Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Desain skema sistem manajemen pengaduan di DynamoDB
Kasus penggunaan bisnis sistem manajemen pengaduan
DynamoDB adalah basis data yang cocok untuk kasus penggunaan sistem manajemen pengaduan (atau pusat kontak) karena sebagian besar pola akses yang terkait dengannya adalah pencarian transaksional berbasis kunci-nilai. Pola akses tipikal dalam skenario ini adalah:
-
Membuat dan memperbarui pengaduan
-
Mengeskalasi pengaduan
-
Membuat dan membaca komentar tentang pengaduan
-
Mendapatkan semua pengaduan dari pelanggan
-
Mendapatkan semua komentar oleh agen dan mendapatkan semua eskalasi
Beberapa komentar mungkin memiliki lampiran yang menjelaskan pengaduan atau solusi. Meskipun ini semua adalah pola akses kunci-nilai, mungkin ada persyaratan tambahan seperti mengirimkan pemberitahuan ketika komentar baru ditambahkan ke pengaduan atau menjalankan kueri analitik untuk menemukan distribusi pengaduan berdasarkan tingkat keparahan (atau kinerja agen) per minggu. Persyaratan tambahan yang terkait dengan manajemen siklus hidup atau kepatuhan adalah mengarsipkan data pengaduan yang sudah tercatat selama tiga tahun.
Diagram arsitektur sistem manajemen pengaduan
Diagram berikut menunjukkan diagram arsitektur sistem manajemen keluhan. Diagram ini menunjukkan Layanan AWS integrasi berbeda yang digunakan sistem manajemen keluhan.
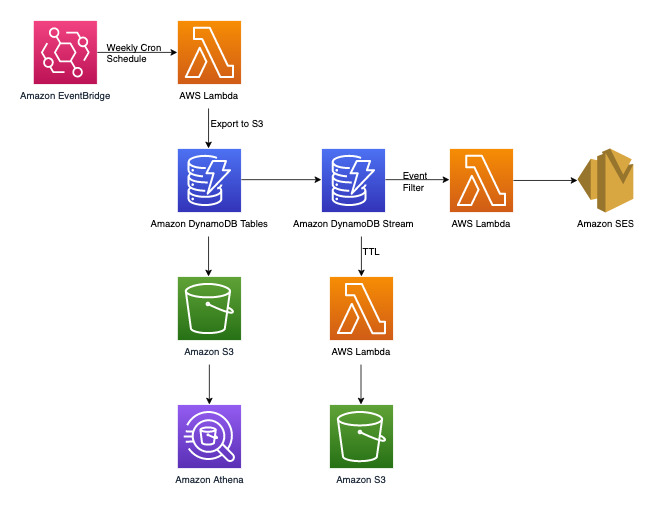
Terlepas dari pola akses transaksional kunci-nilai yang akan kita tangani di bagian pemodelan data DynamoDB nanti, ada tiga persyaratan non-transaksional. Diagram arsitektur di atas dapat dipecah menjadi tiga alur kerja berikut:
-
Kirim pemberitahuan saat komentar baru ditambahkan ke pengaduan
-
Jalankan kueri analitik pada data mingguan
-
Arsipkan data yang berusia lebih dari tiga tahun
Mari kita lihat setiap alur kerja tersebut lebih mendalam.
Kirim pemberitahuan saat komentar baru ditambahkan ke pengaduan
Kita dapat menggunakan alur kerja di bawah ini untuk mencapai persyaratan ini:
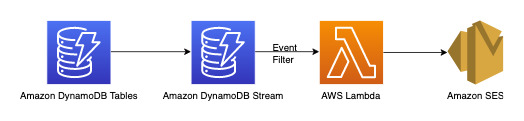
DynamoDB Streams adalah mekanisme pengambilan data perubahan untuk merekam semua aktivitas tulis pada tabel DynamoDB Anda. Anda dapat mengonfigurasi fungsi Lambda untuk memicu beberapa atau semua perubahan ini. Filter peristiwa dapat dikonfigurasi pada pemicu Lambda untuk memfilter peristiwa yang tidak relevan dengan kasus penggunaan. Dalam instans ini, kita dapat menggunakan filter untuk memicu Lambda hanya ketika komentar baru ditambahkan dan mengirimkan pemberitahuan ke ID email yang relevan yang dapat diambil dari AWS Secrets Manager atau penyimpanan kredensial lainnya.
Jalankan kueri analitik pada data mingguan
DynamoDB cocok untuk beban kerja yang utamanya difokuskan pada pemrosesan transaksional online (OLTP). Untuk 10-20% pola akses lainnya dengan persyaratan analitik, data dapat diekspor ke S3 dengan fitur Ekspor ke Amazon S3 yang dikelola tanpa berdampak pada lalu lintas langsung di tabel DynamoDB. Lihat alur kerja di bawah ini:
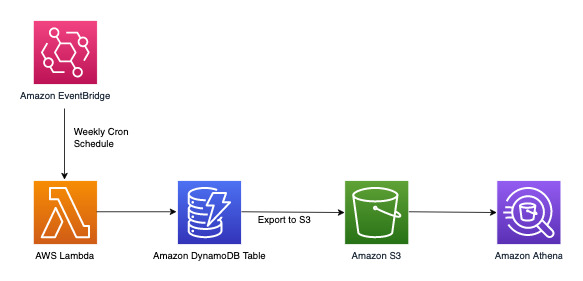
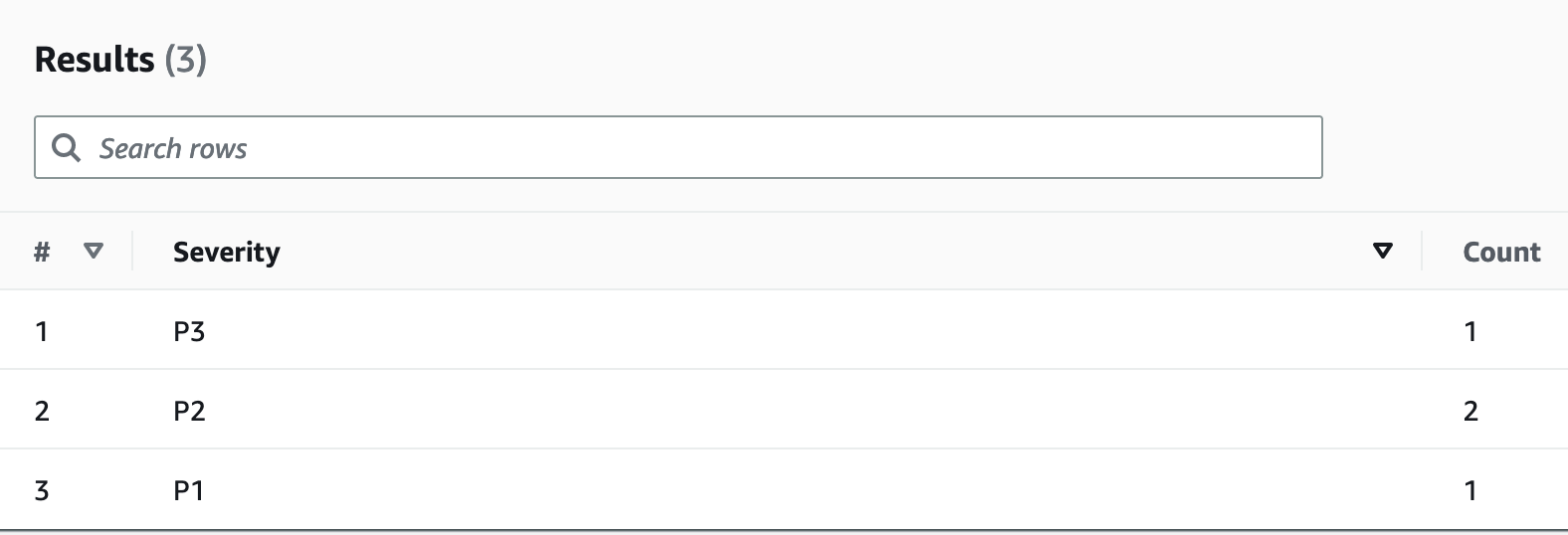
Amazon EventBridge dapat digunakan untuk memicu AWS Lambda sesuai jadwal - ini memungkinkan Anda untuk mengonfigurasi ekspresi cron agar pemanggilan Lambda berlangsung secara berkala. Lambda dapat menginvokasi panggilan API ExportToS3 dan menyimpan data DynamoDB di S3. Data S3 ini kemudian dapat diakses oleh mesin SQL seperti Amazon Athena untuk menjalankan kueri analitik pada data DynamoDB tanpa memengaruhi beban kerja transaksional langsung pada tabel. Contoh kueri Athena untuk menemukan jumlah pengaduan per tingkat keparahan akan terlihat seperti ini:
SELECT Item.severity.S as "Severity", COUNT(Item) as "Count" FROM "complaint_management"."data" WHERE NOT Item.severity.S = '' GROUP BY Item.severity.S ;
Hal ini memunculkan hasil kueri Athena berikut:
Arsipkan data yang berusia lebih dari tiga tahun
Anda dapat memanfaatkan fitur Waktu untuk Beroperasi (TTL) DynamoDB guna menghapus data usang dari tabel DynamoDB Anda tanpa biaya tambahan (kecuali dalam kasus replika tabel global untuk versi 2019.11.21 (Terbaru), di mana penghapusan TTL yang direplikasi ke Wilayah lain akan mengonsumsi kapasitas tulis). Data ini muncul dan dapat dikonsumsi dari DynamoDB Streams untuk diarsipkan ke Amazon S3. Alur kerja untuk persyaratan ini adalah sebagai berikut:
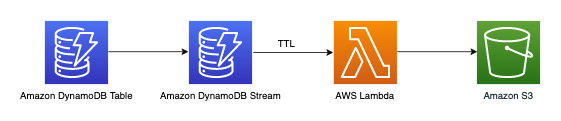
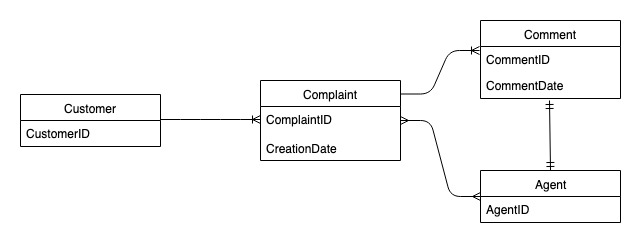
Diagram hubungan entitas sistem manajemen pengaduan
Ini adalah diagram hubungan entitas (ERD) yang akan kita gunakan untuk desain skema sistem manajemen pengaduan.
