Options de reprise après sinistre dans le cloud
Les stratégies de reprise après sinistre mises à votre disposition au sein d'AWS peuvent être classées en quatre approches, allant du faible coût et de la faible complexité des sauvegardes à des stratégies plus complexes utilisant plusieurs régions actives. Il est essentiel de tester régulièrement votre stratégie de reprise après sinistre afin de pouvoir l'invoquer en toute confiance, le cas échéant.
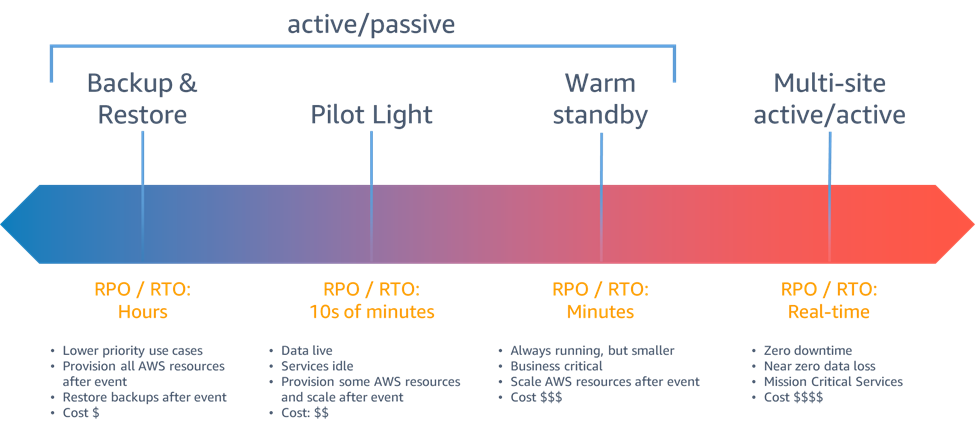
Figure 6 - Stratégies de reprise après sinistre
En cas de sinistre lié à la perturbation ou à la perte d'un centre de données physique pour une charge de travail hautement disponible et bien structurée
Sauvegarde et restauration
La sauvegarde et la restauration constituent une approche appropriée pour atténuer les risques de perte ou de corruption des données. Cette approche peut également être utilisée pour atténuer un sinistre régional en répliquant les données vers d'autres régions AWS, ou pour atténuer le manque de redondance des charges de travail déployées dans une seule zone de disponibilité. Outre les données, vous devez redéployer l'infrastructure, la configuration et le code d'application dans la région de reprise. Pour permettre le redéploiement rapide et sans erreur de l'infrastructure, vous devez toujours déployer à l'aide d'Infrastructure as code (IaC) par le biais de services tels que AWS CloudFormation
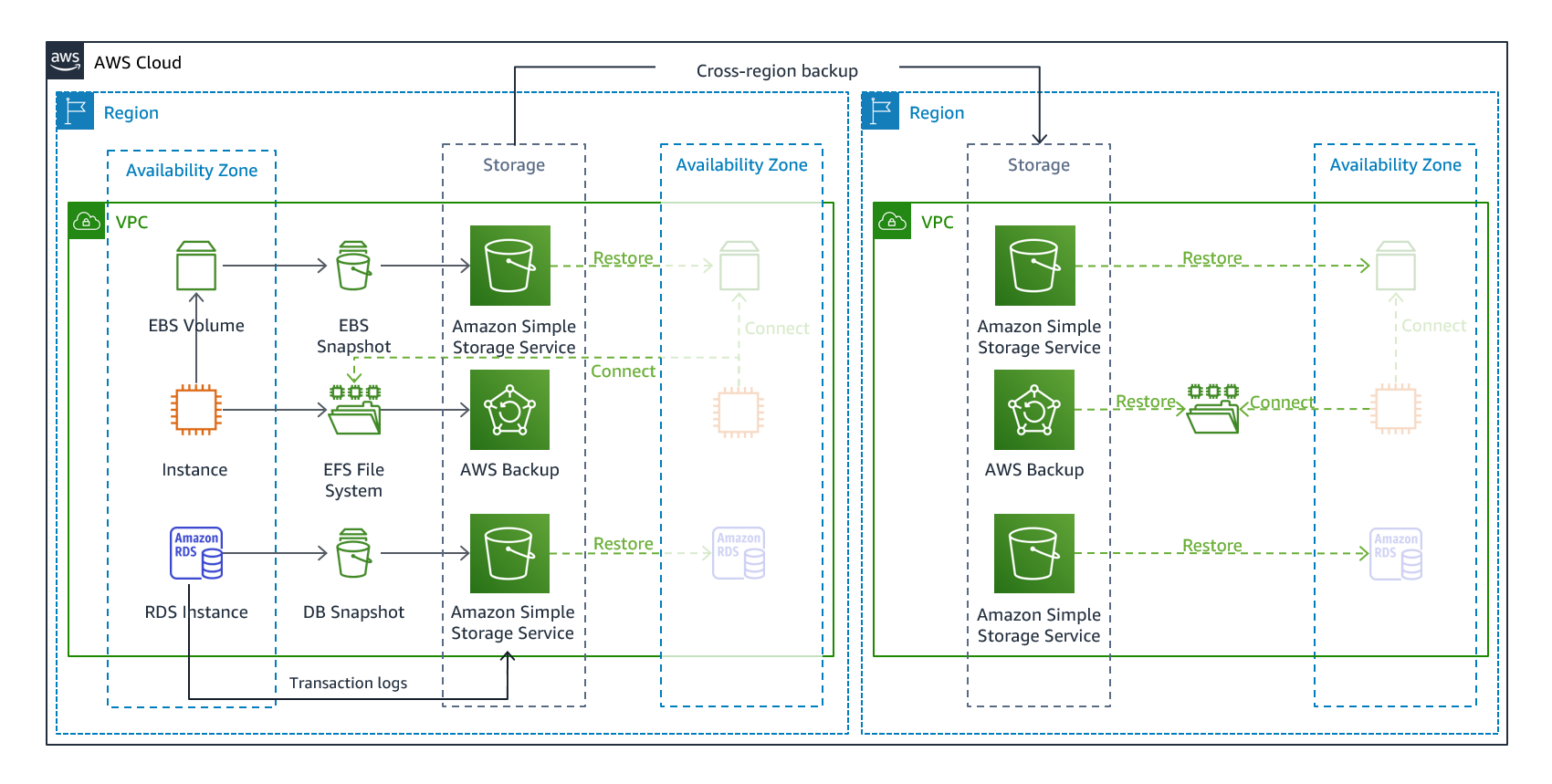
Figure 7 - Architecture de sauvegarde et restauration
Services AWS
Les données de votre charge de travail nécessiteront une stratégie de sauvegarde qui s'exécute périodiquement ou qui est continue. La fréquence à laquelle vous exécutez votre sauvegarde déterminera votre point de reprise réaliste (qui doit correspondre à votre RPO). La sauvegarde doit également permettre de restaurer au moment de la récupération. La sauvegarde avec restauration à un instant dans le passé est disponible via les services et ressources suivants :
