Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Memigrasi data dari gudang data lokal ke Amazon Redshift dengan AWS Schema Conversion Tool
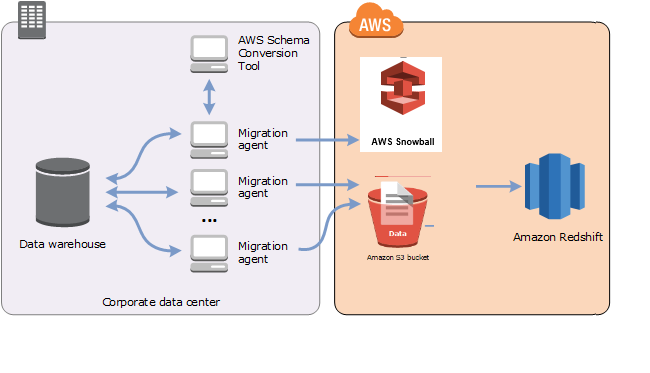
Anda dapat menggunakan AWS SCT agen untuk mengekstrak data dari gudang data lokal dan memigrasikannya ke Amazon Redshift. Agen mengekstrak data Anda dan mengunggah data ke Amazon S3 atau, untuk migrasi skala besar, perangkat Edge. AWS Snowball Edge Anda kemudian dapat menggunakan AWS SCT agen untuk menyalin data ke Amazon Redshift.
Atau, Anda dapat menggunakan AWS Database Migration Service (AWS DMS) untuk memigrasikan data ke Amazon Redshift. AWS DMS Keuntungannya adalah dukungan replikasi yang sedang berlangsung (perubahan pengambilan data). Namun, untuk meningkatkan kecepatan migrasi data, gunakan beberapa AWS SCT agen secara paralel. Menurut pengujian kami, AWS SCT agen memigrasikan data lebih cepat daripada AWS DMS 15-35 persen. Perbedaan kecepatan adalah karena kompresi data, dukungan migrasi partisi tabel secara paralel, dan pengaturan konfigurasi yang berbeda. Untuk informasi selengkapnya, lihat Menggunakan database Amazon Redshift sebagai target. AWS Database Migration Service
Amazon S3 adalah layanan penyimpanan dan pengambilan. Untuk menyimpan objek di Amazon S3, Anda mengunggah file yang ingin Anda simpan ke bucket Amazon S3. Saat Anda mengunggah file, Anda dapat mengatur izin pada objek dan juga pada metadata apa pun.
Migrasi skala besar
Migrasi data skala besar dapat mencakup banyak terabyte informasi, dan dapat diperlambat oleh kinerja jaringan dan oleh banyaknya data yang harus dipindahkan. AWS Snowball Edge Edge adalah AWS layanan yang dapat Anda gunakan untuk mentransfer data ke cloud dengan faster-than-network kecepatan menggunakan alat yang AWS dimiliki. Perangkat AWS Snowball Edge Edge dapat menampung hingga 100 TB data. Menggunakan enkripsi 256-bit dan Trusted Platform Module (TPM) standar industri untuk memastikan keamanan dan penuh untuk data Anda. chain-of-custody AWS SCT bekerja dengan perangkat AWS Snowball Edge Edge.
Saat Anda menggunakan AWS SCT dan perangkat AWS Snowball Edge Edge, Anda memigrasikan data dalam dua tahap. Pertama, Anda gunakan AWS SCT untuk memproses data secara lokal dan kemudian memindahkan data itu ke perangkat AWS Snowball Edge Edge. Anda kemudian mengirim perangkat untuk AWS menggunakan proses AWS Snowball Edge Edge, dan kemudian AWS secara otomatis memuat data ke dalam bucket Amazon S3. Selanjutnya, ketika data tersedia di Amazon S3, Anda gunakan AWS SCT untuk memigrasikan data ke Amazon Redshift. Agen ekstraksi data dapat bekerja di latar belakang saat AWS SCT ditutup.
Diagram berikut menunjukkan skenario yang didukung.
Agen ekstraksi data saat ini didukung untuk gudang data sumber berikut:
Analisis Sinaps Azure
BigQuery
Database Greenplum (versi 4.3)
Microsoft SQL Server (versi 2008 dan lebih tinggi)
Netezza (versi 7.0.3 dan lebih tinggi)
Oracle (versi 10 dan lebih tinggi)
Kepingan salju (versi 3)
Teradata (versi 13 dan lebih tinggi)
Vertica (versi 7.2.2 dan lebih tinggi)
Anda dapat terhubung ke titik akhir FIPS untuk Amazon Redshift jika Anda perlu mematuhi persyaratan keamanan Federal Information Processing Standard (FIPS). Titik akhir FIPS tersedia di Wilayah berikut: AWS
Wilayah AS Timur (Virginia N.) (redshift-fips.us-east-1.amazonaws.com)
Wilayah Timur AS (Ohio) (redshift-fips.us-east-2.amazonaws.com)
Wilayah AS Barat (California Utara) (redshift-fips.us-west-1.amazonaws.com)
Wilayah Barat AS (Oregon) (redshift-fips.us-west-2.amazonaws.com)
Gunakan informasi dalam topik berikut untuk mempelajari cara bekerja dengan agen ekstraksi data.
Topik
Mendaftarkan agen ekstraksi dengan AWS Schema Conversion Tool
Mengubah pengaturan ekstraktor dan salin dari pengaturan proyek
Membuat, menjalankan, dan memantau tugas ekstraksi AWS SCT data
Menggunakan partisi virtual dengan AWS Schema Conversion Tool
Praktik terbaik dan pemecahan masalah untuk agen ekstraksi data
Prasyarat untuk menggunakan agen ekstraksi data
Sebelum Anda bekerja dengan agen ekstraksi data, tambahkan izin yang diperlukan untuk Amazon Redshift sebagai target ke pengguna Amazon Redshift Anda. Untuk informasi selengkapnya, lihat Izin untuk Amazon Redshift sebagai target.
Kemudian, simpan informasi bucket Amazon S3 Anda dan siapkan kepercayaan dan penyimpanan kunci Secure Sockets Layer (SSL) Anda.
Pengaturan Amazon S3
Setelah agen Anda mengekstrak data Anda, mereka mengunggahnya ke bucket Amazon S3 Anda. Sebelum melanjutkan, Anda harus memberikan kredensil untuk terhubung ke AWS akun Anda dan bucket Amazon S3 Anda. Anda menyimpan kredensi dan informasi bucket Anda di profil di pengaturan aplikasi global, lalu mengaitkan profil dengan proyek Anda AWS SCT . Jika perlu, pilih Pengaturan global untuk membuat profil baru. Untuk informasi selengkapnya, lihat Mengelola Profil di AWS Schema Conversion Tool.
Untuk memigrasikan data ke database Amazon Redshift target, AWS SCT agen ekstraksi data memerlukan izin untuk mengakses bucket Amazon S3 atas nama Anda. Untuk memberikan izin ini, buat pengguna AWS Identity and Access Management (IAM) dengan kebijakan berikut.
Pada contoh sebelumnya, ganti bucket_name111122223333:user/DataExtractionAgentName
Dengan asumsi peran IAM
Untuk keamanan tambahan, Anda dapat menggunakan peran AWS Identity and Access Management (IAM) untuk mengakses bucket Amazon S3. Untuk melakukannya, buat pengguna IAM untuk agen ekstraksi data Anda tanpa izin apa pun. Kemudian, buat peran IAM yang memungkinkan akses Amazon S3, dan tentukan daftar layanan dan pengguna yang dapat mengambil peran ini. Untuk informasi selengkapnya, lihat peran IAM dalam Panduan Pengguna IAM.
Untuk mengonfigurasi peran IAM untuk mengakses bucket Amazon S3 Anda
-
Buat pengguna IAM baru. Untuk kredensi pengguna, pilih Jenis akses terprogram.
-
Konfigurasikan lingkungan host sehingga agen ekstraksi data Anda dapat mengambil peran yang AWS SCT menyediakan. Pastikan bahwa pengguna yang Anda konfigurasikan pada langkah sebelumnya memungkinkan agen ekstraksi data untuk menggunakan rantai penyedia kredensi. Untuk informasi selengkapnya, lihat Menggunakan kredensil di Panduan AWS SDK untuk Java Pengembang.
-
Buat peran IAM baru yang memiliki akses ke bucket Amazon S3 Anda.
-
Ubah bagian kepercayaan dari peran ini untuk mempercayai pengguna yang Anda buat sebelumnya untuk mengambil peran tersebut. Dalam contoh berikut, ganti
111122223333:user/DataExtractionAgentName{ "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::111122223333:user/DataExtractionAgentName" }, "Action": "sts:AssumeRole" } -
Ubah bagian kepercayaan dari peran ini menjadi kepercayaan
redshift.amazonaws.com.rproxy.goskope.comuntuk mengambil peran.{ "Effect": "Allow", "Principal": { "Service": [ "redshift.amazonaws.com" ] }, "Action": "sts:AssumeRole" } -
Lampirkan peran ini ke cluster Amazon Redshift Anda.
Sekarang, Anda dapat menjalankan agen ekstraksi data Anda di AWS SCT.
Bila Anda menggunakan asumsi peran IAM, migrasi data berfungsi dengan cara berikut. Agen ekstraksi data memulai dan mendapatkan kredensil pengguna menggunakan rantai penyedia kredensi. Selanjutnya, Anda membuat tugas migrasi data di AWS SCT, lalu tentukan peran IAM untuk diasumsikan oleh agen ekstraksi data, dan memulai tugas. AWS Security Token Service (AWS STS) menghasilkan kredensil sementara untuk mengakses Amazon S3. Agen ekstraksi data menggunakan kredensil ini untuk mengunggah data ke Amazon S3.
