Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Lakukan bukti konsep (POC) untuk Amazon Redshift
Amazon Redshift adalah gudang data cloud yang populer, yang menawarkan layanan berbasis cloud yang dikelola sepenuhnya yang terintegrasi dengan data lake Amazon Simple Storage Service organisasi, aliran waktu nyata, alur kerja pembelajaran mesin (ML), alur kerja transaksional, dan banyak lagi. Bagian berikut memandu Anda melalui proses melakukan bukti konsep (POC) di Amazon Redshift. Informasi di sini membantu Anda menetapkan sasaran untuk POC Anda, dan memanfaatkan alat yang dapat mengotomatiskan penyediaan dan konfigurasi layanan untuk POC Anda.
catatan
Untuk salinan informasi ini sebagai PDF, pilih tautan Jalankan POC Redshift Anda sendiri di halaman sumber daya Amazon
Saat melakukan POC Amazon Redshift, Anda menguji, membuktikan, dan mengadopsi fitur mulai best-in-class dari kemampuan keamanan, penskalaan elastis, integrasi dan konsumsi yang mudah, dan opsi arsitektur data terdesentralisasi yang fleksibel.

Ikuti langkah-langkah ini untuk melakukan POC yang sukses.
Langkah 1: Cakupan POC Anda

Saat melakukan POC, Anda dapat memilih untuk menggunakan data Anda sendiri, atau Anda dapat memilih untuk menggunakan kumpulan data benchmarking. Ketika Anda memilih data Anda sendiri, Anda menjalankan kueri Anda sendiri terhadap data. Dengan data pembandingan, kueri sampel disediakan dengan tolok ukur. Lihat Menggunakan kumpulan data sampel untuk detail selengkapnya jika Anda belum siap melakukan POC dengan data Anda sendiri.
Secara umum, kami merekomendasikan penggunaan data dua minggu untuk POC Amazon Redshift.
Mulailah dengan melakukan hal berikut:
Identifikasi kebutuhan bisnis dan fungsional Anda, lalu kerjakan mundur. Contoh umum adalah: kinerja yang lebih cepat, biaya lebih rendah, menguji beban kerja atau fitur baru, atau perbandingan antara Amazon Redshift dan gudang data lainnya.
Tetapkan target spesifik yang menjadi kriteria keberhasilan POC. Misalnya, dari kinerja yang lebih cepat, buat daftar lima proses teratas yang ingin Anda percepat, dan sertakan waktu berjalan saat ini bersama dengan waktu berjalan yang Anda butuhkan. Ini bisa berupa laporan, kueri, proses ETL, konsumsi data, atau apa pun titik nyeri Anda saat ini.
Identifikasi ruang lingkup dan artefak spesifik yang diperlukan untuk menjalankan tes. Kumpulan data apa yang Anda perlukan untuk memigrasikan atau terus-menerus masuk ke Amazon Redshift, dan kueri serta proses apa yang diperlukan untuk menjalankan pengujian untuk mengukur terhadap kriteria keberhasilan? Ada dua cara untuk melakukan hal ini:
Bawa data Anda sendiri
Untuk menguji data Anda sendiri, buat daftar artefak data minimum yang layak yang diperlukan untuk menguji kriteria keberhasilan Anda. Misalnya, jika gudang data Anda saat ini memiliki 200 tabel, tetapi laporan yang ingin Anda uji hanya membutuhkan 20, POC Anda dapat dijalankan lebih cepat dengan hanya menggunakan subset tabel yang lebih kecil.
Gunakan kumpulan data sampel
Jika Anda belum menyiapkan kumpulan data sendiri, Anda masih dapat mulai melakukan POC di Amazon Redshift dengan menggunakan kumpulan data benchmark standar industri seperti TPC-DS atau TPC-H
dan menjalankan contoh kueri benchmarking untuk memanfaatkan kekuatan Amazon Redshift. Kumpulan data ini dapat diakses dari dalam gudang data Amazon Redshift Anda setelah dibuat. Untuk petunjuk terperinci tentang cara mengakses kumpulan data dan kueri sampel ini, lihat. Langkah 2: Luncurkan Amazon Redshift
Langkah 2: Luncurkan Amazon Redshift

Amazon Redshift mempercepat waktu Anda ke wawasan dengan pergudangan data cloud yang cepat, mudah, dan aman dalam skala besar. Anda dapat memulai dengan cepat dengan meluncurkan gudang Anda di konsol Redshift Tanpa Server
Siapkan Amazon Redshift Tanpa Server
Pertama kali Anda menggunakan Redshift Serverless, konsol mengarahkan Anda melalui langkah-langkah yang diperlukan untuk meluncurkan gudang Anda. Anda mungkin juga memenuhi syarat untuk kredit terhadap penggunaan Redshift Tanpa Server di akun Anda. Untuk informasi selengkapnya tentang memilih uji coba gratis, lihat uji coba gratis Amazon Redshift
Jika sebelumnya Anda telah meluncurkan Redshift Serverless di akun Anda, ikuti langkah-langkah dalam Membuat grup kerja dengan namespace di Panduan Manajemen Amazon Redshift. Setelah gudang Anda tersedia, Anda dapat memilih untuk memuat data sampel yang tersedia di Amazon Redshift. Untuk informasi tentang menggunakan editor kueri Amazon Redshift v2 untuk memuat data, lihat Memuat data sampel di Panduan Manajemen Amazon Redshift.