Pour Amazon Simple Storage Service (Amazon S3), vous pouvez utiliser la réplication entre régions Amazon S3 (CRR)
AWS Backup
-
Instances Amazon EC2
-
Bases de données Amazon Relational Database Service (Amazon RDS)
(y compris les bases de données Amazon Aurora ) -
Tables Amazon DynamoDB
-
Systèmes de fichiers Amazon Elastic File System (Amazon EFS)
-
Volumes AWS Storage Gateway
AWS Backup prend en charge la copie des sauvegardes entre les régions, par exemple vers une région de reprise après sinistre.
En tant que stratégie de reprise après sinistre supplémentaire pour vos données Amazon S3, activez la gestion des versions des objets S3. La gestion des versions des objets protège vos données dans S3 contre les conséquences des actions de suppression ou de modification en conservant la version d'origine avant l'action. La gestion des versions d'objets peut être utile pour atténuer les catastrophes provenant d'erreurs humaines. Si vous utilisez la réplication S3 pour sauvegarder des données dans votre région de reprise après sinistre, alors, lorsqu'un objet est supprimé dans le compartiment source, Amazon S3 ajoute par défaut un marqueur de suppression dans le compartiment source uniquement. Cette approche protège les données de la région de reprise après sinistre contre les suppressions malveillantes dans la région source.
Outre les données, vous devez également sauvegarder la configuration et l'infrastructure nécessaires pour redéployer votre charge de travail et atteindre votre objectif de délai de reprise (RTO). AWS CloudFormation
