Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Melatih dan mengevaluasi DeepRacer model AWS menggunakan DeepRacer konsol AWS
Untuk melatih model pembelajaran penguatan, Anda dapat menggunakan DeepRacer konsol AWS. Di konsol tersebut, buat tugas pelatihan, pilih kerangka kerja yang didukung dan algoritme yang tersedia, tambahkan fungsi penghargaan, dan konfigurasikan pengaturan pelatihan. Anda juga dapat menonton pelatihan yang berlangsung di simulator. Anda dapat menemukan step-by-step instruksi diLatih DeepRacer model AWS pertama Anda .
Bagian ini menjelaskan cara melatih dan mengevaluasi DeepRacer model AWS. Bagian ini juga menunjukkan cara membuat dan meningkatkan fungsi penghargaan, bagaimana ruang tindakan memengaruhi performa model, dan bagaimana hyperparameter memengaruhi performa pelatihan. Anda juga dapat mempelajari cara mengkloning model pelatihan untuk memperpanjang sesi pelatihan, cara menggunakan simulator untuk mengevaluasi performa pelatihan, dan cara menangani beberapa simulasi untuk tantangan dunia nyata.
Topik
- Buat fungsi hadiah Anda
- Jelajahi ruang aksi untuk melatih model yang tangguh
- Secara sistematis menyetel hyperparameter
- Memeriksa kemajuan pekerjaan DeepRacer pelatihan AWS
- Kloning model terlatih untuk memulai pass pelatihan baru
- Mengevaluasi DeepRacer model AWS dalam simulasi
- Optimalkan DeepRacer model AWS pelatihan untuk lingkungan nyata
Buat fungsi hadiah Anda
Fungsi hadiah menjelaskan umpan balik langsung (sebagai skor hadiah atau penalti) ketika DeepRacer kendaraan AWS Anda bergerak dari satu posisi di trek ke posisi baru. Fungsi tersebut bertujuan untuk mendorong kendaraan bergerak di sepanjang lintasan untuk mencapai tujuan dengan cepat tanpa kecelakaan atau pelanggaran. Langkah yang diinginkan menghasilkan skor yang lebih tinggi untuk tindakan atau keadaan targetnya. Sebuah langkah ilegal atau boros mendapatkan skor yang lebih rendah. Saat melatih DeepRacer model AWS, fungsi hadiah adalah satu-satunya bagian khusus aplikasi.
Secara umum, Anda merancang fungsi penghargaan untuk bertindak seperti rencana insentif. Strategi insentif yang berbeda dapat mengakibatkan perilaku kendaraan yang berbeda. Untuk membuat kendaraan melaju lebih cepat, fungsi tersebut harus memberikan penghargaan bagi kendaraan untuk mengikuti lintasan. Fungsi tersebut harus mengeluarkan penalti ketika kendaraan terlalu lama menyelesaikan putaran atau keluar dari lintasan. Untuk menghindari pola mengemudi zig-zag, Fungsi tersebut bisa memberi penghargaan pada kendaraan untuk mengarahkan lebih sedikit pada bagian lintasan yang lebih lurus. Fungsi penghargaan mungkin memberikan skor positif ketika kendaraan melewati tonggak tertentu, yang diukur dengan waypoints. Hal ini bisa meringankan waktu tunda atau mengemudi ke arah yang salah. Kemungkinan juga Anda akan mengubah fungsi penghargaan untuk memperhitungkan kondisi lintasan. Namun, semakin banyak fungsi penghargaan Anda mempertimbangkan informasi spesifik lingkungan, semakin besar kemungkinan model terlatih Anda terlalu pas dan kurang umum. Untuk membuat model lebih dapat diterapkan secara umum, Anda dapat menjelajahi ruang tindakan.
Jika rencana insentif tidak dipertimbangkan dengan hati-hati, itu dapat menyebabkan konsekuensi yang tidak diinginkan dari efek sebaliknya
Praktik yang bagus untuk membuat fungsi penghargaan adalah mulai dengan yang sederhana serta mencakup skenario dasar. Anda dapat meningkatkan fungsi untuk menangani lebih banyak tindakan. Sekarang mari kita lihat beberapa fungsi penghargaan sederhana.