Jika Anda membawa data Anda sendiri alih-alih memuat kumpulan data sampel, lihatLangkah 3: Muat data Anda.
Langkah 3: Muat data Anda

Setelah meluncurkan Redshift Serverless, langkah selanjutnya adalah memuat data Anda untuk POC. Baik Anda mengunggah file CSV sederhana, menelan data semi-terstruktur dari S3, atau streaming data secara langsung, Amazon Redshift memberikan fleksibilitas untuk memindahkan data dengan cepat dan mudah ke tabel Amazon Redshift dari sumbernya.
Pilih salah satu metode berikut untuk memuat data Anda.
Unggah file lokal
Untuk penyerapan dan analisis cepat, Anda dapat menggunakan editor kueri Amazon Redshift v2 untuk memuat file data dengan mudah dari desktop lokal Anda. Ini memiliki kemampuan untuk memproses file dalam berbagai format seperti CSV, JSON, AVRO, PARQUET, ORC, dan banyak lagi. Untuk memungkinkan pengguna Anda, sebagai administrator, memuat data dari desktop lokal menggunakan editor kueri v2, Anda harus menentukan bucket Amazon S3 umum, dan akun pengguna harus dikonfigurasi dengan izin yang tepat. Anda dapat mengikuti Pemuatan data menjadi mudah dan aman di Amazon Redshift menggunakan Query Editor V2
Memuat file Amazon S3
Untuk memuat data dari bucket Amazon S3 ke Amazon Redshift, mulailah dengan menggunakan perintah COPY, tentukan lokasi sumber Amazon S3 dan targetkan tabel Amazon Redshift. Pastikan peran dan izin IAM dikonfigurasi dengan benar untuk memungkinkan Amazon Redshift mengakses bucket Amazon S3 yang ditentukan. Ikuti Tutorial: Memuat data dari Amazon S3 untuk step-by-step panduan. Anda juga dapat memilih opsi Muat data di editor kueri v2 untuk langsung memuat data dari bucket S3 Anda.
Konsumsi data terus menerus
Autocopy (dalam pratinjau) adalah perpanjangan dari perintah COPY dan mengotomatiskan pemuatan data berkelanjutan dari bucket Amazon S3. Saat Anda membuat tugas penyalinan, Amazon Redshift mendeteksi kapan file Amazon S3 baru dibuat di jalur yang ditentukan, lalu memuatnya secara otomatis tanpa campur tangan Anda. Amazon Redshift melacak file yang dimuat untuk memverifikasi bahwa file tersebut dimuat hanya satu kali. Untuk petunjuk tentang cara membuat pekerjaan penyalinan, lihat COPYJOB(pratinjau)
catatan
Salinan otomatis saat ini dalam pratinjau dan hanya didukung di kluster yang disediakan secara spesifik. Wilayah AWS Untuk membuat klaster pratinjau untuk autocopy, lihatMemuat tabel dengan konsumsi file terus menerus dari Amazon S3 (pratinjau).
Muat data streaming Anda
Streaming ingestion menyediakan latensi rendah, konsumsi data streaming berkecepatan tinggi dari Amazon Kinesis Data Streams dan Amazon
Langkah 4: Analisis data Anda

Setelah membuat workgroup Redshift Serverless dan namespace, dan memuat data Anda, Anda dapat langsung menjalankan kueri dengan membuka Query editor v2 dari panel navigasi konsol Redshift Serverless.
Kueri menggunakan editor kueri Amazon Redshift v2
Anda dapat mengakses editor kueri v2 dari konsol Amazon Redshift. Lihat Menyederhanakan analisis data Anda dengan editor kueri Amazon Redshift
Atau, jika Anda ingin menjalankan tes beban sebagai bagian dari POC Anda, Anda dapat melakukan ini dengan langkah-langkah berikut untuk menginstal dan menjalankan Apache JMeter.
