Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Saat Anda perlu menanyakan data terbaru dalam jendela waktu tertentu, persyaratan DynamoDB untuk menyediakan kunci partisi untuk sebagian besar operasi baca dapat menghadirkan tantangan. Untuk mengatasi skenario ini, Anda dapat menerapkan pola kueri yang efektif menggunakan kombinasi sharding tulis dan Indeks Sekunder Global (GSI).
Pendekatan ini memungkinkan Anda untuk secara efisien mengambil dan menganalisis data sensitif waktu tanpa melakukan pemindaian tabel lengkap, yang dapat memakan banyak sumber daya dan mahal. Dengan merancang struktur tabel dan pengindeksan secara strategis, Anda dapat membuat solusi fleksibel yang mendukung pengambilan data berbasis waktu sambil mempertahankan kinerja optimal.
Topik
Desain pola
Saat bekerja dengan DynamoDB, Anda dapat mengatasi tantangan pengambilan data berbasis waktu dengan menerapkan pola canggih yang menggabungkan sharding tulis dan Indeks Sekunder Global untuk memungkinkan kueri yang fleksibel dan efisien di seluruh jendela data terbaru.
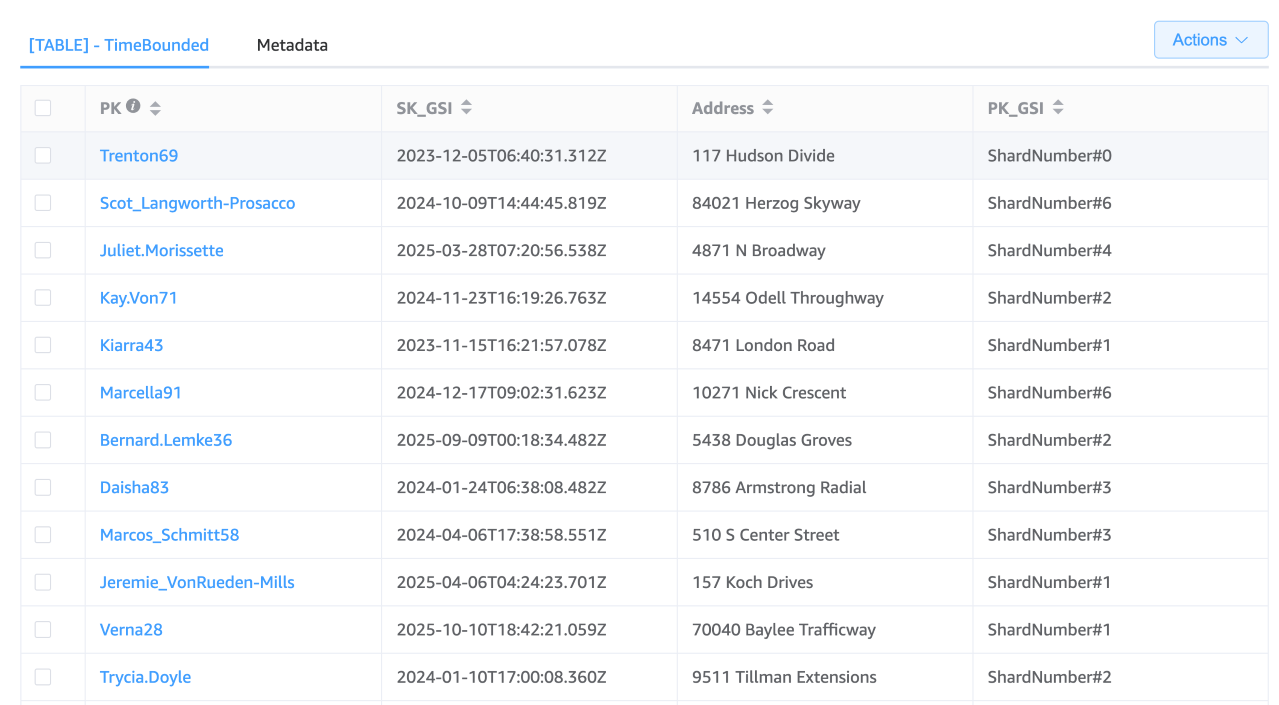
Struktur tabel
Kunci Partisi (PK): “Nama Pengguna”
Struktur GSI
Kunci Partisi GSI (PK_GSI): "#” ShardNumber
Kunci Sortir GSI (SK_GSI): Stempel waktu ISO 8601 (misalnya, “2030-04-01T 12:00:00 Z”)
Strategi sharding
Dengan asumsi Anda memutuskan untuk menggunakan 10 pecahan, nomor pecahan Anda bisa berkisar dari 0 hingga 9. Saat mencatat aktivitas, Anda akan menghitung nomor pecahan (misalnya, dengan menggunakan fungsi hash pada ID pengguna dan kemudian mengambil modulus jumlah pecahan) dan menambahkannya ke kunci partisi GSI. Metode ini mendistribusikan entri di berbagai pecahan, mengurangi risiko partisi panas.