Contoh fungsi hadiah sederhana
Kita bisa mulai membangun fungsi penghargaan dengan terlebih dahulu mempertimbangkan situasi yang paling mendasar. Situasi mengemudi di lintasan lurus dari awal hingga akhir tanpa keluar lintasan. Dalam skenario ini, logika fungsi hadiah hanya bergantung pada on_track dan progress. Sebagai percobaan, Anda bisa mulai dengan logika berikut:
def reward_function(params): if not params["all_wheels_on_track"]: reward = -1 else if params["progress"] == 1 : reward = 10 return reward
Logika ini menghukum agen ketika keluar lintasan. Logika ini memberi penghargaan kepada agen saat melaju ke garis finis. Logika ini masuk akal untuk mencapai tujuan yang dinyatakan. Namun, agen berkeliaran dengan bebas antara titik awal dan garis akhir, termasuk mengemudi mundur di lintasan. Pelatihan tidak hanya membutuhkan waktu lama untuk diselesaikan, tetapi juga model yang terlatih akan menyebabkan mengemudi yang kurang efisien saat di-deploy ke kendaraan dunia nyata.
Dalam praktiknya, seorang agen belajar lebih efektif jika dapat melakukannya bit-by-bit selama pelatihan. Ini menyiratkan bahwa fungsi penghargaan harus memberikan penghargaan yang lebih kecil selangkah demi selangkah di sepanjang lintasan. Agar agen dapat mengemudi di lintasan lurus, kami dapat meningkatkan fungsi penghargaan sebagai berikut:
def reward_function(params): if not params["all_wheels_on_track"]: reward = -1 else: reward = params["progress"] return reward
Dengan fungsi ini, agen mendapatkan lebih banyak penghargaan jika semakin dekat dengan garis finis. Agen harus mengurangi atau menghilangkan uji coba mengemudi mundur yang tidak produktif. Secara umum, kami ingin fungsi penghargaan mendistribusikan penghargaan secara lebih merata di ruang tindakan. Menciptakan fungsi penghargaan yang efektif bisa menjadi tugas yang menantang. Anda harus memulai dengan yang sederhana dan secara bertahap meningkatkan atau meningkatkan fungsinya. Dengan eksperimen yang sistematis, fungsi tersebut dapat menjadi lebih tangguh dan efisien.
Tingkatkan fungsi hadiah Anda
Setelah Anda berhasil melatih DeepRacer model AWS Anda untuk jalur lurus sederhana, DeepRacer kendaraan AWS (virtual atau fisik) dapat mengemudi sendiri tanpa keluar jalur. Jika Anda membiarkan kendaraan berjalan di lintasan melingkar, kendaraan tidak akan tetap di lintasan. Fungsi penghargaan telah mengabaikan tindakan untuk berbelok mengikuti lintasan.
Untuk membuat kendaraan Anda menangani tindakan tersebut, Anda harus meningkatkan fungsi penghargaan. Fungsi tersebut harus memberikan penghargaan ketika agen melakukan belokan yang diperbolehkan dan menghasilkan penalti jika agen melakukan belokan yang ilegal. Lalu, Anda siap untuk memulai putaran pelatihan lainnya. Untuk memanfaatkan pelatihan sebelumnya, Anda dapat memulai pelatihan baru dengan mengkloning model yang telah dilatih sebelumnya, meneruskan pengetahuan yang telah dipelajari sebelumnya. Anda dapat mengikuti pola ini untuk secara bertahap menambahkan lebih banyak fitur ke fungsi reward untuk melatih DeepRacer kendaraan AWS Anda untuk mengemudi di lingkungan yang semakin kompleks.
Untuk fungsi penghargaan lanjutan, lihat contoh berikut:
Jelajahi ruang aksi untuk melatih model yang tangguh
Sebagai aturan umum, latih model Anda agar setangguh mungkin agar Anda dapat menerapkannya ke sebanyak mungkin lingkungan. Model tangguh adalah model yang dapat diterapkan pada berbagai bentuk dan kondisi lintasan. Secara umum, model yang tangguh tidak "pintar" karena fungsi penghargaannya tidak memiliki kemampuan untuk memuat pengetahuan spesifik lingkungan yang eksplisit. Jika tidak, model Anda kemungkinan hanya dapat diterapkan pada lingkungan yang serupa dengan lingkungan terlatih.
Memasukkan informasi spesifik lingkungan secara eksplisit ke dalam fungsi penghargaan sama dengan rekayasa fitur. Rekayasa fitur membantu mengurangi waktu pelatihan dan dapat berguna dalam solusi yang dibuat khusus untuk lingkungan tertentu. Untuk melatih model penerapan umum, Anda harus menahan untuk mencoba banyak rekayasa fitur.
Misalnya, saat melatih model pada lintasan melingkar, Anda tidak dapat berharap mendapatkan model terlatih yang berlaku untuk lintasan non-lingkaran mana pun jika Anda memiliki properti geometris yang secara eksplisit dimasukkan ke dalam fungsi penghargaan.
