Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Topik utama di Apache Spark
Bagian ini menjelaskan konsep dasar Apache Spark dan topik utama untuk penyetelan AWS Glue kinerja Apache Spark. Penting untuk memahami konsep dan topik ini sebelum membahas strategi penyetelan dunia nyata.
Arsitektur
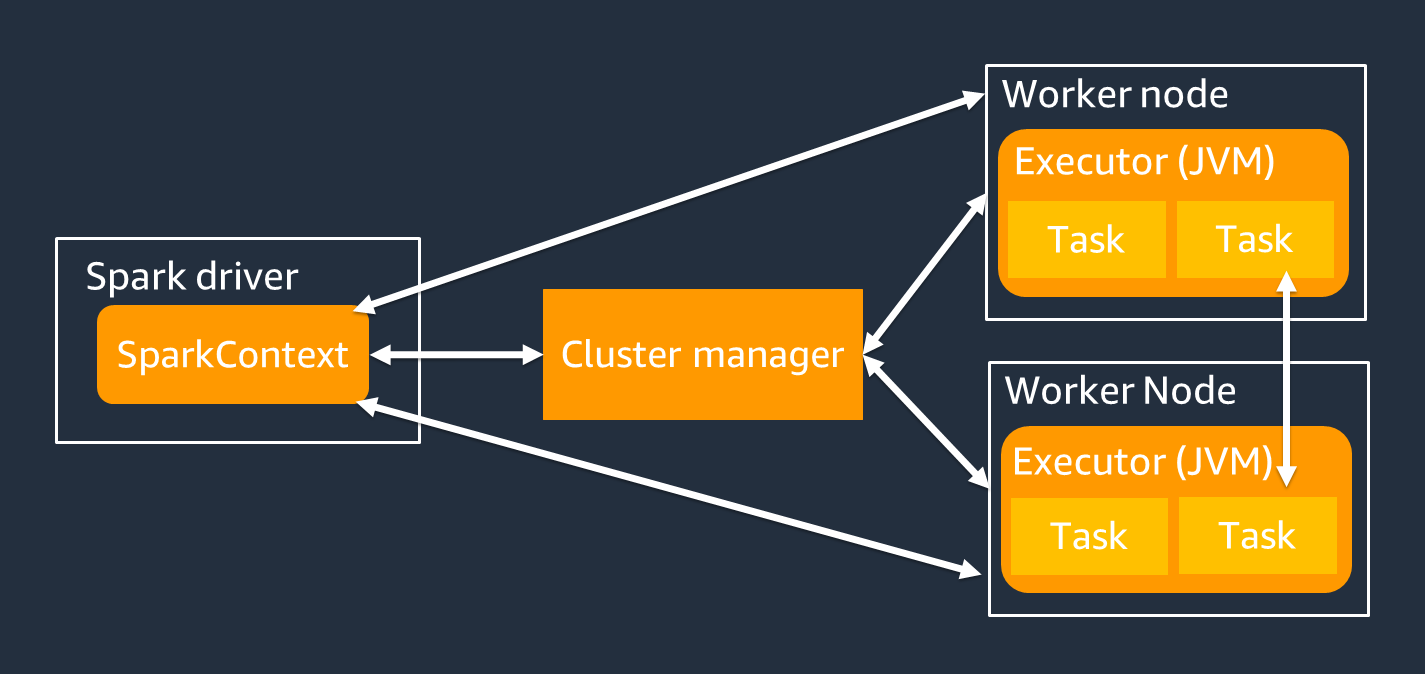
Driver Spark terutama bertanggung jawab untuk membagi aplikasi Spark Anda menjadi tugas-tugas yang dapat diselesaikan pada pekerja individu. Pengemudi Spark memiliki tanggung jawab sebagai berikut:
-
Berjalan
main()di kode Anda -
Menghasilkan rencana eksekusi
-
Penyediaan pelaksana Spark bersama dengan pengelola klaster, yang mengelola sumber daya di cluster
-
Menjadwalkan tugas dan meminta tugas untuk pelaksana Spark
-
Mengelola kemajuan dan pemulihan tugas
Anda menggunakan SparkContext objek untuk berinteraksi dengan driver Spark untuk menjalankan pekerjaan Anda.
