Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Optimalkan shuffle
Operasi tertentu, seperti join() dangroupByKey(), memerlukan Spark untuk melakukan shuffle. Shuffle adalah mekanisme Spark untuk mendistribusikan kembali data sehingga dikelompokkan secara berbeda di seluruh partisi. RDD Pengocokan dapat membantu memulihkan kemacetan kinerja. Namun, karena shuffling biasanya melibatkan penyalinan data antara pelaksana Spark, shuffle adalah operasi yang kompleks dan mahal. Misalnya, shuffle menghasilkan biaya berikut:
-
Disk I/O:
-
Menghasilkan sejumlah besar file perantara pada disk.
-
-
Jaringan I/O:
-
Membutuhkan banyak koneksi jaringan (Jumlah koneksi =
Mapper × Reducer). -
Karena catatan digabungkan ke RDD partisi baru yang mungkin di-host pada eksekutor Spark yang berbeda, sebagian besar dataset Anda mungkin berpindah antara pelaksana Spark melalui jaringan.
-
-
CPUdan beban memori:
-
Mengurutkan nilai dan menggabungkan kumpulan data. Operasi ini direncanakan pada pelaksana, menempatkan beban berat pada pelaksana.
-
Shuffle adalah salah satu faktor terpenting dalam penurunan kinerja aplikasi Spark Anda. Saat menyimpan data perantara, itu dapat menghabiskan ruang pada disk lokal pelaksana, yang menyebabkan pekerjaan Spark gagal.
Anda dapat menilai kinerja shuffle Anda dalam CloudWatch metrik dan di UI Spark.
CloudWatch metrik
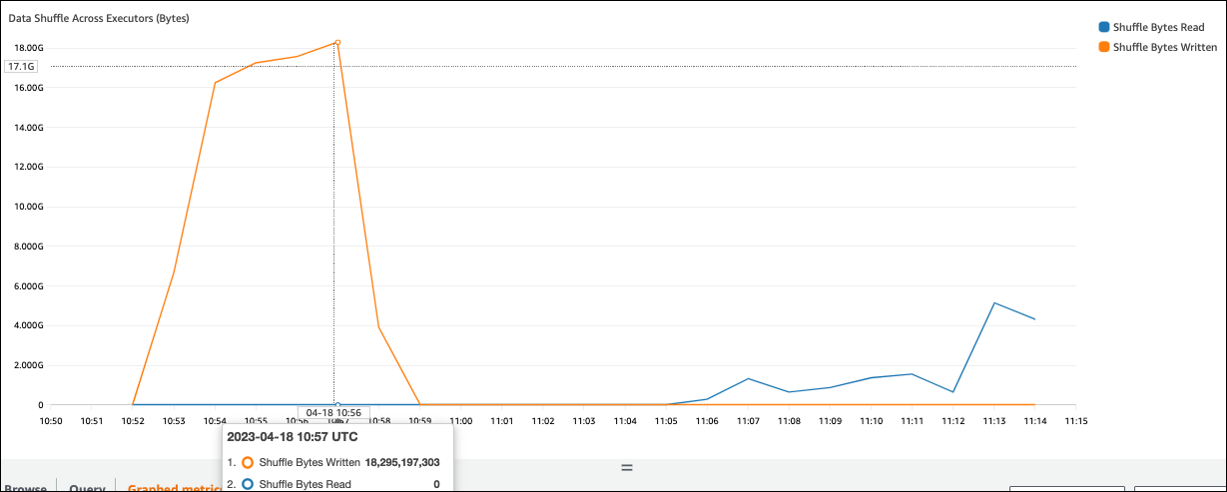
Jika nilai Shuffle Bytes Written tinggi dibandingkan dengan Shuffle Bytes Read, pekerjaan Spark Anda mungkin menggunakan operasi shufflejoin() groupByKey()
Spark UI
Pada tab Tahap UI Spark, Anda dapat memeriksa nilai Shuffle Read Size /Records. Anda juga dapat melihatnya di tab Executors.
Pada tangkapan layar berikut, setiap eksekutor bertukar sekitar 18.6GB/4020000 catatan dengan proses shuffle, dengan total ukuran baca acak sekitar 75 GB).