Bagaimana Anda melatih model setangguh mungkin selagi menjaga fungsi penghargaan sesederhana mungkin? Salah satu caranya adalah dengan menjelajahi ruang tindakan yang mencakup tindakan yang dapat dilakukan agen Anda. Cara yang lain adalah untuk bereksperimen dengan hyperparameter dari algoritme pelatihan yang mendasarinya. Sering kali, Anda melakukan keduanya. Di sini, kami fokus pada cara menjelajahi ruang aksi untuk melatih model yang kuat untuk DeepRacer kendaraan AWS Anda.
Dalam melatih DeepRacer model AWS, aksi (a) adalah kombinasi kecepatan (tmeter per detik) dan sudut kemudi (sdalam derajat). Ruang tindakan agen menentukan rentang kecepatan dan sudut kemudi yang dapat diambil agen. Untuk ruang aksi diskrit m jumlah kecepatan, (v1, .., vn) dan n jumlah sudut kemudi, (s1, ..,
sm), ada m*n tindakan yang mungkin dalam ruang aksi:
a1: (v1, s1) ... an: (v1, sn) ... a(i-1)*n+j: (vi, sj) ... a(m-1)*n+1: (vm, s1) ... am*n: (vm, sn)
Nilai sebenarnya dari (vi,
sj) bergantung pada rentang vmax dan |smax| dan tidak terdistribusi secara merata.
Setiap kali Anda memulai pelatihan atau iterasi DeepRacer model AWS Anda, Anda harus terlebih dahulu menentukann,m, vmax dan |smax| atau setuju untuk menggunakan nilai default mereka. Berdasarkan pilihan Anda, DeepRacer layanan AWS menghasilkan tindakan yang tersedia yang dapat dipilih agen Anda dalam pelatihan. Tindakan yang dihasilkan tidak terdistribusi secara merata di ruang tindakan.
Secara umum, jumlah tindakan yang lebih besar dan rentang tindakan yang lebih besar memberi agen Anda lebih banyak ruang atau opsi untuk bereaksi terhadap kondisi lintasan yang lebih bervariasi, seperti lintasan melengkung dengan sudut atau arah belok yang tidak beraturan. Semakin banyak opsi yang tersedia bagi agen, semakin mudah ia menangani variasi lintasan. Hasilnya, Anda dapat berharap bahwa model yang dilatih akan lebih dapat diterapkan secara luas, bahkan saat menggunakan fungsi penghargaan sederhana .
Misalnya, agen Anda dapat belajar dengan cepat untuk menangani lintasan garis lurus menggunakan ruang tindakan tidak halus dengan sejumlah kecepatan dan sudut kemudi yang kecil. Pada lintasan melengkung, ruang tindakan tidak halus ini cenderung menyebabkan agen melampaui batas dan keluar lintasan saat berbelok. Hal ini terjadi karena tidak ada cukup pilihan yang tersedia untuk menyesuaikan kecepatan atau kemudinya. Meningkatkan jumlah kecepatan atau jumlah sudut kemudi atau keduanya, agen harus mampu bermanuver lebih di tikungan selagi tetap berada di lintasan. Demikian pula, jika agen Anda bergerak dengan cara zig-zag, Anda dapat mencoba meningkatkan jumlah rentang kemudi untuk mengurangi belokan drastis pada setiap langkah tertentu.
Ketika ruang tindakan terlalu besar, performa pelatihan mungkin terganggu, karena perlu waktu lebih lama untuk menjelajahi ruang tindakan. Pastikan untuk menyeimbangkan manfaat penerapan umum model terhadap persyaratan performa pelatihannya. Optimalisasi ini melibatkan eksperimen sistematis.
Secara sistematis menyetel hyperparameter
Salah satu cara untuk meningkatkan performa model Anda adalah dengan memberlakukan proses pelatihan yang lebih baik atau lebih efektif. Misalnya, untuk mendapatkan model yang tangguh, pelatihan harus menyediakan sampel yang didistribusikan secara merata kepada agen Anda di ruang tindakan agen. Hal ini membutuhkan perpaduan yang cukup antara eksplorasi dan eksploitasi. Variabel yang mempengaruhi hal ini termasuk jumlah data pelatihan yang digunakan (number of episodes between each
training dan batch size), seberapa cepat agen dapat belajar (learning rate), porsi dari eksplorasi (entropy). Anda mungkin ingin mempercepat proses pembelajaran agar pelatihan menjadi praktis. Variabel yang mempengaruhi hal ini antara lain learning rate, batch size, number of
epochs dan discount factor.
Variabel yang mempengaruhi proses pelatihan dikenal sebagai hyperparameter dari pelatihan. Atribut algoritme ini bukan properti dari model yang mendasarinya. Sayangnya, hyperparameter bersifat empiris. Nilai optimalnya tidak diketahui untuk semua tujuan praktis dan memerlukan eksperimen sistematis untuk diturunkan.
