Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Contoh ini menjelaskan cara memodelkan data relasional di Amazon DynamoDB. Desain tabel DynamoDB sesuai dengan skema entri urutan relasional yang ditampilkan dalam Pemodelan relasional. Desain ini mengikuti Pola desain daftar kedekatan, yang merupakan cara umum untuk merepresentasikan struktur data relasional di DynamoDB.
Pola desain mengharuskan Anda untuk menentukan set jenis entitas yang biasanya berkorelasi dengan berbagai tabel dalam skema relasional. Item entitas kemudian ditambahkan ke tabel menggunakan kunci primer gabungan (partisi dan urutan). Kunci partisi pada item entitas ini adalah atribut yang mengidentifikasi item secara unik dan disebut secara umum pada semua item sebagai PK. Atribut kunci urutan berisi nilai atribut yang dapat Anda gunakan untuk indeks terbalik atau indeks sekunder global. Hal ini umumnya disebut sebagai SK.
Anda menentukan entitas berikut, yang mendukung skema entri urutan relasional.
-
HR-Employee - PK: EmployeeID, SK: Nama Karyawan
-
HR-Region - PK: RegionID, SK: Nama Wilayah
-
HR-Negara - PK: CountryId, SK: Nama Negara
-
HR-Location - PK: LocationID, SK: Nama Negara
-
HR-Job - PK: JobID, SK: Jabatan
-
Departemen SDM - PK: Departmentid, SK: DepartmentName
-
Pelanggan OE - PK: CustomerID, SK, ID AccountRep
-
OE-Order - PK OrderID, SK: CustomerID
-
OE-Product - PK: ProductID, SK: Nama Produk
-
OE-Warehouse - PK: WarehouseID, SK: Nama Wilayah
