Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Tutorial: Menelan data ke dalam koleksi menggunakan Amazon OpenSearch Ingestion
Tutorial ini menunjukkan cara menggunakan Amazon OpenSearch Ingestion untuk mengonfigurasi pipeline sederhana dan menyerap data ke dalam koleksi Amazon OpenSearch Tanpa Server. Pipeline adalah sumber daya yang disediakan dan dikelola oleh OpenSearch Ingestion. Anda dapat menggunakan pipeline untuk memfilter, memperkaya, mengubah, menormalkan, dan mengumpulkan data untuk analitik dan visualisasi hilir di Layanan. OpenSearch
Untuk tutorial yang menunjukkan cara menyerap data ke dalam domain OpenSearch Layanan yang disediakan, lihat. Tutorial: Menelan data ke dalam domain menggunakan Amazon OpenSearch Ingestion
Anda akan menyelesaikan langkah-langkah berikut dalam tutorial ini:.
Dalam tutorial, Anda akan membuat sumber daya berikut:
-
Koleksi bernama
ingestion-collectionbahwa pipa akan menulis -
Sebuah pipa bernama
ingestion-pipeline-serverless
Izin yang diperlukan
Untuk menyelesaikan tutorial ini, pengguna atau peran Anda harus memiliki kebijakan berbasis identitas terlampir dengan izin minimum berikut. Izin ini memungkinkan Anda membuat peran pipeline dan melampirkan kebijakan (iam:Create*daniam:Attach*), membuat atau memodifikasi collection (aoss:*), dan bekerja dengan pipelines (osis:*).
Selain itu, beberapa izin IAM diperlukan untuk secara otomatis membuat peran pipeline dan meneruskannya ke OpenSearch Ingestion sehingga dapat menulis data ke koleksi.
Langkah 1: Buat koleksi
Pertama, buat koleksi untuk menyerap data ke dalam. Kami akan beri nama koleksinyaingestion-collection.
-
Arahkan ke konsol OpenSearch Layanan Amazon di https://console.aws.amazon.com/aos/home
. -
Pilih Koleksi dari navigasi kiri dan pilih Buat koleksi.
-
Di bidang Generasi tanpa server, pilih Beralih ke Klasik.
-
Sebutkan koleksi koleksi ingestion-.
-
Untuk Keamanan, pilih Standard create.
-
Di bawah Pengaturan akses jaringan, ubah jenis akses ke Publik.
-
Simpan semua pengaturan lain sebagai defaultnya dan pilih Berikutnya.
-
Sekarang, konfigurasikan kebijakan akses data untuk koleksi. Hapus pilihan Secara otomatis cocok dengan pengaturan kebijakan akses.
-
Untuk metode Definisi, pilih JSON dan tempel kebijakan berikut ke editor. Kebijakan ini melakukan dua hal:
-
Memungkinkan peran pipeline untuk menulis ke koleksi.
-
Memungkinkan Anda membaca dari koleksi. Kemudian, setelah Anda memasukkan beberapa data sampel ke dalam pipeline, Anda akan menanyakan koleksi untuk memastikan bahwa data berhasil dicerna dan ditulis ke indeks.
[ { "Rules": [ { "Resource": [ "index/ingestion-collection/*" ], "Permission": [ "aoss:CreateIndex", "aoss:UpdateIndex", "aoss:DescribeIndex", "aoss:ReadDocument", "aoss:WriteDocument" ], "ResourceType": "index" } ], "Principal": [ "arn:aws:iam::your-account-id:role/OpenSearchIngestion-PipelineRole", "arn:aws:iam::your-account-id:role/Admin" ], "Description": "Rule 1" } ]
-
-
Ubah
Principalelemen untuk menyertakan Akun AWS ID Anda. Untuk prinsipal kedua, tentukan pengguna atau peran yang dapat Anda gunakan untuk menanyakan koleksi nanti. -
Pilih Berikutnya. Beri nama kebijakan akses pipeline-collection-access dan pilih Berikutnya lagi.
-
Tinjau konfigurasi koleksi Anda dan pilih Kirim.