Kemudian, AWS SCT berikan Amazon Redshift dengan peran IAM. Pada gilirannya, Amazon Redshift mendapatkan kredensi sementara baru dari untuk mengakses AWS STS Amazon S3. Amazon Redshift menggunakan kredensil ini untuk menyalin data dari Amazon S3 ke tabel Amazon Redshift Anda.
Pengaturan keamanan
Agen ekstraksi AWS Schema Conversion Tool dan ekstraksi dapat berkomunikasi melalui Secure Sockets Layer (SSL). Untuk mengaktifkan SSL, siapkan toko kepercayaan dan toko kunci.
Untuk mengatur komunikasi yang aman dengan agen ekstraksi Anda
-
Mulai AWS Schema Conversion Tool.
-
Buka menu Pengaturan, lalu pilih Pengaturan global. Kotak dialog Pengaturan global muncul.
-
Pilih Keamanan.
-
Pilih Hasilkan kepercayaan dan toko kunci, atau pilih Pilih toko kepercayaan yang ada.
Jika Anda memilih Hasilkan kepercayaan dan penyimpanan kunci, Anda kemudian menentukan nama dan kata sandi untuk kepercayaan dan penyimpanan kunci, dan jalur ke lokasi untuk file yang dihasilkan. Anda menggunakan file-file ini di langkah selanjutnya.
Jika Anda memilih Pilih toko kepercayaan yang ada, Anda kemudian menentukan kata sandi dan nama file untuk kepercayaan dan penyimpanan kunci. Anda menggunakan file-file ini di langkah selanjutnya.
-
Setelah Anda menentukan toko kepercayaan dan toko kunci, pilih OK untuk menutup kotak dialog Pengaturan global.
Mengkonfigurasi lingkungan untuk agen ekstraksi data
Anda dapat menginstal beberapa agen ekstraksi data pada satu host. Namun, kami menyarankan Anda menjalankan satu agen ekstraksi data pada satu host.
Untuk menjalankan agen ekstraksi data Anda, pastikan Anda menggunakan host dengan setidaknya empat memori v CPUs dan 32 GB. Juga, atur memori minimum yang tersedia AWS SCT untuk setidaknya empat GB. Untuk informasi selengkapnya, lihat Mengkonfigurasi memori tambahan.
Konfigurasi optimal dan jumlah host agen tergantung pada situasi spesifik setiap pelanggan. Pastikan Anda mempertimbangkan faktor-faktor seperti jumlah data yang akan dimigrasi, bandwidth jaringan, waktu untuk mengekstrak data, dan sebagainya. Anda dapat melakukan bukti konsep (PoC) terlebih dahulu, dan kemudian mengkonfigurasi agen ekstraksi data dan host Anda sesuai dengan hasil PoC ini.
Instalasi agen ekstraksi
Kami menyarankan Anda menginstal beberapa agen ekstraksi pada komputer individu, terpisah dari komputer yang menjalankan AWS Schema Conversion Tool.
Agen ekstraksi saat ini didukung pada sistem operasi berikut:
Microsoft Windows
Perusahaan Topi Merah Linux (RHEL) 6.0
Ubuntu Linux (versi 14.04 dan lebih tinggi)
Gunakan prosedur berikut untuk menginstal agen ekstraksi. Ulangi prosedur ini untuk setiap komputer tempat Anda ingin menginstal agen ekstraksi.
Untuk memasang agen ekstraksi
-
Jika Anda belum mengunduh file AWS SCT penginstal, ikuti instruksi di Instalasi dan Konfigurasi AWS Schema Conversion Tool untuk mengunduhnya. File.zip yang berisi file AWS SCT installer juga berisi file installer agen ekstraksi.
-
Unduh dan instal versi terbaru Amazon Corretto 11. Untuk informasi selengkapnya, lihat Unduhan untuk Amazon Corretto 11 di Panduan Pengguna Amazon Corretto 11.
-
Temukan file penginstal untuk agen ekstraksi Anda di subfolder bernama agen. Untuk setiap sistem operasi komputer, file yang benar untuk menginstal agen ekstraksi ditunjukkan sebagai berikut.
Sistem operasi Nama file Microsoft Windows
aws-schema-conversion-tool-extractor-2.0.1.build-number.msiRHEL
aws-schema-conversion-tool-extractor-2.0.1.build-number.x86_64.rpmUbuntu Linux
aws-schema-conversion-tool-extractor-2.0.1.build-number.deb -
Instal agen ekstraksi pada komputer terpisah dengan menyalin file penginstal ke komputer baru.
-
Jalankan file installer. Gunakan instruksi untuk sistem operasi Anda, yang ditunjukkan berikut.
Sistem operasi Petunjuk pemasangan Microsoft Windows
Klik dua kali file untuk menjalankan penginstal.
RHEL
Jalankan perintah berikut di folder yang Anda unduh atau pindahkan file.
sudo rpm -ivh aws-schema-conversion-tool-extractor-2.0.1.build-number.x86_64.rpm sudo ./sct-extractor-setup.sh --configUbuntu Linux
Jalankan perintah berikut di folder yang Anda unduh atau pindahkan file.
sudo dpkg -i aws-schema-conversion-tool-extractor-2.0.1.build-number.deb sudo ./sct-extractor-setup.sh --config -
Pilih Berikutnya, terima perjanjian lisensi, dan pilih Berikutnya.
-
Masukkan jalur untuk menginstal agen ekstraksi AWS SCT data, dan pilih Berikutnya.
-
Pilih Instal untuk menginstal agen ekstraksi data Anda.
AWS SCT menginstal agen ekstraksi data Anda. Untuk menyelesaikan instalasi, konfigurasikan agen ekstraksi data Anda. AWS SCT secara otomatis meluncurkan program pengaturan konfigurasi. Untuk informasi selengkapnya, lihat Mengkonfigurasi agen ekstraksi.
-
Pilih Selesai untuk menutup wizard instalasi setelah Anda mengonfigurasi agen ekstraksi data Anda.
Mengkonfigurasi agen ekstraksi
Gunakan prosedur berikut untuk mengkonfigurasi agen ekstraksi. Ulangi prosedur ini di setiap komputer yang memiliki agen ekstraksi terpasang.
Untuk mengkonfigurasi agen ekstraksi Anda
-
Luncurkan program pengaturan konfigurasi:
-
Di Windows, AWS SCT meluncurkan program pengaturan konfigurasi secara otomatis selama instalasi agen ekstraksi data.
Sesuai kebutuhan, Anda dapat meluncurkan program pengaturan secara manual. Untuk melakukannya, jalankan
ConfigAgent.batfile di Windows. Anda dapat menemukan file ini di folder tempat Anda menginstal agen. -
Di RHEL dan Ubuntu, jalankan
sct-extractor-setup.shfile dari lokasi tempat Anda menginstal agen.
Program pengaturan meminta Anda untuk informasi. Untuk setiap prompt, nilai default muncul.
-
-
Terima nilai default pada setiap prompt, atau masukkan nilai baru.
Tentukan informasi berikut:
Untuk port Listening, masukkan nomor port yang didengarkan agen.
Untuk Tambahkan vendor sumber, masukkan ya, lalu masukkan platform gudang data sumber Anda.
Untuk driver JDBC, masukkan lokasi tempat Anda menginstal driver JDBC.
Untuk folder Kerja, masukkan jalur tempat agen ekstraksi AWS SCT data akan menyimpan data yang diekstraksi. Folder kerja dapat berada di komputer yang berbeda dari agen, dan satu folder kerja dapat dibagikan oleh beberapa agen di komputer yang berbeda.
Untuk Aktifkan komunikasi SSL, masukkan ya.
Untuk Key Store, masukkan lokasi file penyimpanan kunci.
Untuk kata sandi Key Store, masukkan kata sandi untuk toko kunci.
Untuk Aktifkan otentikasi SSL klien, masukkan ya.
Untuk Trust store, masukkan lokasi file trust store.
Untuk kata sandi toko Trust, masukkan kata sandi untuk toko kepercayaan.
Program pengaturan memperbarui file pengaturan untuk agen ekstraksi. File pengaturan diberi namasettings.properties, dan terletak di mana Anda menginstal agen ekstraksi.
Berikut ini adalah contoh file pengaturan.
$ cat settings.properties
#extractor.start.fetch.size=20000
#extractor.out.file.size=10485760
#extractor.source.connection.pool.size=20
#extractor.source.connection.pool.min.evictable.idle.time.millis=30000
#extractor.extracting.thread.pool.size=10
vendor=TERADATA
driver.jars=/usr/share/lib/jdbc/terajdbc4.jar
port=8192
redshift.driver.jars=/usr/share/lib/jdbc/RedshiftJDBC42-1.2.43.1067.jar
working.folder=/data/sct
extractor.private.folder=/home/ubuntu
ssl.option=OFFUntuk mengubah pengaturan konfigurasi, Anda dapat mengedit settings.properties file menggunakan editor teks atau menjalankan konfigurasi agen lagi.
Memasang dan mengonfigurasi agen ekstraksi dengan agen penyalinan khusus
Anda dapat menginstal agen ekstraksi dalam konfigurasi yang memiliki penyimpanan bersama dan agen penyalinan khusus. Diagram berikut menggambarkan skenario ini.