Toutes les données stockées dans la région de reprise après sinistre en tant que sauvegardes doivent être restaurées au moment du basculement. AWS Backup offre une fonction de restauration, mais ne permet pas actuellement la restauration planifiée ou automatique. Vous pouvez implémenter une restauration automatique dans la région de reprise après sinistre à l'aide du kit SDK AWS afin d'appeler des API pour AWS Backup. Vous pouvez configurer la restauration en tant que tâche récurrente ou déclencher une restauration chaque fois qu'une sauvegarde est terminée. La figure suivante montre un exemple de restauration automatique à l'aide d'Amazon Simple Notification Service (Amazon SNS)
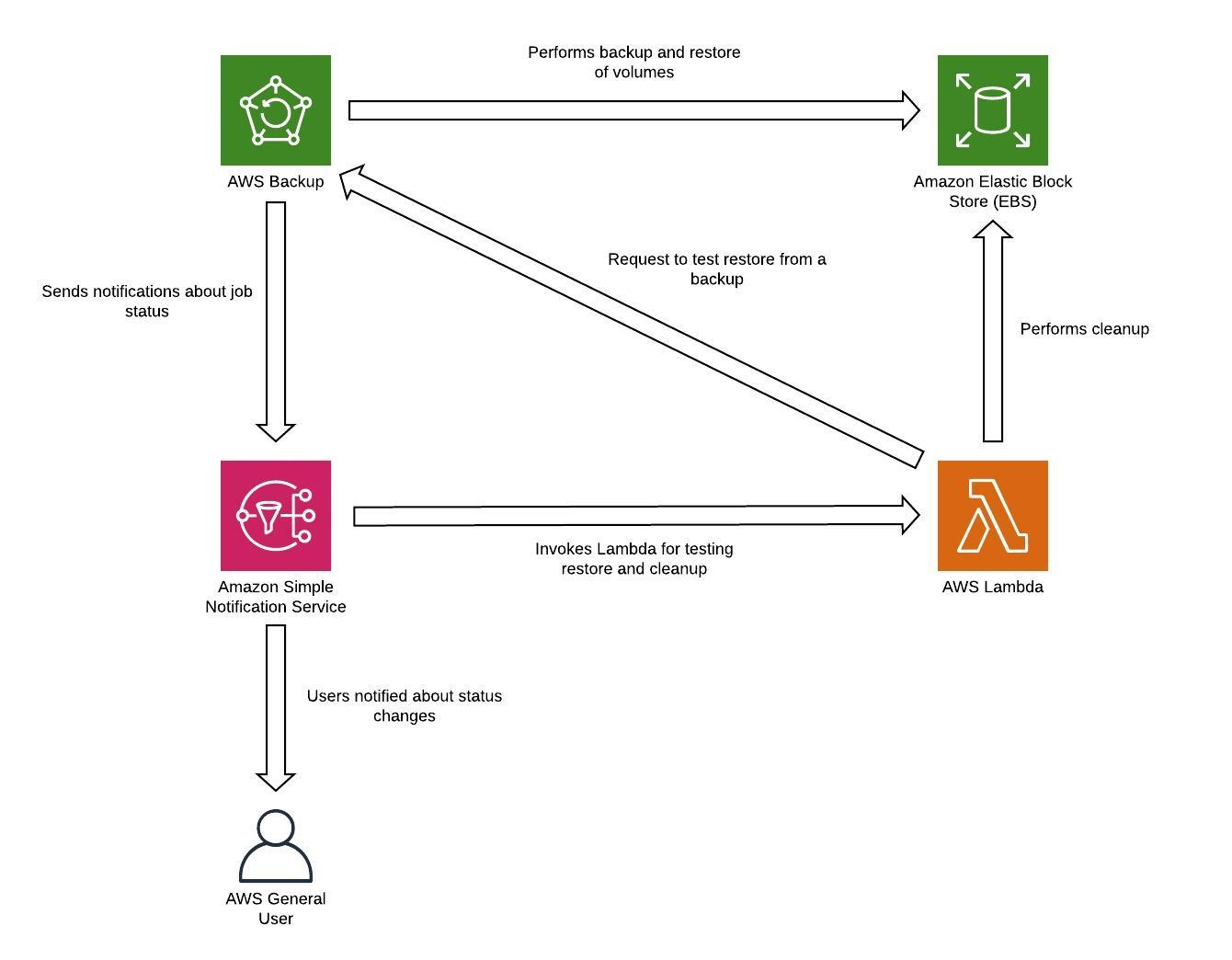
Figure 8 - restauration et test des sauvegardes
Note
Votre stratégie de sauvegarde doit inclure le test de vos sauvegardes. Pour de plus amples informations, veuillez consulter la section Test de reprise après sinistre. Pour obtenir une démonstration pratique de l'implémentation, veuillez consulter Ateliers AWS Well-Architected : Test de la sauvegarde et de la restauration des données
Environnement de veille
Avec l'approche Environnement de veille, vous répliquez vos données d'une région à une autre et mettez en service une copie de votre infrastructure de charge de travail principale. Les ressources nécessaires pour prendre en charge la réplication et la sauvegarde des données, telles que les bases de données et le stockage d'objets, sont toujours disponibles. D'autres éléments, tels que les serveurs d'applications, sont chargés avec le code d'application et les configurations, mais sont désactivés, et ne sont utilisés que pendant les tests ou lorsque le basculement de reprise après sinistre est invoqué. Contrairement à l'approche de sauvegarde et de restauration, votre infrastructure principale est toujours disponible et vous avez toujours la possibilité de provisionner rapidement un environnement de production à grande échelle en utilisant et en procédant à une évolutivité horizontale de vos serveurs d'applications.
