Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Praktik terbaik untuk memodelkan data relasional di DynamoDB
Bagian ini menyediakan praktik terbaik untuk memodelkan data relasional di Amazon DynamoDB. Pertama, kami memperkenalkan konsep pemodelan data tradisional. Kemudian, kami menjelaskan keuntungan menggunakan DynamoDB dibandingkan sistem manajemen basis data relasional tradisional—bagaimana DynamoDB menghilangkan kebutuhan untuk operasi JOIN dan mengurangi overhead.
Kami kemudian menjelaskan cara menyusun tabel DynamoDB yang menskalakan secara efisien. Terakhir, kami memberikan contoh cara memodelkan data relasional di DynamoDB.
Topik
Model basis data relasional traditional
Sistem manajemen basis data relasional tradisional (RDBMS) menyimpan data dalam struktur relasional yang dinormalisasi. Tujuan dari model data relasional adalah untuk mengurangi duplikasi data (melalui normalisasi) untuk mendukung integritas referensial dan mengurangi anomali data.
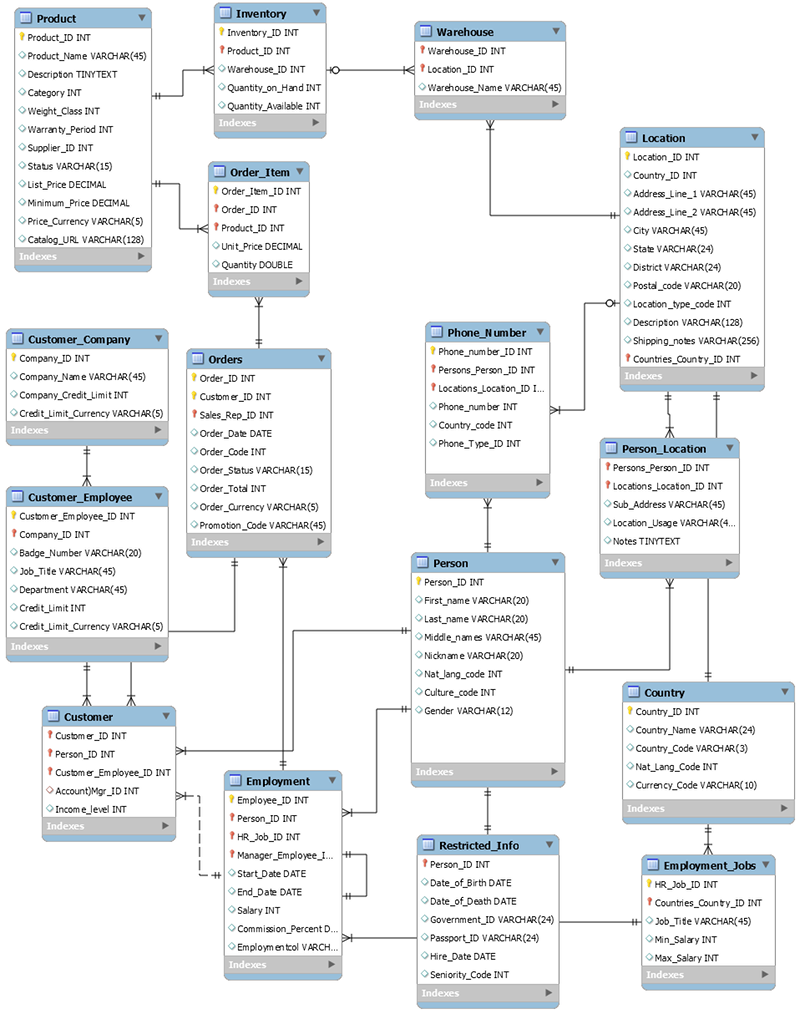
Skema berikut adalah contoh dari model data relasional untuk penerapan urutan-entri generik. Penerapan ini mendukung skema sumber daya manusia yang mendukung sistem pendukung operasional dan bisnis dari produsen teoretis.
Sebagai layanan basis data non-relasional, DynamoDB menawarkan banyak keunggulan dibandingkan sistem manajemen basis data relasional tradisional.
Cara DynamoDB menghilangkan kebutuhan akan operasi JOIN
Sebuah RDBMS menggunakan bahasa kueri terstruktur (SQL) untuk mengembalikan data ke aplikasi. Karena normalisasi model data, kueri semacam ini biasanya memerlukan penggunaan operator JOIN untuk menggabungkan data dari satu atau beberapa tabel.
Misalnya, untuk menghasilkan daftar item pesanan pembelian yang diurutkan berdasarkan jumlah stok di semua gudang yang dapat mengirimkan setiap item, Anda bisa mengeluarkan kueri SQL berikut terhadap skema sebelumnya.
SELECT * FROM Orders
INNER JOIN Order_Items ON Orders.Order_ID = Order_Items.Order_ID
INNER JOIN Products ON Products.Product_ID = Order_Items.Product_ID
INNER JOIN Inventories ON Products.Product_ID = Inventories.Product_ID
ORDER BY Quantity_on_Hand DESCKueri SQL semacam ini dapat menyediakan API fleksibel untuk mengakses data, tetapi kueri tersebut membutuhkan pemrosesan dalam jumlah besar. Setiap gabungan dalam kueri meningkatkan kompleksitas runtime kueri karena data untuk setiap tabel harus ditahapkan dan kemudian dikumpulkan untuk mengembalikan set hasil.