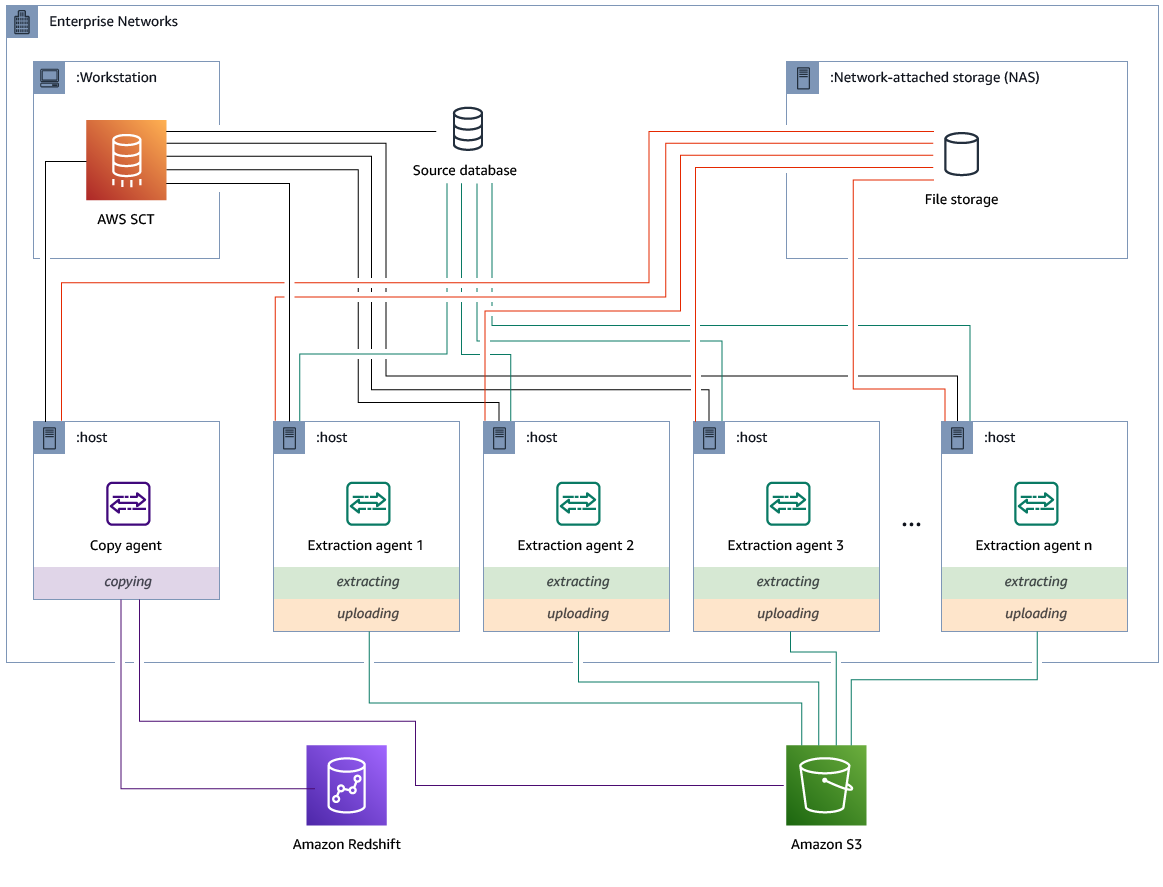
Konfigurasi itu dapat berguna ketika server basis data sumber mendukung hingga 120 koneksi, dan jaringan Anda memiliki penyimpanan yang cukup. Gunakan prosedur berikut untuk mengonfigurasi agen ekstraksi yang memiliki agen penyalinan khusus.
Untuk menginstal dan mengkonfigurasi agen ekstraksi dan agen penyalinan khusus
-
Pastikan bahwa direktori kerja semua agen ekstraksi menggunakan folder yang sama pada penyimpanan bersama.
-
Instal agen ekstraktor dengan mengikuti langkah-langkah diInstalasi agen ekstraksi.
-
Konfigurasikan agen ekstraksi dengan mengikuti langkah-langkahMengkonfigurasi agen ekstraksi, tetapi tentukan hanya driver JDBC sumber.
-
Konfigurasikan agen penyalinan khusus dengan mengikuti langkah-langkahnyaMengkonfigurasi agen ekstraksi, tetapi tentukan hanya driver Amazon Redshift JDBC.
Memulai agen ekstraksi
Gunakan prosedur berikut untuk memulai agen ekstraksi. Ulangi prosedur ini di setiap komputer yang memiliki agen ekstraksi terpasang.
Agen ekstraksi bertindak sebagai pendengar. Ketika Anda memulai agen dengan prosedur ini, agen mulai mendengarkan instruksi. Anda mengirim instruksi agen untuk mengekstrak data dari gudang data Anda di bagian selanjutnya.
Untuk memulai agen ekstraksi Anda
-
Pada komputer yang memiliki agen ekstraksi diinstal, jalankan perintah yang tercantum berikut untuk sistem operasi Anda.
Sistem operasi Mulai perintah Microsoft Windows
Klik dua kali file
StartAgent.batbatch.RHEL
Jalankan perintah berikut di jalur ke folder yang Anda instal agen:
sudo initctlstartsct-extractorUbuntu Linux
Jalankan perintah berikut di jalur ke folder yang Anda instal agen. Gunakan perintah yang sesuai untuk versi Ubuntu Anda.
Ubuntu 14.04:
sudo initctlstartsct-extractorUbuntu 15.04 dan lebih tinggi:
sudo systemctlstartsct-extractor
Untuk memeriksa status agen, jalankan perintah yang sama tetapi ganti start denganstatus.
Untuk menghentikan agen, jalankan perintah yang sama tetapi ganti start denganstop.
Mendaftarkan agen ekstraksi dengan AWS Schema Conversion Tool
Anda mengelola agen ekstraksi Anda dengan menggunakan AWS SCT. Agen ekstraksi bertindak sebagai pendengar. Ketika mereka menerima instruksi dari AWS SCT, mereka mengekstrak data dari gudang data Anda.
Gunakan prosedur berikut untuk mendaftarkan agen ekstraksi dengan AWS SCT proyek Anda.
Untuk mendaftarkan agen ekstraksi
-
Mulai AWS Schema Conversion Tool, dan buka proyek.
-
Buka menu Tampilan, lalu pilih tampilan Migrasi Data (lainnya). Tab Agen muncul. Jika Anda memiliki agen terdaftar sebelumnya AWS SCT , tampilkan mereka dalam kotak di bagian atas tab.
-
PilihPendaftaran.
Setelah Anda mendaftarkan agen dengan AWS SCT proyek, Anda tidak dapat mendaftarkan agen yang sama dengan proyek yang berbeda. Jika Anda tidak lagi menggunakan agen dalam sebuah AWS SCT proyek, Anda dapat membatalkan pendaftarannya. Anda kemudian dapat mendaftarkannya dengan proyek yang berbeda.
-
Pilih agen data Redshift, lalu pilih OK.
-
Masukkan informasi Anda pada tab Koneksi pada kotak dialog:
-
Untuk Deskripsi, masukkan deskripsi agen.
-
Untuk Nama Host, masukkan nama host atau alamat IP komputer agen.
-
Untuk Port, masukkan nomor port yang didengarkan agen.
-
Pilih Daftar untuk mendaftarkan agen dengan AWS SCT proyek Anda.
-
-
Ulangi langkah sebelumnya untuk mendaftarkan beberapa agen dengan AWS SCT proyek Anda.
Menyembunyikan dan memulihkan informasi untuk agen AWS SCT
AWS SCT Agen mengenkripsi sejumlah besar informasi, misalnya kata sandi ke toko kepercayaan kunci pengguna, akun basis data, informasi AWS akun, dan item serupa. Ia melakukannya dengan menggunakan file khusus yang disebutseed.dat. Secara default, agen membuat file ini di folder kerja pengguna yang pertama kali mengkonfigurasi agen.
Karena pengguna yang berbeda dapat mengkonfigurasi dan menjalankan agen, jalur ke seed.dat disimpan dalam {extractor.private.folder} parameter settings.properties file. Ketika agen mulai, ia dapat menggunakan jalur ini untuk menemukan seed.dat file untuk mengakses informasi penyimpanan key-trust untuk database tempat ia bertindak.
Anda mungkin perlu memulihkan kata sandi yang disimpan agen dalam kasus ini:
Jika pengguna kehilangan
seed.datfile dan lokasi serta port AWS SCT agen tidak berubah.Jika pengguna kehilangan
seed.datfile dan lokasi dan port AWS SCT agen telah berubah. Dalam hal ini, perubahan biasanya terjadi karena agen dimigrasikan ke host atau port lain dan informasi dalamseed.datfile tidak lagi valid.
Dalam kasus ini, jika agen dimulai tanpa SSL, itu dimulai dan kemudian mengakses penyimpanan agen yang dibuat sebelumnya. Kemudian pergi ke keadaan Menunggu pemulihan.
Namun, dalam kasus ini, jika agen dimulai dengan SSL, Anda tidak dapat memulai ulang. Ini karena agen tidak dapat mendekripsi kata sandi ke sertifikat yang disimpan dalam file. settings.properties Dalam jenis startup ini, agen gagal memulai. Kesalahan yang mirip dengan berikut ini ditulis dalam log: “Agen tidak dapat memulai dengan mode SSL diaktifkan. Harap konfigurasikan ulang agen. Alasan: Kata sandi untuk keystore tidak benar.”
Untuk memperbaikinya, buat agen baru dan konfigurasikan agen untuk menggunakan kata sandi yang ada untuk mengakses sertifikat SSL. Untuk melakukannya, gunakan prosedur berikut.
Setelah Anda melakukan prosedur ini, agen harus menjalankan dan pergi ke status Menunggu pemulihan. AWS SCT secara otomatis mengirimkan kata sandi yang diperlukan ke agen dalam keadaan Menunggu pemulihan. Ketika agen memiliki kata sandi, ia memulai ulang tugas apa pun. Tidak ada tindakan pengguna lebih lanjut yang diperlukan di AWS SCT samping.
Untuk mengkonfigurasi ulang agen dan mengembalikan kata sandi untuk mengakses sertifikat SSL
Instal AWS SCT agen baru dan jalankan konfigurasi.