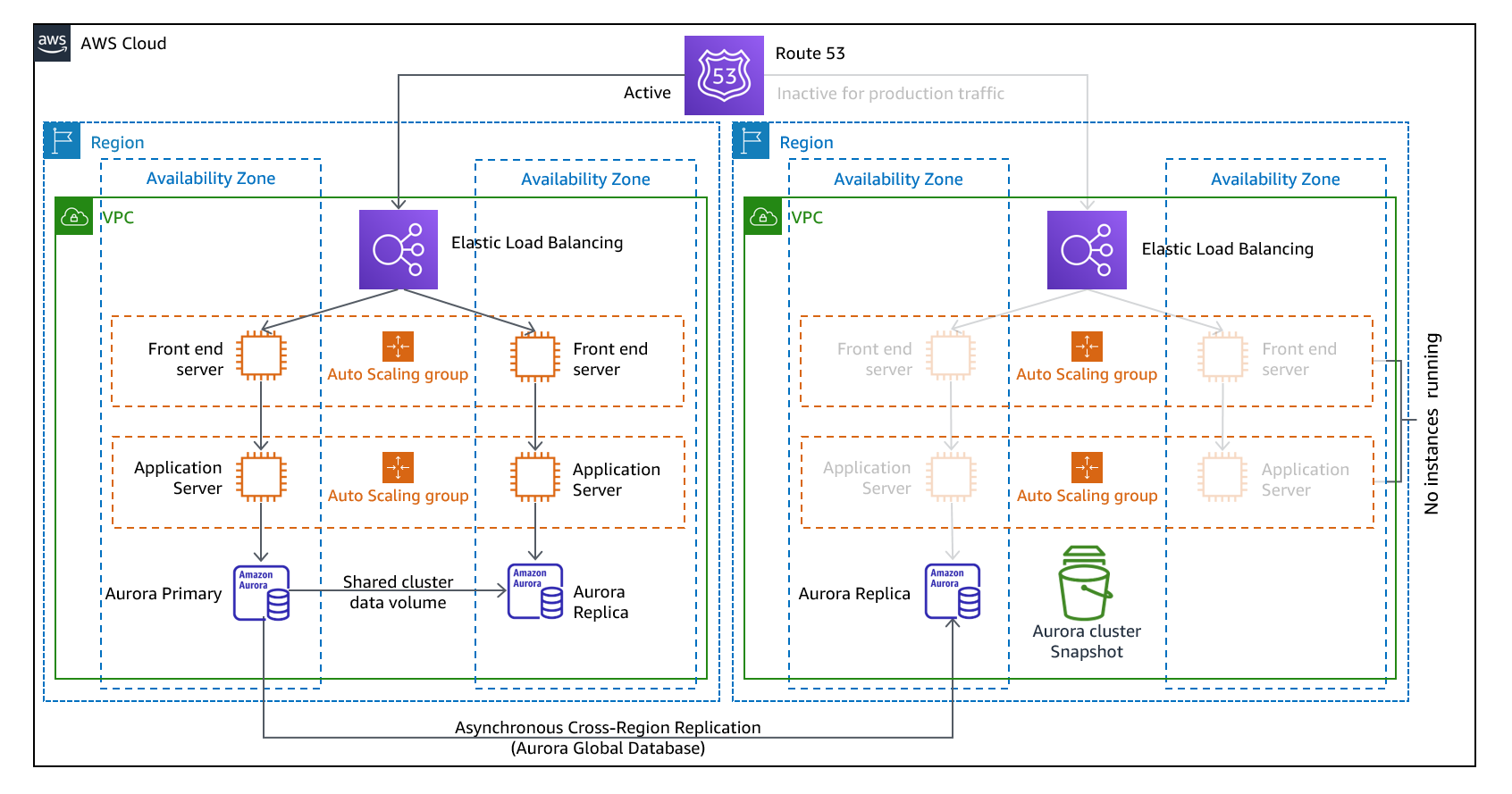
Figure 9 - Environnement de veille
Une approche Environnement de veille réduit le coût permanent de la reprise après sinistre en réduisant les ressources actives, et simplifie la reprise en cas de sinistre, car les exigences de l'infrastructure de base sont toutes en place. Cette option de récupération vous oblige à modifier votre approche du déploiement. Vous devez apporter des modifications à l'infrastructure principale de chaque région et déployer les modifications de la charge de travail (configuration, code) simultanément dans chaque région. Cette étape peut être simplifiée en automatisant vos déploiements et en utilisant l'Infrastructure as code (IaC) pour déployer l'infrastructure sur plusieurs comptes et régions (déploiement complet de l'infrastructure dans la région principale et déploiement d'infrastructure réduit/désactivé vers les régions de reprise après sinistre). Il est recommandé d'utiliser un compte différent par région pour fournir le plus haut niveau d'isolation des ressources et de sécurité (dans le cas où les informations d'identification compromises font également partie de vos plans de reprise après sinistre).
Avec cette approche, vous devez également atténuer les risques liés aux données en cas de sinistre. La réplication continue des données vous protège contre certains types de sinistre, mais elle peut ne pas vous protéger contre la corruption ou la destruction des données, sauf si votre stratégie inclut également la gestion des versions des données stockées ou des options de restauration à un instant dans le passé. Vous pouvez sauvegarder les données répliquées dans la région sinistrée pour créer des sauvegardes à un instant donné dans cette même région.
Services AWS
En plus d'utiliser les services AWS abordés dans la section Sauvegarde et restauration pour créer des sauvegardes à un instant donné, pensez également aux services suivants pour votre stratégie Environnement de veille.
