Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Mengonversi proses ETL ke dalam AWS Glue AWS Schema Conversion Tool
Berikut ini, Anda dapat menemukan garis besar proses untuk mengonversi skrip ETL ke with. AWS Glue AWS SCT Untuk contoh ini, kami mengonversi database Oracle ke Amazon Redshift, bersama dengan proses ETL yang digunakan dengan database sumber dan gudang data.
Topik
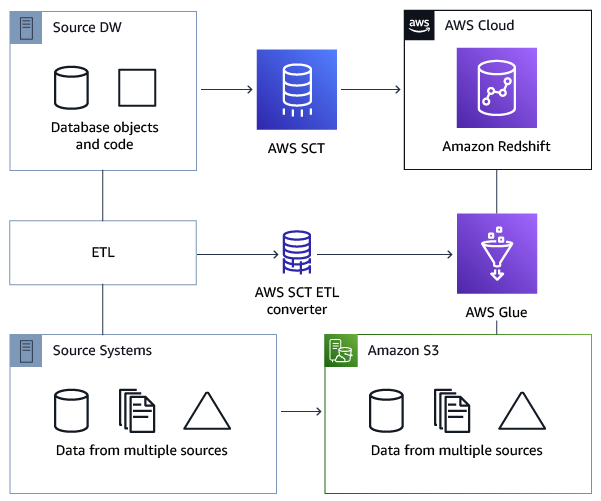
Diagram arsitektur berikut menunjukkan contoh proyek migrasi database yang mencakup konversi skrip ETL ke. AWS Glue
Prasyarat
Sebelum memulai, lakukan hal berikut:
-
Migrasikan database sumber apa pun yang ingin Anda migrasikan. AWS
-
Migrasikan gudang data target ke. AWS
-
Kumpulkan daftar semua kode yang terlibat dalam proses ETL Anda.
-
Kumpulkan daftar semua informasi koneksi yang diperlukan untuk setiap database.
Selain itu, AWS Glue perlu izin untuk mengakses AWS sumber daya lain atas nama Anda. Anda memberikan izin tersebut dengan menggunakan AWS Identity and Access Management (IAM). Pastikan Anda membuat kebijakan IAM untuk AWS Glue. Untuk informasi selengkapnya, lihat Membuat kebijakan IAM untuk AWS Glueservice di Panduan Pengembang.AWS Glue
Memahami Katalog AWS Glue Data
Sebagai bagian dari proses konversi, AWS Glue memuat informasi mengenai sumber dan basis data target. Ini mengatur informasi ini ke dalam kategori, dalam struktur yang disebut pohon. Strukturnya meliputi:
-
Koneksi - Parameter koneksi
-
Crawler — Daftar crawler, satu crawler untuk setiap skema
-
Database — Wadah yang menampung tabel
-
Tabel — Definisi metadata yang mewakili data dalam tabel
-
Pekerjaan ETL — Logika bisnis yang melakukan pekerjaan ETL
-
Pemicu — Logika yang mengontrol kapan pekerjaan ETL berjalan AWS Glue (baik sesuai permintaan, berdasarkan jadwal, atau dipicu oleh peristiwa pekerjaan)
Katalog AWS Glue Data adalah indeks lokasi, skema, dan metrik runtime data Anda. Saat Anda bekerja dengan AWS Glue dan AWS SCT, Katalog AWS Glue Data berisi referensi ke data yang digunakan sebagai sumber dan target pekerjaan ETL Anda. AWS Glue Untuk membuat gudang data Anda, katalogkan data ini.
Anda menggunakan informasi dalam Katalog Data untuk membuat dan memantau tugas ETL Anda. Biasanya, Anda menjalankan crawler untuk mengambil inventaris data di penyimpanan data Anda, tetapi ada cara lain untuk menambahkan tabel metadata ke dalam Katalog Data Anda.
Saat Anda menentukan tabel di Katalog Data, Anda menambahkannya ke database. Database digunakan untuk mengatur tabel di AWS Glue.
Batasan untuk mengonversi menggunakan dengan AWS SCT AWS Glue
Batasan berikut berlaku saat mengonversi menggunakan AWS SCT dengan AWS Glue.
| Sumber Daya | Batas default |
| Jumlah database untuk setiap akun | 10.000 |
| Jumlah tabel untuk setiap database | 100.000 |
| Jumlah partisi untuk setiap tabel | 1.000.000 |
| Jumlah versi tabel untuk setiap tabel | 100.000 |
| Jumlah tabel untuk setiap akun | 1.000.000 |
| Jumlah partisi untuk setiap akun | 10.000.000 |
| Jumlah versi tabel untuk setiap akun | 1.000.000 |
| Jumlah koneksi untuk setiap akun | 1.000 |
| Jumlah crawler untuk setiap akun | 25 |
| Jumlah pekerjaan untuk setiap akun | 25 |
| Jumlah pemicu untuk setiap akun | 25 |
| Jumlah pekerjaan bersamaan yang dijalankan untuk setiap akun | 30 |
| Jumlah pekerjaan bersamaan yang dijalankan untuk setiap pekerjaan | 3 |
| Jumlah pekerjaan untuk setiap pemicu | 10 |
| Jumlah titik akhir pengembangan untuk setiap akun | 5 |
| Unit pemrosesan data maksimum (DPUs) yang digunakan oleh titik akhir pengembangan pada satu waktu | 5 |
| Maksimal DPUs digunakan oleh peran pada satu waktu | 100 |
| Panjang nama basis data |
Tidak terbatas. Untuk kompatibilitas dengan toko metadata lainnya, seperti Apache Hive, namanya diubah untuk menggunakan karakter huruf kecil. Jika Anda berencana untuk mengakses database dari Amazon Athena, berikan nama dengan hanya karakter alfanumerik dan garis bawah. |
| Panjang nama koneksi | Tidak terbatas. |
| Panjang nama crawler | Tidak terbatas. |
Langkah 1: Buat proyek baru
Untuk membuat proyek baru, ambil langkah-langkah tingkat tinggi ini:
-
Buat proyek baru di AWS SCT. Untuk informasi selengkapnya, lihat Memulai dan mengelola Proyek di AWS SCT.