Sebelum membahas hyperparameter yang dapat disesuaikan untuk menyesuaikan kinerja pelatihan DeepRacer model AWS Anda, mari kita tentukan terminologi berikut.
- Titik data
-
Titik data, juga dikenal sebagai pengalaman, itu adalah tupel dari (s, a, r, s'), s singkatan dari pengamatan (atau status) yang ditangkap oleh kamera, a untuk tindakan yang diambil oleh kendaraan, r untuk penghargaan yang diharapkan yang ditimbulkan oleh tindakan tersebut, dan ' untuk pengamatan baru setelah tindakan tersebut dilakukan.
- Episode
-
Episode adalah periode tempat kendaraan mulai dari titik awal tertentu dan berakhir dengan menyelesaikan atau keluar dari lintasan. Hal ini mewujudkan serangkaian pengalaman. Episode yang berbeda dapat memiliki panjang yang berbeda.
- Buffer pengalaman
-
Buffer pengalaman terdiri dari sejumlah titik data terurut yang dikumpulkan melalui sejumlah episode tetap dengan panjang yang bervariasi selama pelatihan. Untuk AWSDeepRacer, ini sesuai dengan gambar yang diambil oleh kamera yang dipasang pada DeepRacer kendaraan AWS Anda dan tindakan yang diambil oleh kendaraan dan berfungsi sebagai sumber dari mana input diambil untuk memperbarui jaringan saraf (kebijakan dan nilai) yang mendasarinya.
- Batch
-
Batch adalah daftar pengalaman yang diurutkan, yang mewakili sebagian simulasi selama periode waktu tertentu, yang digunakan untuk memperbarui bobot jaringan kebijakan. Batch adalah bagian dari buffer pengalaman.
- Data pelatihan
-
Data pelatihan adalah set batch yang diambil sampelnya secara acak dari buffer pengalaman dan digunakan untuk melatih bobot jaringan kebijakan.
| Hyperparameter | Deskripsi |
|---|---|
|
Ukuran batch keturunan gradien |
Jumlah pengalaman kendaraan terbaru yang diambil sampelnya secara acak dari buffer pengalaman dan digunakan untuk memperbarui bobot jaringan neural deep learning yang mendasarinya. Pengambilan sampel secara acak membantu mengurangi korelasi yang melekat pada data input. Gunakan ukuran batch yang lebih besar untuk mempromosikan pembaruan yang lebih stabil dan lancar pada bobot jaringan neural, tetapi waspadai kemungkinan bahwa pelatihan mungkin lebih lama atau lambat.
|
|
Jumlah zaman |
Jumlah lintasan melalui data pelatihan untuk memperbarui bobot jaringan neural selama penurunan gradien. Data pelatihan sesuai dengan sampel acak dari buffer pengalaman. Gunakan jumlah jangka waktu yang lebih besar untuk mempromosikan pembaruan yang lebih stabil, tetapi harapkan pelatihan yang lebih lambat. Ketika ukuran batch kecil, Anda dapat menggunakan jumlah jangka waktu yang lebih kecil
|
|
Tingkat pembelajaran |
Selama pembaruan, sebagian dari bobot baru dapat berasal dari kontribusi keturunan gradien (atau pendakian) dan sisanya dari nilai bobot yang ada. Tingkat pembelajaran mengendalikan seberapa banyak pembaruan keturunan gradien (atau pendakian) berkontribusi pada bobot jaringan. Gunakan tingkat pembelajaran yang lebih tinggi untuk memasukkan lebih banyak kontribusi keturunan gradien untuk pelatihan yang lebih cepat, tetapi waspadai kemungkinan bahwa penghargaan yang diharapkan mungkin tidak menyatu jika tingkat pembelajaran terlalu besar.
|
Entropy |
Tingkat ketidakpastian yang digunakan untuk menentukan kapan harus menambahkan keacakan pada distribusi kebijakan. Ketidakpastian tambahan membantu DeepRacer kendaraan AWS menjelajahi ruang aksi secara lebih luas. Nilai entropi yang lebih besar mendorong kendaraan untuk menjelajahi ruang tindakan lebih teliti.
|
| Faktor diskon |
Sebuah faktor menentukan seberapa banyak penghargaan yang akan datang berkontribusi pada penghargaan yang diharapkan. Semakin besar Faktor diskon semakin jauh kontribusi kendaraan untuk bergerak dan semakin lambat pelatihannya. Dengan faktor diskon 0,9, kendaraan mencakup penghargaan dari urutan 10 langkah di masa depan untuk bergerak. Dengan faktor diskon 0,999, kendaraan mempertimbangkan imbalan dari pesanan 1000 langkah di masa depan untuk bergerak. Nilai faktor diskon yang direkomendasikan adalah 0.99, 0.999 dan 0.9999.