Seorang eksekutor Spark adalah pekerja untuk menyimpan data dan menjalankan tugas yang diteruskan dari driver Spark. Jumlah pelaksana Spark akan naik dan turun dengan ukuran cluster Anda.
catatan
Seorang eksekutor Spark memiliki beberapa slot sehingga banyak tugas untuk diproses secara paralel. Spark mendukung satu tugas untuk setiap inti CPU virtual (vCPU) secara default. Misalnya, jika seorang eksekutor memiliki empat core CPU, ia dapat menjalankan empat tugas bersamaan.
Dataset terdistribusi yang tangguh
Spark melakukan pekerjaan kompleks menyimpan dan melacak kumpulan data besar di seluruh pelaksana Spark. Saat Anda menulis kode untuk pekerjaan Spark, Anda tidak perlu memikirkan detail penyimpanan. Spark menyediakan abstraksi kumpulan data terdistribusi tangguh (RDD), yang merupakan kumpulan elemen yang dapat dioperasikan secara paralel dan dapat dipartisi di seluruh pelaksana Spark cluster.
Gambar berikut menunjukkan perbedaan dalam cara menyimpan data dalam memori ketika skrip Python dijalankan di lingkungan tipikal dan ketika dijalankan dalam kerangka Spark (). PySpark
![Python val [1,2,3 N], Apache Spark rdd = sc.paralelisasi [1,2,3 N].](images/store-data-memory.png)
-
Python — Menulis
val = [1,2,3...N]dalam skrip Python menyimpan data dalam memori pada mesin tunggal tempat kode berjalan. -
PySpark— Spark menyediakan struktur data RDD untuk memuat dan memproses data yang didistribusikan di seluruh memori pada beberapa pelaksana Spark. Anda dapat menghasilkan RDD dengan kode seperti
rdd = sc.parallelize[1,2,3...N], dan Spark dapat secara otomatis mendistribusikan dan menyimpan data dalam memori di beberapa pelaksana Spark.Dalam banyak AWS Glue pekerjaan, Anda menggunakan RDDs through AWS Glue DynamicFramesdan Spark DataFrames. Ini adalah abstraksi yang memungkinkan Anda untuk menentukan skema data dalam RDD dan melakukan tugas tingkat yang lebih tinggi dengan informasi tambahan itu. Karena mereka menggunakan RDDs secara internal, data didistribusikan secara transparan dan dimuat ke beberapa node dalam kode berikut:
-
DynamicFrame
dyf= glueContext.create_dynamic_frame.from_options( 's3', {"paths": [ "s3://<YourBucket>/<Prefix>/"]}, format="parquet", transformation_ctx="dyf" ) -
DataFrame
df = spark.read.format("parquet") .load("s3://<YourBucket>/<Prefix>")
-
RDD memiliki beberapa fitur berikut:
-
RDDs terdiri dari data yang dibagi menjadi beberapa bagian yang disebut partisi. Setiap eksekutor Spark menyimpan satu atau lebih partisi dalam memori, dan data didistribusikan di beberapa pelaksana.
-
RDDs tidak dapat diubah, artinya mereka tidak dapat diubah setelah dibuat. Untuk mengubah DataFrame, Anda dapat menggunakan transformasi, yang didefinisikan di bagian berikut.
-
RDDs mereplikasi data di seluruh node yang tersedia, sehingga mereka dapat secara otomatis pulih dari kegagalan node.
Evaluasi malas
RDDs mendukung dua jenis operasi: transformasi, yang membuat dataset baru dari yang sudah ada, dan tindakan, yang mengembalikan nilai ke program driver setelah menjalankan perhitungan pada dataset.
-
Transformasi — Karena RDDs tidak dapat diubah, Anda dapat mengubahnya hanya dengan menggunakan transformasi.
Misalnya,
mapadalah transformasi yang melewati setiap elemen dataset melalui fungsi dan mengembalikan RDD baru yang mewakili hasil. Perhatikan bahwamapmetode ini tidak mengembalikan output. Spark menyimpan transformasi abstrak untuk masa depan, daripada membiarkan Anda berinteraksi dengan hasilnya. Spark tidak akan bertindak berdasarkan transformasi sampai Anda memanggil suatu tindakan. -
Tindakan — Menggunakan transformasi, Anda membangun rencana transformasi logis Anda. Untuk memulai perhitungan, Anda menjalankan tindakan seperti,
write,count,showatau.collectSemua transformasi di Spark malas, karena mereka tidak langsung menghitung hasilnya. Sebagai gantinya, Spark mengingat serangkaian transformasi yang diterapkan ke beberapa dataset dasar, seperti objek Amazon Simple Storage Service (Amazon S3) Simple Storage Service (Amazon S3). Transformasi dihitung hanya ketika suatu tindakan membutuhkan hasil untuk dikembalikan ke pengemudi. Desain ini memungkinkan Spark berjalan lebih efisien. Misalnya, pertimbangkan situasi di mana kumpulan data yang dibuat melalui
maptransformasi hanya dikonsumsi oleh transformasi yang secara substansional mengurangi jumlah baris, seperti.reduceAnda kemudian dapat meneruskan kumpulan data yang lebih kecil yang telah mengalami kedua transformasi ke driver, alih-alih meneruskan kumpulan data yang dipetakan yang lebih besar.
Terminologi aplikasi Spark
Bagian ini mencakup terminologi aplikasi Spark. Driver Spark membuat rencana eksekusi dan mengontrol perilaku aplikasi dalam beberapa abstraksi. Istilah berikut ini penting untuk pengembangan, debugging, dan penyetelan kinerja dengan UI Spark.
-
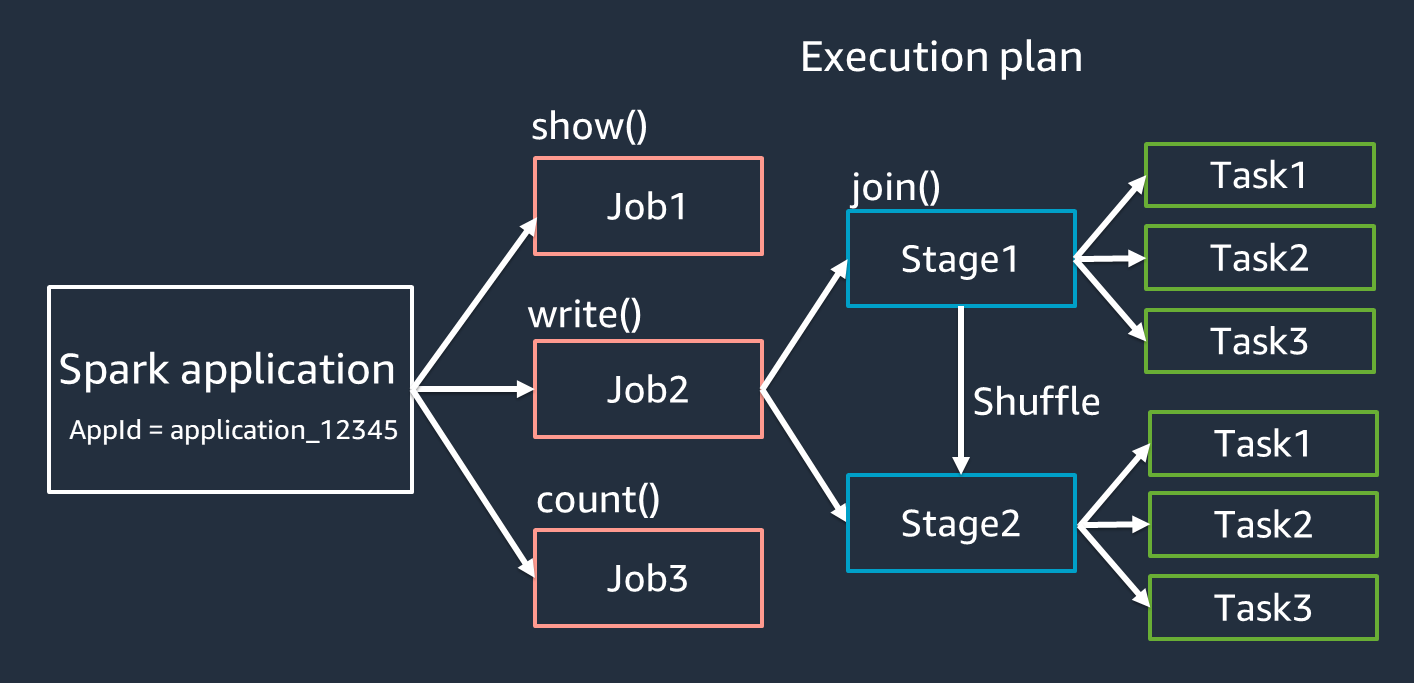
Aplikasi — Berdasarkan sesi Spark (konteks Spark). Diidentifikasi oleh ID unik seperti
<application_XXX>. -
Jobs — Berdasarkan tindakan yang dibuat untuk RDD. Pekerjaan terdiri dari satu tahapan atau lebih.
