Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Multi-AZ Penerapan cluster DB untuk Amazon RDS
Penerapan cluster Multi-AZ DB adalah mode penyebaran Amazon RDS semisinkron dan ketersediaan tinggi dengan dua instans replika DB yang dapat dibaca. Cluster Multi-AZ DB memiliki instans DB penulis dan dua instans DB pembaca di tiga Availability Zone terpisah yang sama Wilayah AWS. Multi-AZ Cluster DB menyediakan ketersediaan tinggi, peningkatan kapasitas untuk beban kerja baca, dan latensi tulis yang lebih rendah jika dibandingkan dengan penerapan instans Multi-AZ DB.
Anda dapat mengimpor data dari database lokal ke kluster Multi-AZ DB dengan mengikuti petunjuk diMengimpor data ke database Amazon RDS for MySQL dengan waktu henti yang dikurangi.
Anda dapat membeli instans DB cadangan untuk cluster Multi-AZ DB. Untuk informasi selengkapnya, lihat Instans DB cadangan untuk cluster Multi-AZ DB.
Ketersediaan dan dukungan fitur bervariasi di seluruh versi spesifik dari setiap mesin basis data, dan di seluruh Wilayah AWS. Untuk informasi selengkapnya tentang versi dan ketersediaan Wilayah Amazon RDS dengan kluster Multi-AZ DB, lihat. Daerah yang Didukung dan engine DB untuk cluster Multi-AZ DB di Amazon RDS
Topik
Secara otomatis menghubungkan sumber daya AWS komputasi dan cluster Multi-AZ DB untuk Amazon RDS
Memutakhirkan versi mesin cluster Multi-AZ DB untuk Amazon RDS
Mem-boot ulang instans Multi-AZ DB cluster dan reader DB untuk Amazon RDS
Menyiapkan replikasi logis PostgreSQL dengan cluster DB untuk Amazon RDS Multi-AZ
Bekerja dengan replika baca cluster Multi-AZ DB untuk Amazon RDS
Menyiapkan replikasi eksternal dari cluster Multi-AZ DB untuk Amazon RDS
penting
Multi-AZ Cluster DB tidak sama dengan cluster Aurora DB. Lihat informasi tentang klaster basis data Aurora di Panduan Pengguna Amazon Aurora.
Ketersediaan kelas instans untuk cluster Multi-AZ DB
Multi-AZ Penerapan cluster DB didukung untuk kelas instans DB berikut:db.c6gd,db.m5d,db.m6gd,db.m6id,db.m6idn,db.m8gd,db.r5d,db.r6gd, db.r6id db.r6idndb.r8gd, dan. db.x2iedn
catatan
Kelas instance c6gd adalah satu-satunya yang mendukung ukuran instance. medium
Untuk informasi selengkapnya tentang kelas instans DB, lihat Kelas instans DB.
Multi-AZ Arsitektur cluster DB
Dengan cluster Multi-AZ DB, Amazon RDS mereplikasi data dari instans DB penulis ke kedua instans DB pembaca menggunakan kemampuan replikasi asli mesin DB. Ketika perubahan dibuat pada instans basis data penulis, perubahan itu dikirim ke setiap instans basis data pembaca.
Multi-AZ Penerapan cluster DB menggunakan replikasi semisinkron, yang memerlukan pengakuan dari setidaknya satu instans DB pembaca agar perubahan dapat dilakukan. Deployment tidak memerlukan pengakuan bahwa peristiwa telah dieksekusi dan di-commit sepenuhnya pada semua replika.
Instans basis data pembaca bertindak sebagai target failover otomatis dan juga melayani lalu lintas baca untuk meningkatkan throughput baca aplikasi. Jika pemadaman terjadi pada instans basis data penulis, RDS mengelola failover ke salah satu instans basis data pembaca. RDS melakukan pemindahan berdasarkan instans basis data pembaca yang memiliki catatan perubahan terbaru.
Diagram berikut menunjukkan cluster Multi-AZ DB.
