Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Minimalkan overhead perencanaan
Seperti yang dibahas Topik utama di Apache Spark, driver Spark menghasilkan rencana eksekusi. Berdasarkan rencana itu, tugas ditugaskan ke pelaksana Spark untuk pemrosesan terdistribusi. Namun, driver Spark dapat menjadi hambatan jika ada sejumlah besar file kecil atau jika AWS Glue Data Catalog berisi sejumlah besar partisi. Untuk mengidentifikasi overhead perencanaan yang tinggi, nilai metrik berikut.
CloudWatch metrik
Periksa Pemanfaatan CPUBeban dan Memori untuk situasi berikut:
-
CPUBeban driver Spark dan Pemanfaatan Memori dicatat sebagai tinggi. Biasanya, driver Spark tidak memproses data Anda, jadi CPU pemuatan dan pemanfaatan memori tidak melonjak. Namun, jika sumber data Amazon S3 memiliki terlalu banyak file kecil, mencantumkan semua objek S3 dan mengelola sejumlah besar tugas dapat menyebabkan pemanfaatan sumber daya menjadi tinggi.
-
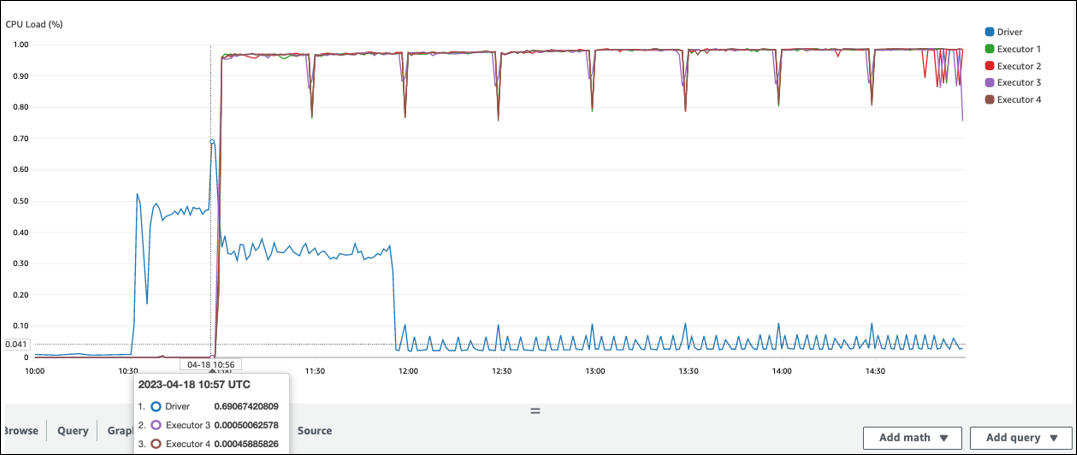
Ada celah panjang sebelum pemrosesan dimulai di pelaksana Spark. Dalam contoh screenshot berikut, CPU Beban pelaksana Spark terlalu rendah hingga 10:57, meskipun pekerjaan dimulai pada 10:00. AWS Glue Ini menunjukkan bahwa driver Spark mungkin membutuhkan waktu lama untuk membuat rencana eksekusi. Dalam contoh ini, mengambil sejumlah besar partisi di Katalog Data dan mencantumkan sejumlah besar file kecil di driver Spark membutuhkan waktu lama.
Spark UI
Pada tab Job di UI Spark, Anda dapat melihat waktu yang dikirimkan. Dalam contoh berikut, pengemudi Spark memulai job0 pada 10:56:46, meskipun pekerjaan dimulai pada 10:00:00. AWS Glue

Anda juga dapat melihat Tugas (untuk semua tahapan): Sukses/Total waktu pada tab Job. Dalam hal ini, jumlah tugas dicatat sebagai58100. Seperti yang dijelaskan di bagian Amazon S3 dari halaman tugas Parallelize, jumlah tugas kira-kira sesuai dengan jumlah objek S3. Ini berarti ada sekitar 58.100 objek di Amazon S3.
Untuk detail selengkapnya tentang pekerjaan dan timeline ini, tinjau tab Stage. Jika Anda mengamati kemacetan dengan driver Spark, pertimbangkan solusi berikut:
-
Ketika Amazon S3 memiliki terlalu banyak partisi, pertimbangkan panduan tentang partisi berlebihan di bagian partisi Amazon S3 Terlalu banyak di halaman Kurangi jumlah pemindaian data. Aktifkan indeks AWS Glue partisi jika ada banyak partisi untuk mengurangi latensi untuk mengambil metadata partisi dari Katalog Data. Untuk informasi selengkapnya, lihat Meningkatkan kinerja kueri menggunakan indeks AWS Glue partisi
. -
Ketika JDBC memiliki terlalu banyak partisi, turunkan
hashpartitionnilainya. -
Ketika DynamoDB memiliki terlalu banyak partisi, turunkan nilainya.
dynamodb.splits -
Ketika pekerjaan streaming memiliki terlalu banyak partisi, turunkan jumlah pecahan.
