Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Masalah RunBooks
Bagian berikut berisi masalah yang mungkin terjadi, cara mendeteksinya, dan saran tentang cara mengatasi masalah tersebut.
-
Saya ingin mengatur domain khusus setelah saya menginstal RES
Pemberitahuan email tidak diterima setelah AWS CloudFormation tumpukan berhasil dibuat
CloudFormation Tumpukan lingkungan gagal dihapus karena kesalahan objek dependen
Kesalahan yang ditemui untuk parameter blok CIDR selama pembuatan lingkungan
CloudFormation kegagalan pembuatan tumpukan selama pembuatan lingkungan
Pembuatan tumpukan sumber daya eksternal (demo) gagal dengan AdDomainAdminNode CREATE_FAILED
-
-
Masalah instalasi
Topik
- Saya ingin mengatur domain khusus setelah saya menginstal RES
- AWS CloudFormation tumpukan gagal dibuat dengan pesan "WaitCondition menerima pesan gagal. Kesalahan:Negara. TaskFailed”
- Pemberitahuan email tidak diterima setelah AWS CloudFormation tumpukan berhasil dibuat
- Instance bersepeda atau vdc-controller dalam keadaan gagal
- CloudFormation Tumpukan lingkungan gagal dihapus karena kesalahan objek dependen
- Kesalahan yang ditemui untuk parameter blok CIDR selama pembuatan lingkungan
- CloudFormation kegagalan pembuatan tumpukan selama pembuatan lingkungan
- Pembuatan tumpukan sumber daya eksternal (demo) gagal dengan AdDomainAdminNode CREATE_FAILED
........................
Saya ingin mengatur domain khusus setelah saya menginstal RES
catatan
Prasyarat: Anda harus menyimpan Sertifikat dan PrivateKey konten dalam rahasia Secrets Manager sebelum melakukan langkah-langkah ini.
Tambahkan sertifikat ke klien web
-
Perbarui sertifikat yang dilampirkan ke pendengar penyeimbang beban external-alb:
-
Arahkan ke penyeimbang beban eksternal RES di AWS konsol di bawah> Load EC2Balancing> Load Balancers.
-
Cari penyeimbang beban yang mengikuti konvensi
<env-name>-external-alb -
Periksa pendengar yang terpasang pada penyeimbang beban.
-
Perbarui listener yang memiliki sertifikat SSL/TLS Default yang dilampirkan dengan detail sertifikat baru.
-
Simpan perubahan Anda.
-
-
Dalam tabel pengaturan cluster:
-
Temukan tabel pengaturan cluster di DynamoDB -> Tabel ->.
<env-name>.cluster-settings -
Pergi ke Jelajahi Item dan Filter berdasarkan Atribut — nama “kunci”, Ketik “string”, kondisi “berisi”, dan nilai “external_alb”.
-
Setel
cluster.load_balancers.external_alb.certificates.providedke Benar. -
Perbarui nilai
cluster.load_balancers.external_alb.certificates.custom_dns_name. Ini adalah nama domain khusus untuk antarmuka pengguna web. -
Perbarui nilai
cluster.load_balancers.external_alb.certificates.acm_certificate_arn. Ini adalah Nama Sumber Daya Amazon (ARN) untuk sertifikat terkait yang disimpan di Amazon Certificate Manager (ACM).
-
-
Perbarui catatan subdomain Route53 yang sesuai yang Anda buat untuk klien web Anda untuk menunjuk ke nama DNS penyeimbang beban alb eksternal.
<env-name>-external-alb -
Jika SSO sudah dikonfigurasi di lingkungan, konfigurasikan ulang SSO dengan input yang sama seperti yang Anda gunakan awalnya dari tombol Environment Management > Identity management > Single Sign-On > Status > Edit di portal web RES.
Tambahkan sertifikat ke VDIs
-
Berikan izin aplikasi RES untuk melakukan GetSecret operasi pada rahasia dengan menambahkan tag berikut ke rahasia:
-
res:EnvironmentName:<env-name> -
res:ModuleName:virtual-desktop-controller
-
-
Dalam tabel pengaturan cluster:
-
Temukan tabel pengaturan cluster di DynamoDB -> Tabel ->.
<env-name>.cluster-settings -
Pergi ke Jelajahi Item dan Filter berdasarkan Atribut — nama “kunci”, Ketik “string”, kondisi “berisi”, dan nilai “dcv_connection_gateway”.
-
Setel
vdc.dcv_connection_gateway.certificate.providedke Benar. -
Perbarui nilai
vdc.dcv_connection_gateway.certificate.custom_dns_name. Ini adalah nama domain khusus untuk akses VDI. -
Perbarui nilai
vdc.dcv_connection_gateway.certificate.certificate_secret_arn. Ini adalah ARN untuk rahasia yang menyimpan isi Sertifikat. -
Perbarui nilai
vdc.dcv_connection_gateway.certificate.private_key_secret_arn. Ini adalah ARN untuk rahasia yang menyimpan isi Private Key.
-
-
Perbarui template peluncuran yang digunakan untuk instance gateway:
-
Buka grup Auto Scaling di AWS Konsol di bawah> Auto Scaling EC2> Auto Scaling Groups.
-
Pilih grup penskalaan otomatis gateway yang sesuai dengan lingkungan RES. Namanya mengikuti konvensi penamaan
<env-name>-vdc-gateway-asg -
Temukan dan buka Template Peluncuran di bagian detail.
-
Di bawah Detail > Tindakan > pilih Ubah template (Buat versi baru).
-
Gulir ke bawah ke detail lanjutan.
-
Gulir ke bagian paling bawah, ke data Pengguna.
-
Carilah
PRIVATE_KEY_SECRET_ARNkata-katanyaCERTIFICATE_SECRET_ARNdan Perbarui nilai-nilai ini dengan ARNs diberikan ke rahasia yang menyimpan konten Sertifikat (lihat langkah 2.c) dan Kunci Pribadi (lihat langkah 2.d). -
Pastikan grup Auto Scaling dikonfigurasi untuk menggunakan versi template peluncuran yang baru dibuat (dari halaman grup Auto Scaling).
-
-
Perbarui catatan subdomain Route53 yang sesuai yang Anda buat untuk desktop virtual Anda untuk menunjuk ke nama DNS penyeimbang beban nlb eksternal:.
<env-name>-external-nlb -
Hentikan instance dcv-gateway yang ada:
<env-name>-vdc-gateway
........................
AWS CloudFormation tumpukan gagal dibuat dengan pesan "WaitCondition menerima pesan gagal. Kesalahan:Negara. TaskFailed”
Untuk mengidentifikasi masalah, periksa grup CloudWatch log Amazon bernama<stack-name>-InstallerTasksCreateTaskDefCreateContainerLogGroup<nonce>-<nonce>. Jika ada beberapa grup log dengan nama yang sama, periksa yang pertama tersedia. Pesan kesalahan dalam log akan memberikan informasi lebih lanjut tentang masalah ini.
catatan
Konfirmasikan bahwa nilai parameter tidak memiliki spasi.
........................
Pemberitahuan email tidak diterima setelah AWS CloudFormation tumpukan berhasil dibuat
Jika undangan email tidak diterima setelah AWS CloudFormation tumpukan berhasil dibuat, verifikasi hal berikut:
-
Konfirmasikan parameter alamat email dimasukkan dengan benar.
Jika alamat email salah atau tidak dapat diakses, hapus dan gunakan kembali lingkungan Studio Riset dan Teknik.
-
Periksa EC2 konsol Amazon untuk bukti kejadian bersepeda.
Jika ada EC2 instance Amazon dengan
<envname>awalan yang muncul sebagai dihentikan dan kemudian diganti dengan instance baru, mungkin ada masalah dengan konfigurasi jaringan atau Direktori Aktif. -
Jika Anda menerapkan resep Komputasi Kinerja AWS Tinggi untuk membuat sumber daya eksternal, konfirmasikan bahwa VPC, subnet pribadi dan publik, dan parameter lain yang dipilih dibuat oleh tumpukan.
Jika salah satu parameter salah, Anda mungkin perlu menghapus dan menerapkan kembali lingkungan RES. Untuk informasi selengkapnya, lihat Copot pemasangan produk.
-
Jika Anda menerapkan produk dengan sumber daya eksternal Anda sendiri, konfirmasikan jaringan dan Active Directory cocok dengan konfigurasi yang diharapkan.
Mengonfirmasi bahwa instans infrastruktur berhasil bergabung dengan Active Directory sangat penting. Coba langkah-langkahnya Instance bersepeda atau vdc-controller dalam keadaan gagal untuk menyelesaikan masalah.
........................
Instance bersepeda atau vdc-controller dalam keadaan gagal
Penyebab paling mungkin dari masalah ini adalah ketidakmampuan sumber daya untuk menghubungkan atau bergabung dengan Active Directory.
Untuk memverifikasi masalah:
-
Dari baris perintah, mulailah sesi dengan SSM pada instance yang sedang berjalan dari vdc-controller.
-
Jalankan
sudo su -. -
Jalankan
systemctl status sssd.
Jika status tidak aktif, gagal, atau Anda melihat kesalahan di log, maka instance tidak dapat bergabung dengan Active Directory.