Jalankan uji beban menggunakan Apache JMeter
Untuk melakukan uji beban untuk mensimulasikan pengguna “N” yang mengirimkan kueri secara bersamaan ke Amazon Redshift, Anda dapat menggunakan Apache
Untuk menginstal dan mengonfigurasi Apache JMeter agar berjalan terhadap workgroup Redshift Serverless Anda, ikuti petunjuk di Automate Amazon Redshift
Setelah Anda menyelesaikan penyesuaian pernyataan SQL Anda dan menyelesaikan rencana pengujian Anda, simpan dan jalankan rencana pengujian Anda terhadap grup kerja Redshift Serverless Anda. Untuk memantau kemajuan pengujian Anda, buka konsol Redshift Serverless
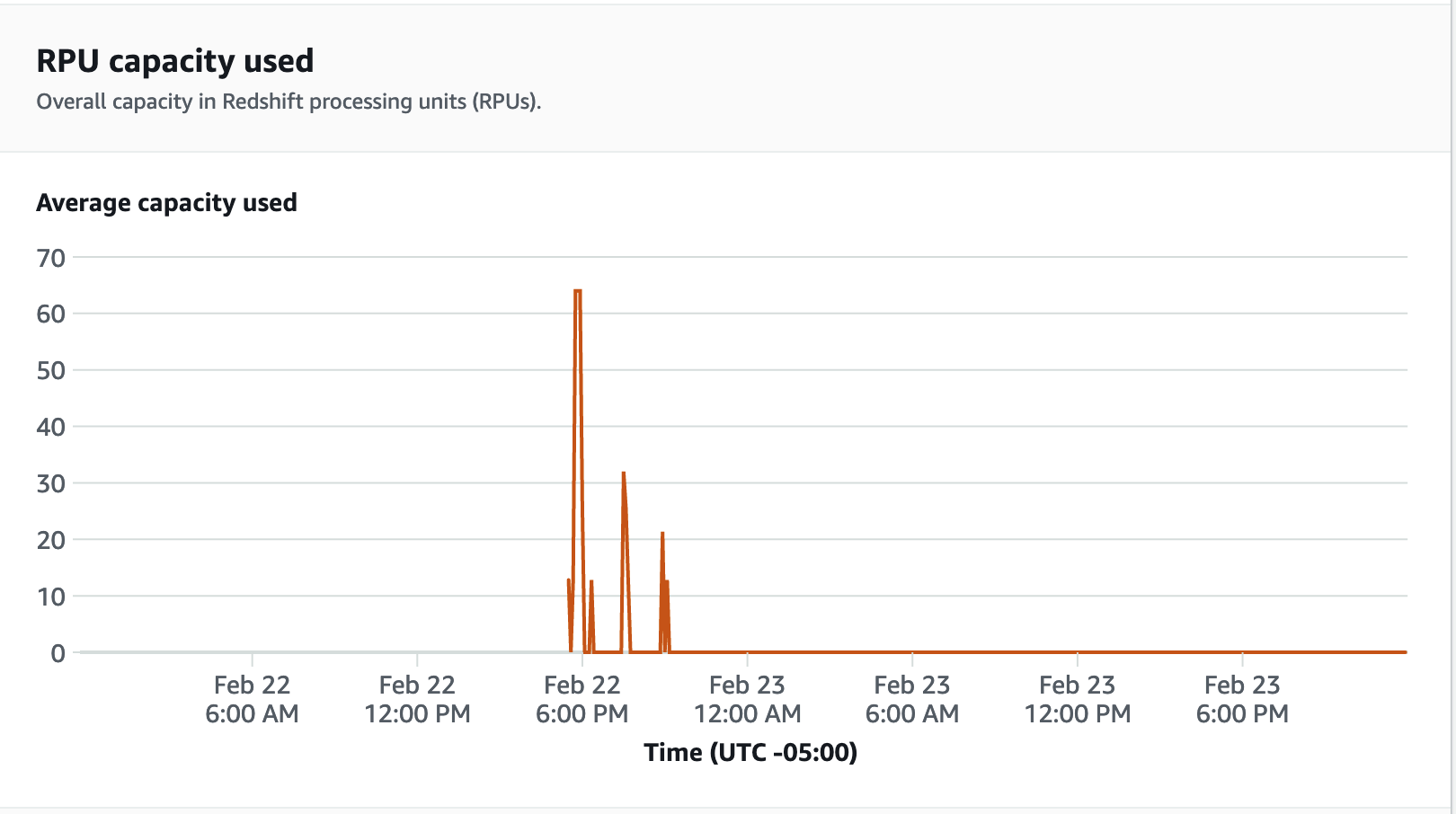
Untuk metrik kinerja, pilih tab Kinerja Database di konsol Redshift Tanpa Server, untuk memantau metrik seperti Koneksi Database dan pemanfaatan CPU. Di sini Anda dapat melihat grafik untuk memantau kapasitas RPU yang digunakan dan mengamati bagaimana Redshift Serverless secara otomatis menskalakan untuk memenuhi tuntutan beban kerja bersamaan saat uji beban berjalan di workgroup Anda.
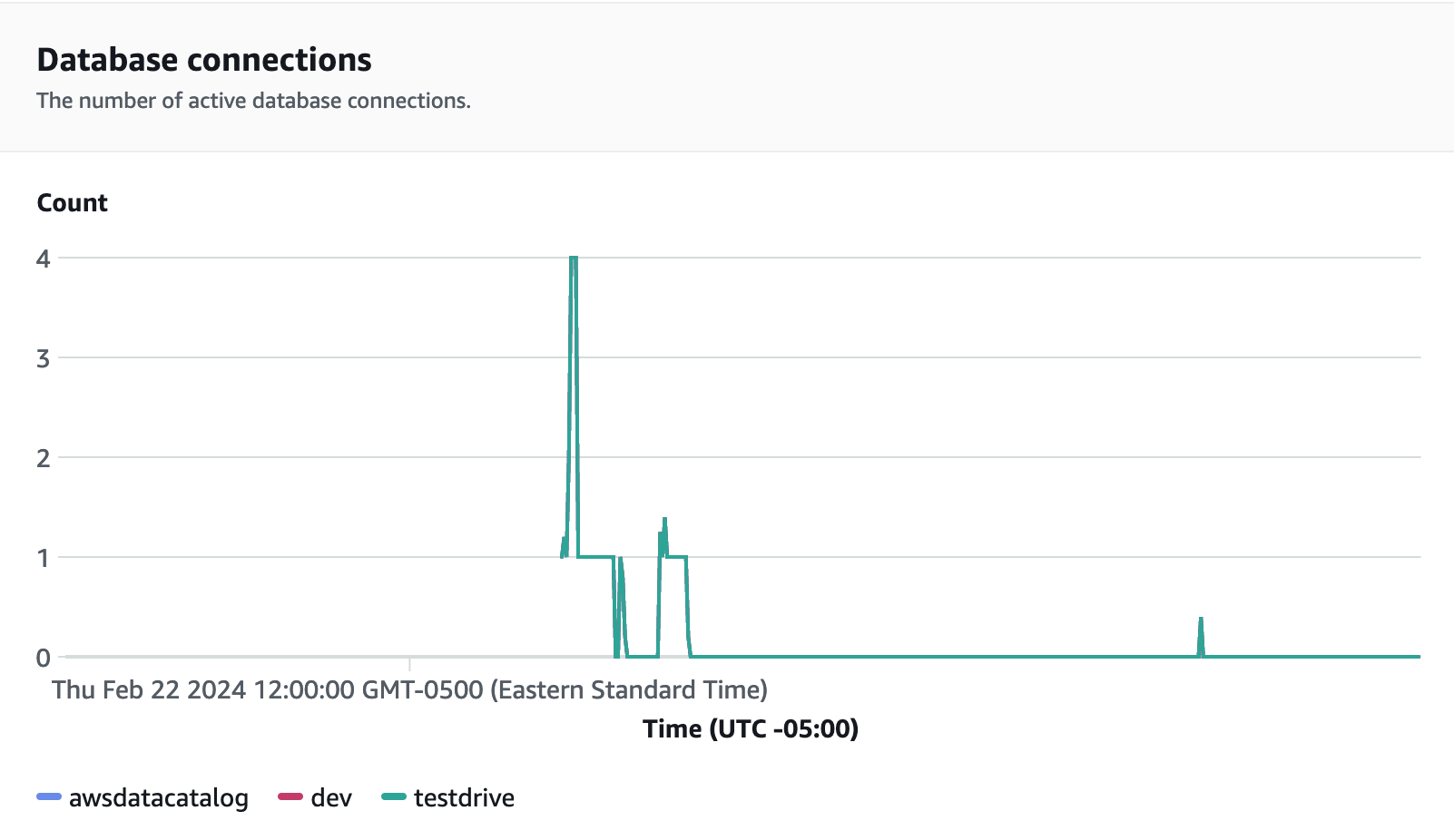
Koneksi database adalah metrik lain yang berguna untuk dipantau saat menjalankan uji beban untuk melihat bagaimana kelompok kerja Anda menangani banyak koneksi bersamaan pada waktu tertentu untuk memenuhi tuntutan beban kerja yang meningkat.
Langkah 5: Optimalkan

Amazon Redshift memberdayakan puluhan ribu pengguna untuk memproses exabyte data setiap hari dan memperkuat beban kerja analitik mereka dengan menawarkan berbagai konfigurasi dan fitur untuk mendukung kasus penggunaan individual. Saat memilih di antara opsi ini, pelanggan mencari alat yang membantu mereka menentukan konfigurasi gudang data yang paling optimal untuk mendukung beban kerja Amazon Redshift mereka.
Test drive
Anda dapat menggunakan Test Drive
