Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Memigrasi beban kerja Hadoop ke Amazon EMR dengan AWS Schema Conversion Tool
Untuk memigrasikan cluster Apache Hadoop, pastikan Anda menggunakan AWS SCT versi 1.0.670 atau yang lebih tinggi. Juga, biasakan diri Anda dengan antarmuka baris perintah (CLI) dari. AWS SCT Untuk informasi selengkapnya, lihat Referensi CLI untuk AWS Schema Conversion Tool.
Topik
Ikhtisar migrasi
Gambar berikut menunjukkan diagram arsitektur migrasi dari Apache Hadoop ke Amazon EMR.
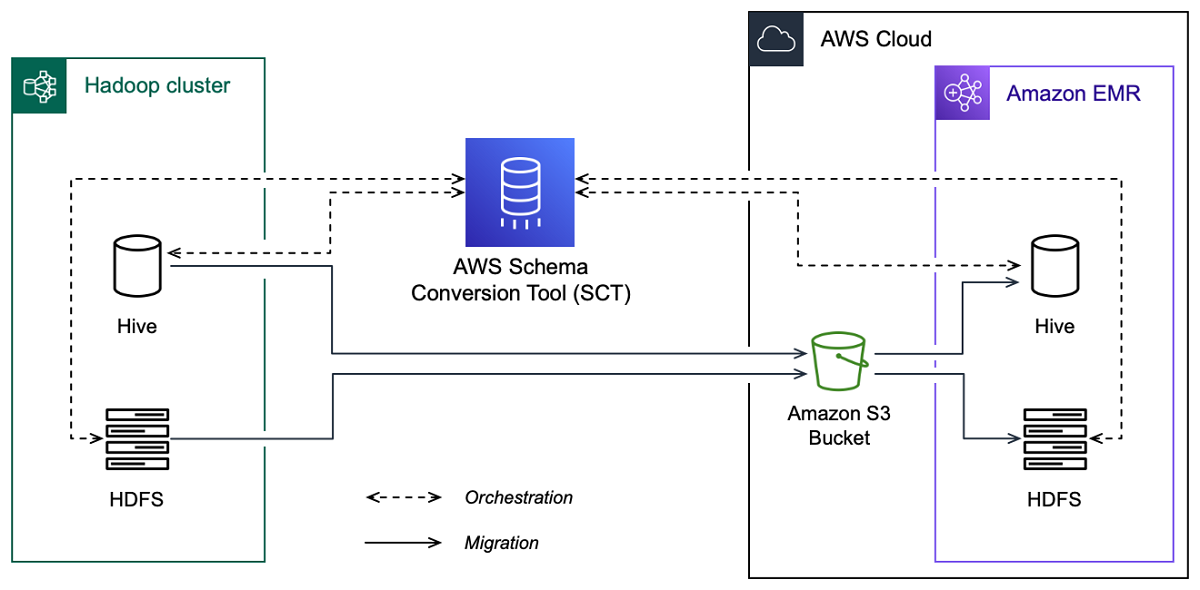
AWS SCT memigrasikan data dan metadata dari cluster Hadoop sumber Anda ke bucket Amazon S3. Selanjutnya, AWS SCT gunakan metadata Hive sumber Anda untuk membuat objek database di layanan Amazon EMR Hive target. Secara opsional, Anda dapat mengkonfigurasi Hive untuk menggunakan AWS Glue Data Catalog sebagai metastore nya. Dalam hal ini, AWS SCT memigrasikan metadata Hive sumber Anda ke file. AWS Glue Data Catalog
Kemudian, Anda dapat menggunakannya AWS SCT untuk memigrasikan data dari bucket Amazon S3 ke layanan HDFS Amazon EMR target Anda. Atau, Anda dapat meninggalkan data di bucket Amazon S3 dan menggunakannya sebagai repositori data untuk beban kerja Hadoop Anda.
Untuk memulai migrasi Hapoood, Anda membuat dan menjalankan skrip AWS SCT CLI Anda. Skrip ini mencakup set lengkap perintah untuk menjalankan migrasi. Anda dapat mengunduh dan mengedit templat skrip migrasi Hadoop. Untuk informasi selengkapnya, lihat Mendapatkan skenario CLI.
Pastikan skrip Anda menyertakan langkah-langkah berikut sehingga Anda dapat menjalankan migrasi dari Apache Hadoop ke Amazon S3 dan Amazon EMR.
Langkah 1: Connect ke cluster Hadoop Anda
Untuk memulai migrasi cluster Apache Hadoop Anda, buat proyek baru. AWS SCT Selanjutnya, sambungkan ke cluster sumber dan target Anda. Pastikan Anda membuat dan menyediakan AWS sumber daya target sebelum memulai migrasi.