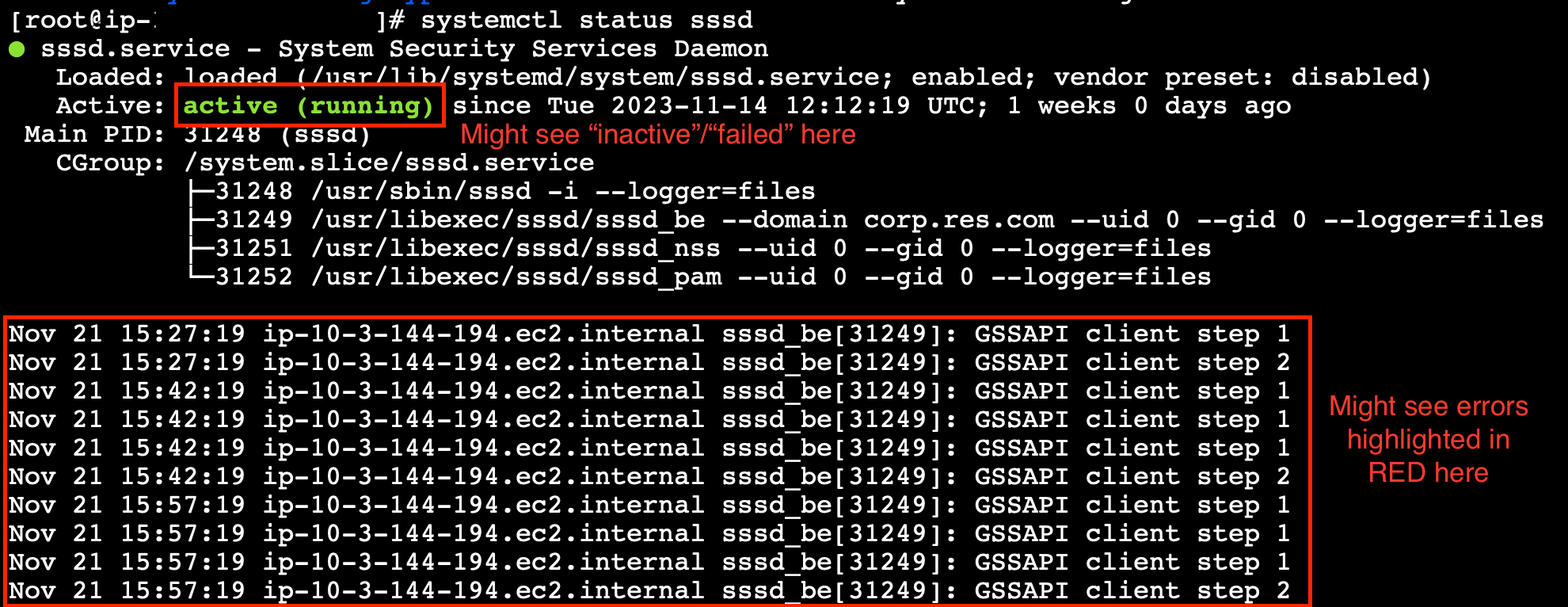
Log kesalahan SSM
Untuk mengatasi masalah ini:
-
Dari instance baris perintah yang sama, jalankan
cat /root/bootstrap/logs/userdata.loguntuk menyelidiki log.
Masalah ini bisa memiliki salah satu dari tiga kemungkinan akar penyebab.
Tinjau log. Jika Anda melihat hal berikut diulang beberapa kali, instance tidak dapat bergabung dengan Active Directory.
+ local AD_AUTHORIZATION_ENTRY= + [[ -z '' ]] + [[ 0 -le 180 ]] + local SLEEP_TIME=34 + log_info '(0 of 180) waiting for AD authorization, retrying in 34 seconds ...' ++ date '+%Y-%m-%d %H:%M:%S,%3N' + echo '[2024-01-16 22:02:19,802] [INFO] (0 of 180) waiting for AD authorization, retrying in 34 seconds ...' [2024-01-16 22:02:19,802] [INFO] (0 of 180) waiting for AD authorization, retrying in 34 seconds ... + sleep 34 + (( ATTEMPT_COUNT++ ))
-
Verifikasi nilai parameter untuk yang berikut dimasukkan dengan benar selama pembuatan tumpukan RES.
-
directoryservice.ldap_connection_uri
-
directoryservice.ldap_base
-
directoryservice.users.ou
-
directoryservice.groups.ou
-
directoryservice.sudoers.ou
-
directoryservice.computers.ou
-
directoryservice.name
-
-
Perbarui nilai yang salah dalam tabel DynamoDB. Tabel ditemukan di konsol DynamoDB di bawah Tabel. Nama tabel seharusnya
<stack name>.cluster-settings -
Setelah Anda memperbarui tabel, hapus cluster-manager dan vdc-controller yang saat ini menjalankan instance lingkungan. Penskalaan otomatis akan memulai instance baru menggunakan nilai terbaru dari tabel DynamoDB.
Jika log kembaliInsufficient permissions to modify computer account, ServiceAccount nama yang dimasukkan selama pembuatan tumpukan bisa salah.
-
Dari AWS Konsol, buka Secrets Manager.
-
Cari
directoryserviceServiceAccountUsername. Rahasianya seharusnya<stack name>-directoryservice-ServiceAccountUsername -
Buka rahasia untuk melihat halaman detail. Di bawah Nilai Rahasia, pilih Ambil nilai rahasia dan pilih Plaintext.
-
Jika nilai diperbarui, hapus instance cluster-manager dan vdc-controller lingkungan yang sedang berjalan. Penskalaan otomatis akan memulai instance baru menggunakan nilai terbaru dari Secrets Manager.
Jika log ditampilkanInvalid credentials, ServiceAccount kata sandi yang dimasukkan selama pembuatan tumpukan mungkin salah.
-
Dari AWS Konsol, buka Secrets Manager.
-
Cari
directoryserviceServiceAccountPassword. Rahasianya seharusnya<stack name>-directoryservice-ServiceAccountPassword -
Buka rahasia untuk melihat halaman detail. Di bawah Nilai Rahasia, pilih Ambil nilai rahasia dan pilih Plaintext.
-
Jika Anda lupa kata sandi atau Anda tidak yakin apakah kata sandi yang dimasukkan benar, Anda dapat mengatur ulang kata sandi di Active Directory dan Secrets Manager.
-
Untuk mengatur ulang kata sandi di AWS Managed Microsoft AD:
-
Buka AWS konsol dan pergi ke AWS Directory Service.
-
Pilih ID Direktori untuk direktori RES Anda, dan pilih Tindakan.
-
Pilih Setel ulang kata sandi pengguna.
-
Masukkan nama ServiceAccount pengguna.
-
Masukkan kata sandi baru, dan pilih Atur ulang kata sandi.
-
-
Untuk mengatur ulang kata sandi di Secrets Manager:
-
Buka AWS konsol dan pergi ke Secrets Manager.
-
Cari
directoryserviceServiceAccountPassword. Rahasianya seharusnya<stack name>-directoryservice-ServiceAccountPassword -
Buka rahasia untuk melihat halaman detail. Di bawah Nilai Rahasia, pilih Ambil nilai rahasia lalu pilih Plaintext.
-
Pilih Edit.
-
Tetapkan kata sandi baru untuk ServiceAccount pengguna dan pilih Simpan.
-
-
-
Jika Anda memperbarui nilainya, hapus instance cluster-manager dan vdc-controller lingkungan yang sedang berjalan. Penskalaan otomatis akan memulai instance baru menggunakan nilai terbaru.
........................
CloudFormation Tumpukan lingkungan gagal dihapus karena kesalahan objek dependen
Jika penghapusan <env-name>-vdcvdcdcvhostsecuritygroup, ini bisa disebabkan oleh EC2 instance Amazon yang diluncurkan ke subnet atau grup keamanan yang dibuat RES menggunakan Konsol. AWS
Untuk mengatasi masalah ini, temukan dan hentikan semua EC2 instans Amazon yang diluncurkan dengan cara ini. Anda kemudian dapat melanjutkan penghapusan lingkungan.
........................
Kesalahan yang ditemui untuk parameter blok CIDR selama pembuatan lingkungan
Saat membuat lingkungan, kesalahan muncul untuk parameter blok CIDR dengan status respons [GAGAL].
Contoh kesalahan:
Failed to update cluster prefix list: An error occurred (InvalidParameterValue) when calling the ModifyManagedPrefixList operation: The specified CIDR (52.94.133.132/24) is not valid. For example, specify a CIDR in the following form: 10.0.0.0/16.
Untuk mengatasi masalah ini, format yang diharapkan adalah x.x.x.0/24 atau x.x.x.0/32.
........................
CloudFormation kegagalan pembuatan tumpukan selama pembuatan lingkungan
Menciptakan lingkungan melibatkan serangkaian operasi pembuatan sumber daya. Di beberapa Wilayah, masalah kapasitas dapat terjadi yang menyebabkan pembuatan CloudFormation tumpukan gagal.
Jika ini terjadi, hapus lingkungan dan coba lagi pembuatannya. Atau, Anda dapat mencoba lagi pembuatan di Wilayah yang berbeda.
........................
Pembuatan tumpukan sumber daya eksternal (demo) gagal dengan AdDomainAdminNode CREATE_FAILED
Jika pembuatan tumpukan lingkungan demo gagal dengan kesalahan berikut, mungkin karena EC2 tambalan Amazon terjadi secara tak terduga selama penyediaan setelah peluncuran instance.
AdDomainAdminNode CREATE_FAILED Failed to receive 1 resource signal(s) within the specified duration
Untuk menentukan penyebab kegagalan:
-
Di SSM State Manager, periksa apakah patching dikonfigurasi dan apakah itu dikonfigurasi untuk semua instance.
-
Dalam riwayat eksekusi RunCommand SSM/Automation, periksa apakah eksekusi dokumen SSM terkait tambalan bertepatan dengan peluncuran instance.
-
Dalam file log untuk EC2 instans Amazon lingkungan, tinjau logging instans lokal untuk menentukan apakah instance di-boot ulang selama penyediaan.
Jika masalah disebabkan oleh patching, tunda patching untuk instans RES setidaknya 15 menit setelah peluncuran.
........................
Masalah manajemen identitas
Sebagian besar masalah dengan sistem masuk tunggal (SSO) dan manajemen identitas terjadi karena kesalahan konfigurasi. Untuk informasi tentang pengaturan konfigurasi SSO Anda, lihat:
Untuk memecahkan masalah lain yang terkait dengan manajemen identitas, lihat topik pemecahan masalah berikut:
Topik
- Saya tidak berwenang untuk melakukan iam: PassRole
- Saya ingin mengizinkan orang-orang di luar AWS akun saya untuk mengakses Studio Penelitian dan Teknik saya tentang AWS sumber daya
- Saat masuk ke lingkungan, saya segera kembali ke halaman login
- Kesalahan “Pengguna tidak ditemukan” saat mencoba masuk
- Pengguna ditambahkan di Active Directory, tetapi hilang dari RES
- Pengguna tidak tersedia saat membuat sesi
- Batas ukuran melebihi kesalahan dalam log CloudWatch pengelola klaster
........................
Saya tidak berwenang untuk melakukan iam: PassRole
Jika Anda menerima kesalahan bahwa Anda tidak diizinkan untuk melakukan PassRole tindakan iam:, kebijakan Anda harus diperbarui agar Anda dapat meneruskan peran ke RES.
Beberapa AWS layanan memungkinkan Anda untuk meneruskan peran yang ada ke layanan tersebut alih-alih membuat peran layanan baru atau peran terkait layanan. Untuk melakukannya, Anda harus memiliki izin untuk meneruskan peran ke layanan.
Contoh kesalahan berikut terjadi ketika pengguna IAM bernama marymajor mencoba menggunakan konsol untuk melakukan tindakan di RES. Namun, tindakan tersebut memerlukan layanan untuk mendapatkan izin yang diberikan oleh peran layanan. Mary tidak memiliki izin untuk meneruskan peran tersebut pada layanan.