Setelah menambahkan item entitas ini ke tabel, Anda dapat menentukan hubungan di antara item entitas tersebut dengan menambahkan item edge ke partisi item entitas. Tabel berikut menunjukkan langkah ini.
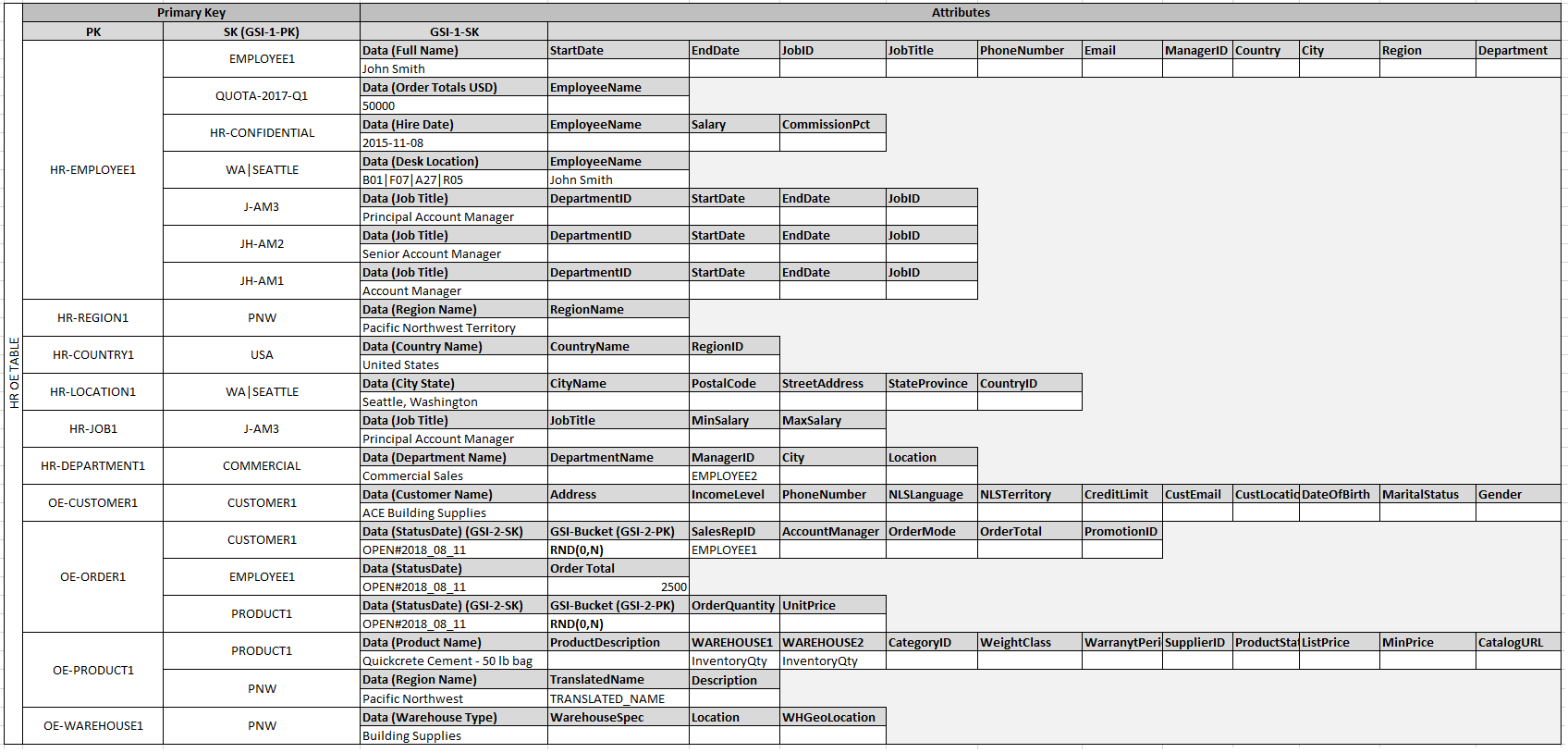
Dalam contoh ini, partisi Employee, Order, dan Product
Entity pada tabel memiliki item edge lain yang berisi penunjuk ke item entitas lain pada tabel. Selanjutnya, tentukan beberapa indeks sekunder global (GSIs) untuk mendukung semua pola akses yang ditentukan sebelumnya. Tidak semua item entitas menggunakan jenis nilai yang sama untuk atribut kunci primer atau kunci urutan. Yang diperlukan hanyalah atribut primer utama dan kunci urutan untuk dimasukkan ke dalam tabel.
Fakta bahwa beberapa entitas ini menggunakan nama yang tepat dan yang lain menggunakan entitas lain IDs sebagai nilai kunci pengurutan memungkinkan indeks sekunder global yang sama untuk mendukung beberapa jenis kueri. Teknik ini disebut GSIoverloading. Teknik ini secara efektif menghilangkan batas default 20 indeks sekunder global untuk tabel yang berisi beberapa jenis item. Ini ditunjukkan pada diagram berikut sebagai GSI1.
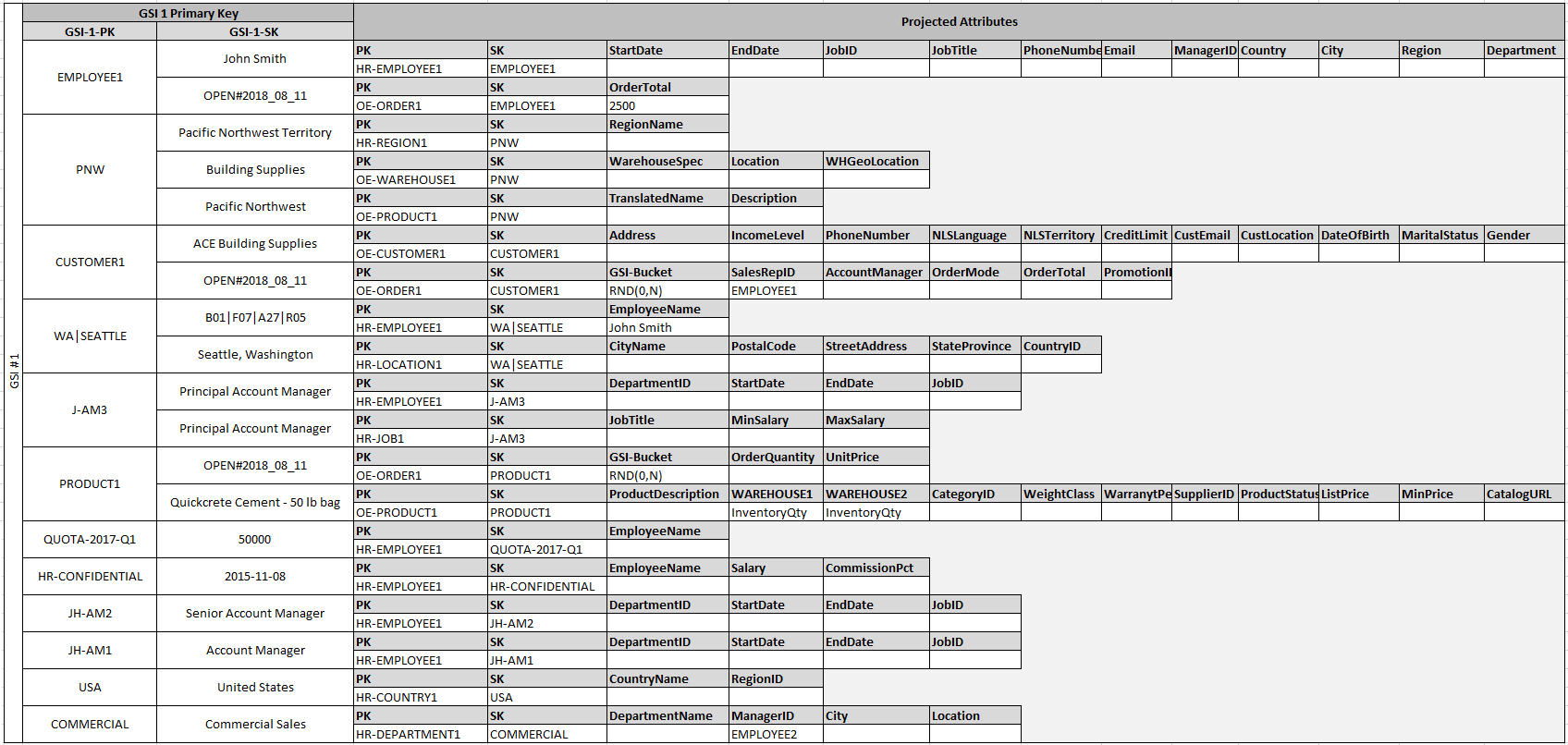
GSI2 dirancang untuk mendukung pola akses aplikasi yang cukup umum, yaitu untuk mendapatkan semua item di atas meja yang memiliki keadaan tertentu. Untuk tabel besar dengan distribusi item yang tidak merata di seluruh status yang tersedia, pola akses ini dapat menghasilkan hot key, kecuali jika item didistribusikan ke lebih dari satu partisi logis yang dapat dikueri secara paralel. Pola desain ini disebut write sharding.
