Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Praktik terbaik untuk mengelola hubungan banyak-ke-banyak di tabel DynamoDB
Daftar kedekatan adalah pola desain yang berguna untuk pemodelan hubungan banyak-ke-banyak di Amazon DynamoDB. Secara lebih umum, daftar ini menyediakan cara untuk merepresentasikan data grafik (simpul dan edge) di DynamoDB.
Pola desain daftar kedekatan
Ketika entitas yang berbeda dari suatu aplikasi memiliki hubungan banyak-ke-banyak di antara entitas tersebut, hubungan ini dapat dimodelkan sebagai daftar kedekatan. Dalam pola ini, semua entitas tingkat atas (sama dengan simpul dalam model grafik) direpresentasikan menggunakan kunci partisi. Hubungan apa pun dengan entitas lain (edge dalam grafik) direpresentasikan sebagai item dalam partisi dengan mengatur nilai kunci urutan ke ID entitas target (simpul target).
Keunggulan pola ini antara lain duplikasi data yang minimal dan pola kueri yang disederhanakan untuk menemukan semua entitas (simpul) yang terkait dengan entitas target (memiliki edge terhadap simpul target).
Contoh aktual kegunaan pola ini adalah sistem faktur dengan faktur yang berisi beberapa tagihan. Satu tagihan bisa masuk ke beberapa faktur. Kunci partisi dalam contoh ini adalah InvoiceID atau BillID. Partisi BillID memiliki semua atribut yang khusus untuk tagihan. Partisi InvoiceID memiliki item yang menyimpan atribut khusus faktur, dan item untuk masing-masing BillID yang dimasukkan ke faktur.
Skemanya akan seperti berikut.
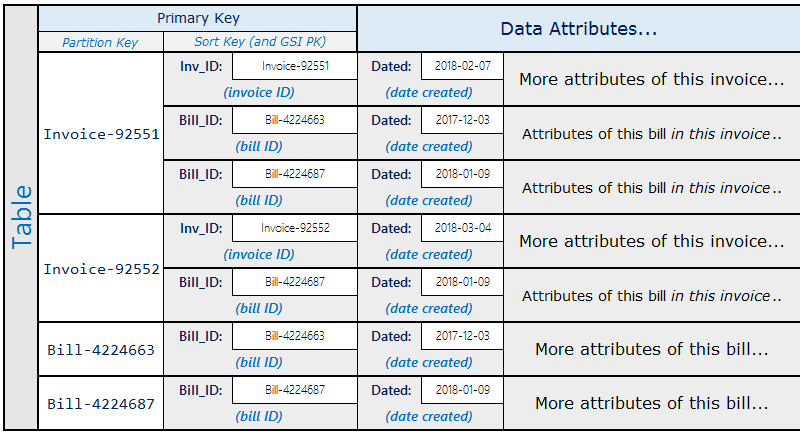
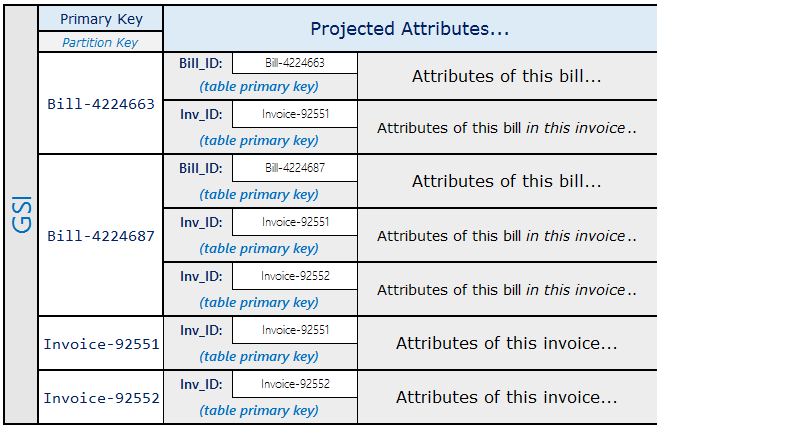
Menggunakan skema sebelumnya, Anda dapat melihat bahwa semua tagihan dalam faktur dapat dikueri menggunakan kunci primer pada tabel. Untuk mencari semua faktur yang memuat bagian dari tagihan, buat indeks sekunder global pada kunci urutan tabel.
Proyeksi untuk indeks sekunder global akan seperti berikut.
Pola grafik terwujud
Banyak aplikasi dibangun berdasarkan pemahaman peringkat di antara sesama aplikasi, hubungan umum di antara entitas, status entitas tetangga, dan jenis alur kerja gaya grafik lainnya. Untuk jenis aplikasi ini, pertimbangkan pola desain skema berikut.
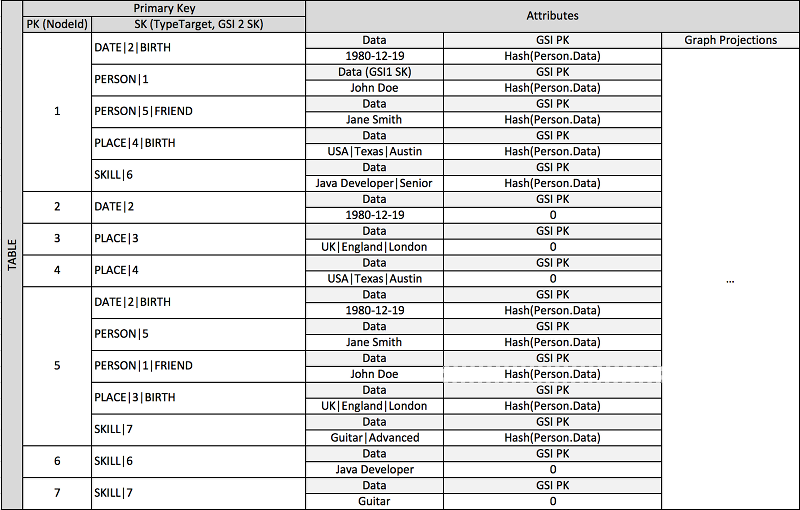
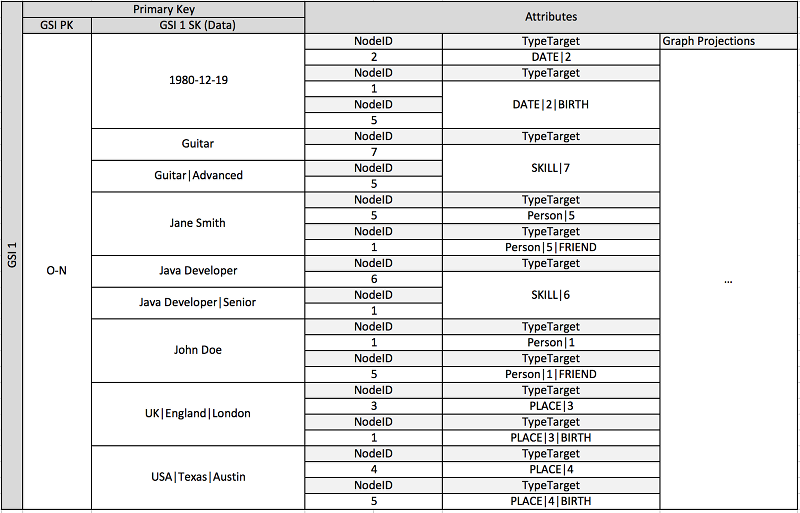
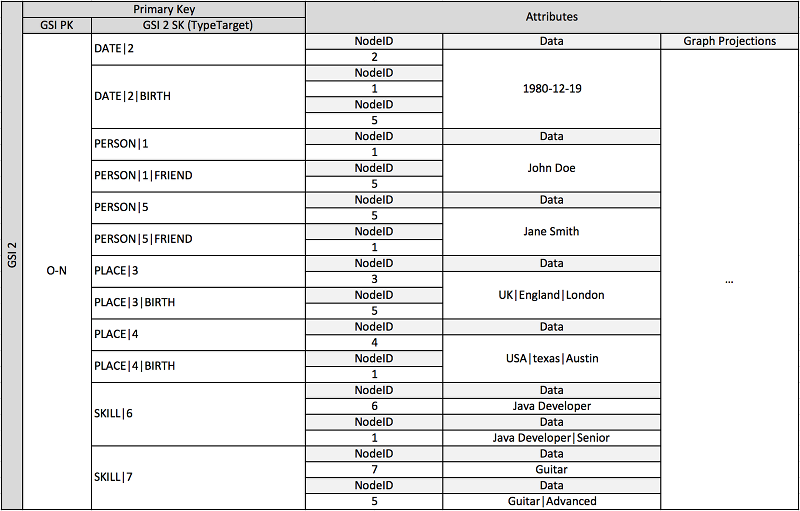
Skema sebelumnya menunjukkan struktur data grafik yang didefinisikan oleh satu set partisi data yang berisi item yang menentukan edge dan simpul grafik. Item edge berisi atribut Target dan Type. Atribut ini digunakan sebagai bagian dari nama kunci komposit TypeTarget "" untuk mengidentifikasi item dalam partisi di tabel primer atau dalam indeks sekunder global kedua.
