Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Desain skema jejaring sosial di DynamoDB
Kasus penggunaan bisnis jejaring sosial
Kasus penggunaan ini membahas penggunaan DynamoDB sebagai jejaring sosial. Jejaring sosial adalah layanan online yang memungkinkan berbagai pengguna berinteraksi satu sama lain. Jejaring sosial yang akan kita desain akan memungkinkan pengguna melihat garis waktu yang terdiri dari postingan mereka, pengikut mereka, orang yang mereka ikuti, dan postingan yang ditulis oleh orang yang mereka ikuti. Pola akses untuk desain skema ini adalah:
-
Mendapatkan informasi pengguna untuk userID tertentu
-
Mendapatkan daftar pengikut untuk userID tertentu
-
Mendapatkan daftar orang yang diikuti untuk userID tertentu
-
Mendapatkan daftar postingan untuk userID tertentu
-
Mendapatkan daftar pengguna yang menyukai postingan untuk postID tertentu
-
Mendapatkan jumlah suka untuk postID tertentu
-
Mendapatkan lini masa untuk userID tertentu
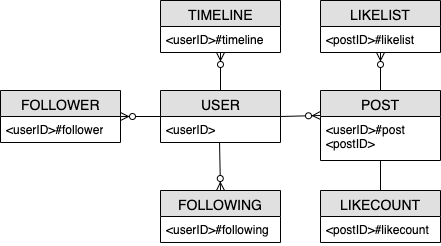
Diagram hubungan entitas jejaring sosial
Ini adalah diagram hubungan entitas (ERD) yang akan kita gunakan untuk desain skema jejaring sosial.
Pola akses jejaring sosial
Ini adalah pola akses yang akan kita pertimbangkan untuk desain skema jaringan sosial.
-
getUserInfoByUserID -
getFollowerListByUserID -
getFollowingListByUserID -
getPostListByUserID -
getUserLikesByPostID -
getLikeCountByPostID -
getTimelineByUserID
Evolusi desain skema jejaring sosial
DynamoDB adalah basis data NoSQL, sehingga Anda tidak dapat melakukan penggabungan, yaitu operasi yang menggabungkan data dari beberapa basis data. Pelanggan yang tidak terbiasa dengan DynamoDB mungkin menerapkan filosofi desain sistem manajemen basis data relasional (RDBMS) (seperti membuat tabel untuk setiap entitas) ke DynamoDB ketika mereka tidak perlu melakukannya. Tujuan desain tabel tunggal DynamoDB adalah untuk menulis data dalam bentuk pra-penggabungan sesuai pola akses aplikasi, lalu segera menggunakan data tanpa komputasi tambahan. Untuk informasi lebih lanjut, lihat Single-tablevs. desain multi-tabel di DynamoDB
Sekarang, mari melanjutkan ke cara mengembangkan desain skema untuk menangani semua pola akses.
Langkah 1: Tangani pola akses 1 (getUserInfoByUserID)
Untuk mendapatkan informasi pengguna tertentu, kita perlu Query tabel dasar dengan kondisi kunci PK=<userID>. Operasi kueri memungkinkan Anda melakukan paginasi hasil, yang berguna ketika pengguna memiliki banyak pengikut. Untuk informasi selengkapnya tentang Kueri, lihat Menanyakan tabel di DynamoDB.
Dalam contoh, kita melacak dua jenis data untuk pengguna: yaitu "count" dan "info". "Count" pengguna mencerminkan berapa banyak pengikut yang dimiliki, berapa banyak pengguna yang diikuti, dan berapa banyak postingan yang telah dibuat. "Info" pengguna mencerminkan informasi pribadi seperti nama mereka.