Pada langkah ini, Anda menggunakan perintah AWS SCT CLI berikut.
CreateProject— untuk membuat AWS SCT proyek baru.AddSourceCluster— untuk terhubung ke cluster Hadoop sumber di proyek Anda AWS SCT .AddSourceClusterHive— untuk terhubung ke layanan sumber Hive di proyek Anda.AddSourceClusterHDFS— untuk terhubung ke layanan HDFS sumber di proyek Anda.AddTargetCluster— untuk terhubung ke kluster EMR Amazon target di proyek Anda.AddTargetClusterS3— untuk menambahkan bucket Amazon S3 ke proyek Anda.AddTargetClusterHive— untuk terhubung ke layanan Hive target di proyek AndaAddTargetClusterHDFS— untuk terhubung ke layanan HDFS target dalam proyek Anda
Untuk contoh menggunakan perintah AWS SCT CLI ini, lihat. Menghubungkan ke Apache Hadoop
Ketika Anda menjalankan perintah yang menghubungkan ke sumber atau target cluster, AWS SCT mencoba untuk membuat koneksi ke cluster ini. Jika upaya koneksi gagal, maka AWS SCT berhenti menjalankan perintah dari skrip CLI Anda dan menampilkan pesan kesalahan.
Langkah 2: Siapkan aturan pemetaan
Setelah Anda terhubung ke sumber dan kluster target, atur aturan pemetaan. Aturan pemetaan mendefinisikan target migrasi untuk kluster sumber. Pastikan Anda menyiapkan aturan pemetaan untuk semua kluster sumber yang ditambahkan dalam proyek Anda AWS SCT . Untuk informasi selengkapnya tentang aturan pemetaan, lihatMemetakan tipe data di AWS Schema Conversion Tool.
Pada langkah ini, Anda menggunakan AddServerMapping perintah. Perintah ini menggunakan dua parameter, yang menentukan cluster sumber dan target. Anda dapat menggunakan AddServerMapping perintah dengan jalur eksplisit ke objek database Anda atau dengan nama objek. Untuk opsi pertama, Anda menyertakan jenis objek dan namanya. Untuk opsi kedua, Anda hanya menyertakan nama objek.
-
sourceTreePath— jalur eksplisit ke objek database sumber Anda.targetTreePath— jalur eksplisit ke objek database target Anda. -
sourceNamePath— jalur yang hanya mencakup nama-nama objek sumber Anda.targetNamePath— jalur yang hanya mencakup nama-nama objek target Anda.
Contoh kode berikut membuat aturan pemetaan menggunakan jalur eksplisit untuk database sumber testdb Hive dan kluster EMR target.
AddServerMapping -sourceTreePath: 'Clusters.HADOOP_SOURCE.HIVE_SOURCE.Databases.testdb' -targetTreePath: 'Clusters.HADOOP_TARGET.HIVE_TARGET' /
Anda dapat menggunakan contoh ini dan contoh berikut di Windows. Untuk menjalankan perintah CLI di Linux, pastikan Anda memperbarui jalur file dengan tepat untuk sistem operasi Anda.
Contoh kode berikut membuat aturan pemetaan menggunakan jalur yang hanya menyertakan nama objek.
AddServerMapping -sourceNamePath: 'HADOOP_SOURCE.HIVE_SOURCE.testdb' -targetNamePath: 'HADOOP_TARGET.HIVE_TARGET' /
Anda dapat memilih Amazon EMR atau Amazon S3 sebagai target untuk objek sumber Anda. Untuk setiap objek sumber, Anda dapat memilih hanya satu target dalam satu AWS SCT proyek. Untuk mengubah target migrasi objek sumber, hapus aturan pemetaan yang ada, lalu buat aturan pemetaan baru. Untuk menghapus aturan pemetaan, gunakan DeleteServerMapping perintah. Perintah ini menggunakan salah satu dari dua parameter berikut.
sourceTreePath— jalur eksplisit ke objek database sumber Anda.sourceNamePath— jalur yang hanya mencakup nama-nama objek sumber Anda.
Untuk informasi selengkapnya tentang DeleteServerMapping perintah AddServerMapping dan, lihat AWS Schema Conversion Tool Referensi CLI
Langkah 3: Buat laporan penilaian
Sebelum memulai migrasi, sebaiknya buat laporan penilaian. Laporan ini merangkum semua tugas migrasi dan merinci item tindakan yang akan muncul selama migrasi. Untuk memastikan migrasi Anda tidak gagal, lihat laporan ini dan alamat item tindakan sebelum migrasi. Untuk informasi selengkapnya, lihat Laporan penilaian.
Pada langkah ini, Anda menggunakan CreateMigrationReport perintah. Perintah ini menggunakan dua parameter. treePathParameternya wajib, dan forceMigrate parameternya opsional.
treePath— jalur eksplisit ke objek database sumber Anda yang Anda simpan salinan laporan penilaian.forceMigrate— ketika diatur ketrue, AWS SCT melanjutkan migrasi bahkan jika proyek Anda menyertakan folder HDFS dan tabel Hive yang merujuk ke objek yang sama. Nilai default-nya adalahfalse.
Anda kemudian dapat menyimpan salinan laporan penilaian sebagai file PDF atau nilai dipisahkan koma (CSV). Untuk melakukannya, gunakan SaveReportCSV perintah SaveReportPDF or.
SaveReportPDFPerintah menyimpan salinan laporan penilaian Anda sebagai file PDF. Perintah ini menggunakan empat parameter. fileParameternya wajib, parameter lainnya bersifat opsional.
file— jalur ke file PDF dan namanya.filter— nama filter yang Anda buat sebelumnya untuk menentukan ruang lingkup objek sumber Anda untuk bermigrasi.treePath— jalur eksplisit ke objek database sumber Anda yang Anda simpan salinan laporan penilaian.namePath— jalur yang hanya mencakup nama objek target Anda yang Anda simpan salinan laporan penilaian.
SaveReportCSVPerintah menyimpan laporan penilaian Anda dalam tiga file CSV. Perintah ini menggunakan empat parameter. directoryParameternya wajib, parameter lainnya bersifat opsional.
directory— jalur ke folder tempat AWS SCT menyimpan file CSV.filter— nama filter yang Anda buat sebelumnya untuk menentukan ruang lingkup objek sumber Anda untuk bermigrasi.treePath— jalur eksplisit ke objek database sumber Anda yang Anda simpan salinan laporan penilaian.namePath— jalur yang hanya mencakup nama objek target Anda yang Anda simpan salinan laporan penilaian.
Contoh kode berikut menyimpan salinan laporan penilaian dalam c:\sct\ar.pdf file.
SaveReportPDF -file:'c:\sct\ar.pdf' /
Contoh kode berikut menyimpan salinan laporan penilaian sebagai file CSV di c:\sct folder.
SaveReportCSV -file:'c:\sct' /
Untuk informasi selengkapnya tentang SaveReportCSV perintah SaveReportPDF dan, lihat AWS Schema Conversion Tool Referensi CLI
Langkah 4: Migrasikan cluster Apache Hadoop Anda ke Amazon EMR dengan AWS SCT
Setelah mengonfigurasi AWS SCT project, mulai migrasi cluster Apache Hadoop lokal Anda ke. AWS Cloud
Pada langkah ini, Anda menggunakanMigrate,MigrationStatus, dan ResumeMigration perintah.
MigratePerintah memigrasikan objek sumber Anda ke cluster target. Perintah ini menggunakan empat parameter. Pastikan Anda menentukan treePath parameter filter atau. Parameter lainnya adalah opsional.
filter— nama filter yang Anda buat sebelumnya untuk menentukan ruang lingkup objek sumber Anda untuk bermigrasi.treePath— jalur eksplisit ke objek database sumber Anda yang Anda simpan salinan laporan penilaian.forceLoad— ketika diatur ketrue, AWS SCT secara otomatis memuat pohon metadata database selama migrasi. Nilai default-nya adalahfalse.forceMigrate— ketika diatur ketrue, AWS SCT melanjutkan migrasi bahkan jika proyek Anda menyertakan folder HDFS dan tabel Hive yang merujuk ke objek yang sama. Nilai default-nya adalahfalse.
MigrationStatusPerintah mengembalikan informasi tentang kemajuan migrasi. Untuk menjalankan perintah ini, masukkan nama proyek migrasi Anda untuk name parameter. Anda menentukan nama ini dalam CreateProject perintah.
ResumeMigrationPerintah melanjutkan migrasi terputus yang Anda luncurkan menggunakan perintah. Migrate ResumeMigrationPerintah tidak menggunakan parameter. Untuk melanjutkan migrasi, Anda harus terhubung ke sumber dan kluster target Anda. Untuk informasi selengkapnya, lihat Mengelola proyek migrasi Anda.
Contoh kode berikut memigrasikan data dari layanan HDFS sumber Anda ke Amazon EMR.
Migrate -treePath: 'Clusters.HADOOP_SOURCE.HDFS_SOURCE' -forceMigrate: 'true' /
Menjalankan skrip CLI Anda
Setelah Anda selesai mengedit skrip AWS SCT CLI Anda, simpan sebagai file dengan ekstensi. .scts Sekarang, Anda dapat menjalankan skrip Anda dari app folder jalur AWS SCT instalasi Anda. Untuk melakukannya, gunakan perintah berikut.
RunSCTBatch.cmd --pathtoscts "C:\script_path\hadoop.scts"
Pada contoh sebelumnya, ganti script_path dengan path ke file Anda dengan skrip CLI. Untuk informasi selengkapnya tentang menjalankan skrip CLI di AWS SCT, lihat. Mode skrip
Mengelola proyek migrasi data besar Anda
Setelah menyelesaikan migrasi, Anda dapat menyimpan dan mengedit AWS SCT proyek Anda untuk digunakan di masa mendatang.
Untuk menyimpan AWS SCT proyek Anda, gunakan SaveProject perintah. Perintah ini tidak menggunakan parameter.
Contoh kode berikut menyimpan AWS SCT proyek Anda.
SaveProject /
Untuk membuka AWS SCT proyek Anda, gunakan OpenProject perintah. Perintah ini menggunakan satu parameter wajib. Untuk file parameter, masukkan path ke file AWS SCT proyek Anda dan namanya. Anda menentukan nama proyek dalam CreateProject perintah. Pastikan Anda menambahkan .scts ekstensi ke nama file proyek Anda untuk menjalankan OpenProject perintah.
Contoh kode berikut membuka hadoop_emr proyek dari c:\sct folder.
OpenProject -file: 'c:\sct\hadoop_emr.scts' /
Setelah Anda membuka AWS SCT proyek Anda, Anda tidak perlu menambahkan sumber dan target cluster karena Anda telah menambahkannya ke proyek Anda. Untuk mulai bekerja dengan sumber dan kluster target Anda, Anda harus terhubung dengan mereka. Untuk melakukannya, Anda menggunakan ConnectTargetCluster perintah ConnectSourceCluster dan. Perintah ini menggunakan parameter yang sama dengan AddTargetCluster perintah AddSourceCluster dan. Anda dapat mengedit skrip CLI Anda dan mengganti nama perintah ini meninggalkan daftar parameter tanpa perubahan.
Contoh kode berikut menghubungkan ke cluster Hadoop sumber.
ConnectSourceCluster -name: 'HADOOP_SOURCE' -vendor: 'HADOOP' -host: 'hadoop_address' -port: '22' -user: 'hadoop_user' -password: 'hadoop_password' -useSSL: 'true' -privateKeyPath: 'c:\path\name.pem' -passPhrase: 'hadoop_passphrase' /
Contoh kode berikut terhubung ke cluster EMR Amazon target.
ConnectTargetCluster -name: 'HADOOP_TARGET' -vendor: 'AMAZON_EMR' -host: 'ec2-44-44-55-66.eu-west-1.EXAMPLE.amazonaws.com' -port: '22' -user: 'emr_user' -password: 'emr_password' -useSSL: 'true' -privateKeyPath: 'c:\path\name.pem' -passPhrase: '1234567890abcdef0!' -s3Name: 'S3_TARGET' -accessKey: 'AKIAIOSFODNN7EXAMPLE' -secretKey: 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY' -region: 'eu-west-1' -s3Path: 'doc-example-bucket/example-folder' /
Pada contoh sebelumnya, ganti hadoop_address dengan alamat IP cluster Hadoop Anda. Jika diperlukan, konfigurasikan nilai variabel port. Selanjutnya, ganti hadoop_user dan hadoop_password dengan nama pengguna Hadoop Anda dan kata sandi untuk pengguna ini. Untukpath\name, masukkan nama dan path ke file PEM untuk cluster Hadoop sumber Anda. Untuk informasi selengkapnya tentang menambahkan sumber dan kluster target, lihatMenghubungkan ke database Apache Hadoop dengan AWS Schema Conversion Tool.
Setelah Anda terhubung ke sumber dan target cluster Hadoop, Anda harus terhubung ke layanan Hive dan HDFS Anda, serta ke bucket Amazon S3 Anda. Untuk melakukannya, Anda menggunakanConnectSourceClusterHive,,ConnectSourceClusterHdfs, ConnectTargetClusterHiveConnectTargetClusterHdfs, dan ConnectTargetClusterS3 perintah. Perintah ini menggunakan parameter yang sama dengan perintah yang Anda gunakan untuk menambahkan layanan Hive dan HDFS, dan bucket Amazon S3 ke proyek Anda. Edit skrip CLI untuk mengganti Add awalan dengan nama Connect perintah.
