Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Menggunakan Indeks Sekunder Global di DynamoDB
Beberapa aplikasi mungkin perlu melakukan banyak jenis kueri, menggunakan berbagai atribut berbeda sebagai kriteria kueri. Untuk mendukung persyaratan ini, Anda dapat membuat satu atau beberapa indeks sekunder global dan mengeluarkan permintaan Query terhadap indeks ini di Amazon DynamoDB.
Topik
Skenario: Menggunakan Indeks Sekunder Global
Sebagai ilustrasi, pertimbangkan tabel bernama GameScores yang melacak pengguna dan skor untuk aplikasi game seluler. Setiap item dalam GameScores diidentifikasi dengan kunci partisi (UserId) dan kunci urutan (GameTitle). Diagram berikut menunjukkan bagaimana item dalam tabel akan diatur. (Tidak semua atribut ditampilkan.)
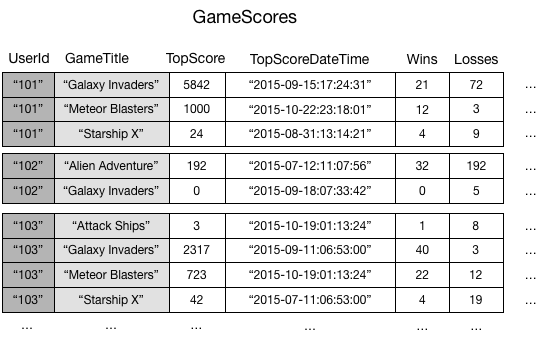
Sekarang, anggaplah Anda ingin menulis aplikasi papan peringkat untuk menampilkan skor teratas untuk setiap game. Kueri yang menentukan atribut kunci (UserId dan GameTitle) akan sangat efisien. Namun, jika aplikasi perlu mengambil data dari GameScores berdasarkan GameTitle saja, aplikasi tersebut perlu menggunakan operasi Scan. Karena lebih banyak item ditambahkan ke tabel, pemindaian semua data akan lambat dan tidak efisien. Hal ini membuat pertanyaan-pertanyaan seperti berikut ini sulit dijawab:
-
Berapa skor tertinggi yang pernah tercatat untuk game Meteor Blasters?
-
Pengguna mana yang memiliki skor tertinggi untuk Galaxy Invaders?
-
Berapa rasio tertinggi untuk kemenangan vs kekalahan?
Untuk mempercepat kueri pada atribut non-kunci, Anda dapat membuat indeks sekunder global. Indeks sekunder global berisi pilihan atribut dari tabel dasar, tetapi atribut tersebut diatur oleh kunci primer yang berbeda dari tabel. Kunci indeks tidak perlu memiliki atribut kunci apa pun dari tabel. Bahkan tidak perlu memiliki skema kunci yang sama dengan tabel.
Misalnya, Anda dapat membuat indeks sekunder global bernama GameTitleIndex, dengan kunci partisi GameTitle dan kunci urutan TopScore. Atribut kunci primer tabel dasar selalu diproyeksikan ke dalam indeks, sehingga atribut UserId juga ada. Diagram berikut menunjukkan seperti apa tampilan indeks GameTitleIndex.
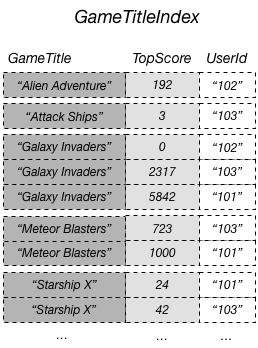
Sekarang Anda dapat meminta GameTitleIndex dan dengan mudah mendapatkan skor untuk Meteor Blasters. Hasilnya diurutkan berdasarkan nilai kunci urutan, TopScore. Jika Anda mangatur parameter ScanIndexForward ke false, hasilnya ditampilkan dalam urutan menurun, sehingga skor tertinggi ditampilkan terlebih dahulu.