-
Tahapan — Berdasarkan shuffle yang dibuat untuk RDD. Sebuah panggung terdiri dari satu atau lebih tugas. Shuffle adalah mekanisme Spark untuk mendistribusikan kembali data sehingga dikelompokkan secara berbeda di seluruh partisi RDD. Transformasi tertentu, seperti
join(), membutuhkan pengocokan. Shuffle dibahas secara lebih rinci dalam praktik penyetelan Optimalkan shuffles. -
Tugas — Tugas adalah unit minimum pemrosesan yang dijadwalkan oleh Spark. Tugas dibuat untuk setiap partisi RDD, dan jumlah tugas adalah jumlah maksimum eksekusi simultan di panggung.
catatan
Tugas adalah hal yang paling penting untuk dipertimbangkan ketika mengoptimalkan paralelisme. Jumlah skala tugas dengan jumlah RDD
Paralelisme
Spark memparalelkan tugas untuk memuat dan mengubah data.
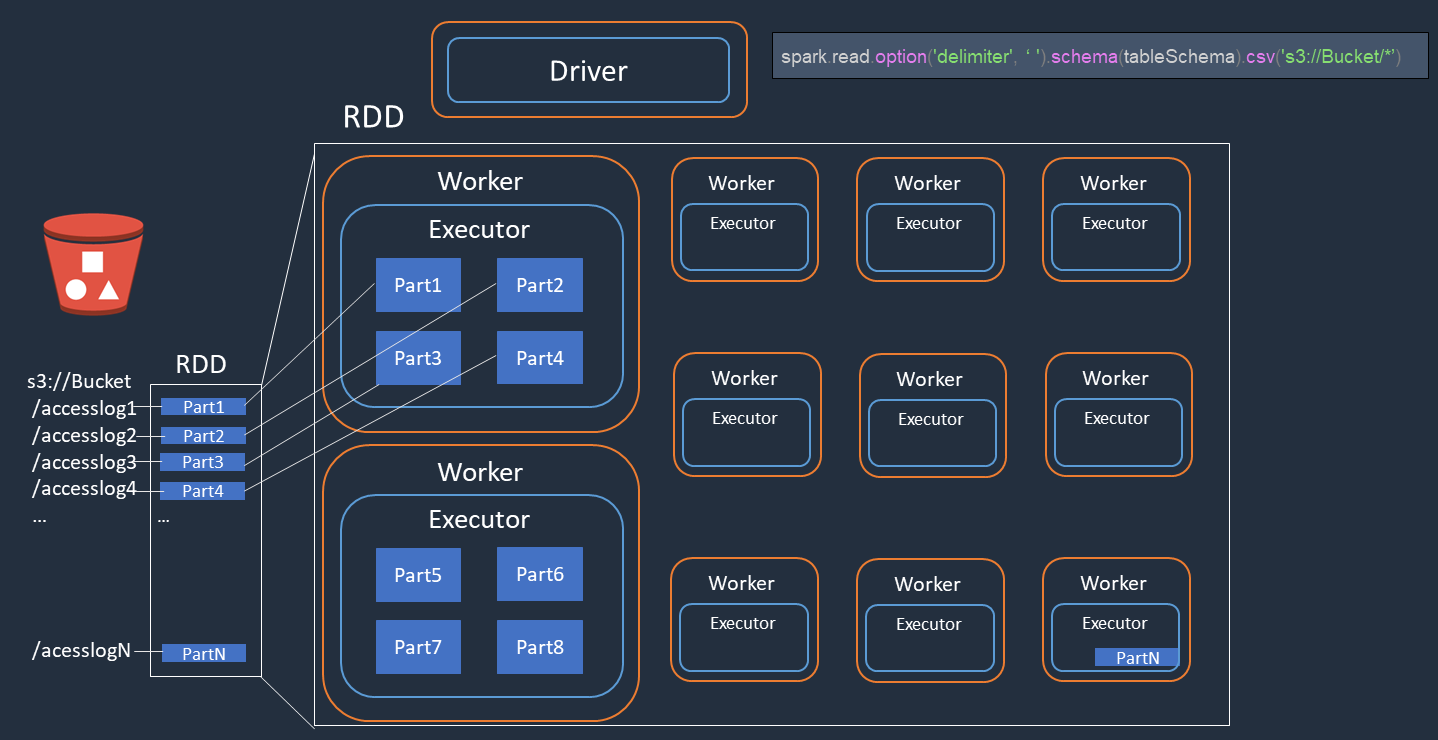
Pertimbangkan contoh di mana Anda melakukan pemrosesan terdistribusi file log akses (bernamaaccesslog1 ... accesslogN) di Amazon S3. Diagram berikut menunjukkan aliran pemrosesan terdistribusi.