Kolom Shuffle Spill (Disk) menunjukkan sejumlah besar memori tumpahan data ke disk, yang dapat menyebabkan disk penuh atau masalah kinerja.

Jika Anda mengamati gejala-gejala ini dan tahapannya terlalu lama jika dibandingkan dengan tujuan kinerja Anda, atau gagal dengan Out Of Memory atau No space
left on device kesalahan, pertimbangkan solusi berikut.
Optimalkan bergabung
join()Operasi, yang bergabung dengan tabel, adalah operasi shuffle yang paling umum digunakan, tetapi sering kali merupakan hambatan kinerja. Karena bergabung adalah operasi yang mahal, kami sarankan untuk tidak menggunakannya kecuali itu penting untuk kebutuhan bisnis Anda. Periksa kembali apakah Anda memanfaatkan pipeline data Anda secara efisien dengan mengajukan pertanyaan berikut:
-
Apakah Anda menghitung ulang bergabung yang juga dilakukan di pekerjaan lain yang dapat Anda gunakan kembali?
-
Apakah Anda bergabung untuk menyelesaikan kunci asing untuk nilai-nilai yang tidak digunakan oleh konsumen output Anda?
Setelah Anda mengonfirmasi bahwa operasi gabungan Anda sangat penting untuk kebutuhan bisnis Anda, lihat opsi berikut untuk mengoptimalkan bergabung dengan cara yang memenuhi persyaratan Anda.
Gunakan pushdown sebelum bergabung
Saring baris dan kolom yang tidak perlu di DataFrame sebelum melakukan gabungan. Ini memiliki keuntungan sebagai berikut:
-
Mengurangi jumlah transfer data selama shuffle
-
Mengurangi jumlah pemrosesan di pelaksana Spark
-
Mengurangi jumlah pemindaian data
# Default df_joined = df1.join(df2, ["product_id"]) # Use Pushdown df1_select = df1.select("product_id","product_title","star_rating").filter(col("star_rating")>=4.0) df2_select = df2.select("product_id","category_id") df_joined = df1_select.join(df2_select, ["product_id"])
Gunakan DataFrame Gabung
Coba gunakan Spark tingkat tinggi APIdyf.toDF(). Seperti yang dibahas dalam Topik utama di bagian Apache Spark, operasi gabungan ini secara internal memanfaatkan optimasi kueri oleh pengoptimal Catalyst.
Shuffle dan broadcast hash bergabung dan petunjuk
Spark mendukung dua jenis join: shuffle join dan broadcast hash join. Gabungan hash siaran tidak memerlukan pengocokan, dan dapat memerlukan pemrosesan yang lebih sedikit daripada gabungan acak. Namun, ini hanya berlaku ketika menggabungkan meja kecil ke meja besar. Saat bergabung dengan tabel yang dapat dimasukkan ke dalam memori seorang eksekutor Spark tunggal, pertimbangkan untuk menggunakan gabungan hash siaran.
Diagram berikut menunjukkan struktur tingkat tinggi dan langkah-langkah dari hash broadcast join dan shuffle join.