Langkah 2: Buat pipeline
Sekarang setelah Anda memiliki koleksi, Anda dapat membuat pipeline.
Untuk membuat pipa
-
Di dalam konsol OpenSearch Layanan Amazon, pilih Pipelines dari panel navigasi kiri.
-
Pilih Buat pipeline.
-
Pilih pipeline kosong, lalu pilih Select blueprint.
-
Dalam tutorial ini, kita akan membuat pipeline sederhana yang menggunakan plugin sumber HTTP
. Plugin menerima data log dalam format array JSON. Kami akan menentukan koleksi OpenSearch Tanpa Server tunggal sebagai wastafel, dan menelan semua data ke dalam indeks. my_logsDi menu Sumber, pilih HTTP. Untuk Path, masukkan /logs.
-
Untuk kesederhanaan dalam tutorial ini, kita akan mengkonfigurasi akses publik untuk pipeline. Untuk opsi jaringan Sumber, pilih Akses publik. Untuk informasi tentang mengonfigurasi akses VPC, lihat. Mengkonfigurasi akses VPC untuk saluran pipa Amazon Ingestion OpenSearch
-
Pilih Berikutnya.
-
Untuk Prosesor, masukkan Tanggal dan pilih Tambah.
-
Aktifkan Dari waktu diterima. Biarkan semua pengaturan lain sebagai defaultnya.
-
Pilih Berikutnya.
-
Konfigurasikan detail wastafel. Untuk jenis OpenSearch sumber daya, pilih Koleksi (Tanpa Server). Kemudian pilih koleksi OpenSearch Layanan yang Anda buat di bagian sebelumnya.
Biarkan nama kebijakan jaringan sebagai default. Untuk nama Indeks, masukkan my_logs. OpenSearch Ingestion secara otomatis membuat indeks ini dalam koleksi jika belum ada.
-
Pilih Berikutnya.
-
Beri nama pipeline ingestion-pipeline-serverless. Biarkan pengaturan kapasitas sebagai defaultnya.
-
Untuk peran Pipeline, pilih Buat dan gunakan peran layanan baru. Peran pipa memberikan izin yang diperlukan untuk pipa untuk menulis ke wastafel koleksi dan membaca dari sumber berbasis tarik. Dengan memilih opsi ini, Anda mengizinkan OpenSearch Ingestion untuk membuat peran untuk Anda, daripada membuatnya secara manual di IAM. Untuk informasi selengkapnya, lihat Menyiapkan peran dan pengguna di Amazon OpenSearch Ingestion.
-
Untuk akhiran nama peran Layanan, masukkan PipelineRole. Di IAM, peran akan memiliki format
arn:aws:iam::.your-account-id:role/OpenSearchIngestion-PipelineRole -
Pilih Berikutnya. Tinjau konfigurasi pipeline Anda dan pilih Buat pipeline. Pipa membutuhkan waktu 5-10 menit untuk menjadi aktif.
Langkah 3: Menelan beberapa data sampel
Ketika status pipelineActive, Anda dapat mulai menelan data ke dalamnya. Anda harus menandatangani semua permintaan HTTP ke pipeline menggunakan Signature Version 4. Gunakan alat HTTP seperti Postman
catatan
Kepala sekolah yang menandatangani permintaan harus memiliki izin osis:Ingest IAM.