Kita melihat dua jenis data yang diwakili oleh dua item di bawah ini. Item dengan "count" dalam kunci urutan (SK) lebih mungkin berubah daripada item dengan "info". DynamoDB menganggap ukuran item seperti yang muncul sebelum dan setelah pembaruan dan throughput yang disediakan akan mencerminkan ukuran item yang lebih besar. Meskipun Anda hanya memperbarui subset atribut item, UpdateItem masih akan menggunakan throughput yang disediakan dalam jumlah penuh (lebih besar dari ukuran item sebelum dan sesudah). Anda bisa mendapatkan item melalui satu operasi Query dan menggunakan UpdateItem untuk menambah atau mengurangi dari atribut numerik yang ada.

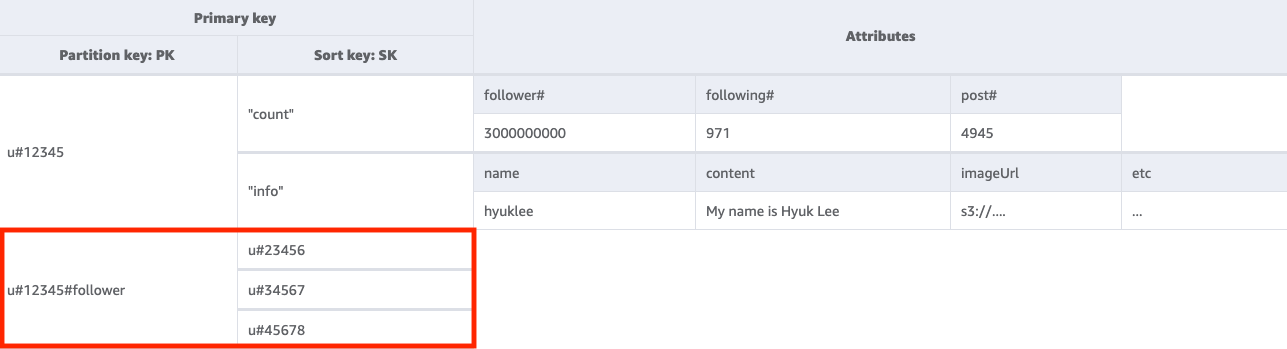
Langkah 2: Tangani pola akses 2 (getFollowerListByUserID)
Untuk mendapatkan daftar pengguna yang mengikuti pengguna tertentu, kita perlu melakukan Query tabel dasar dengan kondisi kunci PK=<userID>#follower.
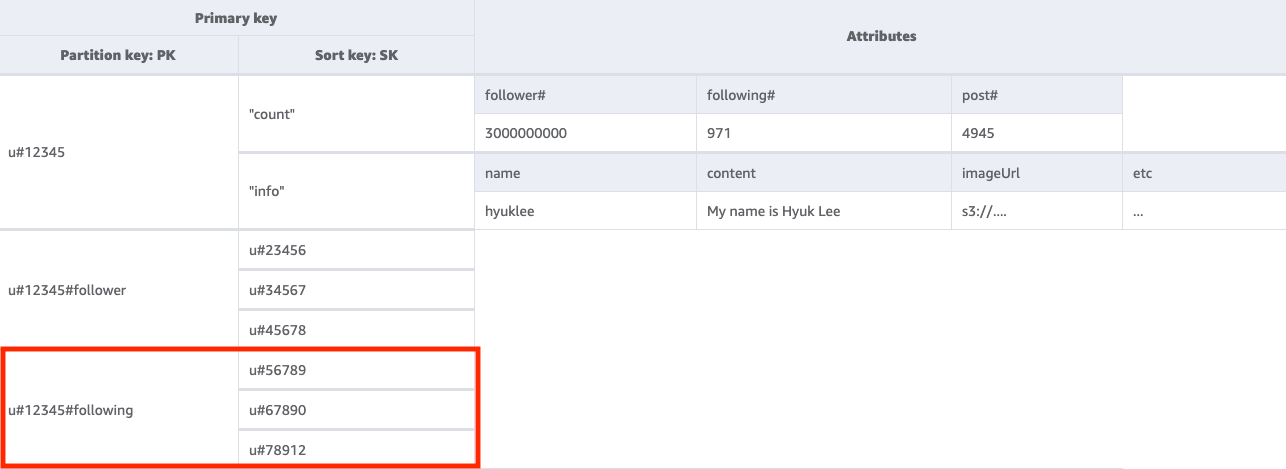
Langkah 3: Tangani pola akses 3 (getFollowingListByUserID)
Untuk mendapatkan daftar pengguna yang diikuti pengguna tertentu, kita perlu melakukan Query tabel dasar dengan kondisi kunci PK=<userID>#following. Anda kemudian dapat menggunakan TransactWriteItemsoperasi untuk mengelompokkan beberapa permintaan bersama-sama dan melakukan hal berikut:
-
Tambahkan Pengguna A ke daftar pengikut Pengguna B, lalu tambahkan jumlah pengikut Pengguna B satu per satu.