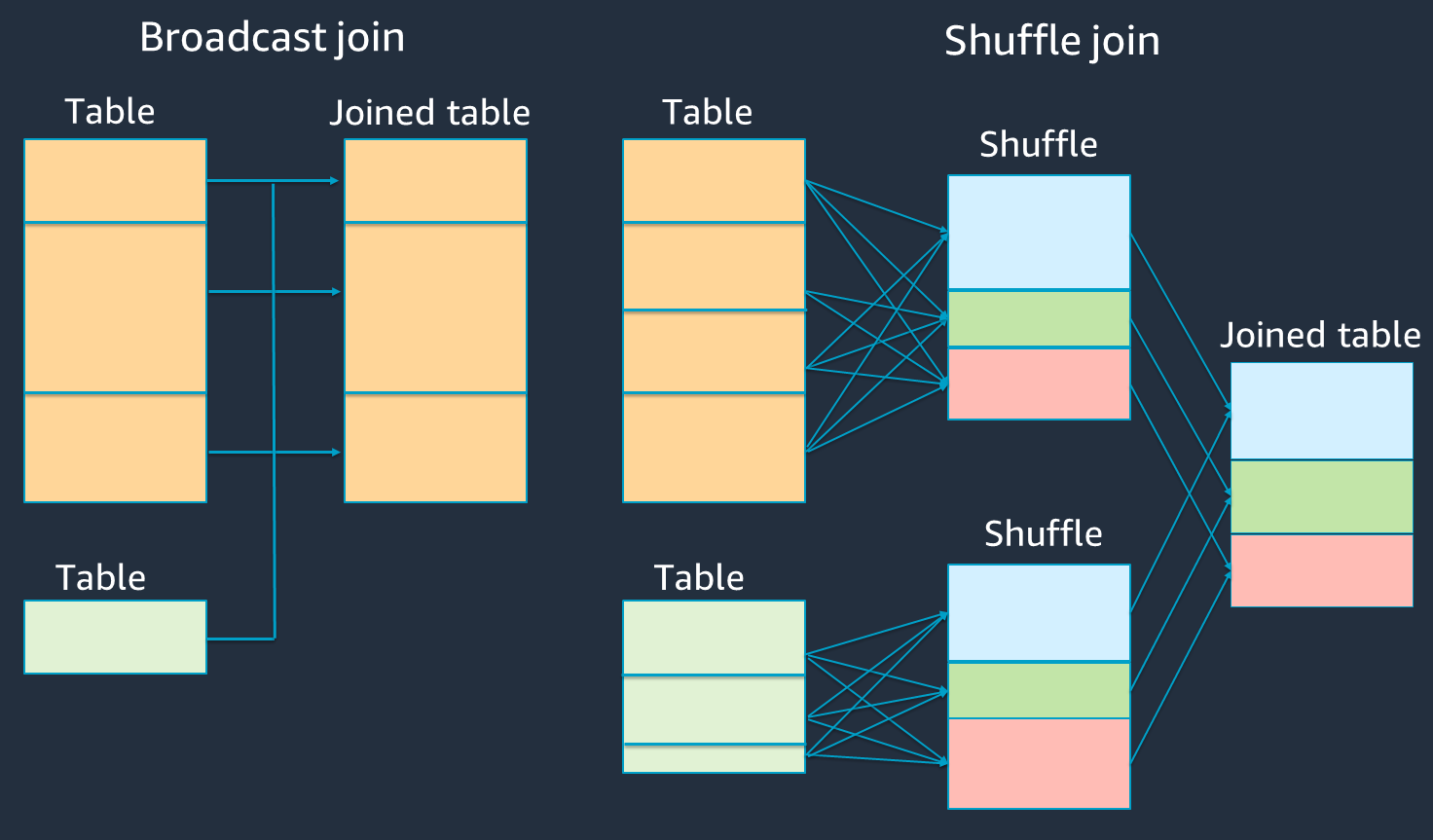
Rincian masing-masing bergabung adalah sebagai berikut:
-
Shuffle bergabung:
-
Hash shuffle bergabung dengan dua tabel tanpa menyortir dan mendistribusikan gabungan antara dua tabel. Ini cocok untuk gabungan tabel kecil yang dapat disimpan dalam memori pelaksana Spark.
-
Gabungan sort-merge mendistribusikan dua tabel untuk digabungkan dengan kunci dan mengurutkannya sebelum bergabung. Ini cocok untuk bergabung dengan meja besar.
-
-
Siaran hash bergabung:
-
Sebuah broadcast hash join mendorong yang lebih kecil RDD atau tabel ke masing-masing node pekerja. Kemudian ia menggabungkan sisi peta dengan setiap partisi yang lebih besar RDD atau tabel.
Ini cocok untuk bergabung ketika salah satu dari Anda RDDs atau tabel dapat dimasukkan ke dalam memori atau dapat dibuat agar sesuai dengan memori. Sangat bermanfaat untuk melakukan broadcast hash join jika memungkinkan, karena tidak memerlukan shuffle. Anda dapat menggunakan petunjuk bergabung untuk meminta siaran bergabung dari Spark sebagai berikut.
