en charge. Avec d’autres services de données AWS gérés, tels qu’Amazon RDS, Amazon Aurora et Amazon Elasticache, vous désignez une région principale (lecture/écriture) et des régions de réplica (lecture seule). Consultez les guides de l’utilisateur et les manuels du développeur des services respectifs pour plus de détails sur la réplication régionale.
-
Si vous exécutez une base de données autogérée, organisez la réplication multirégionale conformément aux instructions ou aux bonnes pratiques de l’application. Familiarisez-vous avec les procédures de basculement de votre application.
-
Si votre charge de travail utilise AWS EventBridge, vous devrez peut-être transférer certains événements de votre région principale vers vos régions secondaires. Pour ce faire, spécifiez les bus d’événements dans vos régions secondaires comme cibles pour les événements correspondants dans votre région principale.
-
-
Déterminez si et dans quelle mesure vous souhaitez utiliser des clés de chiffrement identiques entre les régions. Une approche standard conciliant sécurité et facilité d’utilisation consiste à utiliser des clés régionales pour les données et l’authentification locales d’une région, et à utiliser des clés globales pour le chiffrement des données répliquées entre différentes régions. AWS Key Management Service (KMS)
prend en charge les clés multirégionales pour répartir en toute sécurité et protéger les clés partagées entre les régions. -
Envisagez d’utiliser AWS Global Accelerator pour améliorer la disponibilité de votre application en dirigeant le trafic vers les régions qui contiennent des points de terminaison sains.
Ressources
Bonnes pratiques associées :
Documents connexes :
-
Livre blanc : Limites d’isolation des défaillances des services AWS
-
Amazon EC2 Auto Scaling : exemple : répartition des instances entre les zones de disponibilité
-
Comment Amazon ECS place les tâches sur les instances de conteneur (y compris Fargate)
-
Manuel du développeur Amazon Application Recovery Controller (ARC)
-
Envoi et réception d’événements Amazon EventBridge entre régions Régions AWS
-
Série de blog sur la création d’une application multirégion avec les services AWS
-
Architecture de reprise après sinistre (DR) sur AWS, partie I : stratégies de reprise dans le cloud
Vidéos connexes :