-
Tambahkan Pengguna B ke daftar pengikut Pengguna A, lalu tambahkan jumlah pengikut Pengguna A satu per satu.
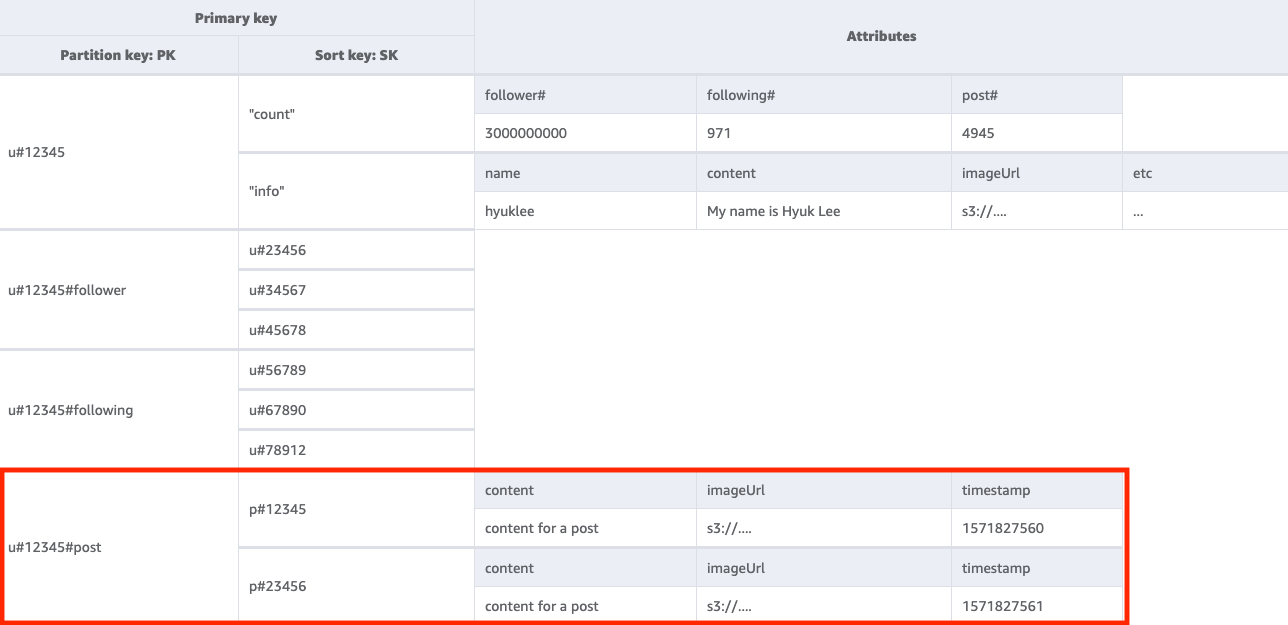
Langkah 4: Tangani pola akses 4 (getPostListByUserID)
Untuk mendapatkan daftar postingan yang dibuat pengguna tertentu, kita perlu melakukan Query tabel dasar dengan kondisi kunci PK=<userID>#post. Satu hal penting yang perlu diperhatikan di sini adalah postID pengguna harus bersifat inkremental: nilai postID kedua harus lebih besar dari nilai postID pertama (karena pengguna ingin melihat postingan mereka secara berurutan). Anda dapat melakukan ini dengan membuat postID berdasarkan nilai waktu seperti Universally Unique Lexicographically Sortable Identifier (ULID).