|
| Jenis kerugian |
Tipe fungsi tujuan yang digunakan untuk memperbarui bobot jaringan. Algoritme pelatihan yang bagus harus membuat perubahan tambahan pada strategi agen sehingga secara bertahap beralih dari mengambil tindakan acak ke mengambil tindakan strategis untuk meningkatkan penghargaan. Namun jika perubahannya terlalu besar maka pelatihan menjadi tidak stabil dan agen akhirnya tidak mempelajarinya. Tipe Huber loss
|
| Jumlah episode pengalaman antara setiap iterasi pembaruan kebijakan | Ukuran buffer pengalaman yang digunakan untuk mengambil data pelatihan untuk bobot jaringan kebijakan pembelajaran. Episode pengalaman adalah periode agen mulai dari titik awal tertentu dan akhirnya menyelesaikan lintasan atau keluar dari lintasan. Episode pengalaman terdiri dari serangkaian pengalaman. Episode yang berbeda dapat memiliki panjang yang berbeda. Untuk masalah pembelajaran penguatan sederhana, buffer pengalaman kecil mungkin cukup dan pembelajaran cepat. Untuk masalah yang lebih kompleks yang memiliki lebih banyak maxima lokal, buffer pengalaman yang lebih besar diperlukan untuk menyediakan lebih banyak titik data yang tidak berkorelasi. Dalam hal ini, pelatihan lebih lambat tetapi lebih stabil. Nilai yang direkomendasikan adalah 10, 20 dan 40.
|
Memeriksa kemajuan pekerjaan DeepRacer pelatihan AWS
Setelah memulai tugas pelatihan, Anda dapat memeriksa metrik penghargaan pelatihan dan melacak penyelesaian per episode untuk memastikan performa tugas pelatihan model Anda. Pada DeepRacer konsol AWS, metrik ditampilkan dalam grafik Reward, seperti yang ditunjukkan pada ilustrasi berikut.
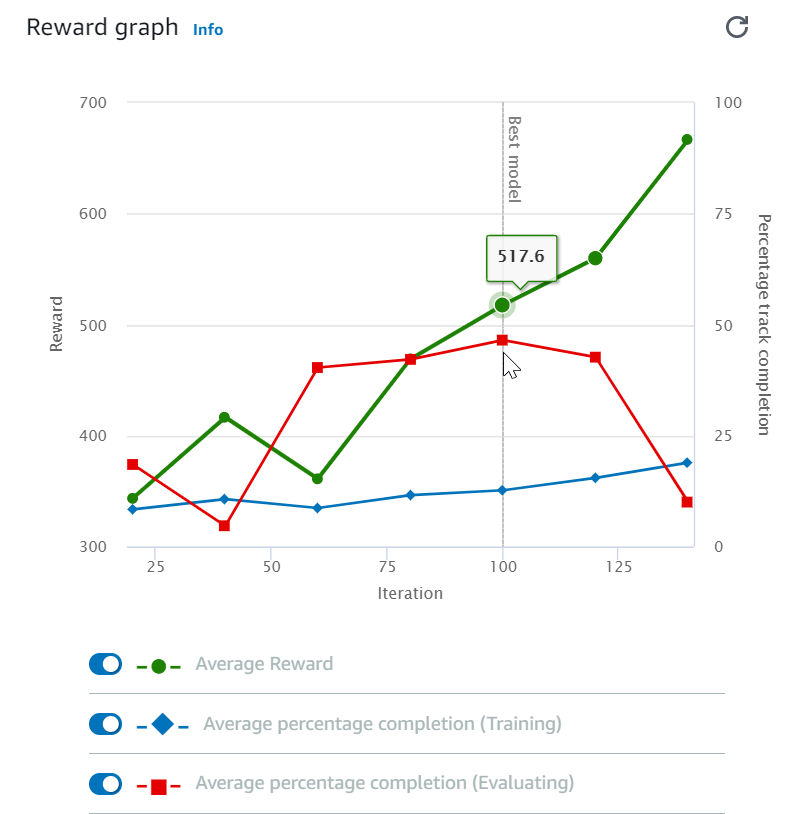
Anda dapat memilih untuk melihat penghargaan yang diperoleh per episode, penghargaan rata-rata per iterasi, kemajuan per episode, kemajuan rata-rata per iterasi atau kombinasi dari semuanya. Untuk melakukannya, alihkan sakelar Penghargaan (Episode, Rata-rata) atau Kemajuan (Episode, Rata-rata) di bagian bawah Grafik penghargaan. Penghargaan dan kemajuan per episode ditampilkan sebagai plot yang tersebar dalam berbagai warna. Penghargaan rata-rata dan penyelesaian lintasan ditampilkan oleh garis plot dan dimulai setelah iterasi pertama.