# DataFrame from pySpark.sql.functions import broadcast df_joined= df_big.join(broadcast(df_small), right_df[key] == left_df[key], how='inner') -- SparkSQL SELECT /*+ BROADCAST(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key;Untuk informasi selengkapnya tentang petunjuk bergabung, lihat Petunjuk bergabung
.
-
Di AWS Glue 3.0 dan yang lebih baru, Anda dapat memanfaatkan siaran hash bergabung secara otomatis dengan mengaktifkan Adaptive Query Execution
Di AWS Glue 3.0, Anda dapat mengaktifkan Adaptive Query Execution dengan pengaturanspark.sql.adaptive.enabled=true. Eksekusi Kueri Adaptif diaktifkan secara default di AWS Glue 4.0.
Anda dapat mengatur parameter tambahan yang terkait dengan shuffles dan broadcast hash bergabung:
-
spark.sql.adaptive.localShuffleReader.enabled -
spark.sql.adaptive.autoBroadcastJoinThreshold
Untuk informasi selengkapnya tentang parameter terkait, lihat Mengonversi gabungan sort-merge menjadi broadcast join
Di AWS Glue 3.0 dan atau yang lebih baru, Anda dapat menggunakan petunjuk bergabung lainnya untuk shuffle untuk menyesuaikan perilaku Anda.
-- Join Hints for shuffle sort merge join SELECT /*+ SHUFFLE_MERGE(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; SELECT /*+ MERGEJOIN(t2) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; SELECT /*+ MERGE(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; -- Join Hints for shuffle hash join SELECT /*+ SHUFFLE_HASH(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; -- Join Hints for shuffle-and-replicate nested loop join SELECT /*+ SHUFFLE_REPLICATE_NL(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key;
Gunakan bucketing
Gabungan sort-merge membutuhkan dua fase, shuffle dan sort, dan kemudian menggabungkan. Kedua fase ini dapat membebani pelaksana Spark OOM dan menyebabkan serta masalah kinerja ketika beberapa pelaksana bergabung dan yang lainnya menyortir secara bersamaan. Dalam kasus seperti itu, dimungkinkan untuk bergabung secara efisien dengan menggunakan bucketing
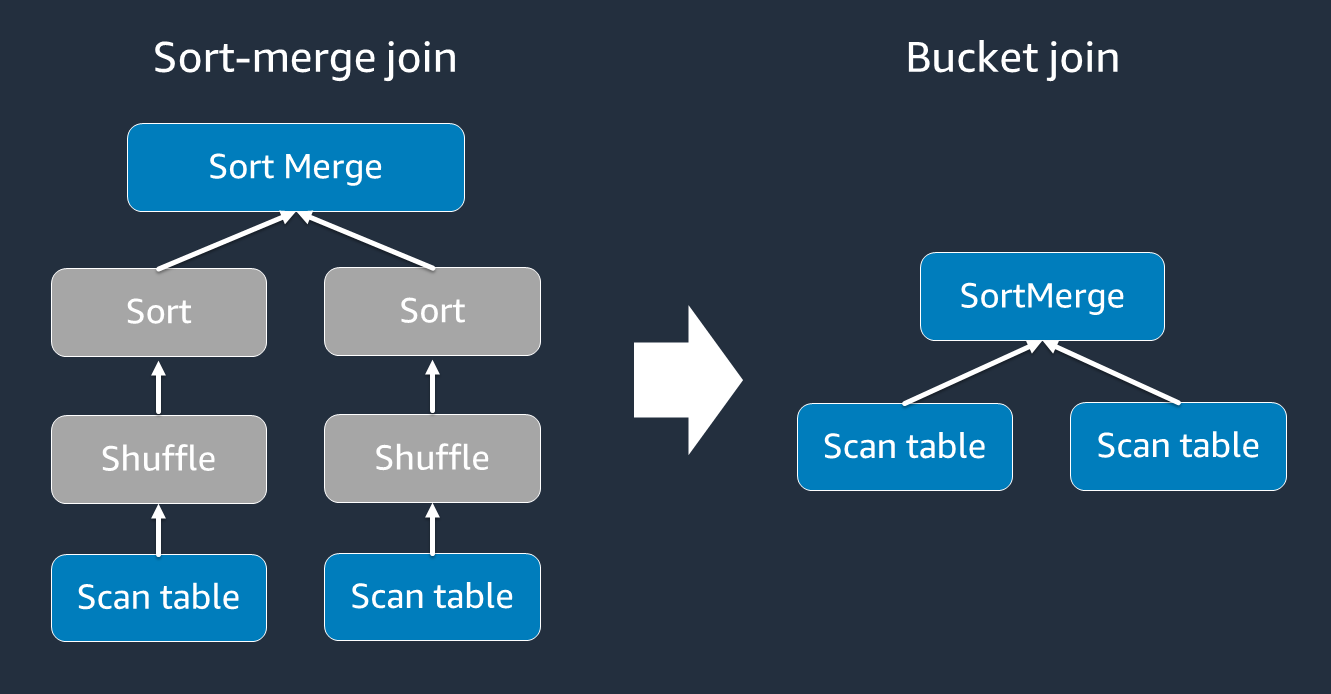
Tabel bucketed berguna untuk hal-hal berikut:
-
Data sering bergabung melalui kunci yang sama, seperti
account_id -
Memuat tabel kumulatif harian, seperti tabel dasar dan delta yang dapat diselimuti pada kolom umum
Anda dapat membuat tabel berember dengan menggunakan kode berikut.