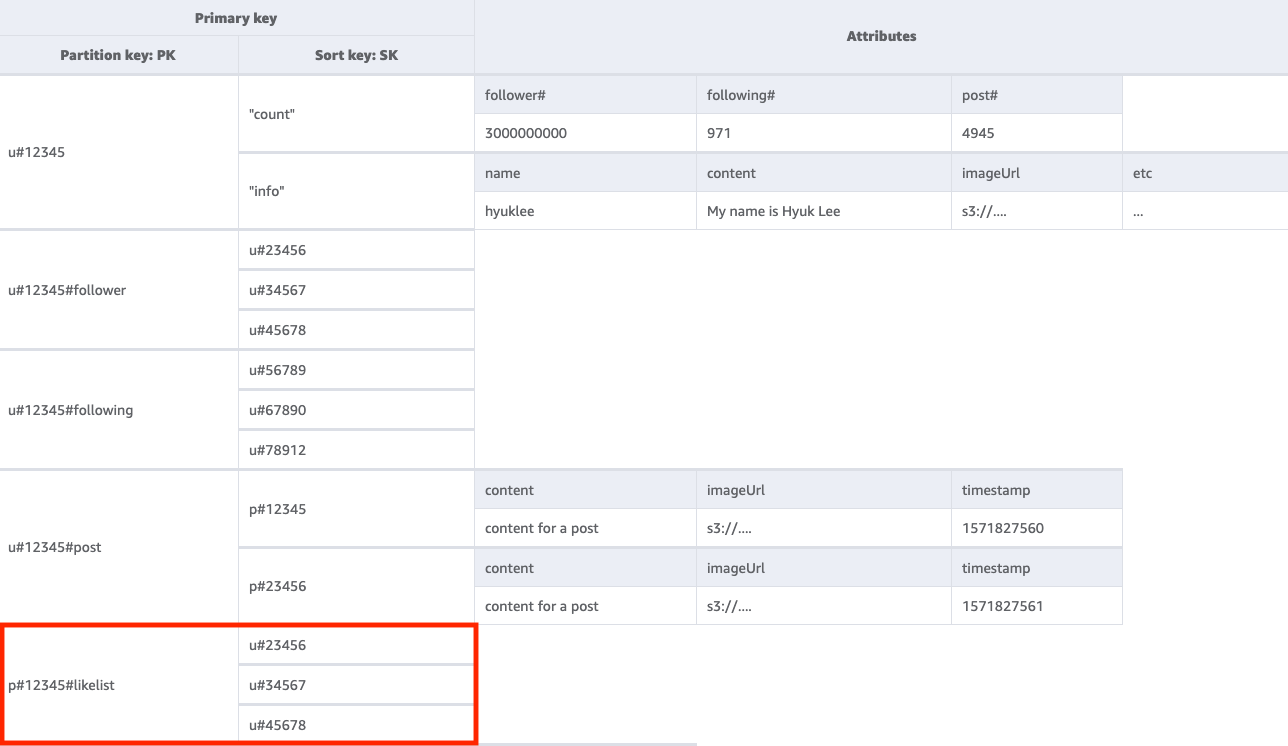
Langkah 5: Tangani pola akses 5 (getUserLikesByPostID)
Untuk mendapatkan daftar pengguna yang menyukai postingan pengguna tertentu, kita perlu melakukan Query tabel dasar dengan kondisi kunci PK=<postID>#likelist. Pendekatan ini sama dengan pola yang kita gunakan untuk mengambil daftar pengikut dan pengguna yang diikuti dalam pola akses 2 (getFollowerListByUserID) dan pola akses 3 (getFollowingListByUserID).