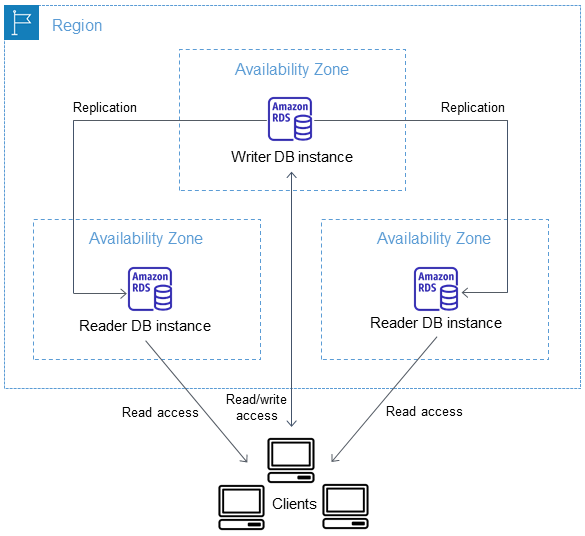
Multi-AZ Cluster DB biasanya memiliki latensi tulis yang lebih rendah jika dibandingkan dengan penerapan instans Multi-AZ DB. Klaster itu juga memungkinkan beban kerja hanya baca berjalan pada instans basis data pembaca. Konsol RDS menunjukkan Zona Ketersediaan instans basis data penulis dan Zona Ketersediaan instans basis data pembaca. Anda juga dapat menggunakan perintah CLI describe-db-clusters atau operasi API DescribeDBClusters untuk menemukan informasi ini.
penting
Untuk mencegah kesalahan replikasi di RDS untuk cluster MySQL Multi-AZ DB, kami sangat menyarankan agar semua tabel memiliki kunci utama.
Grup parameter untuk cluster Multi-AZ DB
Dalam cluster Multi-AZ DB, grup parameter cluster DB bertindak sebagai wadah untuk nilai konfigurasi engine yang diterapkan ke setiap instans DB di cluster Multi-AZ DB.
Dalam cluster Multi-AZ DB, grup parameter DB diatur ke grup parameter DB default untuk mesin DB dan versi mesin DB. Setelan dalam grup parameter klaster basis data digunakan untuk semua instans basis data di klaster.
Lihat informasi tentang grup parameter di Bekerja dengan grup parameter cluster DB untuk cluster Multi-AZ DB.
Proxy RDS dengan cluster Multi-AZ DB
Anda dapat menggunakan Amazon RDS Proxy untuk membuat proxy untuk cluster Multi-AZ DB Anda. Dengan menggunakan Proksi RDS, aplikasi Anda dapat mengumpulkan dan berbagi koneksi basis data untuk meningkatkan kemampuan menskalakan. Setiap proksi melakukan pembentukan multipleks koneksi, yang juga disebut dengan penggunaan ulang koneksi. Dengan multipleks, Proksi RDS melakukan semua operasi untuk sebuah transaksi dengan menggunakan satu koneksi basis data yang mendasari. RDS Proxy juga dapat mengurangi downtime untuk upgrade versi minor dari cluster Multi-AZ DB menjadi satu detik atau kurang. Lihat informasi yang lebih lengkap tentang manfaat-manfaat Proksi RDS di Proksi Amazon RDS.
Untuk menyiapkan proxy untuk cluster Multi-AZ DB, pilih Buat Proxy RDS saat membuat cluster. Untuk petunjuk membuat dan mengelola titik akhir Proksi RDS, lihat Bekerja dengan titik akhir Proksi Amazon RDS.
Replika lag dan cluster Multi-AZ DB
Kelambatan replika adalah selisih waktu antara transaksi terbaru pada instans basis data penulis dan transaksi terbaru yang diterapkan pada instans basis data pembaca. CloudWatch Metrik Amazon ReplicaLag mewakili perbedaan waktu ini. Untuk informasi selengkapnya tentang CloudWatch metrik, lihatMemantau Amazon RDS metrik dengan Amazon CloudWatch.