Setiap indeks sekunder global harus memiliki kunci partisi, dan dapat memiliki kunci urutan opsional. Skema kunci indeks dapat berbeda dari skema tabel dasar. Anda dapat memiliki tabel dengan kunci primer sederhana (kunci partisi), dan membuat indeks sekunder global dengan kunci primer komposit (kunci partisi dan kunci urutan)—atau sebaliknya. Atribut kunci indeks dapat terdiri dari atribut String, Number, atau Binary tingkat atas dari tabel dasar. Jenis skalar, jenis dokumen, dan jenis kumpulan lain tidak diperbolehkan.
Anda dapat memproyeksikan atribut tabel dasar lain ke dalam indeks jika ingin. Saat Anda mengkueri indeks, DynamoDB dapat mengambil atribut yang diproyeksikan ini secara efisien. Namun, kueri indeks sekunder global tidak dapat mengambil atribut dari tabel dasar. Misalnya, jika Anda mengkueri GameTitleIndex seperti yang ditunjukkan pada diagram sebelumnya, kueri tidak dapat mengakses atribut non-kunci selain TopScore (meskipun atribut kunci GameTitle dan UserId akan diproyeksikan secara otomatis).
Dalam tabel DynamoDB, setiap nilai kunci harus unik. Namun, nilai kunci dalam indeks sekunder global tidak perlu unik. Sebagai ilustrasi, anggaplah sebuah game bernama Comet Quest sangat sulit, dengan banyak pengguna baru yang telah mencoba tetapi gagal mendapatkan skor di atas nol. Berikut adalah beberapa data yang dapat mewakili hal tersebut.
| UserId | GameTitle | TopScore |
|---|---|---|
| 123 | Comet Quest | 0 |
| 201 | Comet Quest | 0 |
| 301 | Comet Quest | 0 |
Ketika data ini ditambahkan ke tabel GameScores, DynamoDB menyebarkannya ke GameTitleIndex. Jika kita kemudian mengkueri indeks menggunakan Comet Quest untuk GameTitle dan 0 untuk TopScore, data berikut dikembalikan.
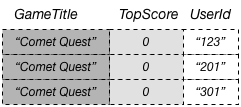
Hanya item dengan nilai kunci tertentu yang muncul dalam respons. Dalam kumpulan data itu, item-item tersebut tidak berada dalam urutan tertentu.
Indeks sekunder global hanya melacak item data yang atribut utamanya benar-benar ada. Misalnya, katakanlah Anda menambahkan item baru ke tabel GameScores, tetapi hanya menyediakan atribut kunci primer yang diperlukan.
| UserId | GameTitle |
|---|---|
| 400 | Comet Quest |
Karena Anda tidak menentukan atribut TopScore, DynamoDB tidak akan menyebarkan item ini ke GameTitleIndex. Jadi, jika mengkueri GameScores untuk semua item Comet Quest, Anda akan mendapatkan empat item berikut.
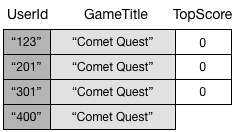
Kueri serupa pada GameTitleIndex masih akan mengembalikan tiga item, bukan empat. Ini karena item dengan TopScore yang tidak ada tidak disebarkan ke indeks.
Proyeksi atribut
Proyeksi adalah kumpulan atribut yang disalin dari tabel ke indeks sekunder. Kunci partisi dan kunci urutan tabel selalu diproyeksikan ke dalam indeks; Anda dapat memproyeksikan atribut lain untuk mendukung persyaratan kueri aplikasi Anda. Saat Anda mengkueri indeks, Amazon DynamoDB dapat mengakses atribut apa pun dalam proyeksi seolah-olah atribut tersebut berada dalam tabelnya sendiri.
Saat membuat indeks sekunder, Anda perlu menentukan atribut yang akan diproyeksikan ke dalam indeks. DynamoDB menyediakan tiga opsi berbeda untuk ini:
-
KEYS_ONLY – Setiap item dalam indeks hanya terdiri dari kunci partisi tabel dan nilai kunci urutan, ditambah nilai kunci indeks. Opsi
KEYS_ONLYmenghasilkan indeks sekunder sekecil mungkin. -
INCLUDE – Selain atribut yang dijelaskan dalam
KEYS_ONLY, indeks sekunder akan menyertakan atribut non-kunci lain yang Anda tentukan. -
ALL – Indeks sekunder menyertakan semua atribut dari tabel sumber. Karena semua data tabel diduplikasi dalam indeks, proyeksi
ALLmenghasilkan indeks sekunder sebesar yang mungkin.