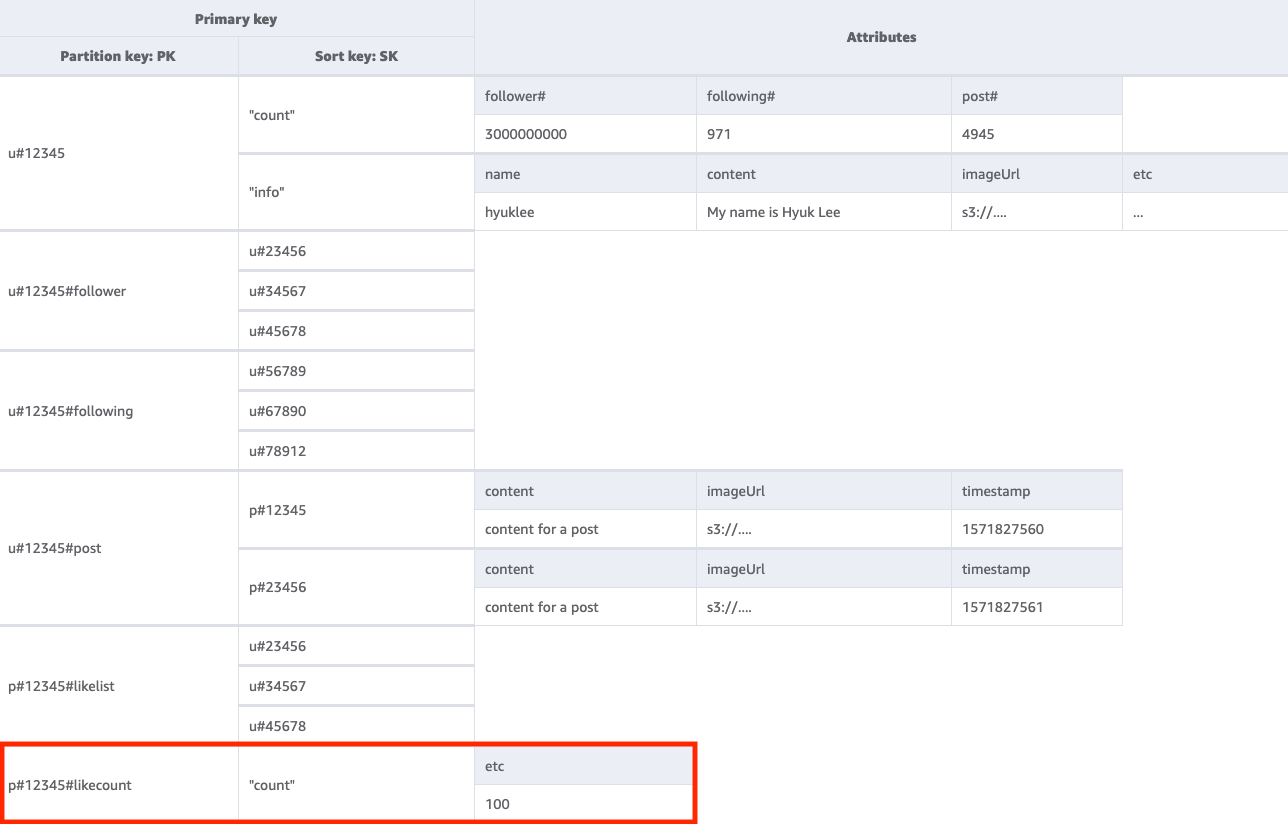
Langkah 6: Tangani pola akses 6 (getLikeCountByPostID)
Untuk mendapatkan jumlah suka dalam posting tertentu, kita harus melakukan GetItem operasi pada tabel dasar dengan kondisi kunci PK=<postID>#likecount. Pola akses ini dapat menyebabkan masalah throttling setiap kali pengguna dengan banyak pengikut (seperti selebritas) membuat postingan karena throttling terjadi ketika throughput partisi melebihi 1000 WCU per detik. Masalah ini tidak dihasilkan oleh DynamoDB, tetapi hanya muncul di DynamoDB karena berada di akhir tumpukan perangkat lunak.