Rentang penghargaan ditampilkan di sisi kiri grafik dan rentang kemajuan (0-100) ada di sisi kanan. Untuk membaca nilai yang tepat dari metrik pelatihan, gerakkan mouse ke dekat titik data pada grafik.
Grafik diperbarui secara otomatis setiap 10 detik saat pelatihan sedang berlangsung. Anda dapat memilih tombol refresh untuk memperbarui tampilan metrik secara manual.
Tugas pelatihan bagus jika penghargaan rata-rata dan penyelesaian lintasan menunjukkan tren untuk bertemu. Secara khusus, model tersebut kemungkinan telah menyatu jika kemajuan per episode terus menerus mencapai 100% dan tingkat penghargaannya keluar. Jika tidak, kloning model dan latih kembali.
Kloning model terlatih untuk memulai pass pelatihan baru
Jika Anda mengkloning model yang dilatih sebelumnya sebagai titik awal dari putaran baru pelatihan, Anda dapat meningkatkan efisiensi pelatihan. Untuk melakukan ini, ubah hyperparameter untuk memanfaatkan pengetahuan yang sudah dipelajari.
Di bagian ini, Anda mempelajari cara mengkloning model terlatih menggunakan DeepRacer konsol AWS.
Untuk mengulangi pelatihan model pembelajaran penguatan menggunakan konsol AWS DeepRacer
-
Masuk ke DeepRacer konsol AWS, jika Anda belum masuk.
-
Pada halaman Model, pilih model terlatih lalu pilih Klon dari daftar menu drop-down Tindakan.
-
Untuk Detail model, lakukan hal berikut:
-
Ketik
RL_model_1di Nama model, jika Anda tidak menginginkan nama yang dibuat untuk model kloning. -
Secara opsional, berikan deskripsi untuk to-be-cloned model dalam Deskripsi Model - opsional.
-
-
Untuk Simulasi lingkungan, pilih opsi lintasan lain.
-
Untuk Fungsi penghargaan, pilih salah satu contoh fungsi penghargaan yang tersedia. Mengubah fungsi penghargaan. Misalnya, pertimbangkan kemudi.
-
Perluas Pengaturan algoritme dan coba opsi yang berbeda. Sebagai contoh, mengubah nilai Ukuran batch keturunan gradien dari 32 ke 64 atau meningkatkan Tingkat pembelajaran untuk mempercepat pelatihan.
-
Bereksperimen dengan pilihan yang berbeda dari Kondisi berhenti.
-
Pilih Mulai Pelatihan untuk memulai babak baru pelatihan.
Seperti halnya melatih model machine learning yang tangguh secara umum, penting bagi Anda untuk melakukan eksperimen sistematis untuk menghasilkan solusi terbaik.
Mengevaluasi DeepRacer model AWS dalam simulasi
Tujuan mengevaluasi model adalah untuk menguji performa model terlatih. Di AWSDeepRacer, metrik kinerja standar adalah waktu rata-rata menyelesaikan tiga putaran berturut-turut. Dengan menggunakan metrik ini, untuk dua model apa pun, satu model lebih baik daripada yang lain jika dapat membuat agen bergerak lebih cepat di jalur yang sama.
Secara umum, mengevaluasi model melibatkan tugas-tugas berikut:
-
Mengonfigurasi dan memulai tugas evaluasi.
-
Amati evaluasi yang sedang berlangsung saat tugas sedang berjalan. Ini dapat dilakukan di DeepRacer simulator AWS.
-
Periksa ringkasan evaluasi setelah tugas evaluasi selesai. Anda dapat mengakhiri tugas evaluasi yang sedang berlangsung kapan saja.
catatan
Waktu evaluasi tergantung pada kriteria yang Anda pilih. Jika model Anda tidak memenuhi kriteria evaluasi, evaluasi akan terus berjalan hingga mencapai batas 20 menit.
-
Secara opsional, kirimkan hasil evaluasi ke DeepRacerpapan peringkat AWS yang memenuhi syarat. Peringkat di papan peringkat memungkinkan Anda mengetahui seberapa baik performa model Anda terhadap peserta lain.
Uji DeepRacer model AWS dengan DeepRacer kendaraan AWS yang mengemudi di trek fisik, lihatOperasikan DeepRacer kendaraan AWS Anda .