Pada diagram sebelumnya, GameTitleIndex hanya memiliki satu atribut yang diproyeksikan: UserId. Jadi, meskipun aplikasi dapat secara efisien menentukan UserId dari pencetak skor terbanyak untuk setiap game menggunakan GameTitle dan TopScore dalam kueri, aplikasi tidak dapat secara efisien menentukan rasio kemenangan vs. kekalahan tertinggi untuk pencetak skor terbanyak. Untuk melakukannya, aplikasi harus melakukan kueri tambahan di tabel dasar untuk mengambil kemenangan dan kerugian untuk masing-masing pencetak gol terbanyak. Cara yang lebih efisien untuk mendukung kueri pada data ini adalah dengan memproyeksikan atribut-atribut ini dari tabel dasar ke dalam indeks sekunder global, seperti yang ditunjukkan dalam diagram ini.
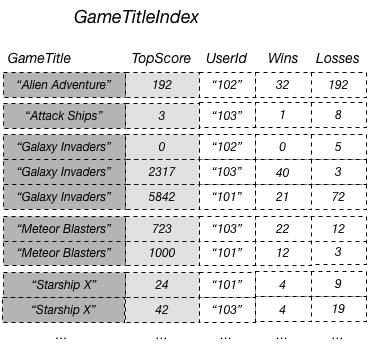
Karena atribut non-kunci Wins dan Losses diproyeksikan ke dalam indeks, aplikasi dapat menentukan rasio kemenangan vs. kekalahan untuk game apa pun, atau untuk kombinasi game dan ID pengguna mana pun.
Saat memilih atribut untuk diproyeksikan ke dalam indeks sekunder global, Anda harus mempertimbangkan tradeoff antara biaya throughput yang disediakan dan biaya penyimpanan:
-
Jika Anda hanya perlu mengakses beberapa atribut dengan latensi serendah mungkin, pertimbangkan untuk hanya memproyeksikan atribut tersebut ke dalam indeks sekunder global. Semakin kecil indeks, semakin sedikit biaya penyimpanannya, dan semakin sedikit pula biaya tulis Anda.
-
Jika aplikasi Anda sering mengakses beberapa atribut non-kunci, sebaiknya Anda memproyeksikan atribut tersebut ke dalam indeks sekunder global. Biaya penyimpanan tambahan untuk indeks sekunder global mengimbangi biaya melakukan pemindaian tabel yang sering dilakukan.
-
Jika sering mengakses sebagian besar atribut non-kunci, Anda dapat memproyeksikan atribut ini—atau bahkan seluruh tabel dasar— ke dalam indeks sekunder global. Hal ini akan memberi Anda fleksibilitas maksimum. Namun, biaya penyimpanan Anda akan meningkat, atau bahkan berlipat ganda.
-
Jika aplikasi Anda jarang mengkueri tabel, tetapi harus melakukan banyak penulisan atau pembaruan terhadap data dalam tabel, pertimbangkan untuk memproyeksikan
KEYS_ONLY. Indeks sekunder global akan berukuran minimal, tetapi akan tetap tersedia jika diperlukan untuk aktivitas kueri.
Multi-attribute skema kunci
Global Secondary Indexes mendukung kunci multi-atribut, memungkinkan Anda untuk membuat kunci partisi dan mengurutkan kunci dari beberapa atribut. Dengan kunci multi-atribut, Anda dapat membuat kunci partisi dari hingga empat atribut dan kunci pengurutan dari hingga empat atribut, dengan total hingga delapan atribut per skema kunci.
Multi-attribute kunci menyederhanakan model data Anda dengan menghilangkan kebutuhan untuk menggabungkan atribut secara manual menjadi kunci sintetis. Alih-alih membuat string komposit sepertiTOURNAMENT#WINTER2024#REGION#NA-EAST, Anda dapat menggunakan atribut alami dari model domain Anda secara langsung. DynamoDB menangani logika kunci komposit secara otomatis, melakukan hashing beberapa atribut kunci partisi bersama-sama untuk distribusi data dan mempertahankan urutan pengurutan hierarkis di beberapa atribut kunci pengurutan.