Anda harus mengevaluasi apakah penting bahwa semua pengguna melihat jumlah suka secara bersamaan atau hal tersebut dapat dilakukan secara bertahap dari waktu ke waktu. Secara umum, jumlah suka postingan tidak harus langsung 100% akurat. Anda dapat menerapkan strategi ini dengan menempatkan antrean antara aplikasi Anda dan DynamoDB agar pembaruan terjadi secara berkala.
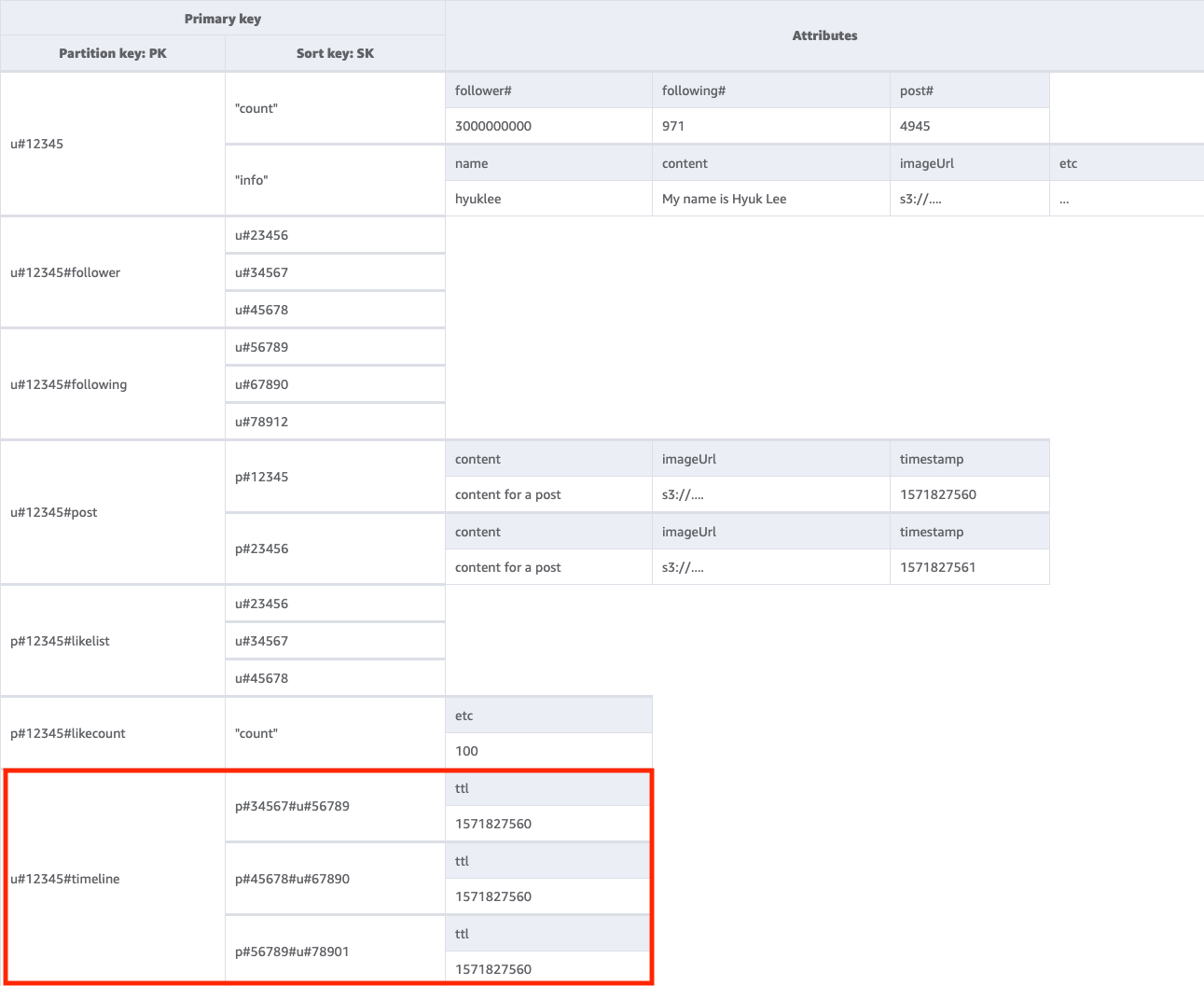
Langkah 7: Tangani pola akses 7 (getTimelineByUserID)
Untuk mendapatkan lini masa pengguna tertentu, kita harus melakukan Query operasi pada tabel dasar dengan kondisi kunci PK=<userID>#timeline. Mari pertimbangkan skenario ketika pengikut pengguna perlu melihat postingan secara sinkron. Setiap kali pengguna menulis postingan, daftar pengikut mereka dibaca dan userID serta postID mereka perlahan dimasukkan ke dalam kunci lini masa semua pengikutnya. Kemudian, ketika aplikasi Anda dimulai, Anda dapat membaca kunci lini masa dengan operasi Query dan mengisi layar lini masa dengan kombinasi userID dan postID menggunakan operasi BatchGetItem untuk semua item baru. Anda tidak dapat membaca lini masa dengan panggilan API, tetapi ini adalah solusi yang lebih hemat biaya jika postingan sering diedit.