Meskipun cluster Multi-AZ DB memungkinkan kinerja penulisan yang tinggi, lag replika masih dapat terjadi karena sifat replikasi berbasis mesin. Karena setiap failover harus menyelesaikan dahulu kelambatan replika sebelum mempromosikan instans basis data penulis baru, memantau dan mengelola kelambatan replika ini menjadi sebuah pertimbangan.
Untuk RDS untuk kluster DB Multi-AZ MySQL, waktu failover bergantung pada lag replika dari kedua instans DB pembaca yang tersisa. Kedua instans basis data pembaca harus menerapkan transaksi yang belum diterapkan sebelum salah satunya dipromosikan menjadi instans basis data penulis baru.
Untuk klaster RDS untuk Multi-AZ PostgreSQL DB, waktu failover bergantung pada lag replika terendah dari dua instance DB pembaca yang tersisa. Instans basis data pembaca dengan kelambatan replika terendah harus menerapkan transaksi yang belum diterapkan sebelum dipromosikan menjadi instans basis data penulis baru.
Untuk tutorial yang menunjukkan cara membuat CloudWatch alarm saat lag replika melebihi jumlah waktu yang ditentukan, lihatTutorial: Membuat CloudWatch alarm Amazon untuk lag replika cluster Multi-AZ DB untuk Amazon RDS.
Penyebab umum kelambatan replika
Secara umum, kelambatan replika terjadi ketika beban kerja tulis terlalu tinggi bagi instans basis data pembaca untuk menerapkan transaksi dengan efisien. Berbagai beban kerja dapat menimbulkan kelambatan replika sementara atau sinambung. Berikut beberapa contoh penyebab umum:
-
Konkurensi tulis tinggi atau pembaruan tumpak/batch berat pada instans basis data penulis, menyebabkan proses penerapan pada instans basis data pembaca tertinggal.
-
Beban kerja baca berat yang menggunakan sumber daya pada satu atau beberapa instans basis data pembaca. Menjalankan kueri yang lambat atau besar dapat memengaruhi proses penerapan dan dapat menyebabkan kelambatan replika.
-
Transaksi yang mengubah sejumlah besar data atau pernyataan DDL terkadang dapat menyebabkan kenaikan sementara kelambatan replika karena basis data harus menjaga urutan commit.
Mengurangi kelambatan replika
Untuk cluster Multi-AZ DB untuk RDS untuk MySQL dan RDS untuk PostgreSQL, Anda dapat mengurangi lag replika dengan mengurangi beban pada instance DB penulis Anda. Anda juga dapat menggunakan kontrol aliran untuk mengurangi kelambatan replika. Kontrol aliran bekerja dengan melakukan throttling operasi tulis pada instans basis data penulis, yang memastikan bahwa kelambatan replika tidak terus tumbuh tanpa batas. Throttling tulis dilakukan dengan menambahkan penundaan ke akhir transaksi, yang mengurangi throughput tulis pada instans basis data penulis. Meskipun tidak menjamin hilangnya kelambatan, kontrol aliran dapat membantu mengurangi kelambatan keseluruhan dalam banyak beban kerja. Bagian-bagian berikut memberikan informasi tentang cara menggunakan kontrol aliran dengan RDS for MySQL dan RDS for PostgreSQL.
Mengurangi kelambatan replika dengan kontrol aliran untuk RDS for MySQL
Saat Anda menggunakan RDS untuk cluster Multi-AZ MySQL DB, kontrol aliran diaktifkan secara default menggunakan parameter dinamis. rpl_semi_sync_master_target_apply_lag Parameter ini menentukan batas atas yang Anda inginkan untuk kelambatan replika. Saat kelambatan replika mendekati batas yang dikonfigurasikan ini, kontrol aliran membatasi transaksi tulis pada instans basis data penulis untuk mencoba mempertahankan kelambatan replika di bawah nilai yang ditentukan. Dalam beberapa kasus, kelambatan replika dapat melebihi batas yang ditentukan. Secara default, parameter ini diatur ke 120 detik. Untuk mematikan kontrol aliran, atur parameter ini ke nilai maksimumnya 86.400 detik (satu hari).