Misalnya, pertimbangkan sistem turnamen game di mana Anda ingin mengatur pertandingan berdasarkan turnamen dan wilayah. Dengan kunci multi-atribut, Anda dapat mendefinisikan kunci partisi Anda sebagai dua atribut terpisah: tournamentId danregion. Demikian pula, Anda dapat menentukan kunci pengurutan Anda menggunakan beberapa atribut seperti roundbracket,, dan matchId untuk membuat hierarki alami. Pendekatan ini membuat data Anda diketik dan kode Anda bersih, tanpa manipulasi string atau penguraian.
Saat Anda menanyakan indeks sekunder global dengan kunci multi-atribut, Anda harus menentukan semua atribut kunci partisi menggunakan kondisi kesetaraan. Untuk mengurutkan atribut kunci, Anda dapat menanyakannya dari kiri ke kanan dalam urutan yang ditentukan dalam skema kunci. Ini berarti Anda dapat menanyakan atribut kunci sortir pertama saja, dua atribut pertama bersama-sama, atau semua atribut bersama-sama, tetapi Anda tidak dapat melewati atribut di tengah. Kondisi ketidaksetaraan seperti>,<,BETWEEN, atau begins_with() harus menjadi kondisi terakhir dalam kueri Anda.
Multi-attribute kunci bekerja sangat baik saat membuat indeks sekunder global pada tabel yang ada. Anda dapat menggunakan atribut yang sudah ada di tabel Anda tanpa mengisi kembali kunci sintetis di seluruh data Anda. Ini membuatnya mudah untuk menambahkan pola kueri baru ke aplikasi Anda dengan membuat indeks yang mengatur ulang data Anda menggunakan kombinasi atribut yang berbeda.
Setiap atribut dalam kunci multi-atribut dapat memiliki tipe datanya sendiri: String (S), Number (N), atau Binary (B). Saat memilih tipe data, pertimbangkan bahwa Number atribut mengurutkan secara numerik tanpa memerlukan padding nol, sementara atribut mengurutkan secara leksikografis. String Misalnya, jika Anda menggunakan Number tipe untuk atribut skor, nilai 5, 50, 500, dan 1000 diurutkan dalam urutan numerik alami. Nilai yang sama dengan String tipe akan diurutkan sebagai “1000", “5", “50", “500" kecuali Anda menutupinya dengan angka nol di depan.
Saat mendesain kunci multi-atribut, urutkan atribut Anda dari yang paling umum ke yang paling spesifik. Untuk kunci partisi, gabungkan atribut yang selalu ditanyakan bersama dan yang menyediakan distribusi data yang baik. Untuk kunci sortir, tempatkan atribut yang sering ditanyakan terlebih dahulu dalam hierarki untuk memaksimalkan fleksibilitas kueri. Urutan ini memungkinkan Anda untuk menanyakan pada tingkat perincian apa pun yang cocok dengan pola akses Anda.
Lihat Kunci multi-atribut contoh implementasi untuk.
Membaca data dari Indeks Sekunder Global
Anda dapat mengambil item dari indeks sekunder global menggunakan operasi Query dan Scan. Operasi GetItem dan BatchGetItem tidak dapat digunakan pada indeks sekunder global.
Mengkueri Indeks Sekunder Global
Anda dapat menggunakan operasi Query untuk mengakses satu atau beberapa item dalam indeks sekunder global. Kueri harus menentukan nama tabel dasar dan nama indeks yang ingin Anda gunakan, atribut yang akan dihasilkan dalam hasil kueri, dan syarat kueri apa pun yang ingin Anda terapkan. DynamoDB dapat menampilkan hasil dalam urutan menaik atau menurun.
Pertimbangkan data berikut yang dihasilkan dari Query yang meminta data game untuk aplikasi papan peringkat.