Pour la stratégie Environnement de veille, la réplication continue des données vers des bases de données actives et des magasins de données dans la région de reprise après sinistre est la meilleure approche pour un faible RPO (lorsqu'elle est utilisée en plus des sauvegardes à un instant donné évoquées précédemment). AWS fournit une réplication entre régions continue et asynchrone pour les données à l'aide des services et des ressources suivants :
Avec la réplication continue, les versions de vos données sont disponibles presque immédiatement dans votre région de reprise après sinistre. Les temps de réplication réels peuvent être surveillés à l'aide de fonctionnalités de service telles que le contrôle du délai de réplication S3 (S3 RTC) pour les objets S3 et les fonctionnalités de gestion des bases de données Amazon Aurora Global Database.
Lors du basculement destiné à exécuter votre application en lecture/écriture à partir de la région de reprise après sinistre, vous devez promouvoir un réplica en lecture RDS pour qu'il devienne l'instance principale. Pour les instances de bases de données autres qu'Aurora, le processus dure quelques minutes et le redémarrage fait partie du processus. Pour la réplication entre régions (CRR) et le basculement avec RDS, l'utilisation d'Amazon Aurora Global Database présente plusieurs avantages. La base de données globale utilise une infrastructure dédiée qui laisse vos bases entièrement disponibles pour servir votre application et peut être répliquée dans une région secondaire avec une latence inférieure à une seconde (et beaucoup moins que 100 millisecondes au sein d'une région AWS). Avec Amazon Aurora Global Database, si votre région principale subit une dégradation des performances ou une panne, vous pouvez promouvoir l'une des régions secondaires afin qu'elle prenne des responsabilités en lecture/écriture en moins d'une minute, même en cas de panne régionale complète. La promotion peut être automatique et il n'y a pas de redémarrage.
Une version réduite de votre infrastructure de charge de travail principale avec moins de ressources ou des ressources plus petites doit être déployée dans votre région de reprise après sinistre. À l'aide d'AWS CloudFormation, vous pouvez définir votre infrastructure et la déployer de manière cohérente sur les comptes AWS et les régions AWS. AWS CloudFormation utilise des pseudo-paramètres prédéfinis pour identifier le compte AWS et la région AWS dans laquelle il est déployé. Par conséquent, vous pouvez implémenter une logique de condition dans vos modèles CloudFormation pour déployer uniquement la version réduite de votre infrastructure dans la région de reprise après sinistre. Pour les déploiements d'instance EC2, une image Amazon Machine Image (AMI) fournit des informations concernant par exemple la configuration matérielle et les logiciels installés. Vous pouvez implémenter un pipeline Image Builder qui crée les AMI dont vous avez besoin et les copier dans votre région principale et dans votre région de sauvegarde. Cela permet de garantir que ces AMI finales disposent de tout ce dont vous avez besoin, en cas de sinistre, pour redéployer ou faire monter en puissance votre charge de travail dans une nouvelle région. Les instances Amazon EC2 sont déployées dans une configuration réduite (qui comporte moins d'instances que dans votre région principale). Vous pouvez utiliser la mise en veille prolongée pour placer les instances EC2 dans un état d'arrêt, ce qui vous permet de ne pas payer de frais EC2, mais uniquement le stockage utilisé. Pour démarrer des instances EC2, vous pouvez créer des scripts à l'aide de l'interface de ligne de commande (CLI) AWS
Pour une configuration Actif/Veille telle que l'Environnement de veille, l'ensemble du trafic est initialement dirigé vers la région principale et passe à la région de reprise après sinistre si la région principale n'est plus disponible. Vous avez le choix entre deux options de gestion du trafic concernant les services AWS. La première option consiste à utiliser Amazon Route 53
La deuxième option consiste à utiliser AWS Global Accelerator
CloudEndure Disaster Recovery
CloudEndure Disaster Recovery

Figure 10 - Architecture CloudEndure Disaster Recovery
Secours à chaud
L'approche Secours à chaud implique de s'assurer qu'il existe une copie réduite, mais entièrement fonctionnelle, de votre environnement de production dans une autre région. Cette approche étend le concept d'Environnement de veille et réduit le délai de reprise, car votre charge de travail est toujours active dans une autre région. Cette approche vous permet également d'effectuer plus facilement des tests ou d'implémenter des tests continus afin d'augmenter la confiance dans votre capacité de reprise après sinistre.
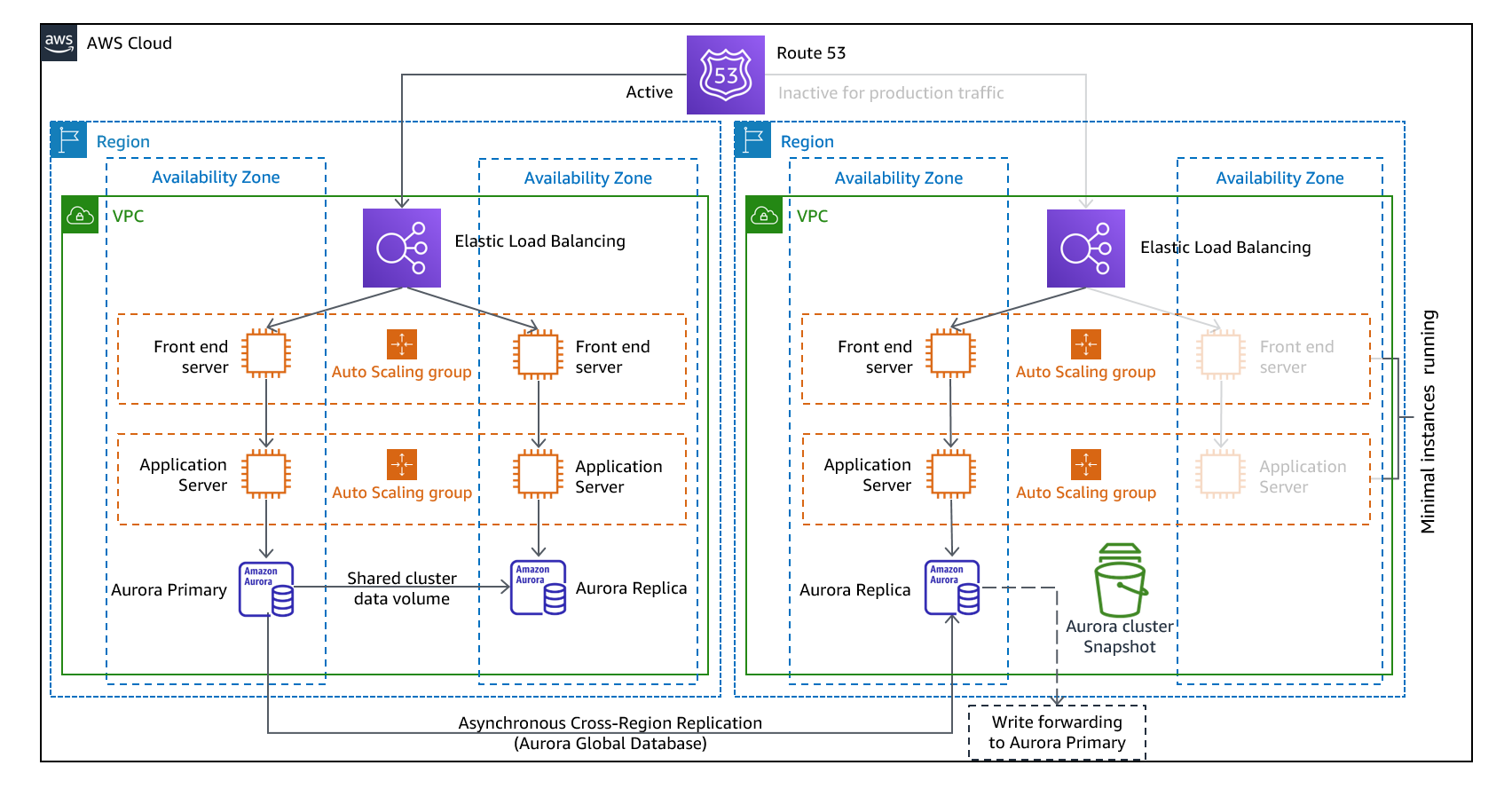
Figure 11 - Architecture Secours à chaud
Remarque : La différence entre l'Environnement de veille et le Secours à chaud peut parfois être difficile à comprendre. Les deux architectures incluent un environnement dans votre région de reprise après sinistre avec des copies des actifs de votre région principale. La différence réside dans le fait que l'Environnement de veille ne peut pas traiter les demandes sans que des mesures supplémentaires ne soient prises au préalable, tandis que le Secours à chaud peut traiter le trafic (à des niveaux de capacité réduits) immédiatement. L'approche Environnement de veille nécessite de « démarrer » les serveurs, déployer éventuellement une infrastructure (non principale) supplémentaire et d'augmenter la charge, tandis que l'approche Secours à chaud ne nécessite que d'augmenter la charge (tout est déjà déployé et en cours d'exécution). Choisissez l'une ou l'autre approche en fonction de vos besoins en termes de RTO et de RPO.
Services AWS
Tous les services AWS couverts par la sauvegarde et la restauration et l'Environnement de veille sont également utilisés dans l'approche Secours à chaud pour la sauvegarde des données, la réplication des données, le routage du trafic actif/en veille et le déploiement de l'infrastructure, y compris les instances EC2.
AWS Auto Scaling
Mode actif/actif multi-site
Vous pouvez exécuter votre charge de travail simultanément dans plusieurs régions dans le cadre d'une stratégie actif/actif multi-site ou actif/passif de secours. La stratégie actif/actif multi-site dirige le trafic de toutes les régions vers lesquelles il est déployé, tandis que la stratégie de Secours à chaud ne traite que le trafic d'une seule région. Et les autres régions ne sont utilisées que pour la reprise après sinistre. Avec une approche actif/actif multi-site, les utilisateurs peuvent accéder à votre charge de travail dans toutes les régions dans lesquelles elle est déployée. Cette approche est la plus complexe et la plus coûteuse en matière de reprise après sinistre, mais elle peut réduire votre délai de reprise à près de zéro pour la plupart des sinistres lorsque les choix technologiques et l'implémentation appropriés sont effectués (toutefois, la corruption des données peut nécessiter des sauvegardes, ce qui aboutit généralement à un point de reprise différent de zéro). Le mode Secours à chaud utilise une configuration active/passive dans laquelle les utilisateurs ne sont dirigés que vers une seule région et les régions de reprise après sinistre ne prennent pas de trafic. La plupart des clients considèrent que s'ils veulent créer un environnement complet dans la deuxième région, il est logique de l'utiliser en mode actif/actif. Si vous ne souhaitez pas utiliser les deux régions pour gérer le trafic utilisateur, le secours à chaud offre une approche plus économique et moins complexe sur le plan opérationnel.
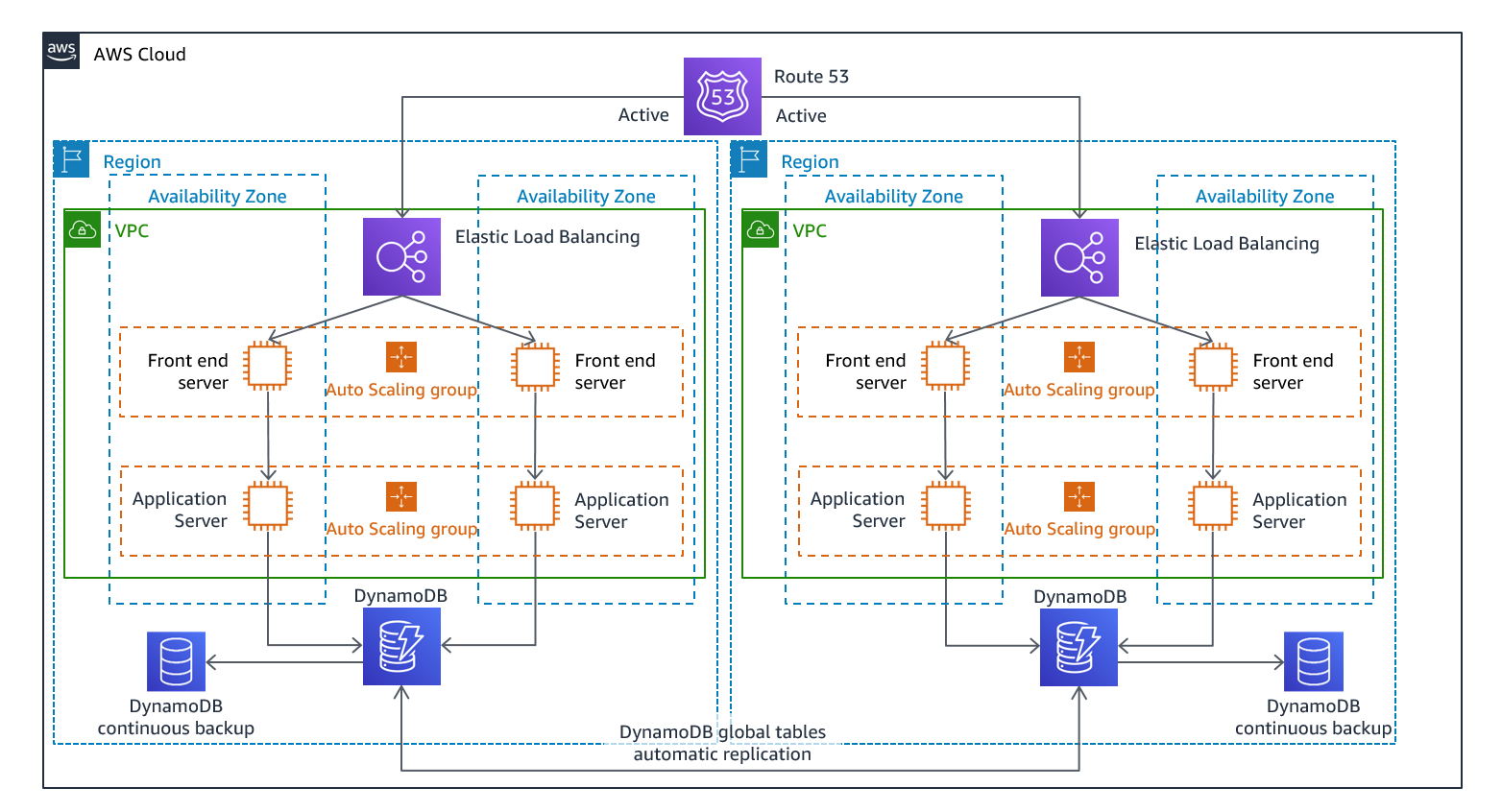
Figure 12 : architecture active/active multi-site (changer un chemin d'accès actif en chemin d'accès inactif pour le secours à chaud)
En mode actif/actif multi-site, étant donné que la charge de travail s'exécute dans plusieurs régions, il n'existe pas de basculement dans ce scénario. Dans ce cas, les tests de reprise après sinistre se concentrent sur la façon dont la charge de travail réagit à la perte d'une région : le trafic est-il acheminé hors de la région défaillante ? Les autres régions peuvent-elles gérer l'ensemble du trafic ? Il est également nécessaire de tester les données en cas de sinistre. La sauvegarde et la restauration sont toujours nécessaires et doivent être testées régulièrement. Il convient également de noter que les délais de reprise pour les données en cas de sinistre impliquant une corruption, une suppression ou une obfuscation des données seront toujours supérieurs à zéro et que le point de reprise sera toujours situé à un certain point avant la découverte du sinistre. Si la complexité et le coût supplémentaires d'une approche actif/actif multi-site (ou de secours à chaud) sont nécessaires pour maintenir des délais de reprise proches de zéro, des efforts supplémentaires doivent être faits pour maintenir la sécurité et prévenir les erreurs humaines afin d'atténuer les risques de catastrophe humaine.