Untuk melihat penundaan saat ini yang disuntikkan oleh kontrol aliran, tampilkan parameter Rpl_semi_sync_master_flow_control_current_delay dengan menjalankan kueri berikut.
SHOW GLOBAL STATUS like '%flow_control%';
Output-nya semestinya mirip dengan yang berikut.
+-------------------------------------------------+-------+
| Variable_name | Value |
+-------------------------------------------------+-------+
| Rpl_semi_sync_master_flow_control_current_delay | 2010 |
+-------------------------------------------------+-------+
1 row in set (0.00 sec)catatan
Penundaan ditampilkan dalam mikrodetik.
Jika Performance Insights diaktifkan untuk klaster Multi-AZ DB RDS untuk MySQL, Anda dapat memantau peristiwa tunggu yang sesuai dengan pernyataan SQL yang menunjukkan bahwa kueri ditunda oleh kontrol aliran. Saat penundaan dikenakan oleh kontrol aliran, Anda dapat melihat peristiwa tunggu /wait/synch/cond/semisync/semi_sync_flow_control_delay_cond yang bersangkutan dengan pernyataan SQL itu di dasbor Wawasan Performa. Untuk melihat semua metrik ini, pastikan bahwa Skema Performa diaktifkan. Lihat informasi tentang Wawasan Performa di Memantau beban DB dengan Performance Insights aktif Amazon RDS.
Mengurangi kelambatan replika dengan kontrol aliran untuk RDS for PostgreSQL
Saat Anda menggunakan RDS untuk cluster Multi-AZ PostgreSQL DB, kontrol aliran digunakan sebagai ekstensi. Kontrol mengaktifkan pekerja latar belakang untuk semua instans basis data dalam klaster basis data. Secara default, pekerja latar belakang pada instans basis data pembaca mengomunikasikan kelambatan replika saat ini dengan pekerja latar belakang pada instans basis data penulis. Jika kelambatan melebihi dua menit pada sebarang instans basis data pembaca, pekerja latar belakang pada instans basis data penulis menambahkan penundaan di akhir transaksi. Untuk mengendalikan ambang batas kelambatan, gunakan parameter flow_control.target_standby_apply_lag.
Saat kontrol aliran membatasi proses PostgreSQL, peristiwa tunggu Extension di pg_stat_activity dan Wawasan Performa menunjukkan hal itu. Fungsi get_flow_control_stats menampilkan detail lama penundaan yang saat ini ditambahkan.
Kontrol aliran dapat menguntungkan sebagian besar beban kerja pemrosesan transaksi online (OLTP) yang memiliki transaksi singkat tetapi sangat konkuren. Jika kelambatan disebabkan oleh transaksi yang berjalan lama, seperti operasi tumpak/batch, kontrol aliran tidak memberikan manfaat yang sama besarnya.
Anda dapat mematikan kontrol aliran dengan menghapus ekstensi dari shared_preload_libraries dan mem-boot ulang instans basis data Anda.
Multi-AZ Cuplikan cluster DB
Amazon RDS membuat dan menyimpan cadangan otomatis cluster Multi-AZ DB Anda selama jendela pencadangan yang dikonfigurasi. RDS membuat snapshot volume penyimpanan cluster DB Anda, mencadangkan seluruh cluster dan bukan hanya instance individual.
Anda juga dapat mengambil backup manual dari cluster Multi-AZ DB Anda. Untuk pencadangan jangka panjang, pertimbangkan untuk mengekspor data snapshot ke Amazon S3. Untuk informasi selengkapnya, lihat Membuat snapshot cluster Multi-AZ DB untuk Amazon RDS.
Anda dapat mengembalikan cluster Multi-AZ DB ke titik waktu tertentu, membuat cluster Multi-AZ DB baru. Untuk petunjuk, lihat Memulihkan cluster Multi-AZ DB ke waktu tertentu.
Sebagai alternatif, Anda dapat memulihkan snapshot cluster Multi-AZ DB ke Single-AZ penerapan atau Multi-AZ penerapan instans DB. Untuk petunjuk, lihat Memulihkan dari snapshot cluster Multi-AZ DB ke instans DB.