Optimalkan DeepRacer model AWS pelatihan untuk lingkungan nyata
Banyak faktor yang mempengaruhi performa dunia nyata dari model yang dilatih, termasuk pilihan ruang tindakan, fungsi penghargaan, hyperparameter yang digunakan dalam pelatihan, dan kalibrasi kendaraan serta kondisi lintasan di dunia nyata . Selain itu, simulasi hanya merupakan perkiraan (sering tidak akurat) dari dunia nyata. Pelatihan ini menjadikannya tantangan untuk melatih model dalam simulasi, menerapkannya ke dunia nyata, dan mencapai performa yang memuaskan.
Melatih model untuk memberikan performa dunia nyata yang solid sering kali membutuhkan banyak iterasi untuk mengeksplorasi fungsi penghargaan, ruang tindakan, hyperparameter, dan evaluasi dalam simulasi dan Pengujian di lingkungan nyata. Langkah terakhir melibatkan apa yang disebut transfer simulation-to-realdunia (sim2real) dan bisa terasa berat.
Untuk membantu mengatasi tantangan sim2real, perhatikan pertimbangan berikut:
-
Pastikan kendaraan Anda dikalibrasi dengan baik.
Hal ini penting karena lingkungan simulasi kemungkinan besar merupakan representasi parsial dari lingkungan nyata. Selain itu, agen mengambil tindakan berdasarkan kondisi lintasan saat ini, seperti yang ditangkap oleh gambar dari kamera, di setiap langkah. Ia tidak dapat melihat cukup jauh untuk merencanakan rutenya dengan kecepatan tinggi. Untuk mengakomodasi hal ini, simulasi memberlakukan batasan pada kecepatan dan kemudi. Untuk memastikan model yang terlatih bekerja di dunia nyata, kendaraan harus dikalibrasi dengan benar agar sesuai dengan hal ini dan pengaturan simulasi lainnya. Untuk informasi lebih lanjut mengenai kalibrasi kendaraan Anda, lihat Mengkalibrasi DeepRacer kendaraan AWS Anda.
-
Uji terlebih dahulu kendaraan Anda dengan model default.
DeepRacerKendaraan AWS Anda dilengkapi dengan model pra-terlatih yang dimuat ke mesin inferensinya. Sebelum menguji model Anda sendiri di dunia nyata, pastikan kendaraan bekerja dengan cukup baik dengan model default. Jika tidak, periksa pengaturan lintasan fisik. Menguji model di lintasan fisik yang dibuat secara tidak benar kemungkinan akan menghasilkan performa yang buruk. Dalam kasus tersebut, konfigurasi ulang atau perbaiki lintasan Anda sebelum memulai atau melanjutkan pengujian.
catatan
Saat menjalankan DeepRacer kendaraan AWS Anda, tindakan disimpulkan sesuai dengan jaringan kebijakan terlatih tanpa meminta fungsi hadiah.
-
Pastikan model bekerja dalam simulasi.
Jika model Anda tidak bekerja dengan baik di dunia nyata, mungkin saja model atau lintasan rusak. Untuk memilah akar masalah, Anda harus terlebih dahulu mengevaluasi model dalam simulasi untuk memeriksa apakah agen simulasi dapat menyelesaikan setidaknya satu putaran tanpa keluar dari lintasan. Anda dapat melakukannya dengan memeriksa konvergensi penghargaan sambil mengamati lintasan agen di simulator. Jika penghargaan mencapai maksimum ketika agen yang disimulasikan menyelesaikan satu putaran tanpa goyah, modelnya kemungkinan besar bagus.
-
Jangan melatih model secara berlebihan.
Melanjutkan pelatihan setelah model secara konsisten menyelesaikan lintasan dalam simulasi akan menyebabkan overfitting pada model. Model yang dilatih berlebihan tidak akan memiliki performa baik di dunia nyata karena model tersebut tidak dapat menangani variasi kecil antara lintasan yang disimulasikan dan lingkungan nyata.
-
Gunakan beberapa model dari iterasi yang berbeda.
Sesi pelatihan khas menghasilkan berbagai model yang jatuh antara underfitted dan overfitted. Karena tidak ada kriteria apriori untuk menentukan model yang tepat, Anda harus memilih beberapa kandidat model saat agen menyelesaikan satu putaran dalam simulator hingga ke titik agen melakukan putaran secara konsisten.
-
Mulai perlahan dan tingkatkan kecepatan mengemudi secara bertahap dalam pengujian.