User: arn:aws:iam::123456789012:user/marymajor is not authorized to perform: iam:PassRole
Dalam hal ini, kebijakan Mary harus diperbarui untuk memungkinkannya melakukan iam: PassRole action. Jika Anda memerlukan bantuan, hubungi AWS administrator Anda. Administrator Anda adalah orang yang memberi Anda kredensial masuk.
........................
Saya ingin mengizinkan orang-orang di luar AWS akun saya untuk mengakses Studio Penelitian dan Teknik saya tentang AWS sumber daya
Anda dapat membuat peran yang dapat digunakan pengguna di akun lain atau orang-orang di luar organisasi Anda untuk mengakses sumber daya Anda. Anda dapat menentukan siapa saja yang dipercaya untuk mengambil peran tersebut. Untuk layanan yang mendukung kebijakan berbasis sumber daya atau daftar kontrol akses (ACLs), Anda dapat menggunakan kebijakan tersebut untuk memberi orang akses ke sumber daya Anda.
Untuk mempelajari selengkapnya, periksa referensi berikut:
-
Untuk mempelajari cara menyediakan akses ke sumber daya Anda di seluruh AWS akun yang Anda miliki, lihat Menyediakan akses ke pengguna IAM di AWS akun lain yang Anda miliki di Panduan Pengguna IAM.
-
Untuk mempelajari cara menyediakan akses ke sumber daya Anda ke AWS akun pihak ketiga, lihat Menyediakan akses ke AWS akun yang dimiliki oleh pihak ketiga di Panduan Pengguna IAM.
-
Untuk mempelajari cara menyediakan akses melalui federasi identitas, lihat Menyediakan akses ke pengguna yang diautentikasi secara eksternal (federasi identitas) di Panduan Pengguna IAM.
-
Untuk mempelajari perbedaan antara menggunakan peran dan kebijakan berbasis sumber daya untuk akses lintas akun, lihat Perbedaan peran IAM dari kebijakan berbasis sumber daya di Panduan Pengguna IAM.
........................
Saat masuk ke lingkungan, saya segera kembali ke halaman login
Masalah ini terjadi ketika integrasi SSO Anda salah dikonfigurasi. Untuk menentukan masalah, periksa log instance pengontrol dan tinjau pengaturan konfigurasi untuk kesalahan.
Untuk memeriksa log:
-
Buka konsol CloudWatch
. -
Dari grup Log, temukan grup bernama
/.<environment-name>/cluster-manager -
Buka grup log untuk mencari kesalahan apa pun di aliran log.
Untuk memeriksa pengaturan konfigurasi:
-
Buka konsol DynamoDB
-
Dari Tabel, temukan tabel bernama
<environment-name>.cluster-settings -
Buka tabel dan pilih Jelajahi item tabel.
-
Perluas bagian filter, dan masukkan variabel berikut:
-
Nama atribut - kunci
-
Kondisi - berisi
-
Nilai — sso
-
-
Pilih Jalankan.
-
Dalam string yang dikembalikan, verifikasi bahwa nilai konfigurasi SSO sudah benar. Jika salah, ubah nilai kunci sso_enabled menjadi False.
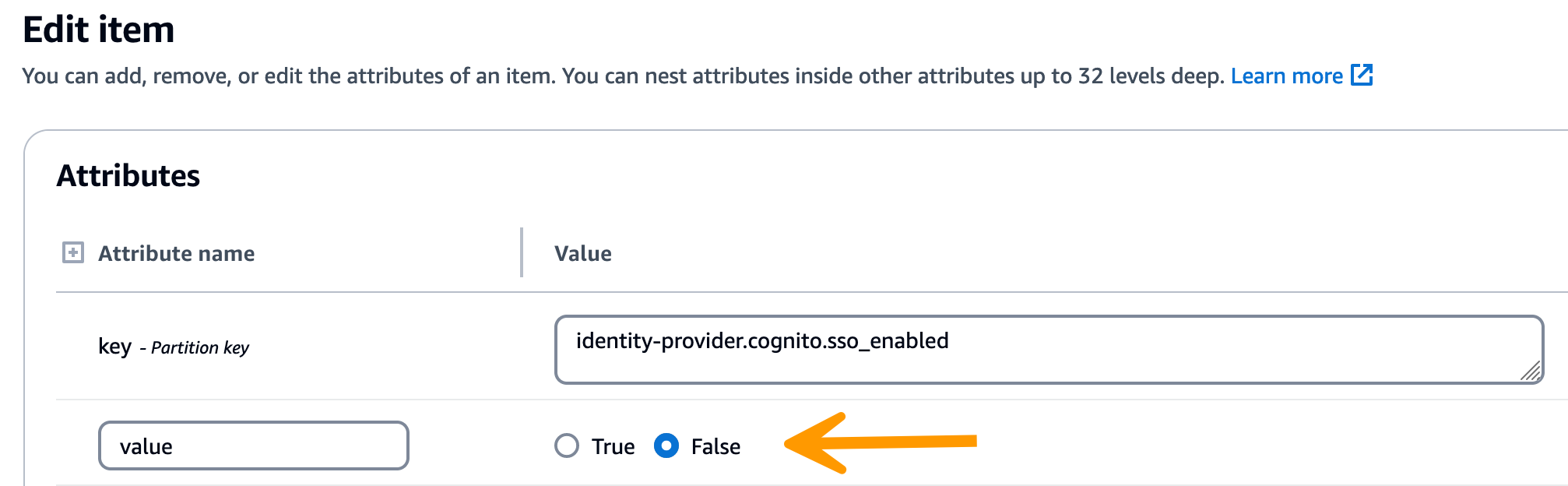
-
Kembali ke antarmuka pengguna RES untuk mengkonfigurasi ulang SSO.
........................
Kesalahan “Pengguna tidak ditemukan” saat mencoba masuk
Jika pengguna menerima kesalahan “Pengguna tidak ditemukan” ketika mereka mencoba masuk ke antarmuka RES, dan pengguna hadir di Active Directory:
-
Jika pengguna tidak hadir di RES dan Anda baru saja menambahkan pengguna ke AD
-
Ada kemungkinan bahwa pengguna belum disinkronkan ke RES. RES disinkronkan setiap jam, jadi Anda mungkin perlu menunggu dan memeriksa apakah pengguna ditambahkan setelah sinkronisasi berikutnya. Untuk segera menyinkronkan, ikuti langkah-langkahnyaPengguna ditambahkan di Active Directory, tetapi hilang dari RES.
-
-
Jika pengguna hadir di RES:
-
Pastikan pemetaan atribut dikonfigurasi dengan benar. Untuk informasi selengkapnya, lihat Mengonfigurasi penyedia identitas Anda untuk single sign-on () SSO.
-
Pastikan bahwa subjek SAMP dan email SAMP keduanya dipetakan ke alamat email pengguna.
-
........................
Pengguna ditambahkan di Active Directory, tetapi hilang dari RES
catatan
Bagian ini berlaku untuk RES 2024.10 dan sebelumnya. Untuk RES 2024.12 dan yang lebih baru lihat. Cara menjalankan sinkronisasi secara manual (rilis 2024.12 dan yang lebih baru)
Jika Anda telah menambahkan pengguna ke Active Directory tetapi tidak ada di RES, sinkronisasi AD perlu dipicu. Sinkronisasi AD dilakukan setiap jam oleh fungsi Lambda yang mengimpor entri AD ke lingkungan RES. Terkadang, ada penundaan hingga proses sinkronisasi berikutnya berjalan setelah Anda menambahkan pengguna atau grup baru. Anda dapat memulai sinkronisasi secara manual dari Amazon Simple Queue Service.
Memulai proses sinkronisasi secara manual:
-
Buka konsol Amazon SQS
. -
Dari Antrian, pilih.
<environment-name>-cluster-manager-tasks.fifo -
Pilih Kirim dan terima pesan.
-
Untuk isi Pesan, masukkan:
{ "name": "adsync.sync-from-ad", "payload": {} } -
Untuk ID grup Pesan, masukkan:
adsync.sync-from-ad -
Untuk ID deduplikasi Pesan, masukkan string alfa-numerik acak. Entri ini harus berbeda dari semua panggilan yang dilakukan dalam lima menit sebelumnya atau permintaan akan diabaikan.
........................
Pengguna tidak tersedia saat membuat sesi
Jika Anda seorang administrator yang membuat sesi, tetapi menemukan bahwa pengguna yang berada di Direktori Aktif tidak tersedia saat membuat sesi, pengguna mungkin perlu masuk untuk pertama kalinya. Sesi hanya dapat dibuat untuk pengguna aktif. Pengguna aktif harus masuk ke lingkungan setidaknya sekali.
........................
Batas ukuran melebihi kesalahan dalam log CloudWatch pengelola klaster
2023-10-31T18:03:12.942-07:00 ldap.SIZELIMIT_EXCEEDED: {'msgtype': 100, 'msgid': 11, 'result': 4, 'desc': 'Size limit exceeded', 'ctrls': []}
Jika Anda menerima kesalahan ini di log CloudWatch pengelola klaster, pencarian ldap mungkin telah mengembalikan terlalu banyak catatan pengguna. Untuk memperbaiki masalah ini, tingkatkan batas hasil pencarian ldap IDP Anda.
........................
Penyimpanan
Topik
........................
Saya membuat sistem file melalui RES tetapi tidak dipasang di host VDI
Sistem file harus dalam keadaan “Tersedia” sebelum dapat dipasang oleh host VDI. Ikuti langkah-langkah di bawah ini untuk memvalidasi sistem file dalam keadaan wajib.
Amazon EFS
-
Buka konsol Amazon EFS
. -
Periksa apakah status sistem File Tersedia.
-
Jika status sistem file tidak Tersedia, tunggu sebelum meluncurkan host VDI.
Amazon FSx ONTAP
-
Pergi ke FSx konsol Amazon
. -
Periksa apakah statusnya tersedia.
-
Jika Status tidak Tersedia, tunggu sebelum meluncurkan host VDI.
........................
Saya memasukkan sistem file melalui RES tetapi tidak dipasang di host VDI
Sistem file yang terpasang pada RES harus memiliki aturan grup keamanan yang diperlukan yang dikonfigurasi untuk memungkinkan host VDI memasang sistem file. Karena sistem file ini dibuat secara eksternal ke RES, RES tidak mengelola aturan grup keamanan terkait.
Grup keamanan yang terkait dengan sistem file onboard harus mengizinkan lalu lintas masuk berikut:
Lalu lintas NFS (port: 2049) dari host VDC linux
Lalu lintas SMB (port: 445) dari host windows VDC
........................
Saya tidak dapat membaca/menulis dari host VDI
ONTAP mendukung UNIX, NTFS dan gaya keamanan MIXED untuk volume. Gaya keamanan menentukan jenis izin yang digunakan ONTAP untuk mengontrol akses data dan jenis klien apa yang dapat memodifikasi izin ini.
Misalnya, jika volume menggunakan gaya keamanan UNIX, klien SMB masih dapat mengakses data (asalkan mereka benar mengautentikasi dan mengotorisasi) karena sifat multi-protokol ONTAP. Namun, ONTAP menggunakan izin UNIX yang hanya dapat dimodifikasi oleh klien UNIX menggunakan alat asli.
Contoh izin menangani kasus penggunaan
Menggunakan volume gaya UNIX dengan beban kerja Linux
Izin dapat dikonfigurasi oleh sudoer untuk pengguna lain. Misalnya, berikut ini akan memberikan semua anggota izin baca/tulis <group-ID> penuh pada direktori: /<project-name>
sudo chown root:<group-ID>/<project-name>sudo chmod 770 /<project-name>
Menggunakan volume gaya NTFS dengan beban kerja Linux dan Windows
Izin Berbagi dapat dikonfigurasi menggunakan properti berbagi folder tertentu. Misalnya, diberikan pengguna user_01 dan foldermyfolder, Anda dapat mengatur izinFull Control,Change, atau Read ke Allow atauDeny:
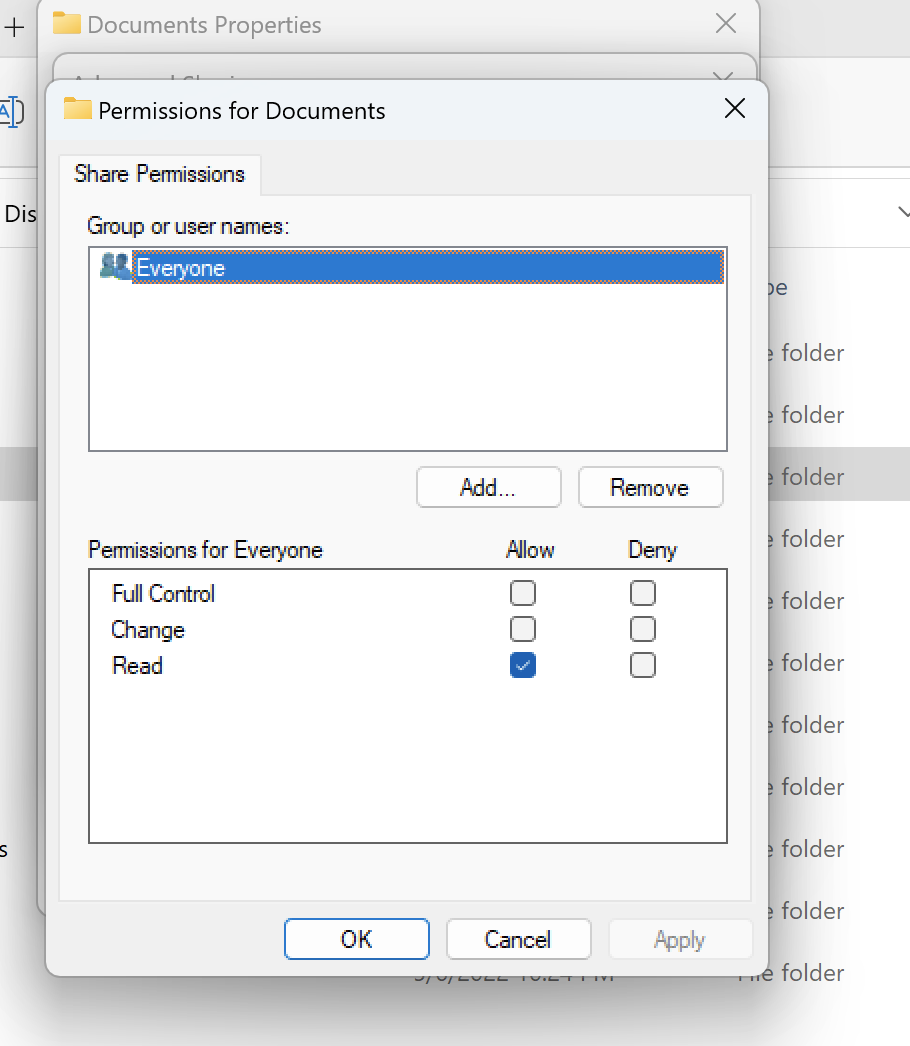
Jika volume akan digunakan oleh klien Linux dan Windows, kita perlu mengatur pemetaan nama pada SVM yang akan mengaitkan nama pengguna Linux apa pun ke nama pengguna yang sama dengan format nama domain NetBIOS dari domain\ username. Ini diperlukan untuk menerjemahkan antara pengguna Linux dan Windows. Untuk referensi, lihat Mengaktifkan beban kerja multiprotokol dengan Amazon FSx
........................
Saya membuat Amazon FSx untuk NetApp ONTAP dari RES tetapi tidak bergabung dengan domain saya
Saat ini, saat Anda membuat Amazon FSx untuk NetApp ONTAP dari konsol RES, sistem file akan disediakan tetapi tidak bergabung dengan domain. Untuk menggabungkan SVM sistem file ONTAP yang dibuat ke domain Anda, lihat Bergabung SVMs ke Microsoft Active Directory dan ikuti langkah-langkah di konsol Amazon FSx
Setelah bergabung ke domain, edit kunci konfigurasi SMB DNS di tabel DynamoDB pengaturan cluster:
-
Buka konsol Amazon DynamoDB
. -
Pilih Tabel, lalu pilih
<stack-name>-cluster-settings. -
Di bawah Jelajahi item tabel, perluas Filter, dan masukkan filter berikut:
Nama atribut - kunci
Kondisi - Sama dengan
-
Nilai -
shared-storage.<file-system-name>.fsx_netapp_ontap.svm.smb_dns
-
Pilih item yang dikembalikan, lalu Tindakan, Edit item.
-
Perbarui nilai dengan nama DNS SMB yang Anda salin sebelumnya.
-
Pilih Save and close (Simpan dan pilih).
Selain itu, pastikan grup keamanan yang terkait dengan sistem file memungkinkan lalu lintas seperti yang direkomendasikan dalam Kontrol Akses Sistem File dengan Amazon VPC. Host VDI baru yang menggunakan sistem file sekarang akan dapat me-mount domain yang bergabung dengan SVM dan sistem file.
Atau, Anda dapat menggunakan sistem file yang sudah ada yang sudah bergabung ke domain Anda menggunakan kemampuan Sistem File Onboard RES- dari Manajemen Lingkungan pilih Sistem File, Sistem File Onboard.
........................
Snapshot
Topik
........................
Snapshot memiliki status Gagal
Pada halaman RES Snapshots, jika snapshot memiliki status Gagal, penyebabnya dapat ditentukan dengan membuka grup CloudWatch log Amazon untuk pengelola klaster selama kesalahan terjadi.
[2023-11-19 03:39:20,208] [INFO] [snapshots-service] creating snapshot in S3 Bucket: asdf at path s31 [2023-11-19 03:39:20,381] [ERROR] [snapshots-service] An error occurred while creating the snapshot: An error occurred (TableNotFoundException) when calling the UpdateContinuousBackups operation: Table not found: res-demo.accounts.sequence-config
........................
Snapshot gagal diterapkan dengan log yang menunjukkan bahwa tabel tidak dapat diimpor.
Jika snapshot yang diambil dari env sebelumnya gagal diterapkan di env baru, lihat CloudWatch log untuk pengelola klaster untuk mengidentifikasi masalah. Jika masalah menyebutkan bahwa cloud tabel yang diperlukan tidak diimpor, verifikasi bahwa snapshot dalam status valid.
-
Unduh file metadata.json dan verifikasi bahwa ExportStatus untuk berbagai tabel memiliki status SELESAI. Pastikan berbagai tabel memiliki
ExportManifestbidang yang ditetapkan. Jika Anda tidak menemukan set bidang di atas, snapshot dalam keadaan tidak valid dan tidak dapat digunakan dengan fungsionalitas snapshot terapkan. -
Setelah memulai pembuatan snapshot, pastikan status Snapshot berubah menjadi SELESAI di RES. Proses pembuatan Snapshot memakan waktu hingga 5 hingga 10 menit. Muat ulang atau kunjungi kembali halaman Manajemen Snapshot untuk memastikan Snapshot berhasil dibuat. Ini akan memastikan bahwa snapshot yang dibuat dalam keadaan valid.
........................
Infrastruktur
........................
Kelompok sasaran penyeimbang beban tanpa instance yang sehat
Jika masalah seperti pesan kesalahan server muncul di UI atau sesi desktop tidak dapat terhubung, itu mungkin menunjukkan masalah dalam infrastruktur EC2 instans Amazon.
Metode untuk menentukan sumber masalah adalah dengan terlebih dahulu memeriksa EC2 konsol Amazon untuk setiap EC2 instance Amazon yang tampaknya berulang kali dihentikan dan digantikan oleh instance baru. Jika itu masalahnya, memeriksa CloudWatch log Amazon dapat menentukan penyebabnya.
Metode lain adalah memeriksa penyeimbang beban dalam sistem. Indikasi bahwa mungkin ada masalah sistem adalah jika ada penyeimbang beban, yang ditemukan di EC2 konsol Amazon, tidak menunjukkan instans sehat yang terdaftar.
Contoh penampilan normal ditunjukkan di sini:
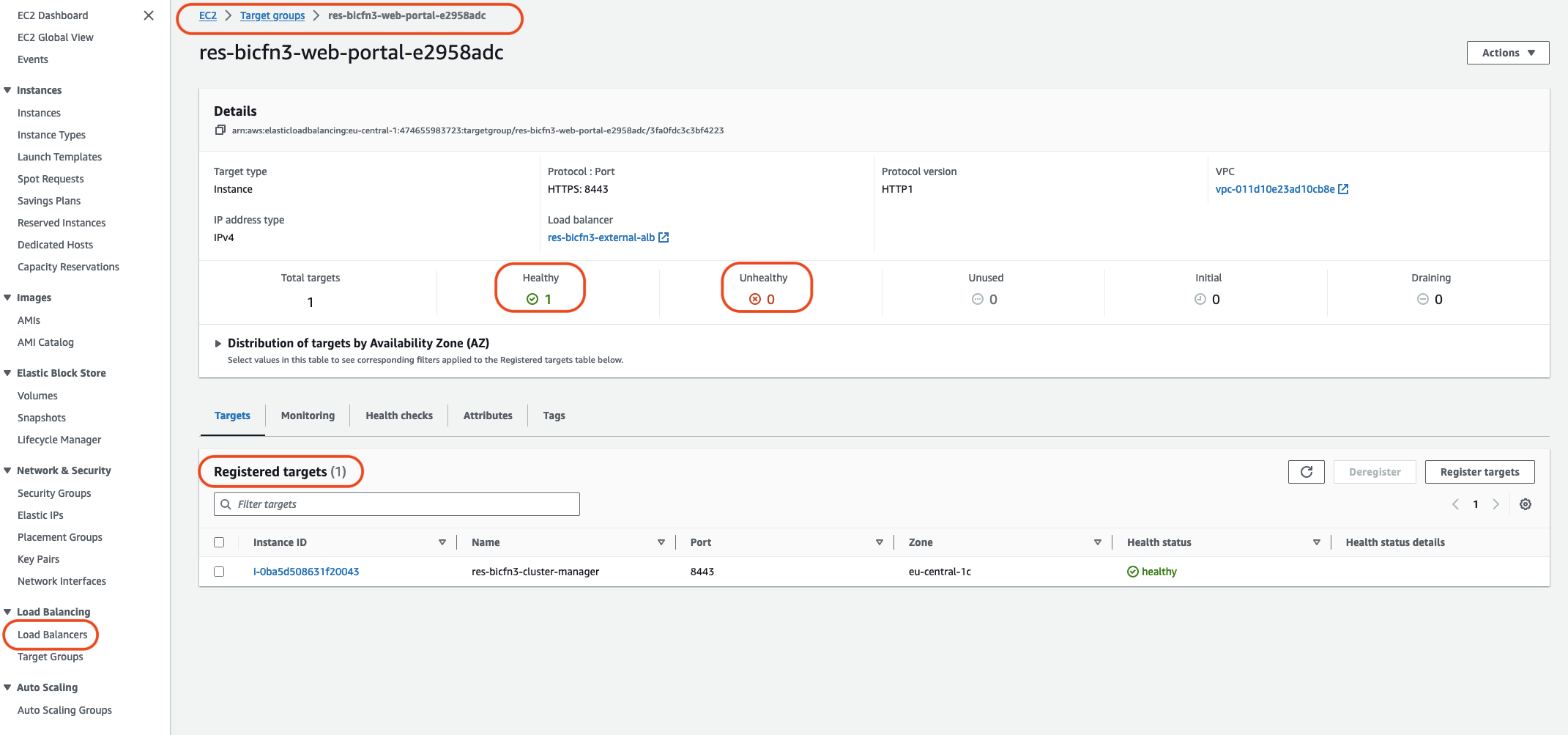
Jika entri Sehat adalah 0, itu menunjukkan bahwa tidak ada EC2 instans Amazon yang tersedia untuk memproses permintaan.
Jika entri Tidak Sehat adalah non-0, itu menunjukkan bahwa EC2 instance Amazon mungkin bersepeda. Ini bisa disebabkan oleh perangkat lunak aplikasi yang diinstal tidak lulus pemeriksaan kesehatan.
Jika entri Sehat dan Tidak Sehat adalah 0, itu menunjukkan potensi kesalahan konfigurasi jaringan. Misalnya, subnet publik dan swasta mungkin tidak sesuai AZs. Jika kondisi ini terjadi, mungkin ada teks tambahan pada konsol yang menunjukkan bahwa status jaringan ada.
........................
Meluncurkan Desktop Virtual
Topik
- Sertifikat kedaluwarsa saat menggunakan sumber daya eksternal CertificateRenewalNode
- Desktop virtual yang sebelumnya berfungsi tidak lagi dapat terhubung dengan sukses
- Saya hanya dapat meluncurkan 5 desktop virtual
- Upaya koneksi Windows Desktop gagal dengan “Koneksi telah ditutup. Kesalahan transportasi”
- VDIs terjebak dalam status Penyediaan
- VDIs masuk ke status Kesalahan setelah diluncurkan
........................
Sertifikat kedaluwarsa saat menggunakan sumber daya eksternal CertificateRenewalNode
Jika Anda menerapkan resep Sumber Daya Eksternal dan menemukan kesalahan yang menyatakan "The connection has been closed. Transport error" saat Anda terhubung ke Linux VDIs, penyebab yang paling mungkin adalah sertifikat kedaluwarsa yang tidak disegarkan secara otomatis karena jalur instalasi pip yang salah di Linux. Sertifikat kedaluwarsa setelah 3 bulan.
Grup CloudWatch log Amazon <envname>/vdc/dcv-connection-gateway
| 2024-07-29T21:46:02.651Z | Jul 29 21:46:01.702 WARN HTTP:Splicer Connection{id=341 client_address="x.x.x.x:50682"}: Error in connection task: TLS handshake error: received fatal alert: CertificateUnknown | redacted:/res-demo/vdc/dcv-connection-gateway | dcv-connection-gateway_10.3.146.195 | | 2024-07-29T21:46:02.651Z | Jul 29 21:46:01.702 WARN HTTP:Splicer Connection{id=341 client_address="x.x.x.x:50682"}: Certificate error: AlertReceived(CertificateUnknown) | redacted:/res-demo/vdc/dcv-connection-gateway | dcv-connection-gateway_10.3.146.195 |
Untuk mengatasi masalah ini:
-
Di AWS akun Anda, buka EC2
. Jika ada instance bernama *-CertificateRenewalNode-*, hentikan instance. -
Pergi ke Lambda
. Anda akan melihat fungsi Lambda bernama *-CertificateRenewalLambda-*, periksa kode Lambda untuk sesuatu yang mirip dengan berikut ini:export HOME=/tmp/home mkdir -p $HOME cd /tmp wget https://bootstrap.pypa.io/pip/3.7/get-pip.py python3 ./get-pip.py pip3 install boto3 eval $(python3 -c "from botocore.credentials import InstanceMetadataProvider, InstanceMetadataFetcher; provider = InstanceMetadataProvider(iam_role_fetcher=InstanceMetadataFetcher(timeout=1000, num_attempts=2)); c = provider.load().get_frozen_credentials(); print(f'export AWS_ACCESS_KEY_ID={c.access_key}'); print(f'export AWS_SECRET_ACCESS_KEY={c.secret_key}'); print(f'export AWS_SESSION_TOKEN={c.token}')") mkdir certificates cd certificates git clone https://github.com/Neilpang/acme.sh.git cd acme.sh -
Temukan template tumpukan Certs sumber daya eksternal terbaru di sini
. Temukan kode Lambda di template: Resources → → Properties CertificateRenewalLambda→ Code. Anda mungkin menemukan sesuatu yang mirip dengan berikut ini: sudo yum install -y wget export HOME=/tmp/home mkdir -p $HOME cd /tmp wget https://bootstrap.pypa.io/pip/3.7/get-pip.py mkdir -p pip python3 ./get-pip.py --target $PWD/pip $PWD/pip/bin/pip3 install boto3 eval $(python3 -c "from botocore.credentials import InstanceMetadataProvider, InstanceMetadataFetcher; provider = InstanceMetadataProvider(iam_role_fetcher=InstanceMetadataFetcher(timeout=1000, num_attempts=2)); c = provider.load().get_frozen_credentials(); print(f'export AWS_ACCESS_KEY_ID={c.access_key}'); print(f'export AWS_SECRET_ACCESS_KEY={c.secret_key}'); print(f'export AWS_SESSION_TOKEN={c.token}')") mkdir certificates cd certificates VERSION=3.1.0 wget https://github.com/acmesh-official/acme.sh/archive/refs/tags/$VERSION.tar.gz -O acme-$VERSION.tar.gz tar -xvf acme-$VERSION.tar.gz cd acme.sh-$VERSION -
Ganti bagian dari Langkah 2 dalam fungsi
*-CertificateRenewalLambda-*Lambda dengan kode dari Langkah 3. Pilih Deploy dan tunggu perubahan kode diterapkan. -
Untuk memicu fungsi Lambda secara manual, buka tab Uji dan kemudian pilih Uji. Tidak diperlukan input tambahan. Ini harus membuat EC2 instance sertifikat yang memperbarui Sertifikat dan PrivateKey rahasia di Secret Manager.
-
Hentikan instance dcv-gateway yang ada:
<env-name>-vdc-gateway
........................
Desktop virtual yang sebelumnya berfungsi tidak lagi dapat terhubung dengan sukses
Jika koneksi desktop ditutup atau Anda tidak dapat lagi terhubung dengannya, masalahnya mungkin disebabkan oleh kegagalan EC2 instans Amazon yang mendasarinya atau EC2 instans Amazon mungkin telah dihentikan atau dihentikan di luar lingkungan RES. Status UI Admin dapat terus menampilkan status siap tetapi upaya untuk menghubungkannya gagal.
EC2 Konsol Amazon harus digunakan untuk menentukan apakah instance telah dihentikan atau dihentikan. Jika berhenti, coba mulai lagi. Jika status dihentikan, desktop lain harus dibuat. Setiap data yang disimpan di direktori home pengguna harus tetap tersedia saat instance baru dimulai.
Jika instance yang gagal sebelumnya masih muncul di UI Admin, instance tersebut mungkin perlu dihentikan menggunakan UI Admin.
........................
Saya hanya dapat meluncurkan 5 desktop virtual
Batas default untuk jumlah desktop virtual yang dapat diluncurkan pengguna adalah 5. Ini dapat diubah oleh admin menggunakan UI Admin sebagai berikut:
Buka Pengaturan Desktop.
Pilih tab Server.
Di panel Sesi DCV, klik ikon edit di sebelah kanan.
Ubah nilai dalam Sesi yang Diizinkan Per Pengguna ke nilai baru yang diinginkan.
Pilih Kirim.
Segarkan halaman untuk mengonfirmasi bahwa pengaturan baru sudah ada.
........................
Upaya koneksi Windows Desktop gagal dengan “Koneksi telah ditutup. Kesalahan transportasi”
Jika koneksi desktop Windows gagal dengan kesalahan UI “Sambungan telah ditutup. Kesalahan transportasi”, penyebabnya dapat disebabkan oleh masalah dalam perangkat lunak server DCV yang terkait dengan pembuatan sertifikat pada instance Windows.
Grup CloudWatch log Amazon <envname>/vdc/dcv-connection-gateway dapat mencatat kesalahan upaya koneksi dengan pesan yang mirip dengan berikut ini:
Nov 24 20:24:27.631 DEBUG HTTP:Splicer Connection{id=9}: Websocket{session_id="1291e75f-7816-48d9-bbb2-7371b3b911cd"}: Resolver lookup{client_ip=Some(52.94.36.19) session_id="1291e75f-7816-48d9-bbb2-7371b3b911cd" protocol_type=WebSocket extension_data=None}:NoStrictCertVerification: Additional stack certificate (0): [s/n: 0E9E9C4DE7194B37687DC4D2C0F5E94AF0DD57E] Nov 24 20:25:15.384 INFO HTTP:Splicer Connection{id=21}:Websocket{ session_id="d1d35954-f29d-4b3f-8c23-6a53303ebc3f"}: Connection initiated error: unreachable, server io error Custom { kind: InvalidData, error: General("Invalid certificate: certificate has expired (code: 10)") } Nov 24 20:25:15.384 WARN HTTP:Splicer Connection{id=21}: Websocket{session_id="d1d35954-f29d-4b3f-8c23-6a53303ebc3f"}: Error in websocket connection: Server unreachable: Server error: IO error: unexpected error: Invalid certificate: certificate has expired (code: 10)
Jika ini terjadi, resolusi mungkin menggunakan SSM Session Manager untuk membuka koneksi ke instance Windows dan menghapus 2 file terkait sertifikat berikut:
PS C:\Windows\system32\config\systemprofile\AppData\Local\NICE\dcv> dir Directory: C:\Windows\system32\config\systemprofile\AppData\Local\NICE\dcv Mode LastWriteTime Length Name ---- ------------- ------ ---- -a---- 8/4/2022 12:59 PM 1704 dcv.key -a---- 8/4/2022 12:59 PM 1265 dcv.pem
File harus dibuat ulang secara otomatis dan upaya koneksi berikutnya mungkin berhasil.
Jika metode ini menyelesaikan masalah dan jika peluncuran baru desktop Windows menghasilkan kesalahan yang sama, gunakan fungsi Create Software Stack untuk membuat tumpukan perangkat lunak Windows baru dari instance tetap dengan file sertifikat yang dibuat ulang. Itu dapat menghasilkan tumpukan perangkat lunak Windows yang dapat digunakan untuk peluncuran dan koneksi yang sukses.
........................
VDIs terjebak dalam status Penyediaan
Jika peluncuran desktop tetap dalam status penyediaan di UI Admin, ini mungkin karena beberapa alasan.
Untuk menentukan penyebabnya, periksa file log pada instance desktop dan cari kesalahan yang mungkin menyebabkan masalah. Dokumen ini berisi daftar file log dan grup CloudWatch log Amazon yang berisi informasi yang relevan di bagian berlabel sumber informasi log dan peristiwa yang berguna.
Berikut ini adalah penyebab potensial dari masalah ini.
-
Id AMI yang digunakan telah terdaftar sebagai tumpukan perangkat lunak tetapi tidak didukung oleh RES.
Skrip penyediaan bootstrap gagal diselesaikan karena Amazon Machine Image (AMI) tidak memiliki konfigurasi atau perkakas yang diharapkan yang diperlukan. File log pada instance, seperti
/root/bootstrap/logs/pada instance Linux, mungkin berisi informasi yang berguna mengenai hal ini. AMIs id yang diambil dari AWS Marketplace mungkin tidak berfungsi untuk instans desktop RES. Mereka memerlukan pengujian untuk mengkonfirmasi apakah mereka didukung. -
Skrip data pengguna tidak dijalankan ketika instance desktop virtual Windows diluncurkan dari AMI kustom.
Secara default, skrip data pengguna berjalan satu kali ketika EC2 instans Amazon diluncurkan. Jika Anda membuat AMI dari instance desktop virtual yang ada, maka daftarkan tumpukan perangkat lunak dengan AMI dan coba luncurkan desktop virtual lain dengan tumpukan perangkat lunak ini, skrip data pengguna tidak akan berjalan pada instance desktop virtual baru.
Untuk memperbaiki masalah, buka jendela PowerShell perintah sebagai Administrator pada instance desktop virtual asli yang Anda gunakan untuk membuat AMI, dan jalankan perintah berikut:
C:\ProgramData\Amazon\EC2-Windows\Launch\Scripts\InitializeInstance.ps1 –ScheduleKemudian buat AMI baru dari instance. Anda dapat menggunakan AMI baru untuk mendaftarkan tumpukan perangkat lunak dan meluncurkan desktop virtual baru setelahnya. Perhatikan bahwa Anda juga dapat menjalankan perintah yang sama pada instance yang tetap dalam status penyediaan dan me-reboot instance untuk memperbaiki sesi desktop virtual, tetapi Anda akan mengalami masalah yang sama lagi saat meluncurkan desktop virtual lain dari AMI yang salah konfigurasi.
........................
VDIs masuk ke status Kesalahan setelah diluncurkan
- Kemungkinan masalah 1: Sistem file beranda memiliki direktori untuk pengguna dengan izin POSIX yang berbeda.
-
Ini bisa menjadi masalah yang Anda hadapi jika skenario berikut benar:
-
Versi RES yang digunakan adalah 2024.01 atau lebih tinggi.
-
Selama penerapan tumpukan RES, atribut untuk
EnableLdapIDMappingdisetel keTrue. -
Sistem file beranda yang ditentukan selama penerapan tumpukan RES digunakan dalam versi sebelum RES 2024.01 atau digunakan di lingkungan sebelumnya dengan disetel ke.
EnableLdapIDMappingFalse
Langkah resolusi: Hapus direktori pengguna di sistem file.
-
SSM ke host pengelola klaster.
-
cd /home. -
ls- harus mencantumkan direktori dengan nama direktori yang cocok dengan nama pengguna, sepertiadmin1,admin2.. dan sebagainya. -
Hapus direktori,
sudo rm -r 'dir_name'. Jangan hapus direktori ssm-user dan ec2-user. -
Jika pengguna sudah disinkronkan ke env baru, hapus pengguna dari tabel DDB pengguna (kecuali clusteradmin).
-
Memulai sinkronisasi AD - jalankan
sudo /opt/idea/python/3.9.16/bin/resctl ldap sync-from-addi pengelola klaster Amazon. EC2 -
Reboot instance VDI di
Errornegara bagian dari halaman web RES. Validasi bahwa transisi VDI keReadystatus dalam waktu sekitar 20 menit.
-
........................
Komponen Desktop Virtual
Topik
- EC2 Instans Amazon berulang kali ditampilkan dihentikan di konsol
- instance vdc-controller sedang bersepeda karena gagal bergabung dengan modul AD/eVDi menunjukkan Pemeriksaan Kesehatan API Gagal
- Proyek tidak muncul di pull down saat mengedit Software Stack untuk menambahkannya
- pengelola klaster Log CloudWatch Amazon menunjukkan “user-home-init< > akun belum tersedia. menunggu pengguna untuk disinkronkan” (di mana akun adalah nama pengguna)
- Desktop Windows pada upaya login mengatakan “Akun Anda telah dinonaktifkan. Silakan lihat administrator Anda”
- Masalah Opsi DHCP dengan konfigurasi AD eksternal/pelanggan
- Kesalahan Firefox MOZILLA_PKIX_ERROR_REQUIRED_TLS_FEATURE_MISSING
........................
EC2 Instans Amazon berulang kali ditampilkan dihentikan di konsol
Jika instance infrastruktur berulang kali ditampilkan sebagai dihentikan di EC2 konsol Amazon, penyebabnya mungkin terkait dengan konfigurasinya dan bergantung pada jenis instans infrastruktur. Berikut ini adalah metode untuk menentukan penyebabnya.
Jika instance vdc-controller menunjukkan status terminasi berulang di EC2 konsol Amazon, ini bisa disebabkan oleh tag Rahasia yang salah. Rahasia yang dikelola oleh RES memiliki tag yang digunakan sebagai bagian dari kebijakan kontrol akses IAM yang dilampirkan ke infrastruktur EC2 instans Amazon. Jika vdc-controller sedang bersepeda dan kesalahan berikut muncul di grup CloudWatch log, penyebabnya mungkin rahasia belum ditandai dengan benar. Perhatikan bahwa rahasia perlu ditandai dengan yang berikut:
{ "res:EnvironmentName": "<envname>" # e.g. "res-demo" "res:ModuleName": "virtual-desktop-controller" }
Pesan CloudWatch log Amazon untuk kesalahan ini akan muncul mirip dengan yang berikut:
An error occurred (AccessDeniedException) when calling the GetSecretValue operation: User: arn:aws:sts::160215750999:assumed-role/<envname>-vdc-gateway-role-us-east-1/i-043f76a2677f373d0 is not authorized to perform: secretsmanager:GetSecretValue on resource: arn:aws:secretsmanager:us-east-1:160215750999:secret:Certificate-res-bi-Certs-5W9SPUXF08IB-F1sNRv because no identity-based policy allows the secretsmanager:GetSecretValue action
Periksa tag pada EC2 instance Amazon dan konfirmasikan bahwa tag tersebut cocok dengan daftar di atas.
........................
instance vdc-controller sedang bersepeda karena gagal bergabung dengan modul AD/eVDi menunjukkan Pemeriksaan Kesehatan API Gagal
Jika modul eVDi gagal pemeriksaan kesehatannya, itu akan menampilkan yang berikut di bagian Status Lingkungan.
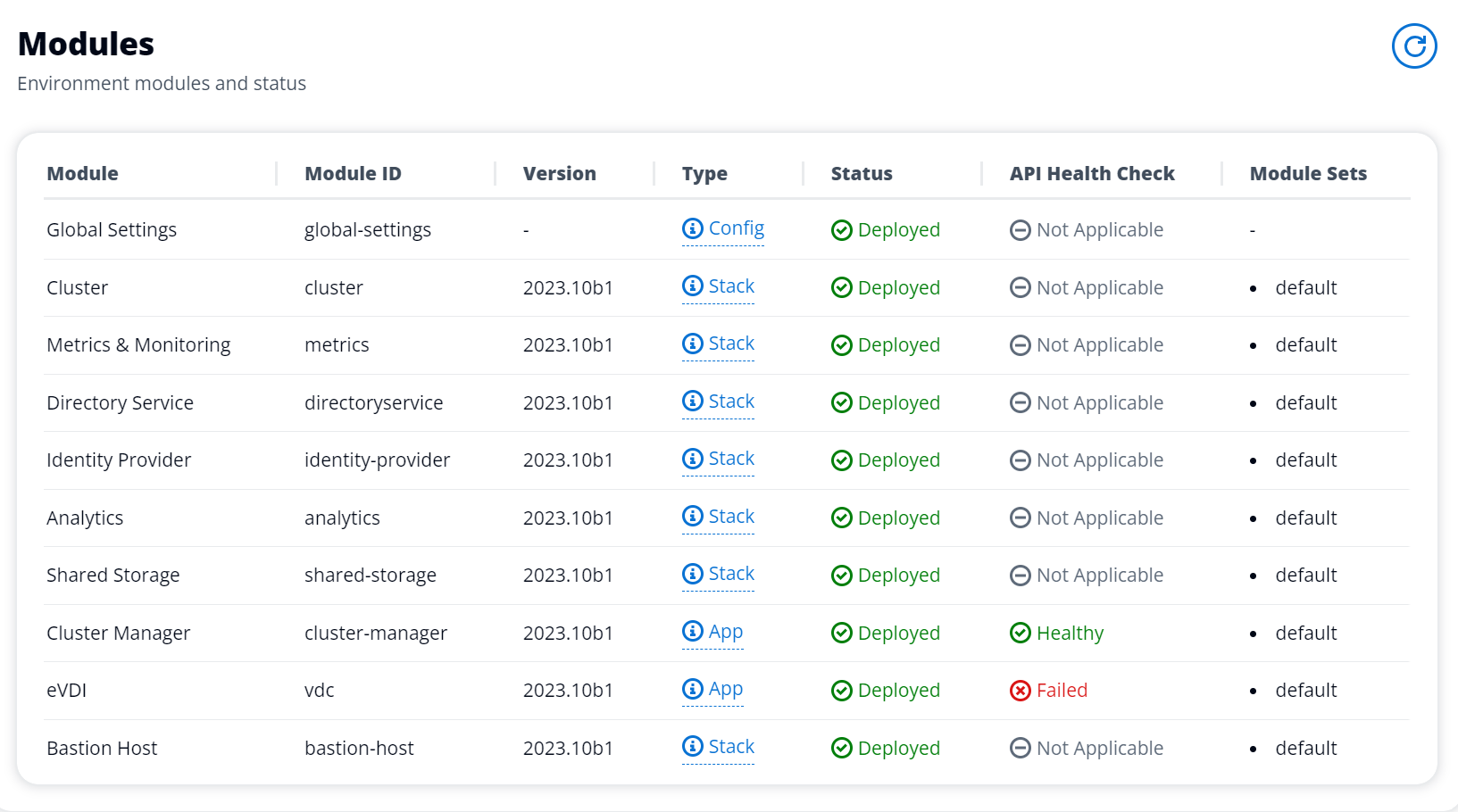
Dalam hal ini, jalur umum untuk debugging adalah dengan melihat log pengelola klaster. CloudWatch<env-name>/cluster-manager.)
Kemungkinan masalah:
-
Jika log berisi teks
Insufficient permissions, pastikan ServiceAccount nama pengguna yang diberikan saat tumpukan res dibuat dieja dengan benar.Contoh baris log:
Insufficient permissions to modify computer account: CN=IDEA-586BD25043,OU=Computers,OU=RES,OU=CORP,DC=corp,DC=res,DC=com: 000020E7: AtrErr: DSID-03153943, #1: 0: 000020E7: DSID-03153943, problem 1005 (CONSTRAINT_ATT_TYPE), data 0, Att 90008 (userAccountControl):len 4 >> 432 ms - request will be retried in 30 seconds-
Anda dapat mengakses ServiceAccount Nama Pengguna yang disediakan selama penerapan RES dari SecretsManager konsol
. Temukan rahasia yang sesuai di Manajer Rahasia dan pilih Ambil teks Biasa. Jika Nama Pengguna salah, pilih Edit untuk memperbarui nilai rahasia. Hentikan instance cluster-manager dan vdc-controller saat ini. Contoh baru akan muncul dalam keadaan stabil. -
Nama pengguna harus "ServiceAccount" jika Anda memanfaatkan sumber daya yang dibuat oleh tumpukan sumber daya eksternal yang disediakan. Jika
DisableADJoinparameter disetel ke False selama penyebaran RES Anda, pastikan pengguna "ServiceAccount" memiliki izin untuk membuat objek Komputer di AD.
-
-
Jika nama pengguna yang digunakan benar, tetapi log berisi teks
Invalid credentials, maka kata sandi yang Anda masukkan mungkin salah atau telah kedaluwarsa.Contoh baris log:
{'msgtype': 97, 'msgid': 1, 'result': 49, 'desc': 'Invalid credentials', 'ctrls': [], 'info': '80090308: LdapErr: DSID-0C090569, comment: AcceptSecurityContext error, data 532, v4563'}-
Anda dapat membaca kata sandi yang Anda masukkan selama pembuatan env dengan mengakses rahasia yang menyimpan kata sandi di konsol Secrets Manager
. Pilih rahasia (misalnya, <env_name>directoryserviceServiceAccountPassword) dan pilih Ambil teks biasa. -
Jika kata sandi dalam rahasia salah, pilih Edit untuk memperbarui nilainya dalam rahasia. Hentikan instance cluster-manager dan vdc-controller saat ini. Contoh baru akan menggunakan kata sandi yang diperbarui dan muncul dalam keadaan stabil.
-
Jika kata sandi benar, bisa jadi kata sandi telah kedaluwarsa di Direktori Aktif yang terhubung. Anda harus terlebih dahulu mengatur ulang kata sandi di Active Directory dan kemudian memperbarui rahasianya. Anda dapat mengatur ulang kata sandi pengguna di Active Directory dari konsol Directory Service
: -
Pilih ID Direktori yang sesuai
-
Pilih Tindakan, Setel ulang kata sandi pengguna lalu isi formulir dengan nama pengguna (misalnya, "ServiceAccount“) dan kata sandi baru.
-
Jika kata sandi yang baru ditetapkan berbeda dari kata sandi sebelumnya, perbarui kata sandi dalam rahasia Manajer Rahasia yang sesuai (misalnya,
<env_name>directoryserviceServiceAccountPassword. -
Hentikan instance cluster-manager dan vdc-controller saat ini. Contoh baru akan muncul dalam keadaan stabil.
-
-
........................
Proyek tidak muncul di pull down saat mengedit Software Stack untuk menambahkannya
Masalah ini mungkin terkait dengan masalah berikut yang terkait dengan sinkronisasi akun pengguna dengan AD. Jika masalah ini muncul, periksa grup log CloudWatch Amazon pengelola klaster untuk kesalahan <user-home-init> account not available yet. waiting for user to be synced "" untuk menentukan apakah penyebabnya sama atau terkait.
........................
pengelola klaster Log CloudWatch Amazon menunjukkan “user-home-init< > akun belum tersedia. menunggu pengguna untuk disinkronkan” (di mana akun adalah nama pengguna)
Pelanggan SQS sibuk dan terjebak dalam loop tak terbatas karena tidak dapat masuk ke akun pengguna. Kode ini dipicu saat mencoba membuat sistem file beranda untuk pengguna selama sinkronisasi pengguna.
Alasan mengapa tidak dapat masuk ke akun pengguna mungkin karena RES tidak dikonfigurasi dengan benar untuk AD yang digunakan. Contohnya mungkin ServiceAccountCredentialsSecretArn parameter yang digunakan pada pembuatan lingkungan BI/RES bukanlah nilai yang benar.
........................
Desktop Windows pada upaya login mengatakan “Akun Anda telah dinonaktifkan. Silakan lihat administrator Anda”
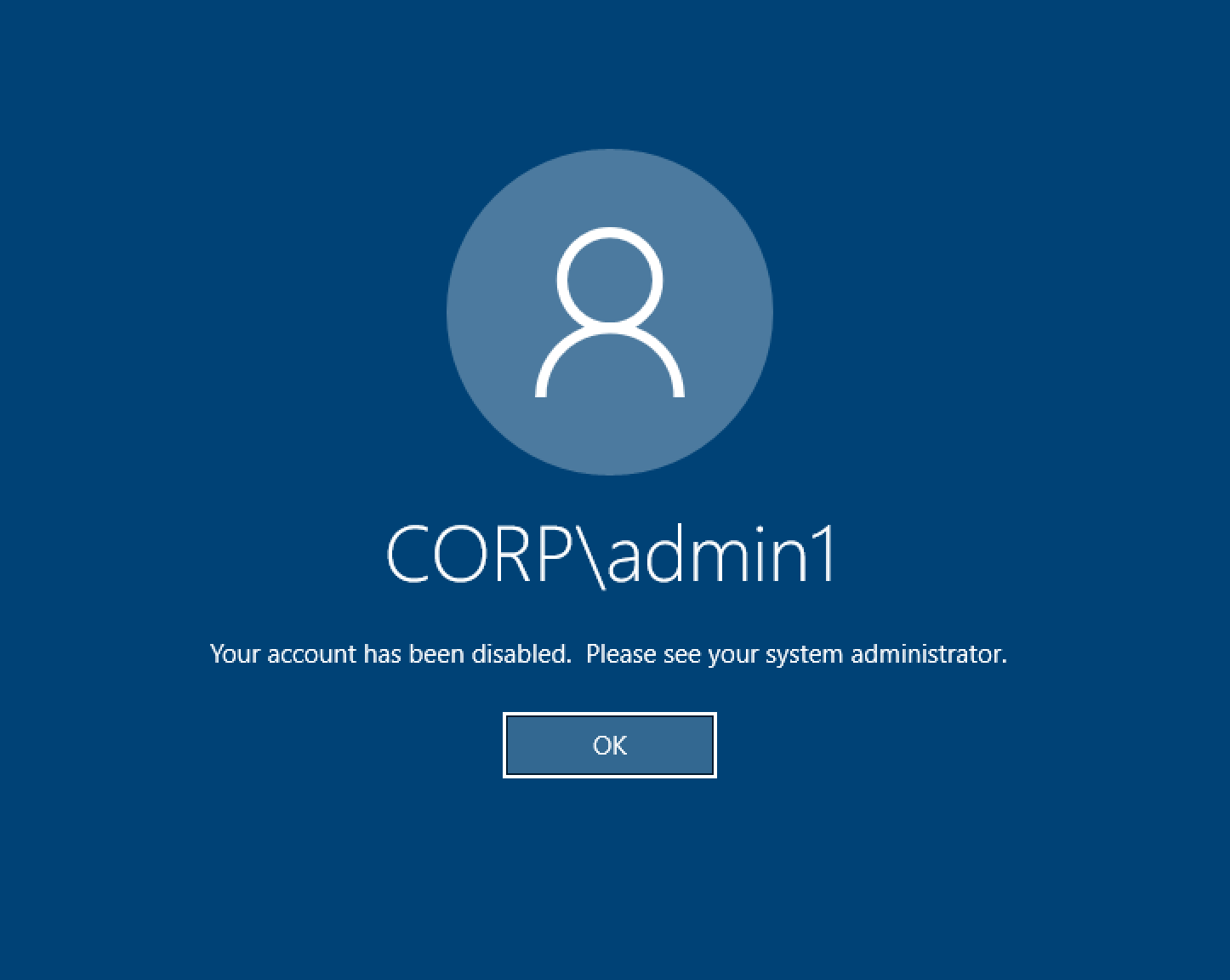
Jika pengguna tidak dapat masuk kembali ke layar yang terkunci, ini mungkin menunjukkan bahwa pengguna telah dinonaktifkan di AD yang dikonfigurasi untuk RES setelah berhasil masuk melalui SSO.