Untuk mencapai ini untuk GSI 2, aplikasi menambahkan GSI 2 atribut kunci utama untuk setiap item Order. Aplikasi mengisinya dengan nomor acak dalam kisaran 0-N, dengan N secara umum dapat dihitung menggunakan rumus berikut, kecuali ada alasan khusus untuk melakukan sebaliknya.
ItemsPerRCU = 4KB / AvgItemSize PartitionMaxReadRate = 3K * ItemsPerRCU N = MaxRequiredIO / PartitionMaxReadRate
Sebagai contoh, misalkan Anda mengharapkan hal berikut:
-
Hingga 2 juta pesanan akan berada dalam sistem, yang berkembang hingga 3 juta dalam 5 tahun.
-
Hingga 20 persen dari pesanan ini akan berada dalam OPEN keadaan pada waktu tertentu.
-
Catatan pesanan rata-rata sekitar 100 byte, dengan tiga
OrderItemcatatan di partisi pesanan yang masing-masing sekitar 50 byte, memberi Anda ukuran entitas pesanan rata-rata 250 byte.
Untuk tabel tersebut, penghitungan faktor N akan seperti berikut ini.
ItemsPerRCU = 4KB / 250B = 16 PartitionMaxReadRate = 3K * 16 = 48K N = (0.2 * 3M) / 48K = 13
Dalam hal ini, Anda perlu mendistribusikan semua pesanan di setidaknya 13 partisi logis pada GSI 2 untuk memastikan bahwa pembacaan semua Order item dengan OPEN status tidak menyebabkan partisi panas pada lapisan penyimpanan fisik. Memasukkan jumlah ini untuk memungkinkan anomali dalam set data adalah praktik yang baik. Jadi, model yang menggunakan N = 15 mungkin baik-baik saja. Seperti disebutkan sebelumnya, Anda melakukan ini dengan menambahkan nilai 0-N acak ke atribut GSI 2 PK masing-masing Order dan OrderItem catatan yang dimasukkan pada tabel.