df.write.bucketBy(50, "account_id").sortBy("age").saveAsTable("bucketed_table")
Partisi ulang DataFrames pada kunci gabungan sebelum bergabung
Untuk mempartisi ulang keduanya DataFrames pada kunci gabungan sebelum bergabung, gunakan pernyataan berikut.
df1_repartitioned = df1.repartition(N,"join_key") df2_repartitioned = df2.repartition(N,"join_key") df_joined = df1_repartitioned.join(df2_repartitioned,"product_id")
Ini akan mempartisi dua (masih terpisah) RDDs pada kunci join sebelum memulai join. Jika keduanya RDDs dipartisi pada kunci yang sama dengan kode partisi yang sama, RDD catatan bahwa rencana Anda untuk bergabung bersama akan memiliki kemungkinan besar ditempatkan bersama pada pekerja yang sama sebelum mengocoknya untuk bergabung. Ini dapat meningkatkan kinerja dengan mengurangi aktivitas jaringan dan kemiringan data selama bergabung.
Atasi kemiringan data
Kemiringan data adalah salah satu penyebab paling umum dari kemacetan untuk pekerjaan Spark. Ini terjadi ketika data tidak terdistribusi secara merata di seluruh RDD partisi. Hal ini menyebabkan tugas untuk partisi itu memakan waktu lebih lama daripada yang lain, menunda waktu pemrosesan aplikasi secara keseluruhan.
Untuk mengidentifikasi kemiringan data, nilai metrik berikut di UI Spark:
-
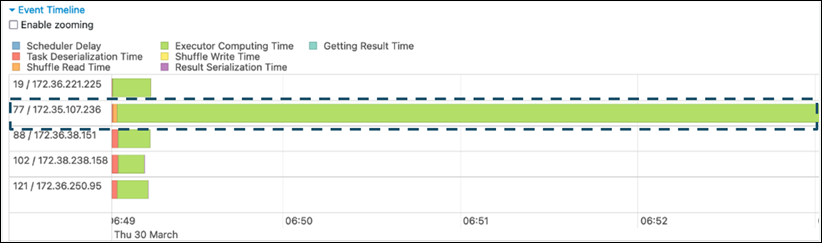
Pada tab Stage di UI Spark, periksa halaman Timeline Acara. Anda dapat melihat distribusi tugas yang tidak merata di tangkapan layar berikut. Tugas yang didistribusikan tidak merata atau terlalu lama untuk dijalankan dapat menunjukkan kemiringan data.
-
Halaman penting lainnya adalah Summary Metrics, yang menunjukkan statistik untuk tugas Spark. Tangkapan layar berikut menunjukkan metrik dengan persentil untuk Durasi, Waktu GC, Tumpahan (memori), Tumpahan (disk), dan sebagainya.