Ubah
agent.nameproperti dalaminstance.propertiesfile menjadi nama agen tempat penyimpanan dibuat, agar agen baru bekerja dengan penyimpanan agen yang ada.instance.propertiesFile disimpan dalam folder pribadi agen, yang dinamai menggunakan konvensi berikut:{.output.folder}\dmt\{hostName}_{portNumber}\Ubah nama
{ke folder keluaran agen sebelumnya.output.folder}Pada titik ini, AWS SCT masih mencoba untuk mengakses extractor lama di host lama dan port. Akibatnya, ekstraktor yang tidak dapat diakses mendapatkan status GAGAL. Anda kemudian dapat mengubah host dan port.
Ubah host, port, atau keduanya untuk agen lama dengan menggunakan perintah Modify untuk mengarahkan aliran permintaan ke agen baru.
Ketika AWS SCT dapat melakukan ping ke agen baru, AWS SCT menerima status Menunggu pemulihan dari agen. AWS SCT kemudian secara otomatis memulihkan kata sandi untuk agen.
Setiap agen yang bekerja dengan penyimpanan agen memperbarui file khusus yang disebut storage.lck terletak di{. File ini berisi ID jaringan agen dan waktu penyimpanan terkunci. Ketika agen bekerja dengan penyimpanan agen, ia memperbarui output.folder}\{agentName}\storage\storage.lck file dan memperpanjang sewa penyimpanan dengan 10 menit setiap 5 menit. Tidak ada contoh lain yang dapat bekerja dengan penyimpanan agen ini sebelum masa sewa berakhir.
Membuat aturan migrasi data di AWS SCT
Sebelum Anda mengekstrak data Anda dengan AWS Schema Conversion Tool, Anda dapat mengatur filter yang mengurangi jumlah data yang Anda ekstrak. Anda dapat membuat aturan migrasi data menggunakan WHERE klausa untuk mengurangi data yang Anda ekstrak. Misalnya, Anda dapat menulis WHERE klausa yang memilih data dari satu tabel.
Anda dapat membuat aturan migrasi data dan menyimpan filter sebagai bagian dari proyek Anda. Dengan proyek Anda terbuka, gunakan prosedur berikut untuk membuat aturan migrasi data.
Untuk membuat aturan migrasi data
-
Buka menu Tampilan, lalu pilih tampilan Migrasi Data (lainnya).
-
Pilih Aturan migrasi data, lalu pilih Tambahkan aturan baru.
-
Konfigurasikan aturan migrasi data Anda:
-
Untuk Nama, masukkan nama untuk aturan migrasi data Anda.
-
Untuk Di mana nama skema seperti, masukkan filter untuk diterapkan ke skema. Dalam filter ini,
WHEREklausa dievaluasi dengan menggunakan klausa.LIKEUntuk memilih satu skema, masukkan nama skema yang tepat. Untuk memilih beberapa skema, gunakan karakter “%” sebagai wildcard untuk mencocokkan sejumlah karakter dalam nama skema. -
Untuk nama tabel seperti, masukkan filter untuk diterapkan ke tabel. Dalam filter ini,
WHEREklausa dievaluasi dengan menggunakan klausa.LIKEUntuk memilih satu tabel, masukkan nama yang tepat. Untuk memilih beberapa tabel, gunakan karakter “%” sebagai wildcard untuk mencocokkan sejumlah karakter dalam nama tabel. -
Untuk klausa Where, masukkan
WHEREklausa untuk memfilter data.
-
-
Setelah mengonfigurasi filter, pilih Simpan untuk menyimpan filter, atau Batalkan untuk membatalkan perubahan.
-
Setelah Anda selesai menambahkan, mengedit, dan menghapus filter, pilih Simpan semua untuk menyimpan semua perubahan Anda.
Untuk mematikan filter tanpa menghapusnya, gunakan ikon sakelar. Untuk menduplikasi filter yang ada, gunakan ikon salin. Untuk menghapus filter yang ada, gunakan ikon hapus. Untuk menyimpan perubahan apa pun yang Anda buat pada filter, pilih Simpan semua.
Mengubah pengaturan ekstraktor dan salin dari pengaturan proyek
Dari jendela Pengaturan proyek AWS SCT, Anda dapat memilih pengaturan untuk agen ekstraksi data dan perintah Amazon RedshiftCOPY.
Untuk memilih pengaturan ini, pilih Pengaturan, Pengaturan proyek, lalu pilih Migrasi data. Di sini, Anda dapat mengedit pengaturan Ekstraksi, pengaturan Amazon S3, dan pengaturan Salin.
Gunakan petunjuk dalam tabel berikut untuk memberikan informasi untuk pengaturan Ekstraksi.
| Untuk parameter ini | Lakukan hal berikut |
|---|---|
Format kompresi |
Tentukan format kompresi file input. Pilih salah satu opsi berikut: GZIP,, ZSTD BZIP2, atau Tidak ada kompresi. |
Karakter pembatas |
Tentukan karakter ASCII yang memisahkan bidang dalam file input. Karakter nonprinting tidak didukung. |
Nilai NULL sebagai string |
Aktifkan opsi ini jika data Anda menyertakan terminator null. Jika opsi ini dimatikan, |
Strategi penyortiran |
Gunakan penyortiran untuk memulai kembali ekstraksi dari titik kegagalan. Pilih salah satu strategi penyortiran berikut: Gunakan penyortiran setelah kegagalan pertama (disarankan), Gunakan penyortiran jika memungkinkan, atau Jangan pernah menggunakan penyortiran. Untuk informasi selengkapnya, lihat Menyortir data sebelum bermigrasi menggunakan AWS SCT. |
Skema suhu sumber |
Masukkan nama skema dalam database sumber, di mana agen ekstraksi dapat membuat objek sementara. |
Ukuran file keluar (dalam MB) |
Masukkan ukuran, dalam MB, file yang diunggah ke Amazon S3. |
Ukuran file Snowball out (dalam MB) |
Masukkan ukuran, dalam MB, dari file yang diunggah ke AWS Snowball Edge. File bisa berukuran 1—1.000 MB. |
Gunakan partisi otomatis. Untuk Greenplum dan Netezza, masukkan ukuran minimal tabel yang didukung (dalam megabyte) |
Aktifkan opsi ini untuk menggunakan partisi tabel, lalu masukkan ukuran tabel untuk dipartisi untuk database sumber Greenplum dan Netezza. Untuk migrasi Oracle ke Amazon Redshift, Anda dapat membiarkan bidang ini kosong AWS SCT karena membuat subtugas untuk semua tabel yang dipartisi. |
Ekstrak LOBs |
Aktifkan opsi ini untuk mengekstrak objek besar (LOBs) dari database sumber Anda. LOBs termasuk BLOBs, CLOBs, NCLOBs, file XHTML, dan sebagainya. Untuk setiap LOB, agen AWS SCT ekstraksi membuat file data. |
Folder ember Amazon S3 LOBs |
Masukkan lokasi untuk agen AWS SCT ekstraksi untuk disimpan LOBs. |
Terapkan RTRIM ke kolom string |
Aktifkan opsi ini untuk memangkas sekumpulan karakter tertentu dari akhir string yang diekstraksi. |
Simpan file secara lokal setelah diunggah ke Amazon S3 |
Aktifkan opsi ini untuk menyimpan file di komputer lokal Anda setelah agen ekstraksi data mengunggahnya ke Amazon S3. |
Gunakan petunjuk dalam tabel berikut untuk memberikan informasi setelan Amazon S3.
| Untuk parameter ini | Lakukan hal berikut |
|---|---|
Gunakan proxy |
Aktifkan opsi ini untuk menggunakan server proxy untuk mengunggah data ke Amazon S3. Kemudian pilih protokol transfer data, masukkan nama host, port, nama pengguna, dan kata sandi. |
Jenis titik akhir |
Pilih FIPS untuk menggunakan titik akhir Federal Information Processing Standard (FIPS). Pilih VPCE untuk menggunakan titik akhir virtual private cloud (VPC). Kemudian untuk titik akhir VPC, masukkan Domain Name System (DNS) dari titik akhir VPC Anda. |
Simpan file di Amazon S3 setelah menyalin ke Amazon Redshift |
Aktifkan opsi ini untuk menyimpan file yang diekstrak di Amazon S3 setelah menyalin file-file ini ke Amazon Redshift. |
Gunakan petunjuk dalam tabel berikut untuk memberikan informasi untuk pengaturan Salin.
| Untuk parameter ini | Lakukan hal berikut |
|---|---|
Jumlah kesalahan maksimum |
Masukkan jumlah kesalahan pemuatan. Setelah operasi mencapai batas ini, agen ekstraksi AWS SCT data mengakhiri proses pemuatan data. Nilai defaultnya adalah 0, yang berarti bahwa agen ekstraksi AWS SCT data melanjutkan pemuatan data terlepas dari kegagalannya. |
Ganti karakter UTF-8 yang tidak valid |
Aktifkan opsi ini untuk mengganti karakter UTF-8 yang tidak valid dengan karakter yang ditentukan dan lanjutkan operasi pemuatan data. |
Gunakan kosong sebagai nilai nol |
Aktifkan opsi ini untuk memuat bidang kosong yang terdiri dari karakter spasi putih sebagai nol. |
Gunakan kosong sebagai nilai null |
Aktifkan opsi ini untuk memuat kosong |
Memotong kolom |
Aktifkan opsi ini untuk memotong data dalam kolom agar sesuai dengan spesifikasi tipe data. |
Kompresi otomatis |
Aktifkan opsi ini untuk menerapkan pengkodean kompresi selama operasi penyalinan. |
Penyegaran statistik otomatis |
Aktifkan opsi ini untuk menyegarkan statistik di akhir operasi penyalinan. |
Periksa file sebelum memuat |
Aktifkan opsi ini untuk memvalidasi file data sebelum memuatnya ke Amazon Redshift. |
Menyortir data sebelum bermigrasi menggunakan AWS SCT
Menyortir data Anda sebelum migrasi dengan AWS SCT memberikan beberapa manfaat. Jika Anda mengurutkan data terlebih dahulu, AWS SCT dapat memulai ulang agen ekstraksi pada titik terakhir yang disimpan setelah kegagalan. Selain itu, jika Anda memigrasikan data ke Amazon Redshift dan mengurutkan data terlebih dahulu AWS SCT , dapat menyisipkan data ke Amazon Redshift lebih cepat.