Pertama, dapatkan URL konsumsi dari halaman pengaturan Pipeline:
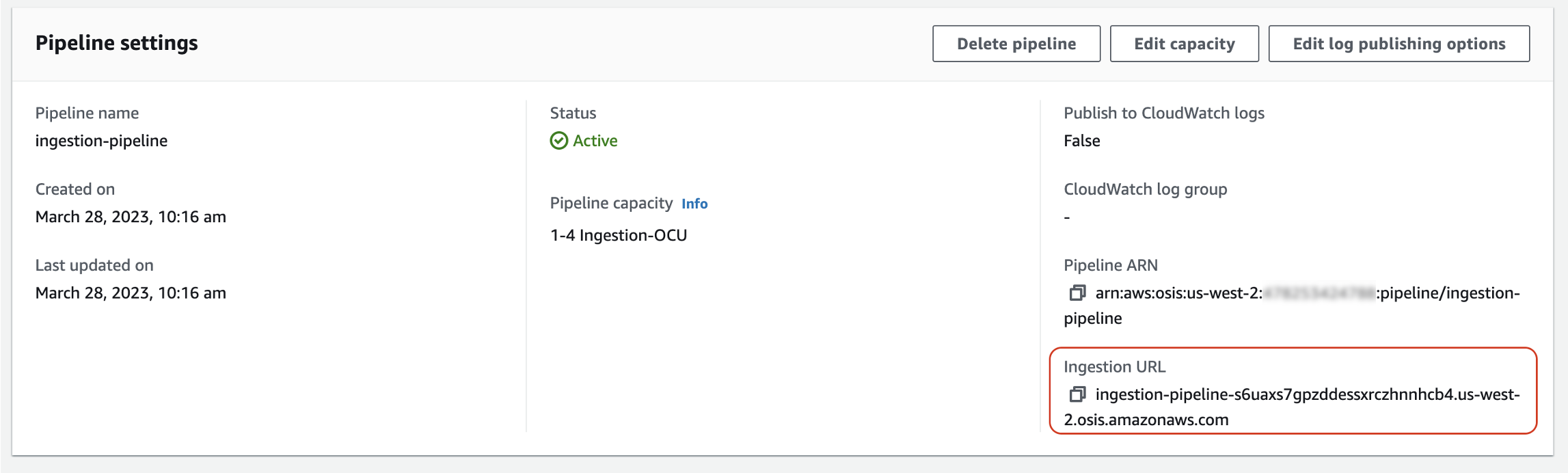
Kemudian, kirim beberapa data sampel ke jalur konsumsi. Permintaan contoh berikut menggunakan awscurl
awscurl --service osis --regionus-east-1\ -X POST \ -H "Content-Type: application/json" \ -d '[{"time":"2014-08-11T11:40:13+00:00","remote_addr":"122.226.223.69","status":"404","request":"GET http://www.k2proxy.com//hello.html HTTP/1.1","http_user_agent":"Mozilla/4.0 (compatible; WOW64; SLCC2;)"}]' \ https://pipeline-endpoint.us-east-1.osis.amazonaws.com/logs
Anda harus melihat 200 OK tanggapan.
Sekarang, kueri my_logs indeks untuk memastikan bahwa entri log berhasil dicerna:
awscurl --service aoss --regionus-east-1\ -X GET \ https://collection-id.us-east-1.aoss.amazonaws.com/my_logs/_search | json_pp
Sampel respon:
{ "took":348, "timed_out":false, "_shards":{ "total":0, "successful":0, "skipped":0, "failed":0 }, "hits":{ "total":{ "value":1, "relation":"eq" }, "max_score":1.0, "hits":[ { "_index":"my_logs", "_id":"1%3A0%3ARJgDvIcBTy5m12xrKE-y", "_score":1.0, "_source":{ "time":"2014-08-11T11:40:13+00:00", "remote_addr":"122.226.223.69", "status":"404", "request":"GET http://www.k2proxy.com//hello.html HTTP/1.1", "http_user_agent":"Mozilla/4.0 (compatible; WOW64; SLCC2;)", "@timestamp":"2023-04-26T05:22:16.204Z" } } ] } }
Sumber daya terkait
Tutorial ini menyajikan kasus penggunaan sederhana menelan satu dokumen melalui HTTP. Dalam skenario produksi, Anda akan mengonfigurasi aplikasi klien Anda (seperti Fluent Bit, Kubernetes, atau OpenTelemetry Collector) untuk mengirim data ke satu atau beberapa pipeline. Saluran pipa Anda kemungkinan akan lebih kompleks daripada contoh sederhana dalam tutorial ini.
Untuk mulai mengonfigurasi klien Anda dan menelan data, lihat sumber daya berikut:
