Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Memantau replikasi baca
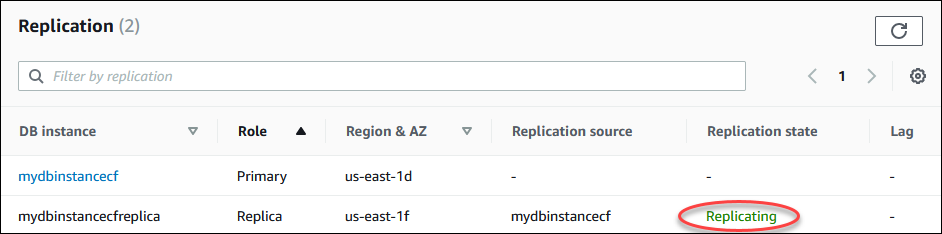
Anda dapat memantau status replika baca dengan beberapa cara. Konsol Amazon RDS menampilkan status replika baca di bagian Replikasi pada tab Konektivitas & keamanan di detail replika baca. Untuk melihat detail replika baca, pilih nama replika baca di daftar instans di konsol Amazon RDS.
Anda juga dapat melihat status replika baca menggunakan AWS CLI
describe-db-instances perintah atau operasi Amazon RDS APIDescribeDBInstances.
Status replika baca dapat berupa salah satu dari berikut ini:
-
mereplikasi – Replika baca berhasil direplikasi.
-
replikasi terdegradasi (hanya SQL Server dan PostgreSQL) – Replika menerima data dari instans primer, tetapi satu atau beberapa basis data mungkin tidak mendapatkan pembaruan. Hal ini bisa terjadi, misalnya, ketika replika sedang dalam proses menyiapkan basis data yang baru dibuat. Ini juga dapat terjadi ketika DDL yang tidak didukung atau perubahan objek besar dibuat di lingkungan biru penerapan. blue/green
Statusnya tidak beralih dari
replication degradedkeerror, kecuali jika terjadi kesalahan selama status terdegradasi. -
kesalahan – Telah terjadi kesalahan pada replikasi. Periksa kolom Kesalahan Replikasi di konsol Amazon RDS atau log peristiwa untuk menentukan kesalahan sebenarnya. Untuk informasi selengkapnya tentang pemecahan masalah kesalahan replikasi, lihat Pemecahan Masalah batasan replika baca MySQL.
-
diakhiri (MariaDB, MySQL, atau PostgreSQL saja) – Replikasi diakhiri. Hal ini terjadi jika replikasi dihentikan selama lebih dari 30 hari berturut-turut, baik secara manual atau karena kesalahan replikasi. Jika ini terjadi, Amazon RDS menghentikan replikasi antara instans DB primer dan semua replika baca. Amazon RDS melakukannya untuk mencegah peningkatan kebutuhan penyimpanan pada instans DB sumber dan waktu failover yang lama.
Replikasi yang rusak dapat memengaruhi penyimpanan karena ukuran dan jumlah log bertambah akibat tingginya volume pesan kesalahan yang ditulis ke log. Replikasi yang rusak juga dapat memengaruhi pemulihan kegagalan karena waktu yang diperlukan Amazon RDS untuk memelihara dan memproses log dalam jumlah besar selama pemulihan.
-
diakhiri (Oracle saja) – Replikasi diakhiri. Hal ini terjadi jika replikasi dihentikan selama lebih dari 8 jam karena penyimpanan yang tersisa tidak memadai di replika baca. Jika ini terjadi, Amazon RDS menghentikan replikasi antara instans DB primer dan replika baca yang terpengaruh. Status ini adalah status akhir, dan replika baca harus dibuat ulang.
-
dihentikan (MariaDB atau MySQL saja) – Replikasi telah dihentikan karena permintaan yang diajukan oleh pelanggan.
-
titik henti replikasi ditetapkan (MySQL saja) – Titik henti yang diajukan oleh pelanggan ditetapkan menggunakan prosedur tersimpan dan replikasi sedang berlangsung.
-
titik henti replikasi tercapai (MySQL saja) – Titik henti yang diajukan oleh pelanggan ditetapkan menggunakan prosedur tersimpan dan replikasi dihentikan karena titik henti tercapai.