{ "TableName": "GameScores", "IndexName": "GameTitleIndex", "KeyConditionExpression": "GameTitle = :v_title", "ExpressionAttributeValues": { ":v_title": {"S": "Meteor Blasters"} }, "ProjectionExpression": "UserId, TopScore", "ScanIndexForward": false }
Dalam kueri ini:
-
DynamoDB GameTitleIndexmengakses, menggunakan kunci partisi untuk menemukan GameTitleitem indeks untuk Meteor Blasters. Semua item indeks dengan kunci ini disimpan berdekatan satu sama lain untuk pengambilan cepat.
-
Dalam game ini, DynamoDB menggunakan indeks tersebut untuk mengakses semua ID pengguna dan skor tertinggi untuk game ini.
-
Hasilnya ditampilkan dalam urutan menurun karena parameter
ScanIndexForwarddiatur ke false.
Memindai Indeks Sekunder Global
Anda dapat menggunakan operasi Scan untuk mengambil semua data dari indeks sekunder global. Anda harus memberikan nama tabel dasar dan nama indeks dalam permintaan. Dengan Scan, DynamoDB membaca semua data dalam indeks dan mengembalikannya ke aplikasi. Anda juga dapat meminta agar hanya sebagian data yang dikembalikan, dan data yang tersisa harus dibuang. Untuk melakukannya, gunakan parameter FilterExpression dari operasi Scan. Untuk informasi selengkapnya, lihat Ekspresi filter untuk pemindaian.
Sinkronisasi data antara tabel dan Indeks Sekunder Global
DynamoDB otomatis menyinkronkan setiap indeks sekunder global dengan tabel dasarnya. Saat aplikasi menulis atau menghapus item dalam tabel, indeks sekunder global apa pun di tabel tersebut diperbarui secara asinkron, menggunakan model yang akhirnya konsisten. Aplikasi tidak pernah menulis langsung ke indeks. Namun, Anda harus memahami implikasi dari cara DynamoDB mempertahankan indeks ini.
Indeks sekunder global mewarisi mode read/write kapasitas dari tabel dasar. Untuk informasi selengkapnya, lihat Pertimbangan saat mengganti mode kapasitas di DynamoDB.
Saat membuat indeks sekunder global, Anda menentukan satu atau beberapa atribut kunci indeks dan jenis datanya. Ini berarti bahwa setiap kali Anda menulis item ke tabel dasar, jenis data untuk atribut tersebut harus cocok dengan jenis data skema kunci indeks. Dalam kasus GameTitleIndex, kunci partisi GameTitle dalam indeks didefinisikan sebagai jenis data String. Kunci urutan TopScore dalam indeks adalah jenis Number. Jika Anda mencoba menambahkan item ke tabel GameScores dan menentukan jenis data yang berbeda untuk GameTitle atau TopScore, DynamoDB mengembalikan ValidationException karena jenis data tidak cocok.
Saat Anda memasukkan atau menghapus item dalam tabel, indeks sekunder global pada tabel tersebut diperbarui secara konsisten. Perubahan pada data tabel disebarkan ke indeks sekunder global dalam sepersekian detik, dalam kondisi normal. Namun, dalam beberapa skenario kegagalan yang tidak terduga, penundaan penyebaran yang lebih lama mungkin terjadi. Oleh karena itu, aplikasi Anda perlu mengantisipasi dan menangani situasi ketika kueri pada indeks sekunder global mengembalikan hasil yang tidak mutakhir.
Jika menulis item ke tabel, Anda tidak perlu menentukan atribut untuk kunci urutan indeks sekunder global. Menggunakan GameTitleIndex, misalnya, Anda tidak perlu menentukan nilai atribut TopScore untuk menulis item baru ke tabel GameScores. Dalam hal ini, DynamoDB tidak menulis data apa pun ke indeks untuk item khusus ini.
Tabel dengan banyak indeks sekunder global menimbulkan biaya lebih tinggi untuk aktivitas tulis dibandingkan tabel dengan lebih sedikit indeks. Untuk informasi selengkapnya, lihat Pertimbangan Throughput yang disediakan untuk Indeks Sekunder Global.
Kelas tabel dengan Indeks Sekunder Global
Indeks sekunder global akan selalu menggunakan kelas tabel yang sama dengan tabel dasarnya. Setiap kali indeks sekunder global baru ditambahkan untuk tabel, indeks baru akan menggunakan kelas tabel yang sama dengan tabel dasarnya. Ketika kelas tabel diperbarui, semua indeks sekunder global terkait juga diperbarui.