Ketika tugas didistribusikan secara merata, Anda akan melihat angka yang sama di semua persentil. Ketika ada kemiringan data, Anda akan melihat nilai yang sangat bias di setiap persentil. Dalam contoh, durasi tugas kurang dari 13 detik dalam persentil Min, 25, Median, dan 75. Sementara tugas Max memproses data 100 kali lebih banyak daripada persentil ke-75, durasinya 6,4 menit sekitar 30 kali lebih lama. Ini berarti bahwa setidaknya satu tugas (atau hingga 25 persen dari tugas) memakan waktu jauh lebih lama daripada tugas lainnya.
Jika Anda melihat data miring, coba yang berikut ini:
-
Jika Anda menggunakan AWS Glue 3.0, aktifkan Adaptive Query Execution dengan pengaturan
spark.sql.adaptive.enabled=true. Eksekusi Kueri Adaptif diaktifkan secara default di AWS Glue 4.0.Anda juga dapat menggunakan Eksekusi Kueri Adaptif untuk kemiringan data yang diperkenalkan oleh gabungan dengan menyetel parameter terkait berikut:
-
spark.sql.adaptive.skewJoin.skewedPartitionFactor -
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes -
spark.sql.adaptive.advisoryPartitionSizeInBytes=128m (128 mebibytes or larger should be good) -
spark.sql.adaptive.coalescePartitions.enabled=true (when you want to coalesce partitions)
Untuk informasi selengkapnya, lihat dokumentasi Apache Spark
. -
-
Gunakan kunci dengan sejumlah besar nilai untuk tombol gabungan. Dalam shuffle join, partisi ditentukan untuk setiap nilai hash dari sebuah kunci. Jika kardinalitas kunci gabungan terlalu rendah, fungsi hash lebih cenderung melakukan pekerjaan yang buruk dalam mendistribusikan data Anda di seluruh partisi. Oleh karena itu, jika aplikasi dan logika bisnis Anda mendukungnya, pertimbangkan untuk menggunakan kunci kardinalitas yang lebih tinggi atau kunci komposit.
# Use Single Primary Key df_joined = df1_select.join(df2_select, ["primary_key"]) # Use Composite Key df_joined = df1_select.join(df2_select, ["primary_key","secondary_key"])
Gunakan cache
Saat Anda menggunakan repetitif DataFrames, hindari pengocokan atau komputasi tambahan dengan menggunakan df.cache() atau df.persist() menyimpan hasil perhitungan di setiap memori pelaksana Spark dan pada disk. Spark juga mendukung bertahan RDDs pada disk atau mereplikasi di beberapa node (tingkat penyimpanan
Misalnya, Anda dapat bertahan DataFrames dengan menambahkandf.persist(). Ketika cache tidak lagi diperlukan, Anda dapat menggunakan unpersist untuk membuang data cache.
df = spark.read.parquet("s3://<Bucket>/parquet/product_category=Books/") df_high_rate = df.filter(col("star_rating")>=4.0) df_high_rate.persist() df_joined1 = df_high_rate.join(<Table1>, ["key"]) df_joined2 = df_high_rate.join(<Table2>, ["key"]) df_joined3 = df_high_rate.join(<Table3>, ["key"]) ... df_high_rate.unpersist()
Hapus tindakan Spark yang tidak dibutuhkan
Hindari menjalankan tindakan yang tidak perlu seperticount,show, ataucollect. Seperti yang dibahas dalam Topik utama di bagian Apache Spark, Spark malas. Setiap transformasi RDD dapat dihitung ulang setiap kali Anda menjalankan tindakan di atasnya. Bila Anda menggunakan banyak tindakan Spark, beberapa akses sumber, perhitungan tugas, dan shuffle run untuk setiap tindakan akan dipanggil.
Jika Anda tidak membutuhkan collect() atau tindakan lain di lingkungan komersial Anda, pertimbangkan untuk menghapusnya.
catatan
Hindari menggunakan Spark collect() di lingkungan komersial sebanyak mungkin. collect()Tindakan mengembalikan semua hasil perhitungan di pelaksana Spark ke driver Spark, yang dapat menyebabkan driver Spark mengembalikan kesalahan. OOM Untuk menghindari OOM kesalahan, Spark menetapkan secara spark.driver.maxResultSize = 1GB default, yang membatasi ukuran data maksimum yang dikembalikan ke driver Spark ke 1 GB.