-
Tambahkan basis data sumber dan target Anda ke proyek. Untuk informasi selengkapnya, lihat Menambahkan server ke proyek di AWS SCT.
Pastikan bahwa Anda telah memilih Gunakan AWS Glue dalam pengaturan koneksi database target. Untuk melakukannya, pilih AWS Gluetab. Untuk Salin dari AWS profil, pilih profil yang ingin Anda gunakan. Profil harus secara otomatis mengisi kunci AWS akses, kunci rahasia, dan folder bucket Amazon S3. Jika tidak, masukkan informasi ini sendiri. Setelah Anda memilih OK, AWS Glue menganalisis objek dan memuat metadata ke dalam Katalog Data. AWS Glue
Bergantung pada pengaturan keamanan Anda, Anda mungkin mendapatkan pesan peringatan yang mengatakan akun Anda tidak memiliki hak istimewa yang memadai untuk beberapa skema di server. Jika Anda memiliki akses ke skema yang Anda gunakan, Anda dapat mengabaikan pesan ini dengan aman.
-
Untuk menyelesaikan persiapan mengimpor ETL Anda, sambungkan ke basis data sumber dan target Anda. Untuk melakukannya, pilih database Anda di pohon metadata sumber atau target, lalu pilih Connect to the server.
AWS Glue membuat database di server database sumber dan satu di server database target untuk membantu konversi ETL. Database pada server target berisi Katalog AWS Glue Data. Untuk menemukan objek tertentu, gunakan pencarian pada sumber atau panel target.
Untuk melihat bagaimana objek tertentu mengonversi, cari item yang ingin Anda konversi, dan pilih Konversi skema dari menu konteksnya (klik kanan). AWS SCT mengubah objek yang dipilih ini menjadi skrip.
Anda dapat meninjau skrip yang dikonversi dari folder Scripts di panel kanan. Saat ini, skrip adalah objek virtual, yang hanya tersedia sebagai bagian dari AWS SCT proyek Anda.
Untuk membuat AWS Glue pekerjaan dengan skrip yang dikonversi, unggah skrip Anda ke Amazon S3. Untuk mengunggah skrip ke Amazon S3, pilih skrip, lalu pilih Simpan ke S3 dari menu konteksnya (klik kanan).
Langkah 2: Buat AWS Glue pekerjaan
Setelah Anda menyimpan skrip ke Amazon S3, Anda dapat memilihnya dan kemudian memilih Configure AWS Glue Job untuk membuka wizard untuk mengonfigurasi pekerjaan. AWS Glue Wizard membuatnya lebih mudah untuk mengatur ini:
-
Pada tab pertama wizard, Design Data Flow, Anda dapat memilih strategi eksekusi dan daftar skrip yang ingin Anda sertakan dalam pekerjaan yang satu ini. Anda dapat memilih parameter untuk setiap skrip. Anda juga dapat mengatur ulang skrip sehingga mereka berjalan dalam urutan yang benar.
-
Pada tab kedua, Anda dapat memberi nama pekerjaan Anda, dan langsung mengonfigurasi pengaturan untuk AWS Glue. Di layar ini, Anda dapat mengonfigurasi pengaturan berikut:
-
AWS Identity and Access Management Peran (IAM)
-
Nama file skrip dan jalur file
-
Enkripsi skrip menggunakan enkripsi sisi server dengan kunci yang dikelola Amazon S3 (SSE-S3)
-
Direktori sementara
-
Jalur pustaka Python yang dihasilkan
-
Jalur pustaka Python pengguna
-
Jalur untuk file.jar yang bergantung
-
Path file yang direferensikan
-
Bersamaan DPUs untuk setiap pekerjaan yang dijalankan
-
Konkurensi maksimum
-
Batas waktu kerja (dalam hitungan menit)
-
Ambang batas pemberitahuan tunda (dalam hitungan menit)
-
Jumlah percobaan
-
Konfigurasi keamanan
-
enkripsi di sisi server
-
-
Pada langkah ketiga, atau tab, Anda memilih koneksi yang dikonfigurasi ke titik akhir target.
Setelah Anda selesai mengkonfigurasi pekerjaan, itu akan ditampilkan di bawah pekerjaan ETL di Katalog AWS Glue Data. Jika Anda memilih pekerjaan, pengaturan akan ditampilkan sehingga Anda dapat meninjau atau mengeditnya. Untuk membuat pekerjaan baru AWS Glue, pilih Create AWS Glue Job dari menu konteks (klik kanan) untuk pekerjaan tersebut. Melakukan hal ini menerapkan definisi skema. Untuk menyegarkan tampilan, pilih Refresh dari database dari menu konteks (klik kanan).
Pada titik ini, Anda dapat melihat pekerjaan Anda di AWS Glue konsol. Untuk melakukannya, masuk ke AWS Management Console dan buka AWS Glue konsol di https://console.aws.amazon.com/glue/
Anda dapat menguji pekerjaan baru untuk memastikan bahwa itu berfungsi dengan benar. Untuk melakukannya, pertama-tama periksa data di tabel sumber Anda, lalu verifikasi bahwa tabel target kosong. Jalankan pekerjaan, dan periksa lagi. Anda dapat melihat log kesalahan dari AWS Glue konsol.