Manfaat ini berkaitan dengan cara AWS SCT membuat kueri ekstraksi data. Dalam beberapa kasus, AWS SCT menggunakan fungsi analitik DENSE_RANK dalam kueri ini. Namun, DENSE_RANK dapat menggunakan banyak waktu dan sumber daya server untuk mengurutkan kumpulan data yang dihasilkan dari ekstraksi, jadi jika AWS SCT dapat bekerja tanpanya, itu berhasil.
Untuk mengurutkan data sebelum bermigrasi menggunakan AWS SCT
Buka AWS SCT proyek.
Buka menu konteks (klik kanan) untuk objek, lalu pilih Buat tugas Lokal.
Pilih tab Advanced, dan untuk strategi Sorting, pilih opsi:
Jangan pernah menggunakan penyortiran — Agen ekstraksi tidak menggunakan fungsi analitik DENSE_RANK dan memulai ulang dari awal jika terjadi kegagalan.
Gunakan penyortiran jika memungkinkan — Agen ekstraksi menggunakan DENSE_RANK jika tabel memiliki kunci utama atau kendala unik.
Gunakan penyortiran setelah gagal pertama (disarankan) - Agen ekstraksi pertama mencoba mendapatkan data tanpa menggunakan DENSE_RANK. Jika upaya pertama gagal, agen ekstraksi membangun kembali kueri menggunakan DENSE_RANK dan mempertahankan lokasinya jika terjadi kegagalan.
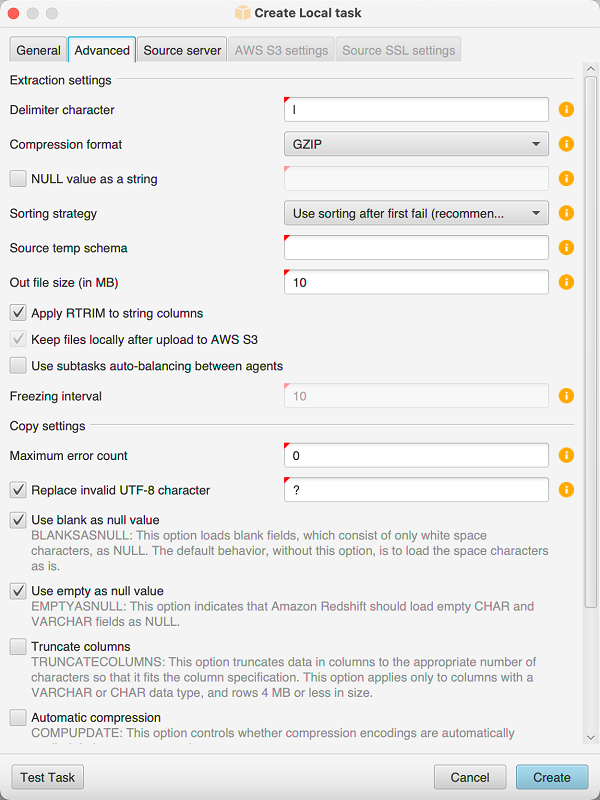
Tetapkan parameter tambahan seperti yang dijelaskan berikut, lalu pilih Buat untuk membuat tugas ekstraksi data Anda.
Membuat, menjalankan, dan memantau tugas ekstraksi AWS SCT data
Gunakan prosedur berikut untuk membuat, menjalankan, dan memantau tugas ekstraksi data.
Untuk menetapkan tugas ke agen dan memigrasikan data
-
Dalam AWS Schema Conversion Tool, setelah Anda mengonversi skema Anda, pilih satu atau beberapa tabel dari panel kiri proyek Anda.
Anda dapat memilih semua tabel, tetapi kami sarankan untuk tidak melakukannya karena alasan kinerja. Kami menyarankan Anda membuat beberapa tugas untuk beberapa tabel berdasarkan ukuran tabel di gudang data Anda.
-
Buka menu konteks (klik kanan) untuk setiap tabel, lalu pilih Buat tugas. Kotak dialog Create Local task terbuka.
-
Untuk nama Tugas, masukkan nama untuk tugas tersebut.
-
Untuk mode Migrasi, pilih salah satu dari berikut ini:
-
Ekstrak saja - Ekstrak data Anda, dan simpan data ke folder kerja lokal Anda.
-
Ekstrak dan unggah - Ekstrak data Anda, dan unggah data Anda ke Amazon S3.
-
Ekstrak, unggah, dan salin — Ekstrak data Anda, unggah data Anda ke Amazon S3, dan salin ke gudang data Amazon Redshift Anda.
-
-
Untuk jenis Enkripsi, pilih salah satu dari berikut ini:
-
NONE — Matikan enkripsi data untuk seluruh proses migrasi data.
-
CSE_SK — Gunakan enkripsi sisi klien dengan kunci simetris untuk memigrasikan data. AWS SCT secara otomatis menghasilkan kunci enkripsi dan mengirimkannya ke agen ekstraksi data menggunakan Secure Sockets Layer (SSL). AWS SCT tidak mengenkripsi objek besar (LOBs) selama migrasi data.
-
-
Pilih Ekstrak LOBs untuk mengekstrak benda besar. Jika Anda tidak perlu mengekstrak benda besar, Anda dapat menghapus kotak centang. Melakukan hal ini mengurangi jumlah data yang Anda ekstrak.
-
Untuk melihat informasi terperinci tentang tugas, pilih Aktifkan pencatatan tugas. Anda dapat menggunakan log tugas untuk men-debug masalah.
Jika Anda mengaktifkan pencatatan tugas, pilih tingkat detail yang ingin Anda lihat. Levelnya adalah sebagai berikut, dengan setiap level termasuk semua pesan dari level sebelumnya:
ERROR— Jumlah detail terkecil.WARNINGINFODEBUGTRACE— Jumlah detail terbesar.
-
Untuk mengekspor data dari BigQuery, AWS SCT gunakan folder bucket Google Cloud Storage. Dalam folder ini, agen ekstraksi data menyimpan data sumber Anda.
Untuk memasukkan jalur ke folder bucket Google Cloud Storage Anda, pilih Advanced. Untuk folder bucket Google CS, masukkan nama bucket dan nama folder.
-
Untuk mengambil peran bagi pengguna agen ekstraksi data Anda, pilih pengaturan Amazon S3. Untuk peran IAM, masukkan nama peran yang akan digunakan. Untuk Wilayah, pilih Wilayah AWS untuk peran ini.
-
Pilih Tugas uji untuk memverifikasi bahwa Anda dapat terhubung ke folder kerja, bucket Amazon S3, dan gudang data Amazon Redshift. Verifikasi tergantung pada mode migrasi yang Anda pilih.
-
Memilih Membuat untuk membuat tugas.
-
Ulangi langkah sebelumnya untuk membuat tugas untuk semua data yang ingin Anda migrasi.
Untuk menjalankan dan memantau tugas
-
Untuk Tampilan, pilih tampilan Migrasi Data. Tab Agen muncul.
-
Pilih tab Tugas. Tugas Anda muncul di kisi di bagian atas seperti yang ditunjukkan berikut. Anda dapat melihat status tugas di kisi atas, dan status subtugasnya di kisi bawah.
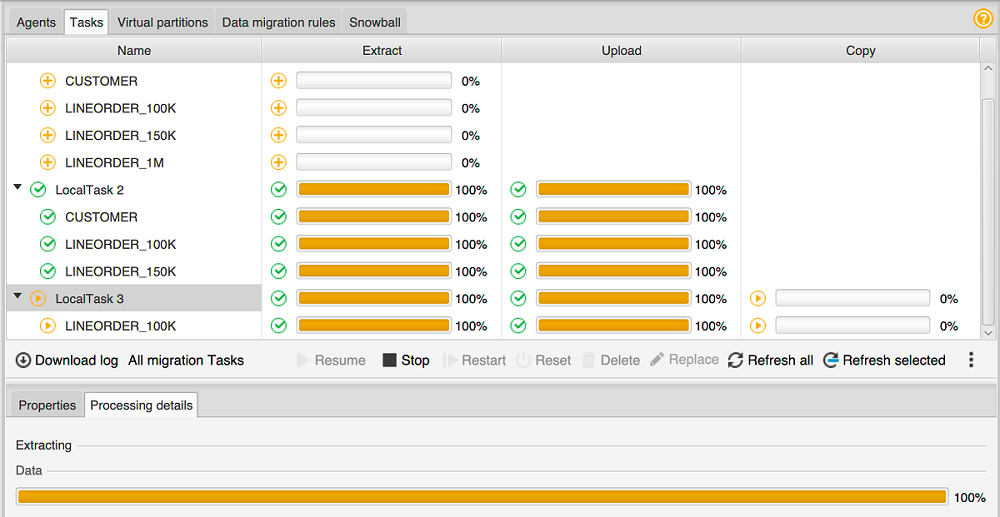
-
Pilih tugas di grid atas dan perluas. Bergantung pada mode migrasi yang Anda pilih, Anda melihat tugas dibagi menjadi Ekstrak, Unggah, dan Salin.
-
Pilih Mulai untuk tugas untuk memulai tugas itu. Anda dapat memantau status tugas Anda saat mereka bekerja. Subtask berjalan secara parallel. Ekstrak, unggah, dan salin juga berjalan secara paralel.
-
Jika Anda mengaktifkan logging saat mengatur tugas, Anda dapat melihat log:
-
Pilih Unduh log. Sebuah pesan muncul dengan nama folder yang berisi file log. Singkirkan pesannya.
-
Tautan muncul di tab Detail tugas. Pilih tautan untuk membuka folder yang berisi file log.
-
Anda dapat menutup AWS SCT, dan agen serta tugas Anda terus berjalan. Anda dapat membuka kembali AWS SCT nanti untuk memeriksa status tugas Anda dan melihat log tugas.
Anda dapat menyimpan tugas ekstraksi data ke disk lokal Anda dan mengembalikannya ke proyek yang sama atau lainnya dengan menggunakan ekspor dan impor. Untuk mengekspor tugas, pastikan Anda memiliki setidaknya satu tugas ekstraksi yang dibuat dalam sebuah proyek. Anda dapat mengimpor tugas ekstraksi tunggal atau semua tugas yang dibuat dalam proyek.
Saat Anda mengekspor tugas ekstraksi, AWS SCT buat .xml file terpisah untuk tugas itu. .xmlFile menyimpan informasi metadata tugas tersebut, seperti properti tugas, deskripsi, dan subtugas. .xmlFile tidak berisi informasi tentang pemrosesan tugas ekstraksi. Informasi seperti berikut ini dibuat ulang saat tugas diimpor:
-
Kemajuan tugas
-
Subtugas dan status panggung
-
Distribusi agen ekstraksi berdasarkan subtugas dan tahapan
-
Tugas dan subtugas IDs
-
Nama tugas
Mengekspor dan mengimpor tugas ekstraksi AWS SCT data
Anda dapat dengan cepat menyimpan tugas yang ada dari satu proyek dan mengembalikannya di proyek lain (atau proyek yang sama) menggunakan AWS SCT ekspor dan impor. Gunakan prosedur berikut untuk mengekspor dan mengimpor tugas ekstraksi data.
Untuk mengekspor dan mengimpor tugas ekstraksi data
-
Untuk Tampilan, pilih tampilan Migrasi Data. Tab Agen muncul.
-
Pilih tab Tugas. Tugas Anda tercantum dalam kisi yang muncul.
-
Pilih tiga titik yang disejajarkan secara vertikal (ikon elipsis) yang terletak di sudut kanan bawah di bawah daftar tugas.
-
Pilih tugas Ekspor dari menu pop-up.
-
Pilih folder tempat Anda AWS SCT ingin menempatkan
.xmlfile ekspor tugas.AWS SCT membuat file ekspor tugas dengan format nama file
TASK-DESCRIPTION_TASK-ID.xml -
Pilih tiga titik yang disejajarkan secara vertikal (ikon elipsis) di kanan bawah di bawah daftar tugas.
-
Pilih Impor tugas dari menu pop-up.
Anda dapat mengimpor tugas ekstraksi ke proyek yang terhubung ke database sumber, dan proyek memiliki setidaknya satu agen ekstraksi terdaftar aktif.
-
Pilih
.xmlfile untuk tugas ekstraksi yang Anda ekspor.AWS SCT mendapatkan parameter tugas ekstraksi dari file, membuat tugas, dan menambahkan tugas ke agen ekstraksi.
-
Ulangi langkah-langkah ini untuk mengekspor dan mengimpor tugas ekstraksi data tambahan.
Pada akhir proses ini, ekspor dan impor Anda selesai dan tugas ekstraksi data Anda siap digunakan.
Ekstraksi data menggunakan perangkat AWS Snowball Edge Edge
Proses penggunaan AWS SCT dan AWS Snowball Edge Edge memiliki beberapa langkah. Migrasi melibatkan tugas lokal, di mana AWS SCT menggunakan agen ekstraksi data untuk memindahkan data ke perangkat AWS Snowball Edge Edge, lalu tindakan perantara di mana AWS menyalin data dari perangkat AWS Snowball Edge Edge ke bucket Amazon S3. Proses selesai AWS SCT memuat data dari bucket Amazon S3 ke Amazon Redshift.
Bagian berikut ikhtisar ini memberikan step-by-step panduan untuk masing-masing tugas ini. Prosedur ini mengasumsikan bahwa Anda telah AWS SCT menginstal dan bahwa Anda telah mengonfigurasi dan mendaftarkan agen ekstraksi data pada mesin khusus.
Lakukan langkah-langkah berikut untuk memigrasikan data dari penyimpanan data lokal ke penyimpanan AWS data menggunakan AWS Snowball Edge Edge.
Buat pekerjaan AWS Snowball Edge Edge menggunakan AWS Snowball Edge konsol.
Buka kunci perangkat AWS Snowball Edge Edge menggunakan mesin Linux lokal khusus.
Buat proyek baru di AWS SCT.
Instal dan konfigurasikan agen ekstraksi data Anda.
Buat dan setel izin untuk bucket Amazon S3 untuk digunakan.
Impor AWS Snowball Edge pekerjaan ke AWS SCT proyek Anda.
Daftarkan agen ekstraksi data Anda di AWS SCT.
Buat tugas lokal di AWS SCT.
Jalankan dan pantau tugas migrasi data di AWS SCT.
Step-by-step prosedur untuk memigrasi data menggunakan AWS SCT dan AWS Snowball Edge Edge
Bagian berikut memberikan informasi rinci tentang langkah-langkah migrasi.
Langkah 1: Buat pekerjaan AWS Snowball Edge Edge
Buat AWS Snowball Edge pekerjaan dengan mengikuti langkah-langkah yang diuraikan di bagian Membuat Pekerjaan AWS Snowball Edge Tepi di Panduan Pengembang AWS Snowball Edge Edge.
Langkah 2: Buka kunci perangkat AWS Snowball Edge Edge
Jalankan perintah yang membuka kunci dan memberikan kredensil ke perangkat Snowball Edge Edge dari mesin tempat Anda menginstal agen. AWS DMS Dengan menjalankan perintah ini, Anda dapat yakin bahwa panggilan AWS DMS agen terhubung ke perangkat AWS Snowball Edge Edge. Untuk informasi selengkapnya tentang membuka kunci perangkat AWS Snowball Edge Edge, lihat Membuka Kunci Snowball Edge Edge.
aws s3 ls s3://<bucket-name> --profile <Snowball Edge profile> --endpoint http://<Snowball IP>:8080 --recursive
Langkah 3: Buat AWS SCT proyek baru
Selanjutnya, buat AWS SCT proyek baru.
Untuk membuat proyek baru di AWS SCT
-
Mulai AWS Schema Conversion Tool. Pada menu File, pilih Proyek baru. Kotak dialog Proyek baru muncul.
-
Memasukkan nama untuk proyek Anda, yang menyimpan secara lokal di komputer Anda.
-
Memasukkan lokasi untuk file proyek lokal Anda.
-
Pilih OK untuk membuat AWS SCT proyek Anda.
-
Pilih Tambahkan sumber untuk menambahkan database sumber baru ke AWS SCT proyek Anda.
-
Pilih Tambahkan target untuk menambahkan platform target baru di AWS SCT proyek Anda.
-
Pilih skema database sumber di panel kiri.
-
Di panel kanan, tentukan platform basis data target untuk skema sumber yang dipilih.
-
Pilih Buat pemetaan. Tombol ini menjadi aktif setelah Anda memilih skema database sumber dan platform basis data target.
Langkah 4: Instal dan konfigurasikan agen ekstraksi data Anda
AWS SCT menggunakan agen ekstraksi data untuk memigrasikan data ke Amazon Redshift. File.zip yang Anda unduh untuk diinstal AWS SCT, termasuk file penginstal agen ekstraksi. Anda dapat menginstal agen ekstraksi data di Windows, Red Hat Enterprise Linux, atau Ubuntu. Untuk informasi selengkapnya, lihat Instalasi agen ekstraksi.
Untuk mengonfigurasi agen ekstraksi data Anda, masukkan mesin basis data sumber dan target Anda. Selain itu, pastikan Anda mengunduh driver JDBC untuk basis data sumber dan target Anda di komputer tempat Anda menjalankan agen ekstraksi data Anda. Agen ekstraksi data menggunakan driver ini untuk terhubung ke basis data sumber dan target Anda. Untuk informasi selengkapnya, lihat Menginstal driver JDBC untuk AWS Schema Conversion Tool.
Di Windows, penginstal agen ekstraksi data meluncurkan wizard konfigurasi di jendela prompt perintah. Di Linux, jalankan sct-extractor-setup.sh file dari lokasi tempat Anda menginstal agen.
Langkah 5: Konfigurasikan AWS SCT untuk mengakses bucket Amazon S3
Untuk informasi tentang mengonfigurasi bucket Amazon S3, lihat ikhtisar Bucket di Panduan Pengguna Layanan Penyimpanan Sederhana Amazon.
Langkah 6: Impor AWS Snowball Edge pekerjaan ke AWS SCT proyek Anda
Untuk menghubungkan AWS SCT proyek Anda dengan perangkat AWS Snowball Edge Edge Anda, impor AWS Snowball Edge pekerjaan Anda.
Untuk mengimpor AWS Snowball Edge pekerjaan Anda
-
Buka menu Pengaturan, lalu pilih Pengaturan global. Kotak dialog Pengaturan global muncul.
-
Pilih profil AWS layanan, lalu pilih Impor pekerjaan.
Pilih AWS Snowball Edge pekerjaan Anda.
-
Masukkan AWS Snowball Edge IP Anda. Untuk informasi selengkapnya, lihat Mengubah Alamat IP Anda di Panduan AWS Snowball Edge Pengguna.
-
Masukkan AWS Snowball Edge Port Anda. Untuk informasi selengkapnya, lihat Port yang Diperlukan untuk Menggunakan AWS Layanan di Perangkat AWS Snowball Edge Edge di Panduan Pengembang AWS Snowball Edge Edge.
-
Masukkan kunci AWS Snowball Edge akses dan kunci AWS Snowball Edge rahasia Anda. Untuk informasi selengkapnya, lihat Otorisasi dan Kontrol Akses AWS Snowball Edge di Panduan AWS Snowball Edge Pengguna.