Pola akses sistem manajemen pengaduan
Ini adalah pola akses yang akan kita pertimbangkan untuk desain skema manajemen pengaduan.
-
createComplaint
-
updateComplaint
-
Perbarui SeveritybyComplaint ID
-
mendapatkan ComplaintByComplaintID
-
menambahkan CommentByComplaintID
-
mendapatkan AllCommentsByComplaintID
-
mendapatkan LatestCommentByComplaintID
-
mendapatkan AComplaintbyCustomerIDAndComplaintID
-
mendapatkan AllComplaintsByCustomerID
-
meningkat ComplaintByComplaintID
-
mendapatkan AllEscalatedComplaints
-
get EscalatedComplaintsByAgentID (order dari yang terbaru ke terlama)
-
dapatkan CommentsByAgentID (antara dua tanggal)
Evolusi desain skema sistem manajemen pengaduan
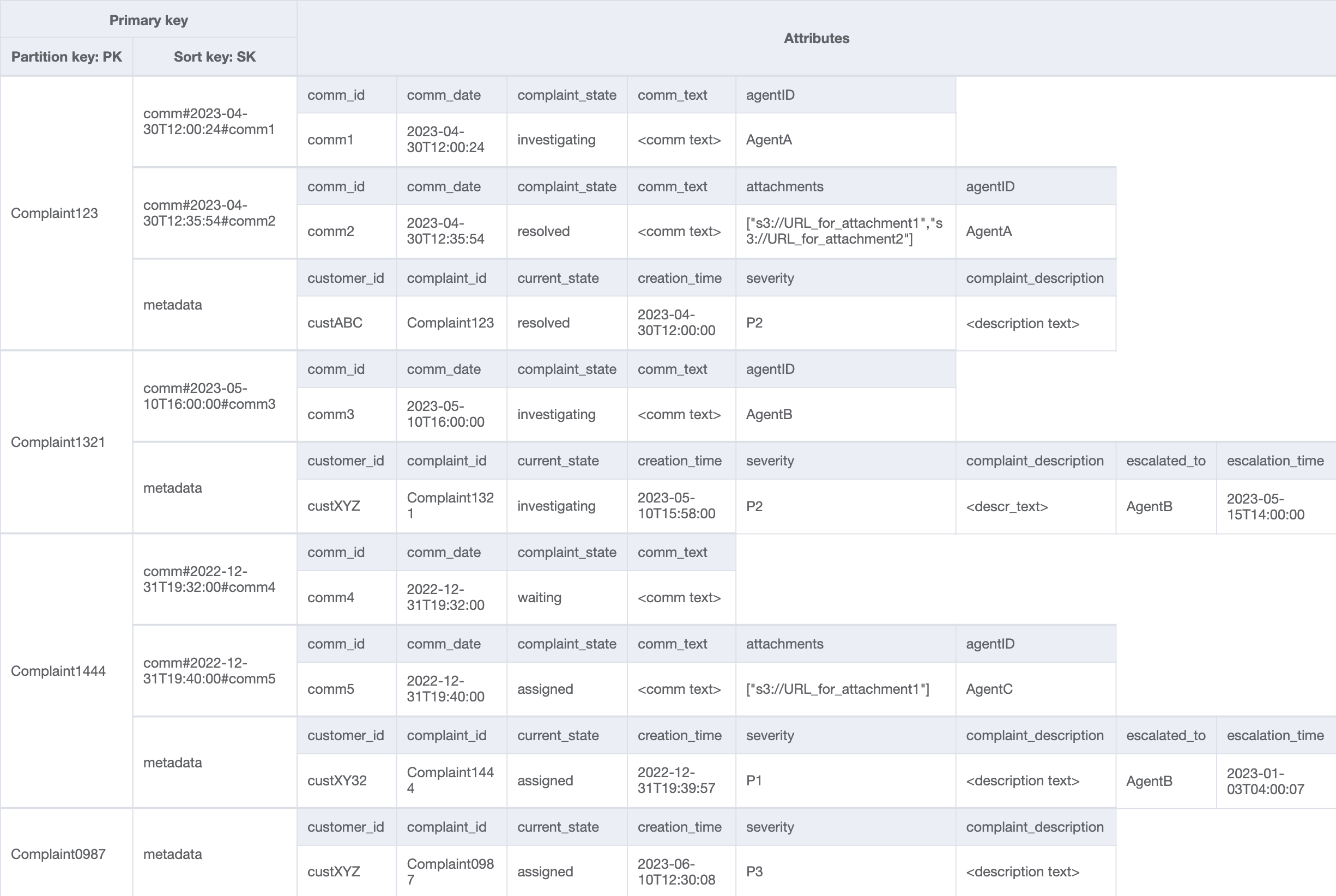
Karena ini adalah sistem manajemen pengaduan, sebagian besar pola akses berkisar pada pengaduan sebagai entitas utama. ComplaintID yang sangat penting akan memastikan distribusi data yang merata di partisi-partisi yang mendasarinya, dan juga merupakan kriteria pencarian yang paling umum untuk pola akses yang teridentifikasi. Oleh karena itu, ComplaintID adalah kandidat kunci partisi yang baik dalam set data ini.
Langkah 1: Tangani pola akses 1 (createComplaint), 2 (updateComplaint), 3 (updateSeveritybyComplaintID), dan 4 (getComplaintByComplaintID)
Kita dapat menggunakan kunci urutan umum yang disebut "metadata" (atau "AA") untuk menyimpan informasi khusus pengaduan sepertiCustomerID, State, Severity, dan CreationDate. Kita menggunakan operasi tunggal dengan PK=ComplaintID dan SK=“metadata” untuk melakukan hal berikut:
-
PutItemuntuk membuat pengaduan baru -
UpdateItemuntuk memperbarui tingkat keparahan atau bidang lain dalam metadata pengaduan -
GetItemuntuk mengambil metadata untuk pengaduan

Langkah 2: Atasi pola akses 5 (addCommentByComplaintID)
Pola akses ini membutuhkan model hubungan satu-ke-banyak antara pengaduan dan komentar tentang pengaduan. Kita akan menggunakan teknik partisi vertikal di sini untuk menggunakan kunci urutan dan membuat koleksi item dengan berbagai jenis data. Jika kita melihat pola akses 6 (getAllCommentsByComplaintID) dan 7 (getLatestCommentByComplaintID), kita tahu bahwa komentar perlu diurutkan berdasarkan waktu. Beberapa komentar dapat masuk pada saat yang sama, sehingga kita dapat menggunakan teknik kunci urutan komposit untuk menambahkan waktu dan CommentID di atribut kunci urutan.