Lini masa adalah tempat yang menampilkan postingan terbaru, jadi kita perlu cara untuk membersihkan yang lama. Dibandingkan menggunakan WCU untuk menghapusnya, Anda dapat menggunakan fitur TTL DynamoDB untuk melakukannya secara gratis.
Semua pola akses dan bagaimana desain skema mengatasinya dirangkum dalam tabel di bawah ini:
| Pola akses | table/GSIDasar/LSI | Operasi | Nilai kunci partisi | Nilai kunci urutan | Lainnya conditions/filters |
|---|---|---|---|---|---|
| mendapatkan UserInfoByUserID | Tabel dasar | Kueri | PK=<userID> | ||
| mendapatkan FollowerListByUserID | Tabel dasar | Kueri | PK=<userID>#follower | ||
| mendapatkan FollowingListByUserID | Tabel dasar | Kueri | PK=<userID>#following | ||
| mendapatkan PostListByUserID | Tabel dasar | Kueri | PK=<userID>#post | ||
| mendapatkan UserLikesByPostID | Tabel dasar | Kueri | PK=<postID>#likelist | ||
| mendapatkan LikeCountByPostID | Tabel dasar | GetItem | PK=<postID>#likecount | ||
| mendapatkan TimelineByUserID | Tabel dasar | Kueri | PK=<userID>#timeline |
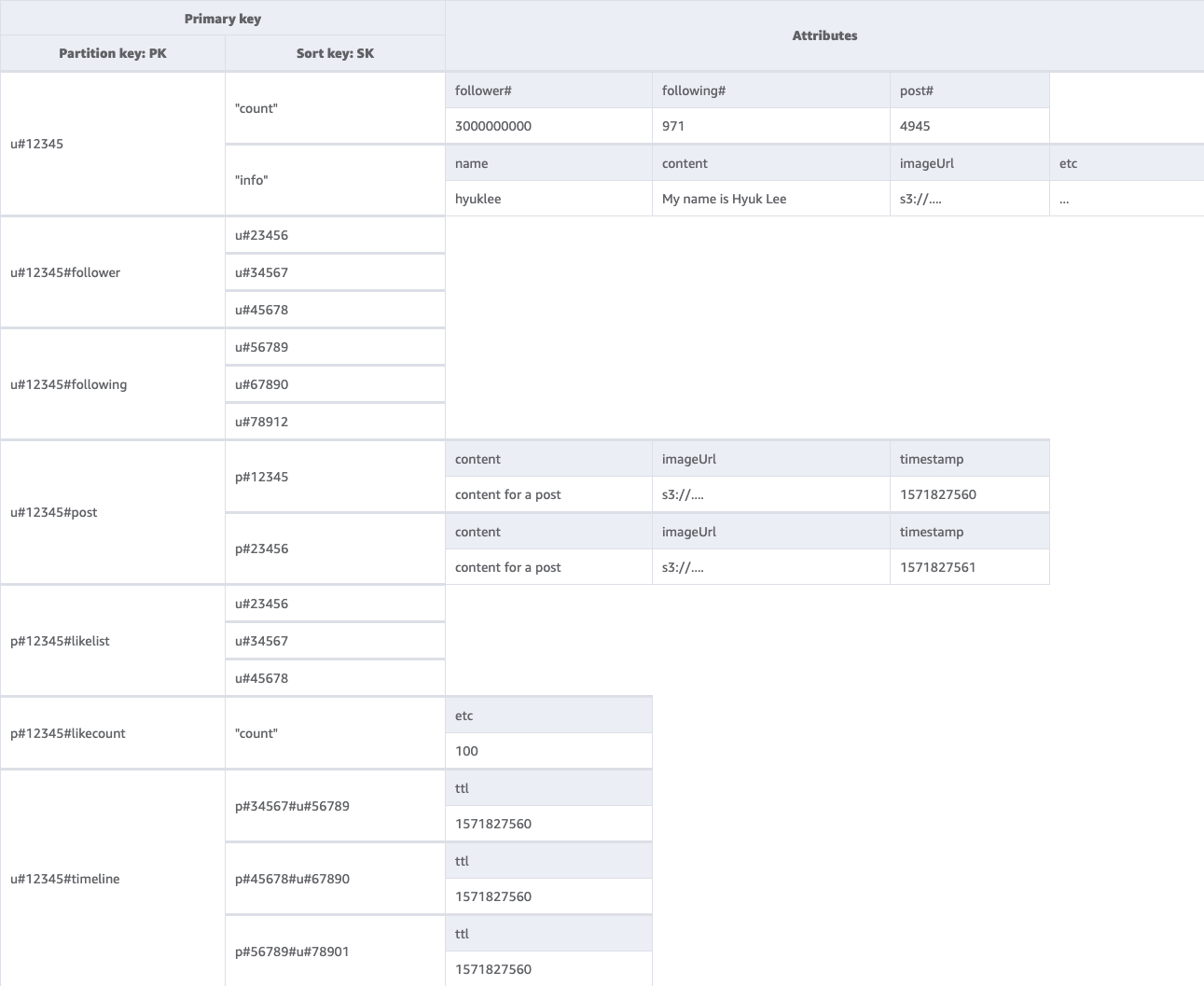
Skema akhir jejaring sosial
Berikut adalah desain skema akhir. Untuk mengunduh desain skema ini sebagai file JSON, lihat Contoh DynamoDB di.
Tabel dasar:
Menggunakan NoSQL Workbench dengan desain skema ini
Anda dapat mengimpor skema akhir ini ke NoSQL Workbench, sebuah alat visual yang menyediakan fitur pemodelan data, visualisasi data, dan pengembangan kueri untuk DynamoDB, guna mengeksplorasi dan mengedit proyek baru Anda lebih lanjut. Ikuti langkah-langkah berikut untuk memulai:
-
Unduh NoSQL Workbench. Untuk informasi selengkapnya, lihat Unduh NoSQL Workbench untuk DynamoDB.
-
Unduh file skema JSON yang tercantum di atas, yang sudah dalam format model NoSQL Workbench.
-
Impor file skema JSON ke NoSQL Workbench. Untuk informasi selengkapnya, lihat Mengimpor model data yang ada.
-
Setelah mengimpor model data ke NoSQL Workbench, Anda dapat mengeditnya. Lihat informasi yang lebih lengkap di Mengedit model data yang ada.