Pilih Berlakukan, lalu pilih OKE.
Langkah 7: Daftarkan agen ekstraksi data di AWS SCT
Di bagian ini, Anda mendaftarkan agen ekstraksi data di AWS SCT.
Untuk mendaftarkan agen ekstraksi data
-
Pada menu Tampilan, pilih Tampilan migrasi data (lainnya), lalu pilih Daftar.
-
Untuk Deskripsi, masukkan nama untuk agen ekstraksi data Anda.
-
Untuk nama Host, masukkan alamat IP komputer tempat Anda menjalankan agen ekstraksi data Anda.
-
Untuk Port, masukkan port mendengarkan yang Anda konfigurasikan.
-
PilihPendaftaran.
Langkah 8: Membuat tugas lokal
Selanjutnya, Anda membuat tugas migrasi. Tugas tersebut mencakup dua subtugas. Satu subtugas memigrasikan data dari database sumber ke alat AWS Snowball Edge Edge. Subtugas lainnya mengambil data yang dimuat alat ke dalam bucket Amazon S3 dan memigrasikannya ke database target.
Untuk membuat tugas migrasi
-
Pada menu Tampilan, lalu pilih Tampilan migrasi data (lainnya).
Di panel kiri yang menampilkan skema dari database sumber Anda, pilih objek skema untuk dimigrasi. Buka menu konteks (klik kanan) untuk objek, lalu pilih Buat tugas lokal.
-
Untuk nama Tugas, masukkan nama deskriptif untuk tugas migrasi data Anda.
-
Untuk mode Migrasi, pilih Ekstrak, unggah, dan salin.
-
Pilih pengaturan Amazon S3.
-
Pilih Gunakan Snowball Edge.
-
Masukkan folder dan subfolder di bucket Amazon S3 tempat agen ekstraksi data dapat menyimpan data.
-
Memilih Membuat untuk membuat tugas.
Langkah 9: Menjalankan dan memantau tugas migrasi data di AWS SCT
Untuk memulai tugas migrasi data, pilih Mulai. Pastikan Anda membuat koneksi ke database sumber, bucket Amazon S3, AWS Snowball Edge perangkat, serta koneksi ke database target aktif. AWS
Anda dapat memantau dan mengelola tugas migrasi data dan subtugasnya di tab Tugas. Anda dapat melihat kemajuan migrasi data, serta menjeda atau memulai ulang tugas migrasi data Anda.
Output tugas ekstraksi data
Setelah tugas migrasi Anda selesai, data Anda siap. Gunakan informasi berikut untuk menentukan cara melanjutkan berdasarkan mode migrasi yang Anda pilih dan lokasi data Anda.
| Modus migrasi | Lokasi data |
|---|---|
|
Ekstrak, unggah, dan salin |
Data sudah ada di gudang data Amazon Redshift Anda. Anda dapat memverifikasi bahwa data ada di sana, dan mulai menggunakannya. Untuk informasi selengkapnya, lihat Menghubungkan ke klaster dari alat dan kode klien. |
|
Ekstrak dan unggah |
Agen ekstraksi menyimpan data Anda sebagai file di bucket Amazon S3 Anda. Anda dapat menggunakan perintah Amazon Redshift COPY untuk memuat data Anda ke Amazon Redshift. Untuk informasi selengkapnya, lihat Memuat data dari Amazon S3 di dokumentasi Amazon Redshift. Ada beberapa folder di bucket Amazon S3 Anda, sesuai dengan tugas ekstraksi yang Anda siapkan. Saat memuat data ke Amazon Redshift, tentukan nama file manifes yang dibuat oleh setiap tugas. File manifes muncul di folder tugas di bucket Amazon S3 Anda seperti yang ditunjukkan berikut. 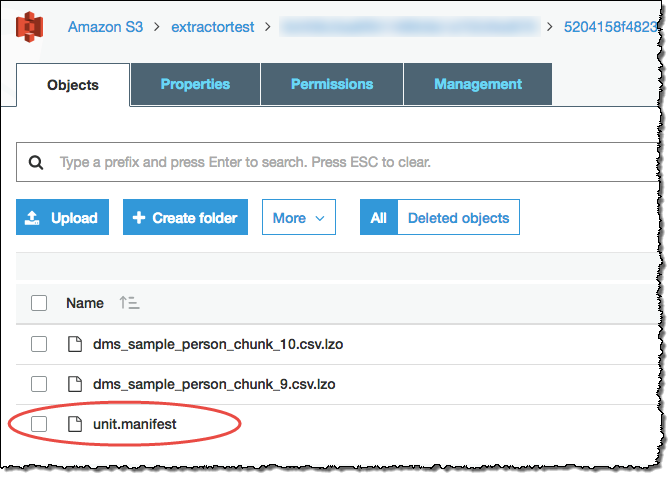
|
|
Ekstrak saja |
Agen ekstraksi menyimpan data Anda sebagai file di folder kerja Anda. Salin data Anda secara manual ke bucket Amazon S3 Anda, lalu lanjutkan dengan instruksi untuk Ekstrak dan unggah. |
Menggunakan partisi virtual dengan AWS Schema Conversion Tool
Anda sering dapat mengelola tabel non-partisi besar dengan membuat subtugas yang membuat partisi virtual dari data tabel menggunakan aturan pemfilteran. Di AWS SCT, Anda dapat membuat partisi virtual untuk data yang dimigrasi. Ada tiga jenis partisi, yang bekerja dengan tipe data tertentu:
Jenis partisi RANGE bekerja dengan tipe data numerik dan tanggal dan waktu.
Jenis partisi LIST bekerja dengan tipe data numerik, karakter, dan tanggal dan waktu.
Jenis partisi DATE AUTO SPLIT bekerja dengan tipe data numerik, tanggal, dan waktu.
AWS SCT memvalidasi nilai yang Anda berikan untuk membuat partisi. Misalnya, jika Anda mencoba mempartisi kolom dengan tipe data NUMERIC tetapi Anda memberikan nilai dari tipe data yang berbeda, akan AWS SCT menimbulkan kesalahan.
Selain itu, jika Anda menggunakan AWS SCT untuk memigrasikan data ke Amazon Redshift, Anda dapat menggunakan partisi asli untuk mengelola migrasi tabel besar. Untuk informasi selengkapnya, lihat Menggunakan partisi asli.
Batas saat membuat partisi virtual
Ini adalah batasan untuk membuat partisi virtual:
Anda hanya dapat menggunakan partisi virtual hanya untuk tabel yang tidak dipartisi.
Anda dapat menggunakan partisi virtual hanya dalam tampilan migrasi data.
Anda tidak dapat menggunakan opsi UNION ALL VIEW dengan partisi virtual.
Jenis partisi RANGE
Jenis partisi RANGE partisi data berdasarkan rentang nilai kolom untuk tipe data numerik dan tanggal dan waktu. Jenis partisi ini membuat WHERE klausa, dan Anda memberikan rentang nilai untuk setiap partisi. Untuk menentukan daftar nilai untuk kolom yang dipartisi, gunakan kotak Nilai. Anda dapat memuat informasi nilai dengan menggunakan file.csv.
Jenis partisi RANGE menciptakan partisi default di kedua ujung nilai partisi. Partisi default ini menangkap data apa pun yang kurang dari atau lebih besar dari nilai partisi yang ditentukan.
Misalnya, Anda dapat membuat beberapa partisi berdasarkan rentang nilai yang Anda berikan. Dalam contoh berikut, nilai partisi untuk LO_TAX ditentukan untuk membuat beberapa partisi.
Partition1: WHERE LO_TAX <= 10000.9 Partition2: WHERE LO_TAX > 10000.9 AND LO_TAX <= 15005.5 Partition3: WHERE LO_TAX > 15005.5 AND LO_TAX <= 25005.95
Untuk membuat partisi virtual RANGE
Terbuka AWS SCT.
Pilih mode tampilan Migrasi Data (lainnya).
Pilih tabel tempat Anda ingin mengatur partisi virtual. Buka menu konteks (klik kanan) untuk tabel, dan pilih Tambahkan partisi virtual.
Dalam Tambahkan partisi virtual kotak dialog, masukkan informasi sebagai berikut.
Opsi Tindakan Jenis partisi
Pilih RANGE. UI kotak dialog berubah tergantung pada jenis yang Anda pilih.
Nama kolom
Pilih kolom yang ingin Anda partisi.
Jenis kolom
Pilih tipe data untuk nilai di kolom.
Nilai-nilai
Tambahkan nilai baru dengan mengetikkan setiap nilai di kotak Nilai Baru, lalu pilih tanda plus untuk menambahkan nilai.
Muat dari file
(Opsional) Masukkan nama file.csv yang berisi nilai partisi.
-
Pilih OK.
LIST jenis partisi
Jenis partisi LIST data partisi berdasarkan nilai kolom untuk tipe data numerik, karakter, dan tanggal dan waktu. Jenis partisi ini membuat WHERE klausa, dan Anda memberikan nilai untuk setiap partisi. Untuk menentukan daftar nilai untuk kolom yang dipartisi, gunakan kotak Nilai. Anda dapat memuat informasi nilai dengan menggunakan file.csv.
Misalnya, Anda dapat membuat beberapa partisi berdasarkan nilai yang Anda berikan. Dalam contoh berikut, nilai partisi untuk LO_ORDERKEY ditentukan untuk membuat beberapa partisi.
Partition1: WHERE LO_ORDERKEY = 1 Partition2: WHERE LO_ORDERKEY = 2 Partition3: WHERE LO_ORDERKEY = 3 … PartitionN: WHERE LO_ORDERKEY = USER_VALUE_N
Anda juga dapat membuat partisi default untuk nilai-nilai yang tidak termasuk dalam yang ditentukan.