Perincian ini mengasumsikan bahwa pola akses yang memerlukan pengumpulan semua faktur OPEN relatif jarang terjadi sehingga Anda dapat menggunakan kapasitas lonjakan untuk memenuhi permintaan. Anda dapat mengkueri indeks sekunder global berikut menggunakan syarat Kunci Urutan State dan Date Range untuk menghasilkan sebagian atau semua Orders dalam status tertentu sesuai kebutuhan.

Dalam contoh ini, item didistribusikan secara acak ke 15 partisi logis. Struktur ini berfungsi karena pola akses memerlukan sejumlah besar item untuk diambil. Oleh karena itu, kecil kemungkinannya bahwa salah satu dari 15 thread akan mengembalikan set hasil kosong yang berpotensi mewakili kapasitas yang terbuang. Kueri selalu menggunakan 1 unit kapasitas baca (RCU) atau 1 unit kapasitas tulis (WCU), bahkan jika tidak ada yang dikembalikan atau tidak ada data yang ditulis.
Jika pola akses memerlukan kueri kecepatan tinggi pada indeks sekunder global ini yang mengembalikan set hasil yang jarang, sebaiknya gunakan algoritma hash untuk mendistribusikan item daripada pola acak. Dalam hal ini, Anda dapat memilih atribut yang diketahui ketika kueri dijalankan pada saat runtime dan meng-hash atribut tersebut ke dalam ruang kunci 0–14 saat item dimasukkan. Kemudian, item tersebut dapat dibaca secara efisien dari indeks sekunder global.
Terakhir, Anda dapat meninjau kembali pola akses yang ditetapkan sebelumnya. Berikut ini adalah daftar pola akses dan ketentuan kueri yang akan Anda gunakan dengan versi DynamoDB baru pada aplikasi untuk mengakomodasinya.
| S. Tidak. | Pola akses | Ketentuan kueri |
|---|---|---|
|
1 |
Cari Detail Karyawan berdasarkan ID Karyawan |
Kunci Utama di atas meja, ID = “HR-” EMPLOYEE |
|
2 |
Kueri Detail Karyawan berdasarkan Nama Karyawan |
Gunakan GSI -1, PK="Nama Karyawan” |
|
3 |
Dapatkan detail pekerjaan karyawan saat ini saja |
Kunci Utama di atas meja, PK=HR- EMPLOYEE -1, SK dimulai dengan “JH” |
|
4 |
Dapatkan Pesanan pelanggan untuk rentang tanggal |
Gunakan GSI -1, PK=CUSTOMER1, SK=” STATUS - DATE “, untuk masing-masing StatusCode |
|
5 |
Tampilkan semua Pesanan dalam OPEN status untuk rentang tanggal di semua pelanggan |
Gunakan GSI -2, PK=Query secara paralel untuk rentang [0.. N], SK antara OPEN -Date1 dan -Date2 OPEN |
|
6 |
Semua Karyawan yang baru direkrut |
Gunakan GSI -1, PK="HR- CONFIDENTIAL ', SK > date1 |
|
7 |
Temukan semua Karyawan di Gudang tertentu |
Gunakan GSI -1, PK= WAREHOUSE1 |
|
8 |
Dapatkan semua Orderitems untuk suatu Produk termasuk inventaris lokasi gudang |
Gunakan GSI -1, PK= PRODUCT1 |
|
9 |
Dapatkan pelanggan dengan Perwakilan Akun |
Gunakan GSI -1, PK= ACCOUNT - REP |
|
10 |
Dapatkan pesanan berdasarkan Perwakilan Akun dan tanggal |
Gunakan GSI -1, PK= ACCOUNT -REP, SK=” STATUS - DATE “, untuk masing-masing StatusCode |
|
11 |
Dapatkan semua karyawan dengan Jabatan tertentu |
Gunakan GSI -1, PK= JOBTITLE |
|
12 |
Dapatkan inventaris berdasarkan Produk dan Gudang |
Kunci Utama di atas meja, PK=OE-, SK= PRODUCT1 PRODUCT1 |
|
13 |
Dapatkan total inventaris produk |
Kunci Utama di atas meja, PK=OE-, SK= PRODUCT1 PRODUCT1 |
|
14 |
Dapatkan Perwakilan Akun diberi peringkat berdasarkan Total Pesanan dan Periode Penjualan |
Gunakan GSI -1, PK= YYYY -Q1, = Salah scanIndexForward |