Opsi lain untuk menangani kemungkinan benturan komentar seperti itu adalah dengan meningkatkan perincian stempel waktu atau menambahkan angka tambahan sebagai sufiks alih-alih menggunakan Comment_ID. Dalam hal ini, kita akan mengawali nilai kunci urutan untuk item yang sesuai dengan komentar dengan “comm#” untuk mengaktifkan operasi berbasis kisaran.
Kita juga perlu memastikan bahwa currentState dalam metadata pengaduan mencerminkan keadaan saat komentar baru ditambahkan. Menambahkan komentar mungkin menunjukkan bahwa pengaduan telah ditugaskan ke agen atau telah diselesaikan dan lain sebagainya. Untuk menggabungkan penambahan komentar dan pembaruan status saat ini dalam metadata keluhan, dengan cara semua-atau-tidak sama sekali, kami akan menggunakan API. TransactWriteItems Status tabel kini terlihat seperti ini:

Kita tambahkan beberapa data lagi dalam tabel dan juga tambahkan ComplaintID sebagai bidang terpisah dari PK kita untuk pemeriksaan model di masa depan jika kita membutuhkan indeks tambahan di ComplaintID. Perhatikan juga bahwa beberapa komentar mungkin memiliki lampiran yang akan kita simpan di Amazon Simple Storage Service dan hanya mempertahankan referensi atau URL-nya di DynamoDB. Hal ini adalah praktik terbaik untuk menjaga basis data transaksional seramping mungkin untuk mengoptimalkan biaya dan performa. Data sekarang terlihat seperti ini:
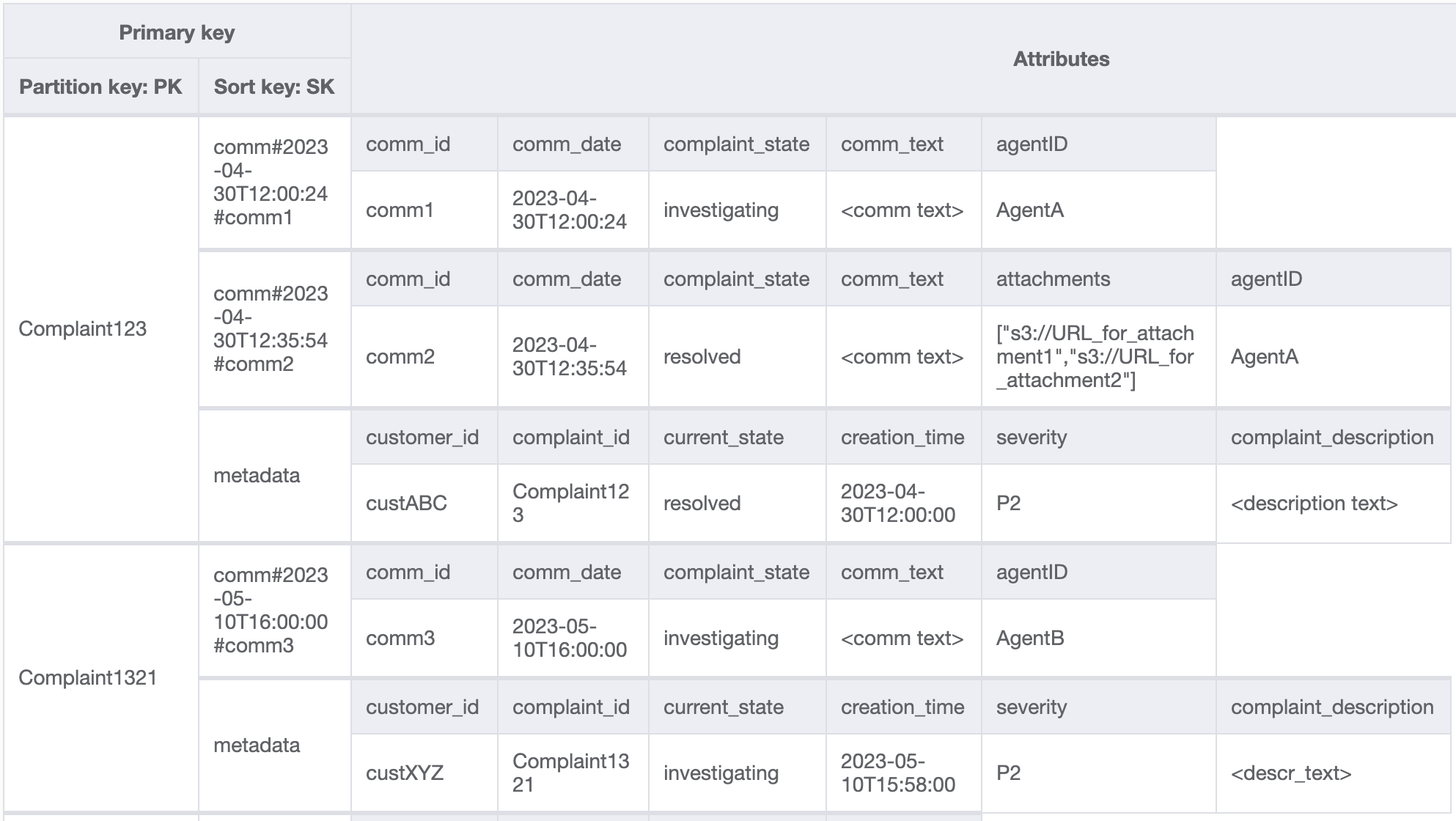