Pertimbangan Throughput yang disediakan untuk Indeks Sekunder Global
Saat membuat indeks sekunder global pada tabel mode yang disediakan, Anda harus menentukan unit kapasitas baca dan tulis untuk beban kerja yang diharapkan pada indeks tersebut. Pengaturan throughput yang disediakan pada indeks sekunder global terpisah dari pengaturan tabel dasarnya. Operasi Query pada indeks sekunder global menggunakan unit kapasitas baca dari indeks, bukan tabel dasar. Saat Anda memasukkan, memperbarui, atau menghapus item dalam tabel, indeks sekunder global pada tabel tersebut juga diperbarui. Pembaruan indeks ini menggunakan unit kapasitas tulis dari indeks, bukan dari tabel dasar.
Misalnya, jika Anda Query indeks sekunder global dan melebihi kapasitas baca yang disediakan, permintaan Anda akan mengalami throttling. Jika Anda melakukan aktivitas tulis berat pada tabel, tetapi indeks sekunder global pada tabel tersebut memiliki kapasitas tulis yang tidak memadai, aktivitas tulis pada tabel akan mengalami throttling.
penting
Untuk menghindari potensi throttling, kapasitas tulis yang disediakan untuk indeks sekunder global harus sama atau lebih besar dari kapasitas tulis tabel dasar karena pembaruan baru menulis ke tabel dasar dan indeks sekunder global.
Untuk melihat pengaturan throughput yang disediakan untuk indeks sekunder global, gunakan operasi DescribeTable. Informasi mendetail tentang semua indeks sekunder global tabel ditampilkan.
Unit kapasitas baca
Indeks sekunder global mendukung bacaan akhir konsisten, yang masing-masing menggunakan setengah dari unit kapasitas baca. Artinya, satu kueri indeks sekunder global dapat mengambil hingga 2 × 4 KB = 8 KB per unit kapasitas baca.
Untuk kueri indeks sekunder global, DynamoDB menghitung aktivitas baca yang disediakan dengan cara yang sama seperti kueri terhadap tabel. Satu-satunya hal yang membedakan adalah penghitungan didasarkan pada ukuran entri indeks, bukan ukuran item dalam tabel dasar. Jumlah unit kapasitas baca adalah jumlah dari semua ukuran atribut yang diproyeksikan di semua item yang dikembalikan. Hasilnya kemudian dibulatkan ke batas 4 KB berikutnya. Untuk informasi selengkapnya tentang cara DynamoDB menghitung penggunaan throughput yang disediakan, lihat Mode kapasitas yang disediakan DynamoDB.
Ukuran maksimum hasil yang dikembalikan oleh operasi Query adalah 1 MB. Ini termasuk ukuran semua nama dan nilai atribut di semua item yang dikembalikan.
Misalnya, pertimbangkan indeks sekunder global yang setiap itemnya berisi 2.000 byte data. Sekarang, anggaplah Anda Query indeks ini dan KeyConditionExpression kueri cocok dengan delapan item. Ukuran total item yang cocok adalah 2.000 byte × 8 item = 16.000 byte. Hasil ini kemudian dibulatkan ke batas 4 KB terdekat. Karena kueri indeks sekunder global pada akhirnya konsisten, biaya totalnya adalah 0,5 × (16 KB / 4 KB), atau 2 unit kapasitas baca.
Unit kapasitas tulis
Ketika item dalam tabel ditambahkan, diperbarui, atau dihapus, dan indeks sekunder global terpengaruh oleh ini, indeks sekunder global menggunakan unit kapasitas tulis yang disediakan untuk operasi. Total biaya throughput yang disediakan untuk penulisan terdiri dari jumlah unit kapasitas tulis yang digunakan dengan menulis ke tabel dasar dan yang digunakan dengan memperbarui indeks sekunder global. Jika penulisan ke tabel tidak memerlukan pembaruan indeks sekunder global, tidak ada kapasitas tulis yang digunakan dari indeks.
