Setelah mempertimbangkan dengan cermat, kami memutuskan untuk menghentikan Amazon Kinesis Data Analytics untuk aplikasi SQL:
1. Mulai 1 September 2025, kami tidak akan memberikan perbaikan bug apa pun untuk Amazon Kinesis Data Analytics untuk aplikasi SQL karena kami akan memiliki dukungan terbatas untuk itu, mengingat penghentian yang akan datang.
2. Mulai 15 Oktober 2025, Anda tidak akan dapat membuat Kinesis Data Analytics baru untuk aplikasi SQL.
3. Kami akan menghapus aplikasi Anda mulai 27 Januari 2026. Anda tidak akan dapat memulai atau mengoperasikan Amazon Kinesis Data Analytics untuk aplikasi SQL. Support tidak akan lagi tersedia untuk Amazon Kinesis Data Analytics untuk SQL sejak saat itu. Untuk informasi selengkapnya, lihat Amazon Kinesis Data Analytics untuk penghentian Aplikasi SQL.
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Contoh: Mengambil Nilai yang Paling Sering Terjadi (TOP_K_ITEMS_TUMBLING)
Contoh Amazon Kinesis Data Analytics menunjukkan cara menggunakan fungsi TOP_K_ITEMS_TUMBLING untuk mengambil nilai yang paling sering terjadi di jendela tumbling. Untuk informasi selengkapnya, lihat TOP_K_ITEMS_TUMBLINGfungsi di Amazon Managed Service for Apache Flink SQL Reference.
Fungsi TOP_K_ITEMS_TUMBLING berguna ketika menggabungkan lebih dari puluhan atau ratusan ribu kunci, dan Anda ingin mengurangi penggunaan sumber daya Anda. Fungsi ini menghasilkan hasil yang sama seperti menggabungkan dengan klausa GROUP BY dan ORDER BY.
Dalam contoh ini, Anda menulis catatan berikut ke Amazon Kinesis data stream:
{"TICKER": "TBV"} {"TICKER": "INTC"} {"TICKER": "MSFT"} {"TICKER": "AMZN"} ...
Anda kemudian membuat aplikasi Kinesis Data Analytics AWS Management Console di, dengan aliran data Kinesis sebagai sumber streaming. Proses penemuan membaca catatan sampel pada sumber streaming dan menyimpulkan skema dalam aplikasi dengan satu kolom (TICKER) seperti yang ditunjukkan di bawah ini.

Anda menggunakan kode aplikasi dengan fungsi TOP_K_VALUES_TUMBLING untuk membuat jendela agregasi data. Anda selanjutnya memasukkan data yang dihasilkan ke aliran dalam aplikasi lainnya, seperti yang ditunjukkan dalam tangkapan layar bawah ini:
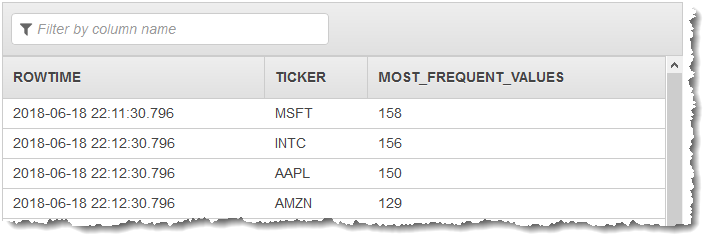
Dalam prosedur berikut, Anda membuat aplikasi Kinesis Data Analytics yang mengambil nilai yang paling sering terjadi di aliran input.
Langkah 1: Buat Kinesis Data Stream
Buat Amazon Kinesis data stream dan isi catatan sebagai berikut:
-
Pilih Data Streams (Aliran Data) di panel navigasi.
-
Pilih Create Kinesis stream (Buat Aliran Kinesis), lalu buat aliran dengan satu serpihan. Untuk informasi selengkapnya, lihat Buat Aliran di Panduan Developer Amazon Kinesis Data Streams.
-
Untuk menulis catatan ke Kinesis data stream di lingkungan produksi, sebaiknya gunakan Kinesis Client Library atau API Kinesis Data Streams. Untuk kemudahan, contoh ini menggunakan skrip Python berikut untuk menghasilkan catatan. Jalankan kode untuk mengisi catatan ticker sampel. Kode sederhana ini terus menulis catatan ticker acak ke aliran. Biarkan skrip tetap berjalan agar Anda dapat menghasilkan skema aplikasi di langkah berikutnya.
import datetime import json import random import boto3 STREAM_NAME = "ExampleInputStream" def get_data(): return { "EVENT_TIME": datetime.datetime.now().isoformat(), "TICKER": random.choice(["AAPL", "AMZN", "MSFT", "INTC", "TBV"]), "PRICE": round(random.random() * 100, 2), } def generate(stream_name, kinesis_client): while True: data = get_data() print(data) kinesis_client.put_record( StreamName=stream_name, Data=json.dumps(data), PartitionKey="partitionkey" ) if __name__ == "__main__": generate(STREAM_NAME, boto3.client("kinesis"))
Langkah 2: Buat Aplikasi Kinesis Data Analytics
Buat aplikasi Amazon Kinesis Data Analytics seperti berikut:
-
Pilih Create application (Buat aplikasi), masukkan nama aplikasi, dan pilih Create application (Buat aplikasi).
-
Pada halaman detail aplikasi, pilih Connect data streaming (Sambungkan data streaming) untuk menyambungkan ke sumber.
-
Di halaman Sambungkan ke sumber, lakukan hal berikut:
-
Pilih aliran yang Anda buat di bagian sebelumnya.
-
Pilih Discover Schema (Temukan Skema). Tunggu hingga konsol menampilkan skema yang disimpulkan dan catatan sampel yang digunakan untuk menyimpulkan skema untuk aliran dalam aplikasi yang dibuat. Skema yang disimpulkan memiliki satu kolom.
-
Pilih Save schema and update stream samples (Simpan skema dan perbarui sampel aliran). Setelah konsol menyimpan skema, pilih Exit (Keluar).
-
Jangan pilih Save and continue (Simpan dan lanjutkan).
-
-
Di halaman detail aplikasi, pilih Go to SQL editor (Buka editor SQL). Untuk memulai aplikasi, pilih Yes, start application (Ya, mulai aplikasi) di kotak dialog yang muncul.
-
Di editor SQL, tulis kode aplikasi, dan verifikasi hasilnya sebagai berikut:
-
Salin kode aplikasi berikut dan tempelkan ke editor:
CREATE OR REPLACE STREAM DESTINATION_SQL_STREAM ( "TICKER" VARCHAR(4), "MOST_FREQUENT_VALUES" BIGINT ); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM * FROM TABLE (TOP_K_ITEMS_TUMBLING( CURSOR(SELECT STREAM * FROM "SOURCE_SQL_STREAM_001"), 'TICKER', -- name of column in single quotes 5, -- number of the most frequently occurring values 60 -- tumbling window size in seconds ) ); -
Pilih Save and run SQL (Simpan dan jalankan SQL).
Di tab Real-time analytics (Analitik waktu nyata), Anda dapat melihat semua aliran dalam aplikasi yang dibuat aplikasi dan memverifikasi data.
-