Langkah 3: Atasi pola akses 6 (getAllCommentsByComplaintID) dan 7 (getLatestCommentByComplaintID)
Untuk mendapatkan semua komentar untuk pengaduan, kita dapat menggunakan operasi query dengan kondisi begins_with pada kunci urutan. Daripada menghabiskan kapasitas baca tambahan untuk membaca entri metadata dan kemudian menyaring hasil yang relevan, memiliki kondisi kunci urutan seperti ini membantu kita untuk hanya membaca apa yang kita butuhkan. Misalnya, operasi kueri dengan PK=Complaint123 dan SK begins_with comm# akan mengembalikan yang berikut saat melewatkan entri metadata:
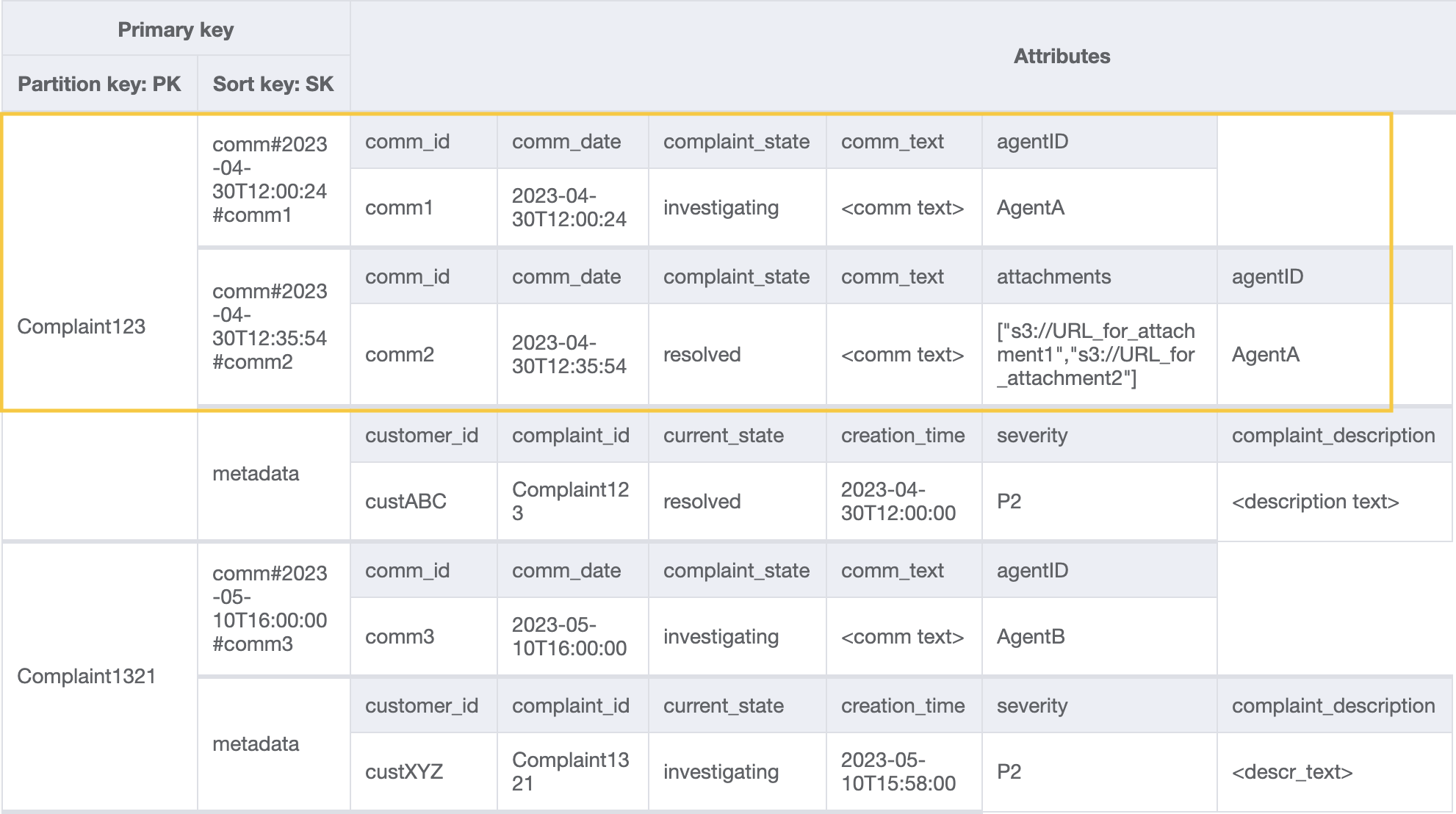
Karena kita memerlukan komentar terbaru untuk pengaduan dalam pola 7 (getLatestCommentByComplaintID), mari kita gunakan dua parameter kueri tambahan:
-
ScanIndexForwardharus diatur ke False untuk mendapatkan hasil yang diurutkan dalam urutan menurun -
Limitharus diatur ke 1 untuk mendapatkan (hanya satu) komentar terbaru
Mirip dengan pola akses 6 (getAllCommentsByComplaintID), kita melewatkan entri metadata menggunakan begins_with comm# sebagai kondisi kunci urutan. Sekarang, Anda dapat melakukan pola akses 7 pada desain ini menggunakan operasi kueri dengan PK=Complaint123 dan SK=begins_with comm#, ScanIndexForward=False, serta Limit 1. Item yang ditargetkan berikut akan dikembalikan sebagai hasilnya:
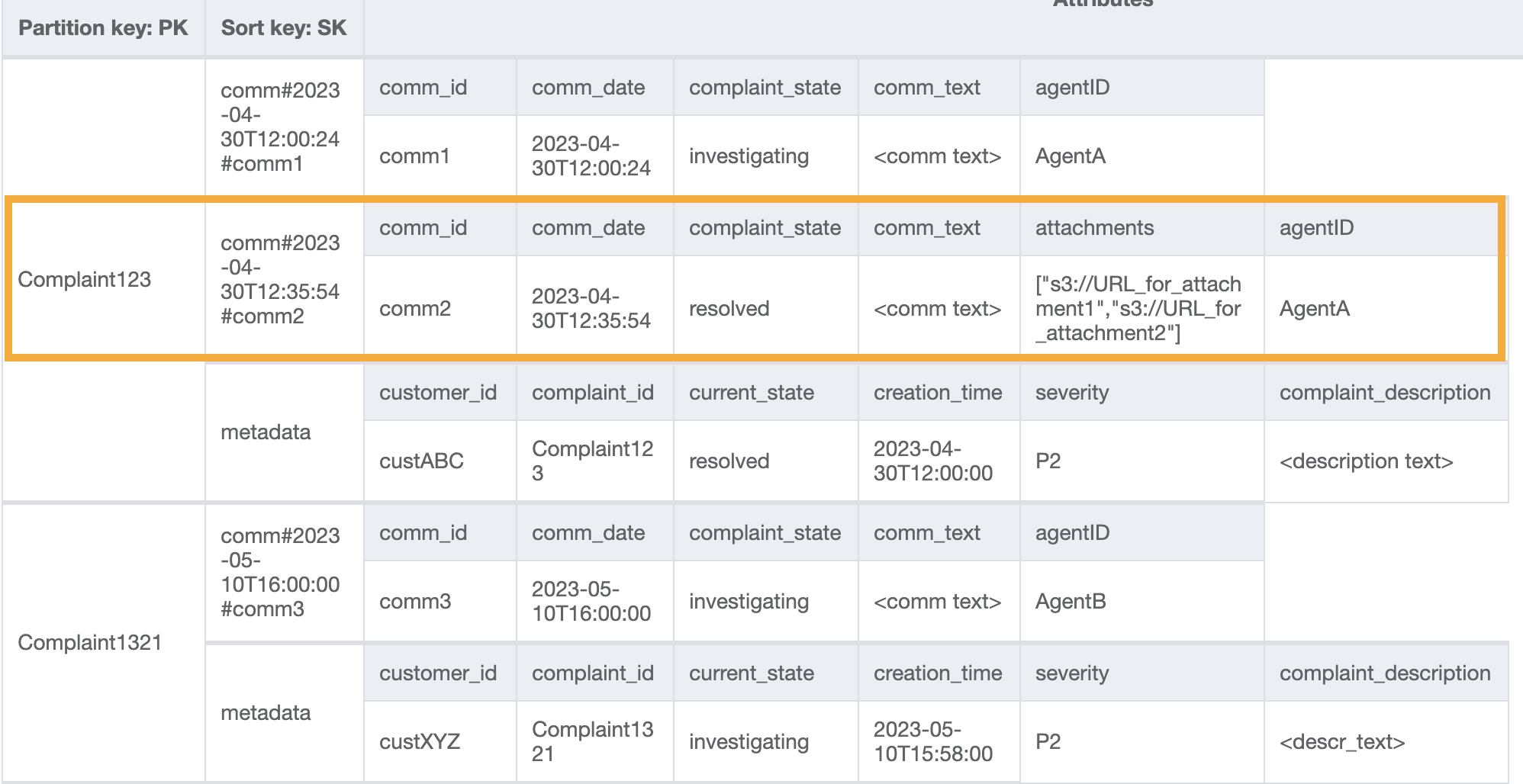
Mari tambahkan lebih banyak data dummy ke tabel.