Services AWS
Tous les services AWS couverts par les modes Sauvegarde et la restauration, Environnement de veille et Secours à chaud sont également utilisés ici pour la sauvegarde des données à un instant dans le passé, la réplication des données, le routage du trafic actif/actif, ainsi que le déploiement et la mise à l'échelle de l'infrastructure, y compris les instances EC2.
Pour les scénarios actifs/passifs évoqués précédemment (Environnement de veille et Secours à chaud), Amazon Route 53 et AWS Global Accelerator peuvent tous deux être utilisés pour acheminer le trafic réseau vers la région active. Pour la stratégie active/active exposée ici, ces deux services permettent également de définir des politiques qui déterminent quels utilisateurs se dirigent vers quel point de terminaison régional actif. Avec AWS Global Accelerator vous définissez un variateur de trafic pour contrôler le pourcentage de trafic dirigé vers chaque point de terminaison d'application. Amazon Route 53 prend en charge cette approche en pourcentage, ainsi que plusieurs autres politiques disponibles, notamment celles basées sur la proximité géographique et la latence. Global Accelerator exploite automatiquement le vaste réseau de serveurs Edge AWS pour intégrer le trafic vers le réseau principal AWS dès que possible, ce qui réduit les latences des demandes.
La réplication des données associée à cette stratégie permet d'atteindre un objectif de point de reprise proche de zéro. Les services AWS comme Amazon Aurora Global Database, utilisent une infrastructure dédiée qui laisse vos bases de données entièrement disponibles pour servir votre application et peuvent être répliqués dans une région secondaire avec, généralement, une latence inférieure à une seconde. Avec les stratégies en mode actif/passif, les écritures se produisent uniquement dans la région principale. La différence par rapport à la stratégie en mode actif/actif porte sur la conception de la gestion des écritures dans chaque région active. Il est courant de concevoir des lectures utilisateur qui seront acheminées depuis la région la plus proche, système appelé système de lecture local. Avec les écritures, plusieurs options s'offrent à vous :
-
Une stratégie d'écriture globale achemine toutes les écritures vers une seule région. En cas d'échec de cette région, une autre région est promue pour accepter les écritures. La base de données globale Aurora convient parfaitement à l'écriture globale, car elle prend en charge la synchronisation avec des réplicas en lecture entre les régions, et vous pouvez promouvoir l'une des régions secondaires pour qu'elle prenne des responsabilités en lecture/écriture en moins d'une minute.
-
Une stratégie d'écriture locale achemine les écritures vers la région la plus proche (tout comme les lectures). Les tables globales Amazon DynamoDB permettent ce type de stratégie, autorisant la lecture et l'écriture à partir de chaque région dans laquelle votre table globale est déployée. Les tables globales Amazon DynamoDB utilisent un rapprochement last writer wins (dernière version valide) entre des mises à jour concomitantes.
-
Une stratégie partitionnée en écriture attribue des écritures à une région spécifique en fonction d'une clé de partition (par exemple un ID utilisateur) pour éviter les conflits d'écriture. La réplication Amazon S3 configurée de manière bidirectionnelle
peut être utilisée dans ce cas, et prend actuellement en charge la réplication entre deux régions. Lors de l'implémentation de cette approche, veillez à activer la synchronisation des modifications de réplica sur les compartiments A et B pour répliquer les modifications des métadonnées de réplica, telles que les listes de contrôle d'accès aux objets, les balises d'objet ou les verrous d'objet sur les objets répliqués. Vous pouvez également configurer la réplication ou la non réplication des marqueurs de suppression entre les compartiments de vos régions actives. Outre la réplication, votre stratégie doit inclure des sauvegardes à un instant dans le passé pour vous protéger contre les événements de corruption ou de destruction des données.
AWS CloudFormation est un outil puissant qui permet d'appliquer une infrastructure déployée de manière cohérente entre les comptes AWS de plusieurs régions AWS. AWS CloudFormation StackSets étend cette fonctionnalité en vous permettant de créer, mettre à jour ou supprimer des piles CloudFormation sur plusieurs comptes et régions en une seule opération. Bien qu'AWS CloudFormation utilise YAML ou JSON pour définir Infrastructure as Code, AWS Cloud Development Kit (AWS CDK)