Saat menguji model yang digunakan untuk kendaraan Anda, mulailah dengan nilai kecepatan maksimum yang rendah. Misalnya, Anda dapat mengatur batas kecepatan pengujian menjadi <10% dari batas kecepatan latihan. Kemudian secara bertahap tingkatkan batas kecepatan pengujian hingga kendaraan mulai bergerak. Anda menetapkan batas kecepatan pengujian saat mengkalibrasi kendaraan menggunakan konsol kendali perangkat. Jika kendaraan berjalan terlalu cepat, misalnya jika kecepatan melebihi yang terlihat selama pelatihan di simulator, model tidak mungkin berkinerja baik di jalur yang sebenarnya.
-
Uji model dengan kendaraan Anda di posisi awal yang berbeda.
Model belajar untuk mengambil jalur tertentu dalam simulasi dan dapat peka terhadap posisinya di dalam lintasan. Anda harus memulai pengujian kendaraan dengan posisi berbeda dalam batas lintasan (dari kiri ke tengah ke kanan) untuk melihat apakah model memiliki performa baik dari posisi tertentu. Kebanyakan model cenderung membuat kendaraan tetap dekat dengan salah satu sisi dari salah satu garis putih. Untuk membantu menganalisis jalur kendaraan, plot posisi kendaraan (x, y) langkah demi langkah dari simulasi untuk mengidentifikasi kemungkinan jalur yang akan diambil oleh kendaraan Anda di lingkungan nyata.
-
Mulai pengujian dengan lintasan lurus.
Lintasan lurus jauh lebih mudah dinavigasi dibandingkan lintasan lengkung. Memulai pengujian Anda dengan lintasan lurus berguna untuk menyingkirkan model yang buruk dengan cepat. Jika sebagian besar waktu kendaraan tidak dapat mengikuti lintasan lurus, model juga tidak akan memiliki performa baik di lintasan melengkung.
-
Perhatikan perilaku tempat kendaraan hanya melakukan satu jenis tindakan,
Ketika kendaraan Anda dapat mengatur untuk mengambil hanya satu jenis tindakan, misalnya, untuk mengarahkan kendaraan ke kiri saja, model kemungkinan over-fitted atau under-fitted. Dengan parameter model yang diberikan, terlalu banyak iterasi dalam pelatihan dapat membuat model terlalu pas. Terlalu sedikit iterasi bisa membuat model kurang pas.
-
Perhatikan kemampuan kendaraan untuk memperbaiki jalurnya di sepanjang batas lintasan.
Model yang bagus membuat kendaraan mengoreksi dirinya sendiri ketika mendekati batas lintasan. Kebanyakan model terlatih memiliki kemampuan ini. Jika kendaraan dapat memperbaiki dirinya sendiri di kedua batas lintasan, model tersebut dianggap lebih tangguh dan berkualitas lebih tinggi.
-
Hati-hati dengan perilaku tidak konsisten yang ditunjukkan oleh kendaraan.
Model kebijakan mewakili distribusi probabilitas untuk mengambil tindakan dalam status tertentu. Dengan model terlatih yang dimuat ke mesin inferensi, kendaraan akan memilih tindakan yang paling mungkin, selangkah demi selangkah, sesuai dengan rekomendasi model. Jika probabilitas tindakan terdistribusi secara merata, kendaraan dapat mengambil salah satu tindakan dengan probabilitas yang sama atau hampir mirip. Hal ini akan menyebabkan perilaku mengemudi yang tidak menentu. Misalnya, ketika kendaraan kadang-kadang mengikuti jalur lurus (misalnya, separuh waktu) dan membuat belokan yang tidak perlu di lain waktu, modelnya kurang pas atau terlalu pas.
-
Hati-hati hanya dengan satu jenis belokan (kiri atau kanan) yang dibuat oleh kendaraan.
Jika kendaraan berbelok ke kiri dengan sangat baik tetapi gagal mengelola kemudi ke kanan, atau, dengan cara yang sama, jika kendaraan hanya berbelok ke kanan dengan baik, tetapi tidak ke kiri, Anda perlu mengkalibrasi atau mengkalibrasi ulang kemudi kendaraan Anda dengan hati-hati. Atau, Anda dapat mencoba menggunakan model yang dilatih dengan pengaturan yang mendekati pengaturan fisik yang sedang diuji.
-
Watch out untuk kendaraan membuat tiba-tiba berubah dan pergi off-track.
Jika kendaraan mengikuti sebagian besar jalur dengan benar, tetapi tiba-tiba membelok keluar jalur, kemungkinan karena gangguan di lingkungan. Gangguan yang paling umum termasuk pantulan cahaya yang tidak terduga atau yang tidak diinginkan. Dalam kasus seperti itu, gunakan penghalang di sekitar lintasan atau cara lain untuk mengurangi cahaya yang menyilaukan.