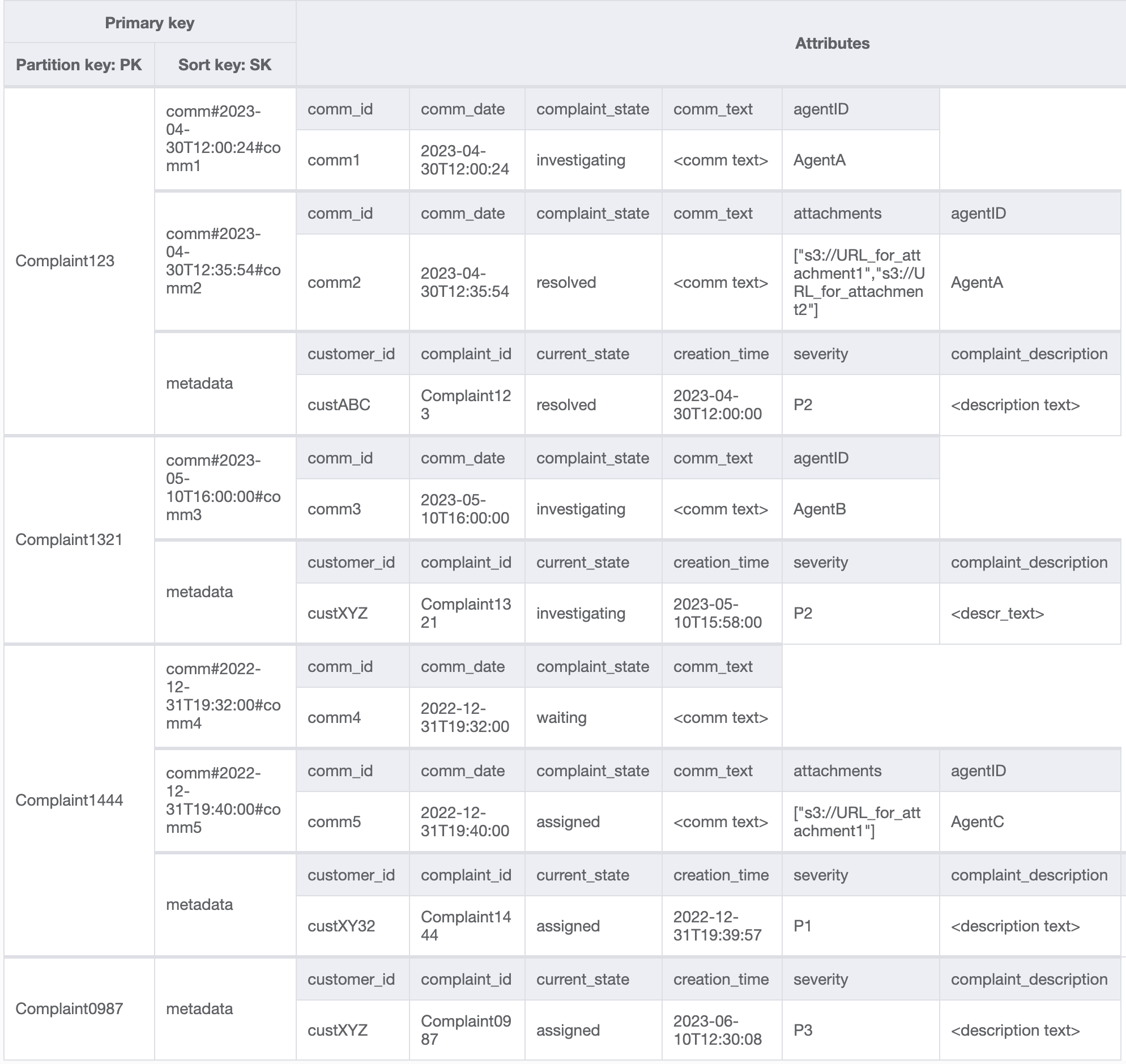
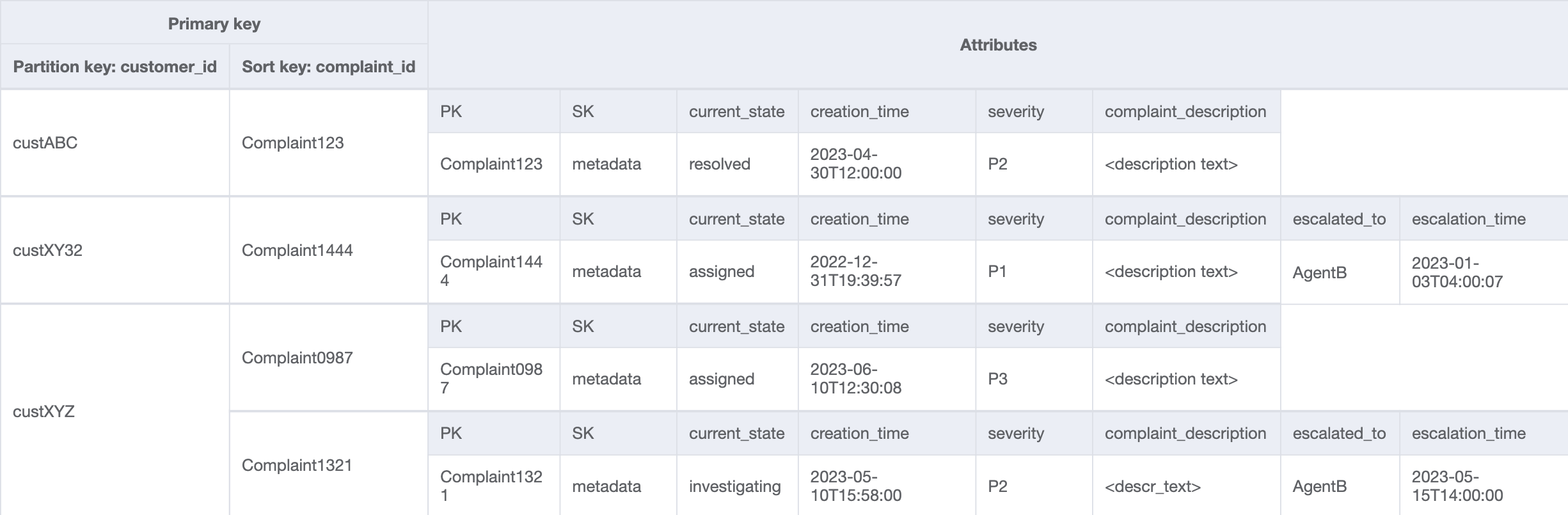
Langkah 4: Atasi pola akses 8 (getAComplaintbyCustomerIDAndComplaintID) dan 9 (getAllComplaintsByCustomerID)
Pola akses 8 (getAComplaintbyCustomerIDAndComplaintID) dan 9 (getAllComplaintsByCustomerID) memperkenalkan kriteria pencarian baru:CustomerID. Mengambilnya dari tabel yang ada memerlukan Scan yang mahal untuk membaca semua data dan kemudian memfilter item yang relevan untuk CustomerID yang bersangkutan. Kita dapat membuat pencarian ini lebih efisien dengan membuat indeks sekunder global (GSI) dengan CustomerID sebagai kunci partisi. Mengingat hubungan satu-ke-banyak antara pelanggan dan pengaduan serta pola akses 9 (getAllComplaintsByCustomerID), ComplaintID akan menjadi kandidat yang tepat untuk kunci urutan.