Anda dapat menggunakan jenis partisi LIST untuk memfilter data sumber jika Anda ingin mengecualikan nilai tertentu dari migrasi. Misalnya, anggaplah Anda ingin menghilangkan baris denganLO_ORDERKEY = 4. Dalam hal ini, jangan sertakan nilai 4 dalam daftar nilai partisi dan pastikan bahwa Sertakan nilai lain tidak dipilih.
Untuk membuat partisi virtual LIST
Terbuka AWS SCT.
Pilih mode tampilan Migrasi Data (lainnya).
Pilih tabel tempat Anda ingin mengatur partisi virtual. Buka menu konteks (klik kanan) untuk tabel, dan pilih Tambahkan partisi virtual.
Dalam Tambahkan partisi virtual kotak dialog, masukkan informasi sebagai berikut.
Opsi Tindakan Jenis partisi
Pilih DAFTAR. UI kotak dialog berubah tergantung pada jenis yang Anda pilih.
Nama kolom
Pilih kolom yang ingin Anda partisi.
Nilai baru
Ketik nilai di sini untuk menambahkannya ke set nilai partisi.
Sertakan nilai lainnya
Pilih opsi ini untuk membuat partisi default di mana semua nilai yang tidak memenuhi kriteria partisi disimpan.
Muat dari file
(Opsional) Masukkan nama file.csv yang berisi nilai partisi.
Pilih OK.
Jenis partisi DATE AUTO SPLIT
Jenis partisi DATE AUTO SPLIT adalah cara otomatis untuk menghasilkan partisi RANGE. Dengan DATA AUTO SPLIT, Anda memberi tahu AWS SCT atribut partisi, di mana harus memulai dan mengakhiri, dan ukuran rentang antara nilai-nilai. Kemudian AWS SCT menghitung nilai partisi secara otomatis.
DATA AUTO SPLIT mengotomatiskan banyak pekerjaan yang terlibat dengan pembuatan partisi rentang. Tradeoff antara menggunakan teknik ini dan partisi rentang adalah seberapa banyak kontrol yang Anda butuhkan atas batas partisi. Proses pemisahan otomatis selalu menciptakan rentang ukuran (seragam) yang sama. Partisi rentang memungkinkan Anda untuk memvariasikan ukuran setiap rentang sesuai kebutuhan untuk distribusi data tertentu Anda. Misalnya, Anda dapat menggunakan harian, mingguan, dua mingguan, bulanan, dan sebagainya.
Partition1: WHERE LO_ORDERDATE >= ‘1954-10-10’ AND LO_ORDERDATE < ‘1954-10-24’ Partition2: WHERE LO_ORDERDATE >= ‘1954-10-24’ AND LO_ORDERDATE < ‘1954-11-06’ Partition3: WHERE LO_ORDERDATE >= ‘1954-11-06’ AND LO_ORDERDATE < ‘1954-11-20’ … PartitionN: WHERE LO_ORDERDATE >= USER_VALUE_N AND LO_ORDERDATE <= ‘2017-08-13’
Untuk membuat partisi virtual DATE AUTO SPLIT
Terbuka AWS SCT.
Pilih mode tampilan Migrasi Data (lainnya).
Pilih tabel tempat Anda ingin mengatur partisi virtual. Buka menu konteks (klik kanan) untuk tabel, dan pilih Tambahkan partisi virtual.
Dalam Tambahkan partisi virtual kotak dialog, masukkan informasi sebagai berikut.
Opsi Tindakan Jenis partisi
Pilih DATE AUTO SPLIT. UI kotak dialog berubah tergantung pada jenis yang Anda pilih.
Nama kolom
Pilih kolom yang ingin Anda partisi.
Tanggal mulai
Ketik tanggal mulai.
Tanggal akhir
Ketik tanggal akhir.
Interval
Masukkan unit interval, dan pilih nilai untuk unit itu.
Pilih OK.
Menggunakan partisi asli
Untuk mempercepat migrasi data, agen ekstraksi data Anda dapat menggunakan partisi asli tabel di server gudang data sumber Anda. AWS SCT mendukung partisi asli untuk migrasi dari Greenplum, Netezza, dan Oracle ke Amazon Redshift.
Misalnya, setelah membuat proyek, Anda dapat mengumpulkan statistik pada skema dan menganalisis ukuran tabel yang dipilih untuk migrasi. Untuk tabel yang melebihi ukuran yang ditentukan, AWS SCT memicu mekanisme partisi asli.
Untuk menggunakan partisi asli
-
Buka AWS SCT, dan pilih Proyek baru untuk File. Kotak dialog Proyek baru muncul.
-
Buat proyek baru, tambahkan server sumber dan target Anda, dan buat aturan pemetaan. Untuk informasi selengkapnya, lihat Memulai dan mengelola Proyek di AWS SCT.
-
Pilih Tampilan, lalu pilih Tampilan utama.
-
Untuk pengaturan Project, pilih tab Migrasi data. Pilih Gunakan partisi otomatis. Untuk database sumber Greenplum dan Netezza, masukkan ukuran minimal tabel yang didukung dalam megabyte (misalnya, 100). AWS SCT secara otomatis membuat subtugas migrasi terpisah untuk setiap partisi asli yang tidak kosong. Untuk migrasi Oracle ke Amazon Redshift, buat subtugas untuk semua tabel AWS SCT yang dipartisi.
-
Di panel kiri yang menampilkan skema dari database sumber Anda, pilih skema. Buka menu konteks (klik kanan) untuk objek, dan pilih Kumpulkan statistik. Untuk migrasi data dari Oracle ke Amazon Redshift, Anda dapat melewati langkah ini.
-
Pilih semua tabel untuk dimigrasi.
-
Daftarkan jumlah agen yang diperlukan. Untuk informasi selengkapnya, lihat Mendaftarkan agen ekstraksi dengan AWS Schema Conversion Tool.
-
Buat tugas ekstraksi data untuk tabel yang dipilih. Untuk informasi selengkapnya, lihat Membuat, menjalankan, dan memantau tugas ekstraksi AWS SCT data.
Periksa apakah tabel besar dibagi menjadi subtugas, dan setiap subtugas cocok dengan kumpulan data yang menyajikan bagian tabel yang terletak pada satu irisan di gudang data sumber Anda.
-
Mulai dan pantau proses migrasi hingga agen ekstraksi AWS SCT data menyelesaikan migrasi data dari tabel sumber Anda.
Bermigrasi LOBs ke Amazon Redshift
Amazon Redshift tidak mendukung penyimpanan objek biner besar ()LOBs. Namun, jika Anda perlu memigrasikan satu atau beberapa LOBs ke Amazon Redshift AWS SCT , dapat melakukan migrasi. Untuk melakukannya, AWS SCT gunakan bucket Amazon S3 untuk menyimpan LOBs dan menulis URL untuk bucket Amazon S3 ke dalam data migrasi yang disimpan di Amazon Redshift.
Untuk bermigrasi LOBs ke Amazon Redshift
Buka AWS SCT proyek.
Connect ke database sumber dan target. Segarkan metadata dari database target, dan pastikan tabel yang dikonversi ada di sana.
Untuk Tindakan, pilih Buat tugas lokal.
-
Untuk mode Migrasi, pilih salah satu dari berikut ini:
-
Ekstrak dan unggah untuk mengekstrak data Anda, dan unggah data Anda ke Amazon S3.
-
Ekstrak, unggah, dan salin untuk mengekstrak data Anda, unggah data Anda ke Amazon S3, dan salin ke gudang data Amazon Redshift Anda.
-
Pilih pengaturan Amazon S3.
Untuk LOBs folder bucket Amazon S3, masukkan nama folder di bucket Amazon S3 tempat Anda ingin disimpan. LOBs
Jika Anda menggunakan profil AWS layanan, bidang ini bersifat opsional. AWS SCT dapat menggunakan pengaturan default dari profil Anda. Untuk menggunakan bucket Amazon S3 lainnya, masukkan jalur di sini.
-
Aktifkan opsi Gunakan proxy untuk menggunakan server proxy untuk mengunggah data ke Amazon S3. Kemudian pilih protokol transfer data, masukkan nama host, port, nama pengguna, dan kata sandi.
-
Untuk tipe Endpoint, pilih FIPS untuk menggunakan titik akhir Federal Information Processing Standard (FIPS). Pilih VPCE untuk menggunakan titik akhir virtual private cloud (VPC). Kemudian untuk titik akhir VPC, masukkan Domain Name System (DNS) dari titik akhir VPC Anda.
-
Aktifkan Simpan file di Amazon S3 setelah menyalin ke Amazon Redshift opsi untuk menyimpan file yang diekstraksi di Amazon S3 setelah menyalin file-file ini ke Amazon Redshift.
Memilih Membuat untuk membuat tugas.
Praktik terbaik dan pemecahan masalah untuk agen ekstraksi data
Berikut ini adalah beberapa praktik terbaik dan saran pemecahan masalah untuk menggunakan agen ekstraksi.
| Masalah | Saran pemecahan masalah |
|---|---|
|
Kinerja lambat |
Untuk meningkatkan kinerja, kami merekomendasikan yang berikut:
|
|
Penundaan pertikaian |
Hindari terlalu banyak agen yang mengakses gudang data Anda secara bersamaan. |
|
Seorang agen turun sementara |
Jika agen down, status setiap tugasnya muncul sebagai gagal dalam AWS SCT. Jika Anda menunggu, dalam beberapa kasus agen dapat pulih. Dalam hal ini, status tugasnya diperbarui di AWS SCT. |
|
Seorang agen turun secara permanen |
Jika komputer yang menjalankan agen mati secara permanen, dan agen tersebut menjalankan tugas, Anda dapat mengganti agen baru untuk melanjutkan tugas. Anda dapat mengganti agen baru hanya jika folder kerja agen asli tidak berada di komputer yang sama dengan agen asli. Untuk mengganti agen baru, lakukan hal berikut:
|