-
Driver Spark membuat rencana eksekusi untuk pemrosesan terdistribusi di banyak pelaksana Spark.
-
Driver Spark memberikan tugas setiap pelaksana berdasarkan rencana eksekusi. Secara default, driver Spark membuat partisi RDD (masing-masing sesuai dengan tugas Spark) untuk setiap objek S3 ().
Part1 ... NKemudian driver Spark memberikan tugas kepada setiap eksekutor. -
Setiap tugas Spark mengunduh objek S3 yang ditetapkan dan menyimpannya dalam memori di partisi RDD. Dengan cara ini, beberapa pelaksana Spark mengunduh dan memproses tugas yang ditugaskan secara paralel.
Untuk detail selengkapnya tentang jumlah awal partisi dan pengoptimalan, lihat bagian Parallelize task.
Pengoptimal katalis
Secara internal, Spark menggunakan mesin yang disebut Catalyst Optimizer untuk mengoptimalkan rencana eksekusi
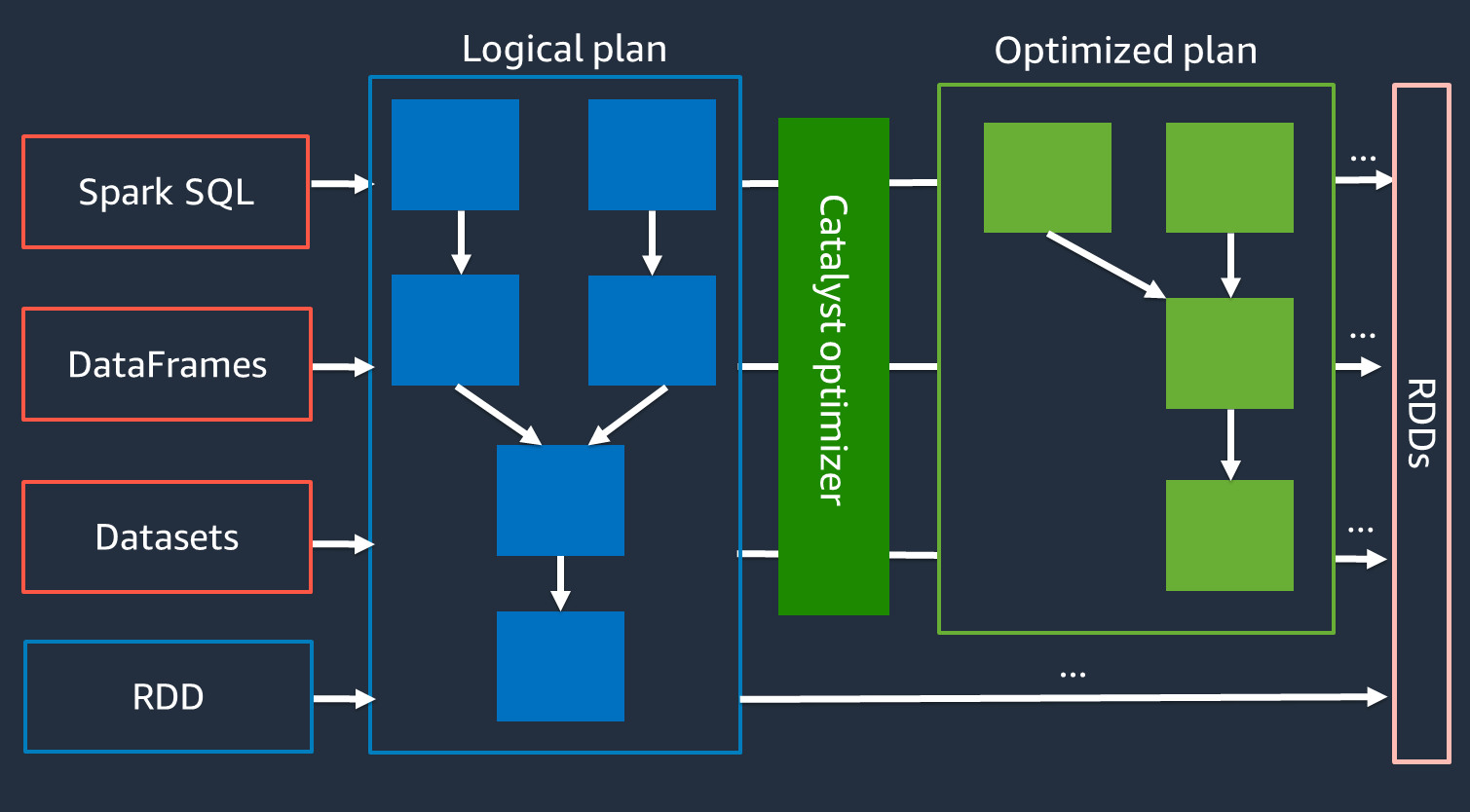
Karena pengoptimal Catalyst tidak bekerja secara langsung dengan API RDD, level tinggi umumnya lebih cepat daripada API RDD tingkat APIs rendah. Untuk gabungan yang kompleks, pengoptimal Catalyst dapat secara signifikan meningkatkan kinerja dengan mengoptimalkan rencana menjalankan pekerjaan. Anda dapat melihat rencana pekerjaan Spark yang dioptimalkan di tab SQL UI Spark.
Eksekusi Kueri Adaptif
Pengoptimal Catalyst melakukan optimasi runtime melalui proses yang disebut Adaptive Query Execution. Eksekusi Kueri Adaptif menggunakan statistik runtime untuk mengoptimalkan kembali rencana run kueri saat pekerjaan Anda berjalan. Adaptive Query Execution menawarkan beberapa solusi untuk tantangan kinerja, termasuk menggabungkan partisi pasca-shuffle, mengonversi gabungan sort-merge menjadi broadcast join, dan pengoptimalan skew join, seperti yang dijelaskan di bagian berikut.