Faktor lain yang dapat memengaruhi durasi yang dibutuhkan untuk menjalankan kueri adalah ukuran tabel dan apakah kolom yang digabungkan memiliki indeks. Kueri sebelumnya memulai kueri kompleks di beberapa tabel, lalu mengurutkan set hasilnya.
Menghilangkan kebutuhan untuk JOINs adalah inti dari pemodelan data NoSQL. Inilah sebabnya mengapa kami membangun DynamoDB untuk Amazon.com mendukung, dan mengapa DynamoDB dapat memberikan kinerja yang konsisten pada skala apa pun. Mengingat kompleksitas runtime kueri SQL danJOINs, kinerja RDBMS tidak konstan pada skala. Hal ini menyebabkan masalah performa seiring berkembangnya aplikasi pelanggan.
Meskipun normalisasi data mengurangi jumlah data yang disimpan ke disk, sumber daya yang paling terkendala sehingga berdampak performa sering kali adalah waktu CPU dan latensi jaringan.
DynamoDB dibangun untuk meminimalkan kendala tersebut dengan menghilangkan JOINs (dan mendorong denormalisasi data) dan mengoptimalkan arsitektur basis data untuk sepenuhnya menjawab kueri aplikasi dengan satu permintaan ke item. Kualitas ini memungkinkan DynamoDB untuk menghadirkan performa milidetik satu digit di semua skala. Ini karena kompleksitas runtime untuk operasi DynamoDB konstan, terlepas dari ukuran data, untuk pola akses umum.
Bagaimana transaksi DynamoDB menghilangkan overhead ke proses tulis
Faktor lain yang dapat memperlambat RDBMS adalah penggunaan transaksi untuk menulis ke skema yang dinormalisasi. Seperti yang ditunjukkan dalam contoh, struktur data relasional yang digunakan oleh sebagian besar aplikasi pemrosesan transaksi online (OLTP) harus diuraikan dan didistribusikan ke beberapa tabel logis jika disimpan di RDBMS.
Oleh karena itu, kerangka kerja ACID-compliant transaksi diperlukan untuk menghindari kondisi balapan dan masalah integritas data yang dapat terjadi jika aplikasi mencoba membaca objek yang sedang dalam proses penulisan. Kerangka transaksi semacam itu, jika digabungkan dengan skema relasional, dapat menambah overhead yang signifikan untuk proses tulis.
Implementasi transaksi di DynamoDB dapat mencegah masalah penskalaan umum yang dialami pada RDBMS. DynamoDB melakukan ini dengan mengeluarkan transaksi sebagai panggilan API tunggal dan membatasi jumlah item yang dapat diakses dalam satu transaksi itu. Long-running Transaksi dapat menyebabkan masalah operasional dengan menahan kunci pada data baik untuk waktu yang lama, atau terus-menerus, karena transaksi tidak pernah ditutup.
Untuk mencegah masalah demikian di DynamoDB, transaksi diimplementasikan dengan dua operasi API yang berbeda: TransactWriteItems dan TransactGetItems. Operasi API ini tidak memiliki semantik awal dan akhir yang lazim di RDBMS. Selanjutnya, DynamoDB memiliki batas akses 100 item dalam transaksi untuk mencegah transaksi yang berjalan lama. Untuk mempelajari selengkapnya tentang transaksi DynamoDB, lihat Bekerja dengan transaksi.
Dengan demikian, ketika bisnis Anda memerlukan respons latensi rendah terhadap kueri dengan lalu lintas tinggi, memanfaatkan sistem NoSQL umumnya masuk akal secara teknis dan ekonomis. Amazon DynamoDB membantu memecahkan masalah yang membatasi skalabilitas sistem relasional dengan menghindari masalah tersebut.
Performa RDBMS biasanya tidak menskalakan dengan baik karena alasan berikut:
-
Penggabungan yang mahal digunakan untuk mengumpulkan kembali tampilan yang diperlukan dari hasil kueri.
-
Sistem tersebut menormalkan data dan menyimpannya di beberapa tabel yang memerlukan sejumlah kueri untuk menulis ke disk.
-
Ini umumnya menimbulkan biaya kinerja sistem ACID-compliant transaksi.
DynamoDB menskalakan dengan baik karena alasan berikut:
-
Fleksibilitas skema memungkinkan DynamoDB menyimpan data hierarkis kompleks dalam satu item.
-
Desain kunci komposit memungkinkan DynamoDB menyimpan item terkait secara berdekatan di tabel yang sama.
-
Transaksi dilakukan dalam satu operasi. Batas jumlah item yang dapat diakses adalah 100, untuk menghindari operasi yang berjalan lama.
Kueri terhadap penyimpanan data menjadi jauh lebih sederhana, sering kali dalam bentuk berikut:
SELECT * FROM Table_X WHERE Attribute_Y = "somevalue"
DynamoDB dapat memberikan data yang diminta dengan lebih efisien dibandingkan RDBMS dalam contoh sebelumnya.