Agar penulisan tabel berhasil, pengaturan throughput yang disediakan untuk tabel dan semua indeks sekunder globalnya harus memiliki kapasitas tulis yang memadai untuk mengakomodasi penulisan. Jika tidak, penulisan ke tabel akan mengalami throttling.
penting
Saat membuat Indeks Sekunder Global (GSI), operasi tulis ke tabel dasar dapat dibatasi jika aktivitas GSI yang dihasilkan dari penulisan ke tabel dasar melebihi kapasitas tulis yang disediakan GSI. Pelambatan ini memengaruhi semua operasi penulisan, mulai dari proses pengindeksan hingga berpotensi mengganggu beban kerja produksi Anda. Untuk informasi selengkapnya, lihat Pemecahan masalah pembatasan di Amazon DynamoDB.
Biaya tulis item ke indeks sekunder global tergantung pada beberapa faktor:
-
Jika Anda menulis item baru ke tabel yang menentukan atribut yang diindeks, atau Anda memperbarui item yang ada untuk menentukan atribut terindeks yang sebelumnya tidak ditentukan, satu operasi tulis diperlukan untuk memasukkan item ke dalam indeks.
-
Jika pembaruan pada tabel mengubah nilai atribut kunci yang diindeks (dari A menjadi B), diperlukan dua penulisan, satu untuk menghapus item sebelumnya dari indeks dan satu lagi untuk memasukkan item baru ke dalam indeks.
-
Jika suatu item ada dalam indeks, tetapi penulisan ke tabel menyebabkan atribut yang diindeks terhapus, satu penulisan diperlukan untuk menghapus proyeksi item lama dari indeks.
-
Jika item tidak ada dalam indeks sebelum atau setelah item diperbarui, tidak ada biaya penulisan tambahan untuk indeks tersebut.
-
Jika pembaruan pada tabel hanya mengubah nilai atribut yang diproyeksikan dalam skema kunci indeks, tetapi tidak mengubah nilai atribut kunci yang diindeks, satu penulisan diperlukan untuk memperbarui nilai atribut yang diproyeksikan ke dalam indeks.
-
Jika pembaruan pada tabel hanya mengubah atribut yang bukan merupakan atribut kunci indeks atau diproyeksikan ke dalam indeks, entri indeks tidak berubah, jadi tidak ada kapasitas tulis yang dikonsumsi untuk indeks tersebut. Tabel dasar masih dikenakan biaya untuk penulisan.
Semua faktor ini mengasumsikan bahwa ukuran setiap item dalam indeks kurang dari atau sama dengan ukuran item 1 KB untuk menghitung unit kapasitas tulis. Entri indeks yang lebih besar memerlukan unit kapasitas tulis tambahan. Anda dapat meminimalkan biaya penulisan dengan mempertimbangkan atribut yang perlu dikembalikan oleh kueri dan hanya memproyeksikan atribut tersebut ke dalam indeks.
Pertimbangan penyimpanan untuk Indeks Sekunder Global
Saat aplikasi menulis item ke tabel, DynamoDB otomatis menyalin subset atribut yang benar ke indeks sekunder global tempat atribut tersebut akan muncul. AWS Akun Anda dikenakan biaya untuk penyimpanan item di tabel dasar dan juga untuk penyimpanan atribut dalam indeks sekunder global apa pun di tabel itu.
Jumlah ruang yang digunakan oleh item indeks adalah jumlah dari berikut ini:
-
Ukuran kunci primer tabel dasar dalam byte (kunci partisi dan kunci urutan)
-
Ukuran atribut kunci indeks dalam byte
-
Ukuran atribut yang diproyeksikan dalam byte (jika ada)
-
100 byte dari overhead per item indeks
Untuk memperkirakan kebutuhan penyimpanan indeks sekunder global, Anda dapat memperkirakan ukuran rata-rata item dalam indeks lalu mengalikannya dengan jumlah item dalam tabel dasar yang memiliki atribut kunci indeks sekunder global.
Jika tabel berisi item di mana atribut tertentu tidak didefinisikan, tetapi atribut tersebut didefinisikan sebagai kunci partisi indeks atau kunci sortir, DynamoDB tidak menulis data apa pun untuk item tersebut ke indeks.