Eksekusi Kueri Adaptif tersedia di AWS Glue 3.0 dan yang lebih baru, dan diaktifkan secara default di AWS Glue 4.0 (Spark 3.3.0) dan yang lebih baru. Eksekusi Kueri Adaptif dapat dihidupkan dan dimatikan dengan menggunakan spark.conf.set("spark.sql.adaptive.enabled",
"true") kode Anda.
Menggabungkan partisi pasca-pengocokan
Fitur ini mengurangi partisi RDD (coalesce) setelah setiap shuffle berdasarkan statistik output. map Ini menyederhanakan penyetelan nomor partisi shuffle saat menjalankan kueri. Anda tidak perlu mengatur nomor partisi acak agar sesuai dengan kumpulan data Anda. Spark dapat memilih nomor partisi shuffle yang tepat saat runtime setelah Anda memiliki jumlah partisi shuffle awal yang cukup besar.
Menggabungkan partisi pasca-shuffle diaktifkan ketika keduanya spark.sql.adaptive.enabled dan disetel ke true. spark.sql.adaptive.coalescePartitions.enabled Untuk informasi selengkapnya, lihat dokumentasi Apache Spark
Mengonversi gabungan sort-merge menjadi broadcast join
Fitur ini mengenali ketika Anda menggabungkan dua kumpulan data dengan ukuran yang sangat berbeda, dan mengadopsi algoritma gabungan yang lebih efisien berdasarkan informasi tersebut. Untuk detail selengkapnya, lihat dokumentasi Apache Spark
Skew bergabung optimasi
Kemiringan data adalah salah satu kemacetan paling umum untuk pekerjaan Spark. Ini menggambarkan situasi di mana data condong ke partisi RDD tertentu (dan akibatnya, tugas tertentu), yang menunda waktu pemrosesan keseluruhan aplikasi. Ini sering dapat menurunkan kinerja operasi gabungan. Fitur pengoptimalan gabungan miring secara dinamis menangani gabungan miring dalam penggabungan sortir dengan membagi (dan mereplikasi jika diperlukan) tugas miring menjadi tugas yang kira-kira berukuran genap.
Fitur ini diaktifkan ketika spark.sql.adaptive.skewJoin.enabled disetel ke true. Untuk detail selengkapnya, lihat dokumentasi Apache Spark