Data di GSI akan terlihat seperti ini:
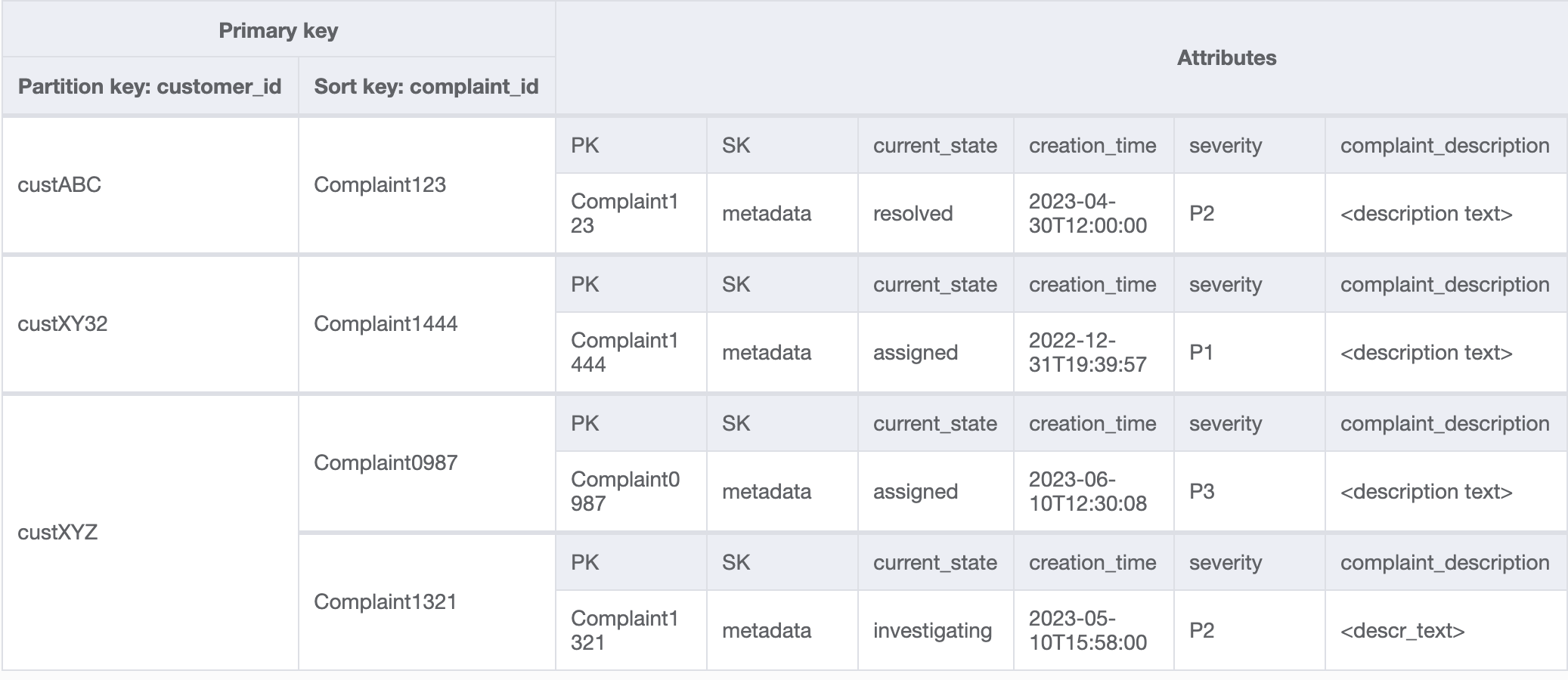
Contoh kueri pada GSI ini untuk pola akses 8 (getAComplaintbyCustomerIDAndComplaintID) adalah: customer_id=custXYZ, sort key=Complaint1321. Hasilnya akan menjadi:
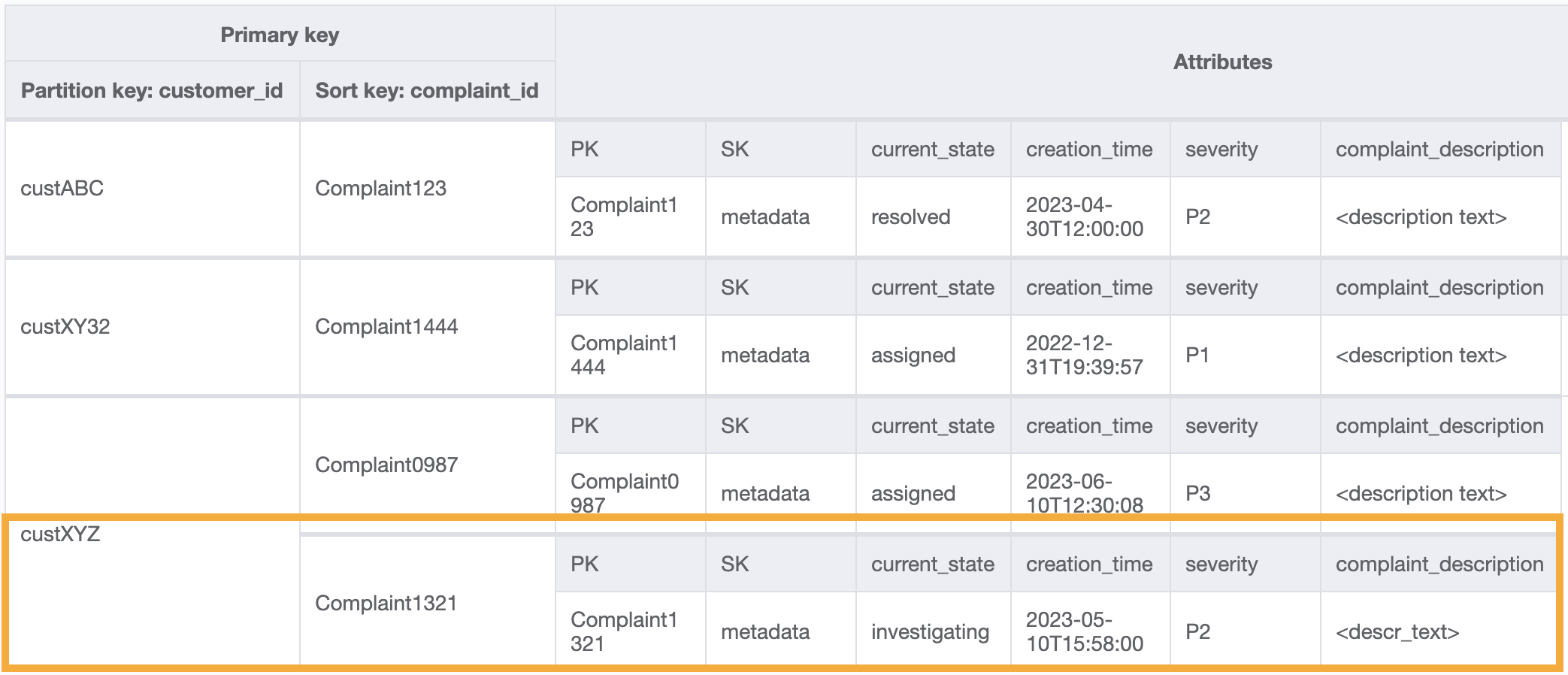
Untuk mendapatkan semua pengaduan bagi pelanggan untuk pola akses 9 (getAllComplaintsByCustomerID), kueri pada GSI adalah: customer_id=custXYZ sebagai kondisi kunci partisi. Hasilnya akan menjadi:
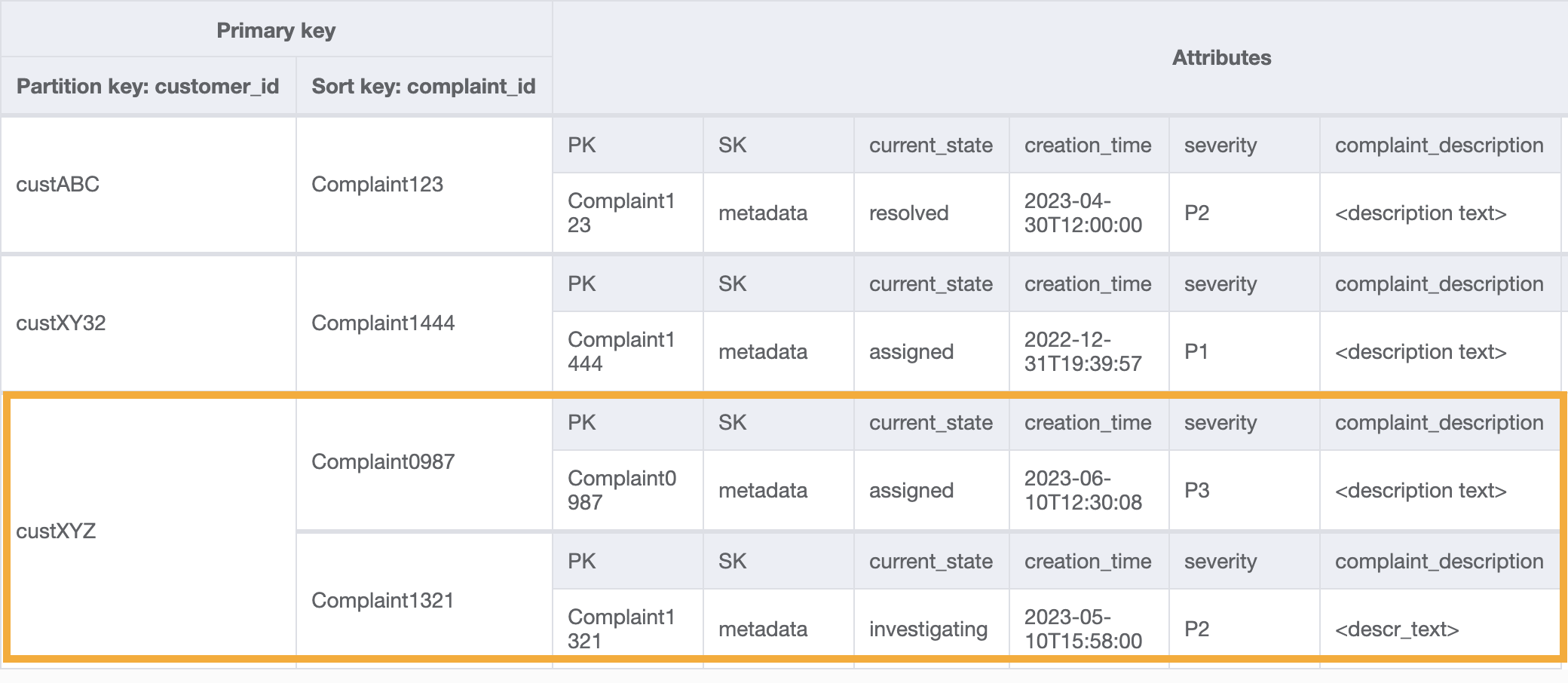
Langkah 5: Atasi pola akses 10 (escalateComplaintByComplaintID)
Akses ini memperkenalkan aspek eskalasi. Untuk mengeskalasi pengaduan, kita dapat menggunakan UpdateItem untuk menambahkan atribut seperti escalated_to dan escalation_time ke item metadata pengaduan yang ada. DynamoDB menyediakan desain skema fleksibel yang berarti satu set atribut non-kunci dapat dibuat seragam atau terpisah di berbagai item. Lihat contohnya di bawah ini:
UpdateItem with PK=Complaint1444, SK=metadata
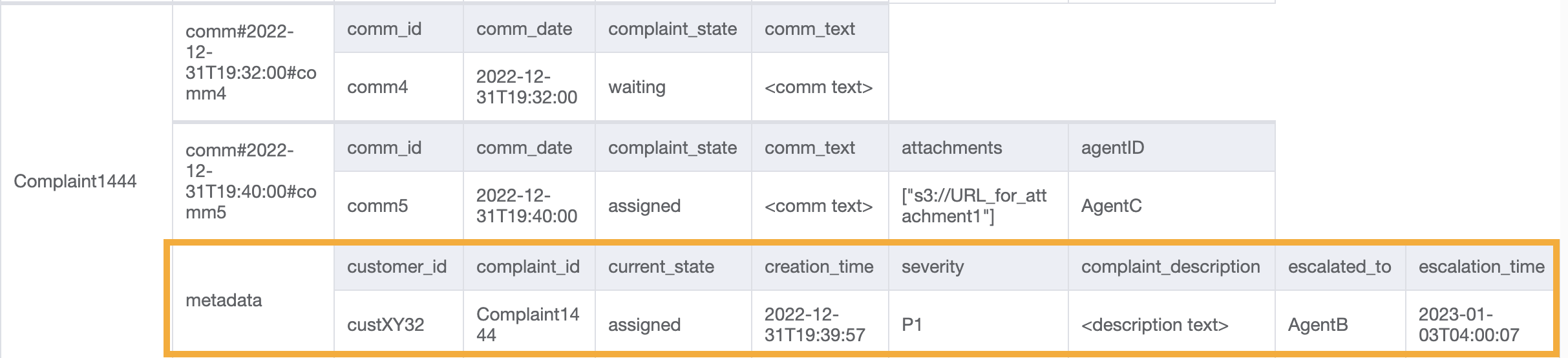
Langkah 6: Atasi pola akses 11 (getAllEscalatedComplaints) dan 12 (getEscalatedComplaintsByAgentID)
Hanya segelintir pengaduan yang diharapkan akan dieskalasikan dari seluruh set data. Oleh karena itu, membuat indeks pada atribut terkait eskalasi akan menghasilkan pencarian yang efisien serta penyimpanan GSI yang hemat biaya. Kita bisa melakukan hal ini dengan memanfaatkan teknik indeks jarang. GSI dengan kunci partisi sebagai escalated_to dan kunci urutan sebagai escalation_time akan terlihat seperti ini:

Untuk mendapatkan semua pengaduan yang dieskalasikan untuk pola akses 11 (getAllEscalatedComplaints), kita cukup memindai GSI ini. Perhatikan bahwa pemindaian ini akan berperforma baik dan hemat biaya karena ukuran GSI. Untuk mendapatkan pengaduan yang dieskalasikan untuk agen tertentu (pola akses 12 (getEscalatedComplaintsByAgentID)), kunci partisi akan berupa escalated_to=agentID dan kita mengatur ScanIndexForward ke False untuk mengurutkan dari yang terbaru ke yang terlama.
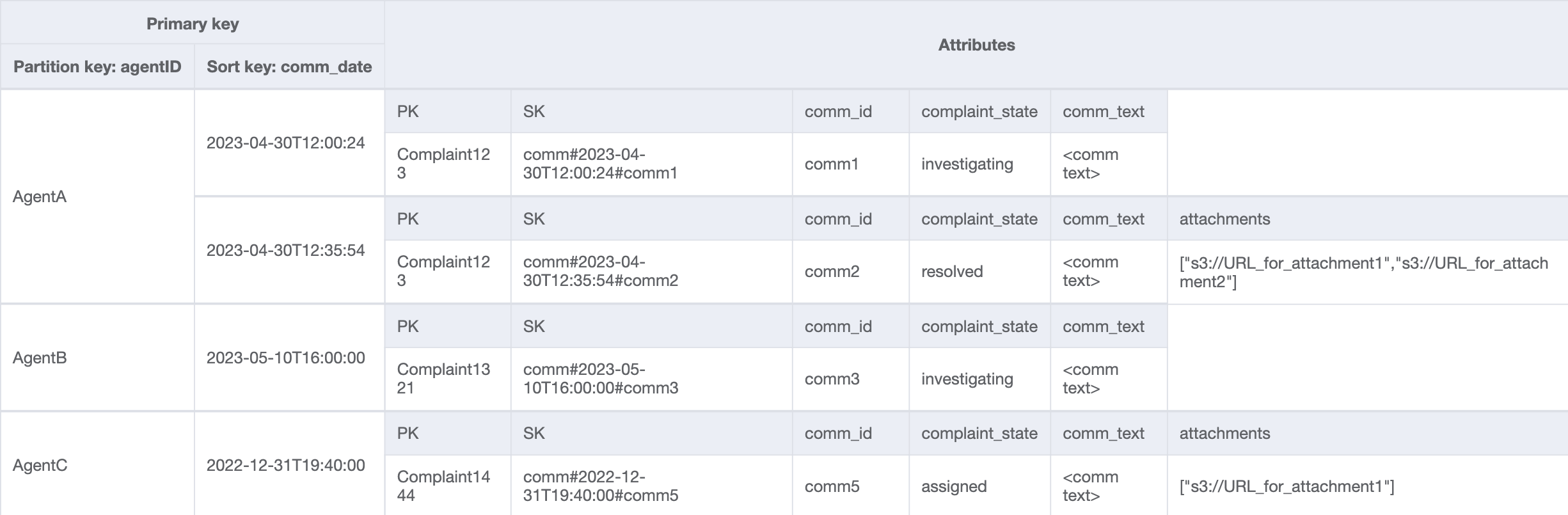
Langkah 7: Atasi pola akses 13 (getCommentsByAgentID)
Untuk pola akses terakhir, kita perlu melakukan pencarian berdasarkan dimensi baru: AgentID. Kita juga membutuhkan pengurutan berbasis waktu untuk membaca komentar di antara dua tanggal, jadi kita membuat GSI dengan agent_id sebagai kunci partisi dan comm_date sebagai kunci urutan. Data dalam GSI ini akan terlihat seperti berikut:
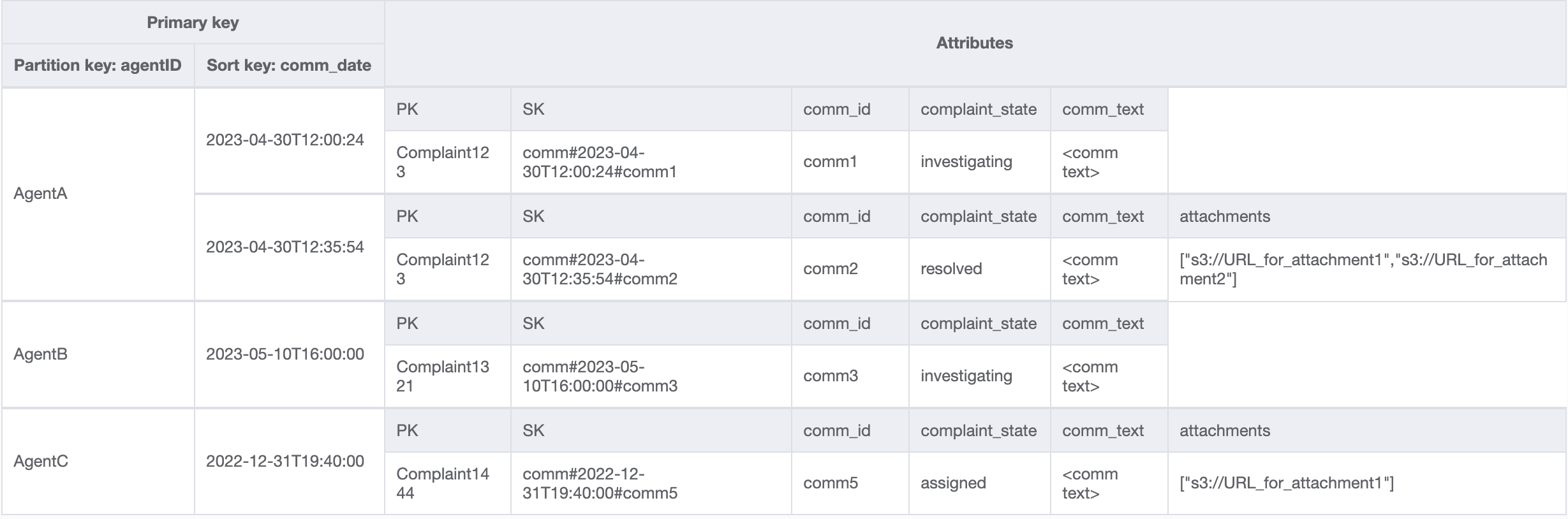
Contoh kueri pada GSI ini adalah partition key agentID=AgentA dan sort key=comm_date between (2023-04-30T12:30:00, 2023-05-01T09:00:00), yang hasilnya adalah:
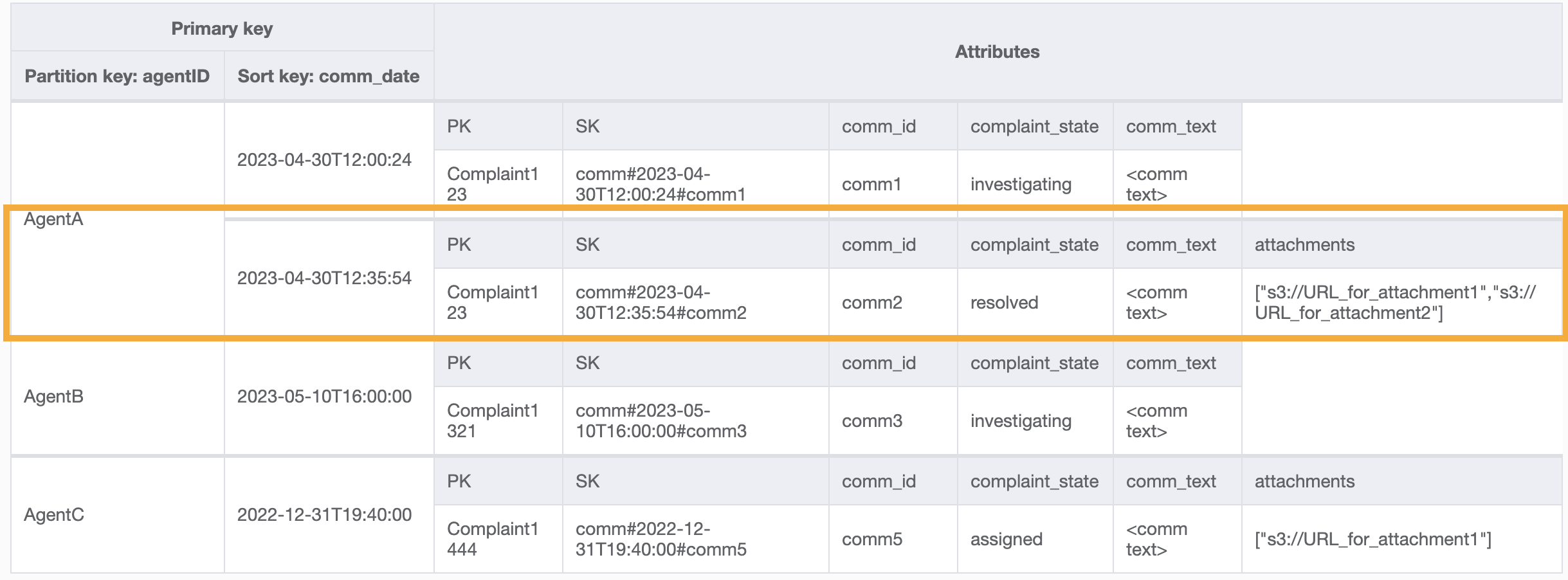
Semua pola akses dan bagaimana desain skema mengatasinya dirangkum dalam tabel di bawah ini:
| Pola akses | table/GSIDasar/LSI | Operasi | Nilai kunci partisi | Nilai kunci urutan | Lainnya conditions/filters |
|---|---|---|---|---|---|
| createComplaint | Tabel dasar | PutItem | PK=complaint_id | SK=metadata | |
| updateComplaint | Tabel dasar | UpdateItem | PK=complaint_id | SK=metadata | |
| Perbarui SeveritybyComplaint ID | Tabel dasar | UpdateItem | PK=complaint_id | SK=metadata | |
| mendapatkan ComplaintByComplaintID | Tabel dasar | GetItem | PK=complaint_id | SK=metadata | |
| menambahkan CommentByComplaintID | Tabel dasar | TransactWriteItems | PK=complaint_id | SK=metadata, SK=comm#comm_date#comm_id | |
| mendapatkan AllCommentsByComplaintID | Tabel dasar | Kueri | PK=complaint_id | SK begins_with "comm#" | |
| mendapatkan LatestCommentByComplaintID | Tabel dasar | Kueri | PK=complaint_id | SK begins_with "comm#" | scan_index_forward=False, Limit 1 |
| mendapatkan AComplaintbyCustomerIDAndComplaintID | Customer_complaint_GSI | Kueri | customer_id=customer_id | complaint_id = complaint_id | |
| mendapatkan AllComplaintsByCustomerID | Customer_complaint_GSI | Kueri | customer_id=customer_id | N/A | |
| meningkat ComplaintByComplaintID | Tabel dasar | UpdateItem | PK=complaint_id | SK=metadata | |
| mendapatkan AllEscalatedComplaints | Escalations_GSI | Scan | N/A | N/A | |
| get EscalatedComplaintsByAgentID (order dari yang terbaru ke terlama) | Escalations_GSI | Kueri | escalated_to=agent_id | N/A | scan_index_forward=False |
| dapatkan CommentsByAgentID (antara dua tanggal) | Agents_Comments_GSI | Kueri | agent_id=agent_id | SK antara (date1, date2) |
Skema akhir sistem manajemen pengaduan
Berikut adalah desain skema akhir. Untuk mengunduh desain skema ini sebagai file JSON, lihat Contoh DynamoDB di.
Tabel dasar
Customer_Complaint_GSI
Escalations_GSI

Agents_Comments_GSI
Menggunakan NoSQL Workbench dengan desain skema ini
Anda dapat mengimpor skema akhir ini ke NoSQL Workbench, sebuah alat visual yang menyediakan fitur pemodelan data, visualisasi data, dan pengembangan kueri untuk DynamoDB, guna mengeksplorasi dan mengedit proyek baru Anda lebih lanjut. Ikuti langkah-langkah berikut untuk memulai:
-
Unduh NoSQL Workbench. Untuk informasi selengkapnya, lihat Unduh NoSQL Workbench untuk DynamoDB.
-
Unduh file skema JSON yang tercantum di atas, yang sudah dalam format model NoSQL Workbench.
-
Impor file skema JSON ke NoSQL Workbench. Untuk informasi selengkapnya, lihat Mengimpor model data yang ada.
-
Setelah mengimpor model data ke NoSQL Workbench, Anda dapat mengeditnya. Lihat informasi yang lebih lengkap di Mengedit model data yang ada.