Indeks sekunder global pertama dibangun di atas atribut Data. Atribut ini menggunakan muatan berlebih indeks sekunder global seperti yang dijelaskan sebelumnya untuk mengindeks beberapa jenis atribut, yaitu Dates, Names, Places, dan Skills. Di sini, satu indeks sekunder global mengindeks empat atribut yang berbeda secara efektif.
Saat Anda memasukkan item ke dalam tabel, Anda dapat menggunakan strategi sharding cerdas untuk mendistribusikan set item dengan agregasi besar (tanggal lahir, keterampilan) di sebanyak mungkin partisi logis pada indeks sekunder global yang diperlukan untuk menghindari masalah panas. read/write
Hasil dari kombinasi pola desain ini adalah penyimpanan data yang solid untuk alur kerja grafik waktu nyata yang sangat efisien. Alur kerja ini dapat memberikan status entitas tetangga performa tinggi dan kueri agregasi edge untuk mesin rekomendasi, aplikasi jejaring sosial, peringkat simpul, agregasi subtree, dan kasus penggunaan grafik umum lainnya.
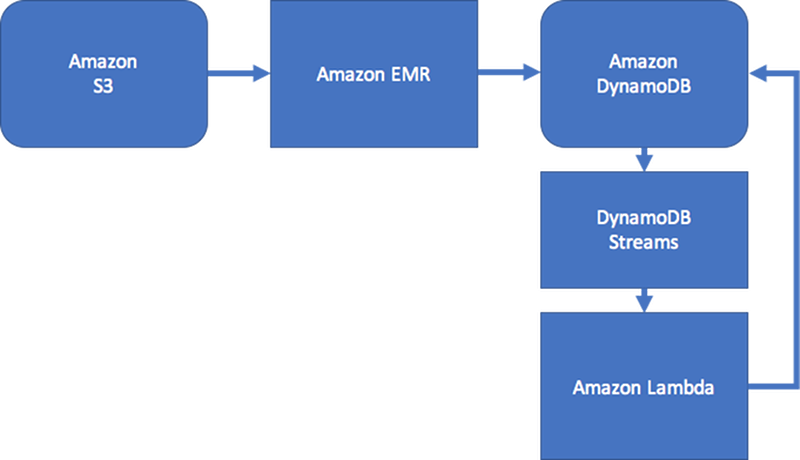
Jika kasus penggunaan Anda tidak sensitif terhadap konsistensi data waktu nyata, Anda dapat menggunakan proses Amazon EMR terjadwal untuk mengisi edge dengan agregasi ringkasan grafik yang relevan untuk alur kerja Anda. Anda dapat menggunakan proses terjadwal untuk menggabungkan hasil jika aplikasi Anda tidak perlu segera mengetahui kapan edge ditambahkan ke grafik.
Untuk mempertahankan beberapa tingkat konsistensi, desain dapat menyertakan Amazon DynamoDB Streams dan AWS Lambda untuk memproses pembaruan edge. Desain ini juga bisa menggunakan tugas Amazon EMR untuk memvalidasi hasil secara berkala. Pendekatan ini diilustrasikan dengan diagram berikut. Ini biasanya digunakan dalam aplikasi jejaring sosial, jika biaya kueri waktu nyata tinggi dan kebutuhan untuk mengetahui pembaruan pengguna individu rendah.
Manajemen layanan TI (IT service-management/ITSM) dan aplikasi keamanan umumnya perlu merespons secara waktu nyata terhadap perubahan status entitas yang terdiri dari agregasi edge yang kompleks. Aplikasi semacam itu membutuhkan sistem yang dapat mendukung agregasi beberapa simpul waktu nyata dari hubungan tingkat kedua dan ketiga, atau traversal edge yang kompleks. Jika kasus penggunaan Anda memerlukan jenis alur kerja kueri grafik waktu nyata ini, sebaiknya pertimbangkan menggunakan Amazon Neptune untuk mengelola alur kerja ini.
catatan
Jika Anda perlu mengkueri set data yang sangat terhubung atau mengeksekusi kueri yang perlu melintasi beberapa simpul (juga dikenal sebagai kueri multi-hop) dengan latensi milidetik, sebaiknya gunakan Amazon Neptune. Amazon Neptune adalah mesin basis data grafik berperforma tinggi yang dibuat khusus dan dioptimalkan untuk menyimpan miliaran hubungan dan mengkueri grafik dengan latensi milidetik.