Anda dapat melihat tempat instans DB sedang direplikasi dan jika demikian, memeriksa status replikasinya. Pada halaman Basis data di konsol RDS, Primer akan ditampilkan dalam kolom Peran. Pilih nama instans DB nya. Pada halaman detailnya, pada tab Konektivitas & keamanan, status replikasinya ada di bawah Replikasi.
Memantau lag replikasi
Anda dapat memantau kelambatan replikasi di Amazon CloudWatch dengan melihat metrik Amazon RDS. ReplicaLag
Untuk Db2, ReplicaLag metrik adalah lag maksimum database yang tertinggal, dalam hitungan detik. Misalnya, jika dua database masing-masing tertinggal 5 detik dan 10 detik, maka ReplicaLag adalah 10 detik. Database tanpa status High Availability Disaster Recovery (HADR) yang tersedia tidak termasuk dalam perhitungan.
Untuk MariaDB dan MySQL, metrik ReplicaLag melaporkan nilai bidang Seconds_Behind_Master dari perintah SHOW REPLICA STATUS. Penyebab umum lag replikasi untuk MySQL dan MariaDB adalah sebagai berikut:
-
Pemadaman jaringan.
-
Menulis ke tabel dengan indeks pada replika baca. Jika parameter
read_onlytidak diatur ke 0 pada replika baca, hal ini dapat memecah replikasi. -
Menggunakan mesin penyimpanan non-transaksional seperti MyISAM. Replikasi hanya didukung untuk mesin penyimpanan InnoDB pada MySQL dan mesin penyimpanan XtraDB pada MariaDB.
catatan
Versi sebelumnya dari MariaDB menggunakan SHOW SLAVE STATUS, bukan SHOW REPLICA STATUS. Jika Anda menggunakan versi MariaDB yang lebih rendah dari 10.5, maka gunakan. SHOW SLAVE STATUS
Saat metrik ReplicaLag mencapai 0, replika telah menjadi instans DB primer. Jika metrik ReplicaLag menampilkan -1, maka replikasi saat ini tidak aktif. ReplicaLag = -1 setara dengan Seconds_Behind_Master = NULL.
Untuk Oracle, metrik ReplicaLag adalah jumlah dari nilai Apply
Lag dan perbedaan antara waktu saat ini dan nilai DATUM_TIME untuk apply lag. Nilai DATUM_TIME adalah terakhir kali replika baca menerima data dari instans DB sumbernya. Untuk informasi selengkapnya, lihat V$DATAGUARD_STATS
Untuk SQL Server, metrik ReplicaLag adalah lag maksimum dari basis data yang tertinggal, dalam hitungan detik. Misalnya, jika Anda memiliki dua basis data yang masing-masing tertinggal 5 detik dan 10 detik, maka ReplicaLag adalah 10 detik. Metrik ReplicaLag menampilkan nilai dari kueri berikut.
SELECT MAX(secondary_lag_seconds) max_lag FROM sys.dm_hadr_database_replica_states;
Untuk informasi selengkapnya, lihat secondary_lag_seconds
ReplicaLag menampilkan -1 jika RDS tidak dapat menentukan lag, seperti selama penyiapan replika, atau saat replika baca berada dalam status error.
catatan
Basis data baru tidak disertakan dalam penghitungan lag sampai basis data tersebut dapat diakses di replika baca.
Untuk PostgreSQL, metrik ReplicaLag menampilkan nilai dari kueri berikut.
SELECT extract(epoch from now() - pg_last_xact_replay_timestamp()) AS reader_lag
PostgreSQL versi 9.5.2 dan yang lebih baru menggunakan slot replikasi fisik untuk mengelola retensi write ahead log (WAL) pada instans sumber. Untuk setiap instans replika baca lintas Wilayah, Amazon RDS membuat slot replikasi fisik dan mengaitkannya dengan instans. Dua CloudWatch metrik Amazon, Oldest Replication Slot Lag danTransaction
Logs Disk Usage, menunjukkan seberapa jauh di belakang replika yang paling tertinggal dalam hal data WAL yang diterima dan berapa banyak penyimpanan yang digunakan untuk data WAL. Nilai Transaction
Logs Disk Usage dapat meningkat secara substansial ketika replika baca lintas Wilayah tertinggal secara signifikan.
Untuk informasi selengkapnya tentang memantau instans DB dengan CloudWatch, lihatMemantau Amazon RDS metrik dengan Amazon CloudWatch.