Meminta GSI yang dipecah
Query di semua pecahan untuk item dalam rentang waktu tertentu dalam tabel DynamoDB, di mana data di-sharded di beberapa kunci partisi, memerlukan pendekatan yang berbeda dari query partisi tunggal. Karena kueri DynamoDB terbatas pada satu kunci partisi pada satu waktu, Anda tidak dapat langsung melakukan kueri di beberapa pecahan dengan satu operasi kueri. Namun, Anda dapat mencapai hasil yang diinginkan melalui logika tingkat aplikasi dengan melakukan beberapa kueri, masing-masing menargetkan pecahan tertentu, dan kemudian menggabungkan hasilnya. Prosedur di bawah ini menjelaskan cara melakukan ini.
Untuk kueri dan agregat pecahan
Identifikasi kisaran nomor pecahan yang digunakan dalam strategi sharding Anda. Misalnya, jika Anda memiliki 10 pecahan, nomor pecahan Anda akan berkisar dari 0-9.
Untuk setiap pecahan, buat dan jalankan kueri untuk mengambil item dalam rentang waktu yang diinginkan. Kueri ini dapat dieksekusi secara paralel untuk meningkatkan efisiensi. Gunakan tombol partisi dengan nomor pecahan dan tombol sortir dengan rentang waktu Anda untuk kueri ini. Berikut adalah contoh kueri untuk pecahan tunggal:
aws dynamodb query \ --table-name "YourTableName" \ --index-name "YourIndexName" \ --key-condition-expression "PK_GSI = :pk_val AND SK_GSI BETWEEN :start_date AND :end_date" \ --expression-attribute-values '{ ":pk_val": {"S": "ShardNumber#0"}, ":start_date": {"S": "2024-04-01"}, ":end_date": {"S": "2024-04-30"} }'
Anda akan mereplikasi kueri ini untuk setiap pecahan, menyesuaikan kunci partisi yang sesuai (misalnya, "ShardNumber#1 “," ShardNumber #2 “,...," ShardNumber #9 “).
Agregat hasil dari setiap kueri setelah semua kueri selesai. Lakukan agregasi ini dalam kode aplikasi Anda, gabungkan hasilnya menjadi satu kumpulan data yang mewakili item dari semua pecahan dalam rentang waktu yang ditentukan.
Pertimbangan eksekusi kueri paralel
Setiap kueri menggunakan kapasitas baca dari tabel atau indeks Anda. Jika Anda menggunakan throughput yang disediakan, pastikan tabel Anda disediakan dengan kapasitas yang cukup untuk menangani ledakan kueri paralel. Jika Anda menggunakan kapasitas sesuai permintaan, perhatikan implikasi biaya potensial.
Contoh kode
Untuk mengeksekusi query paralel di seluruh pecahan di DynamoDB menggunakan Python, Anda dapat menggunakan library boto3, yang merupakan Amazon Web Services SDK untuk Python. Contoh ini mengasumsikan Anda telah menginstal boto3 dan dikonfigurasi dengan kredenal yang sesuai. AWS
Kode Python berikut menunjukkan bagaimana melakukan query paralel di beberapa pecahan untuk rentang waktu tertentu. Ini menggunakan futures bersamaan untuk mengeksekusi kueri secara paralel, mengurangi waktu eksekusi keseluruhan dibandingkan dengan eksekusi sekuensial.
import boto3
from concurrent.futures import ThreadPoolExecutor, as_completed
# Initialize a DynamoDB client
dynamodb = boto3.client('dynamodb')
# Define your table name and the total number of shards
table_name = 'YourTableName'
total_shards = 10 # Example: 10 shards numbered 0 to 9
time_start = "2030-03-15T09:00:00Z"
time_end = "2030-03-15T10:00:00Z"
def query_shard(shard_number):
"""
Query items in a specific shard for the given time range.
"""
response = dynamodb.query(
TableName=table_name,
IndexName='YourGSIName', # Replace with your GSI name
KeyConditionExpression="PK_GSI = :pk_val AND SK_GSI BETWEEN :date_start AND :date_end",
ExpressionAttributeValues={
":pk_val": {"S": f"ShardNumber#{shard_number}"},
":date_start": {"S": time_start},
":date_end": {"S": time_end},
}
)
return response['Items']
# Use ThreadPoolExecutor to query across shards in parallel
with ThreadPoolExecutor(max_workers=total_shards) as executor:
# Submit a future for each shard query
futures = {executor.submit(query_shard, shard_number): shard_number for shard_number in range(total_shards)}
# Collect and aggregate results from all shards
all_items = []
for future in as_completed(futures):
shard_number = futures[future]
try:
shard_items = future.result()
all_items.extend(shard_items)
print(f"Shard {shard_number} returned {len(shard_items)} items")
except Exception as exc:
print(f"Shard {shard_number} generated an exception: {exc}")
# Process the aggregated results (e.g., sorting, filtering) as needed
# For example, simply printing the count of all retrieved items
print(f"Total items retrieved from all shards: {len(all_items)}")Sebelum menjalankan kode ini, pastikan untuk mengganti YourTableName dan YourGSIName dengan tabel aktual dan nama GSI dari pengaturan DynamoDB Anda. Juga, sesuaikan total_shardstime_start,, dan time_end variabel sesuai dengan kebutuhan spesifik Anda.
Skrip ini menanyakan setiap pecahan untuk item dalam rentang waktu yang ditentukan dan mengumpulkan hasilnya.