Login SSO akan gagal jika akun pengguna telah dinonaktifkan di AD.
........................
Masalah Opsi DHCP dengan konfigurasi AD eksternal/pelanggan
Jika Anda menemukan kesalahan yang menyatakan "The connection has been closed. Transport
error" dengan desktop virtual Windows saat menggunakan RES dengan Direktori Aktif Anda sendiri, periksa CloudWatch log dcv-connection-gateway Amazon untuk sesuatu yang mirip dengan yang berikut ini:
Oct 28 00:12:30.626 INFO HTTP:Splicer Connection{id=263}: Websocket{session_id="96cffa6e-cf2e-410f-9eea-6ae8478dc08a"}: Connection initiated error: unreachable, server io error Custom { kind: Uncategorized, error: "failed to lookup address information: Name or service not known" } Oct 28 00:12:30.626 WARN HTTP:Splicer Connection{id=263}: Websocket{session_id="96cffa6e-cf2e-410f-9eea-6ae8478dc08a"}: Error in websocket connection: Server unreachable: Server error: IO error: failed to lookup address information: Name or service not known Oct 28 00:12:30.627 DEBUG HTTP:Splicer Connection{id=263}: ConnectionGuard dropped
Jika Anda menggunakan pengontrol domain AD untuk Opsi DHCP untuk VPC Anda sendiri, Anda perlu:
-
Tambahkan AmazonProvided DNS ke dua pengontrol IPs domain.
-
Atur nama domain ke ec2.internal.
Sebuah contoh ditampilkan di sini. Tanpa konfigurasi ini, desktop Windows akan memberi Anda kesalahan Transport, karena RES/DCV mencari nama host ip-10-0-x-xx.ec2.internal.

........................
Kesalahan Firefox MOZILLA_PKIX_ERROR_REQUIRED_TLS_FEATURE_MISSING
Ketika Anda menggunakan browser web Firefox, Anda mungkin menemukan jenis pesan kesalahan MOZILLA_PKIX_ERROR_REQUIRED_TLS_FEATURE_MISSING ketika Anda mencoba untuk terhubung ke desktop virtual.
Anda dapat memperbaikinya dengan mengikuti petunjuk di: https://really-simple-ssl.com/mozilla_pkix_error_required_tls_feature_missing
........................
Penghapusan Env
Topik
- res-xxx-cluster tumpuk dalam status “DELETE_FAILED” dan tidak dapat dihapus secara manual karena kesalahan “Peran tidak valid atau tidak dapat diasumsikan”
- Mengumpulkan Log
- Mengunduh VDI Logs
- Mengunduh log dari EC2 instance Linux
- Mengunduh log dari EC2 instance Windows
- Mengumpulkan log ECS untuk kesalahan WaitCondition
........................
res-xxx-cluster tumpuk dalam status “DELETE_FAILED” dan tidak dapat dihapus secara manual karena kesalahan “Peran tidak valid atau tidak dapat diasumsikan”
Jika Anda melihat bahwa tumpukan "res-xxx-cluster" berada dalam status “DELETE_FAILED” dan tidak dapat dihapus secara manual, Anda dapat melakukan langkah-langkah berikut untuk menghapusnya.
Jika Anda melihat tumpukan dalam status “DELETE_FAILED”, pertama-tama coba hapus secara manual. Ini mungkin memunculkan dialog yang mengonfirmasi Hapus Tumpukan. Pilih Hapus.
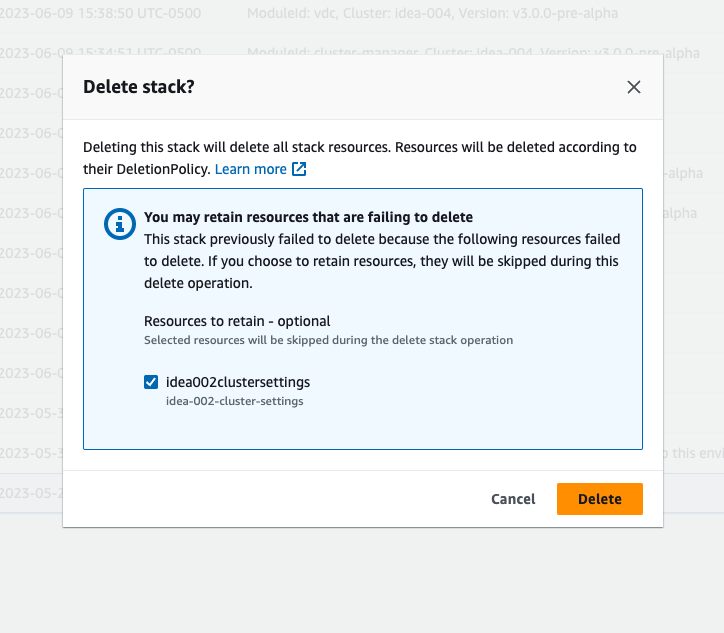
Terkadang, bahkan jika Anda menghapus semua sumber daya tumpukan yang diperlukan, Anda mungkin masih melihat pesan untuk memilih sumber daya yang akan disimpan. Dalam hal ini, pilih semua sumber daya sebagai “sumber daya untuk dipertahankan” dan pilih Hapus.
Anda mungkin melihat kesalahan yang terlihat seperti Role: arn:aws:iam::... is Invalid or cannot
be assumed
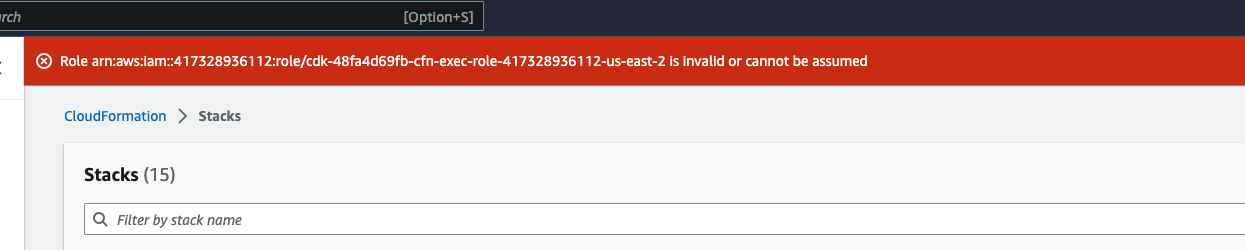
Ini berarti bahwa peran yang diperlukan untuk menghapus tumpukan dihapus terlebih dahulu sebelum tumpukan. Untuk menyiasatinya, salin nama perannya. Buka konsol IAM dan buat peran dengan nama itu menggunakan parameter seperti yang ditunjukkan di sini, yaitu:
-
Untuk jenis entitas Tepercaya pilih AWS layanan.
-
Untuk kasus Penggunaan, di bawah
Use cases for other AWS servicespilihCloudFormation.
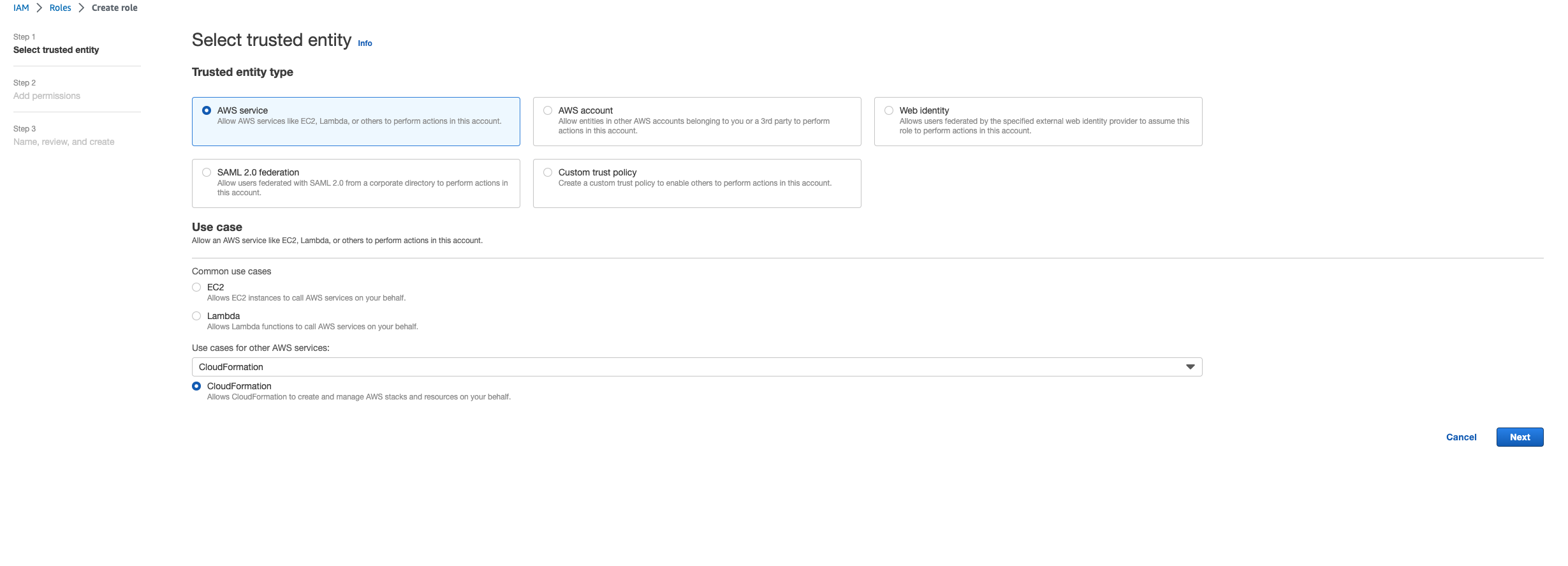
Pilih Berikutnya. Pastikan Anda memberikan izin peran 'AWSCloudFormationFullAccess' dan AdministratorAccess ''. Halaman ulasan Anda akan terlihat seperti ini:
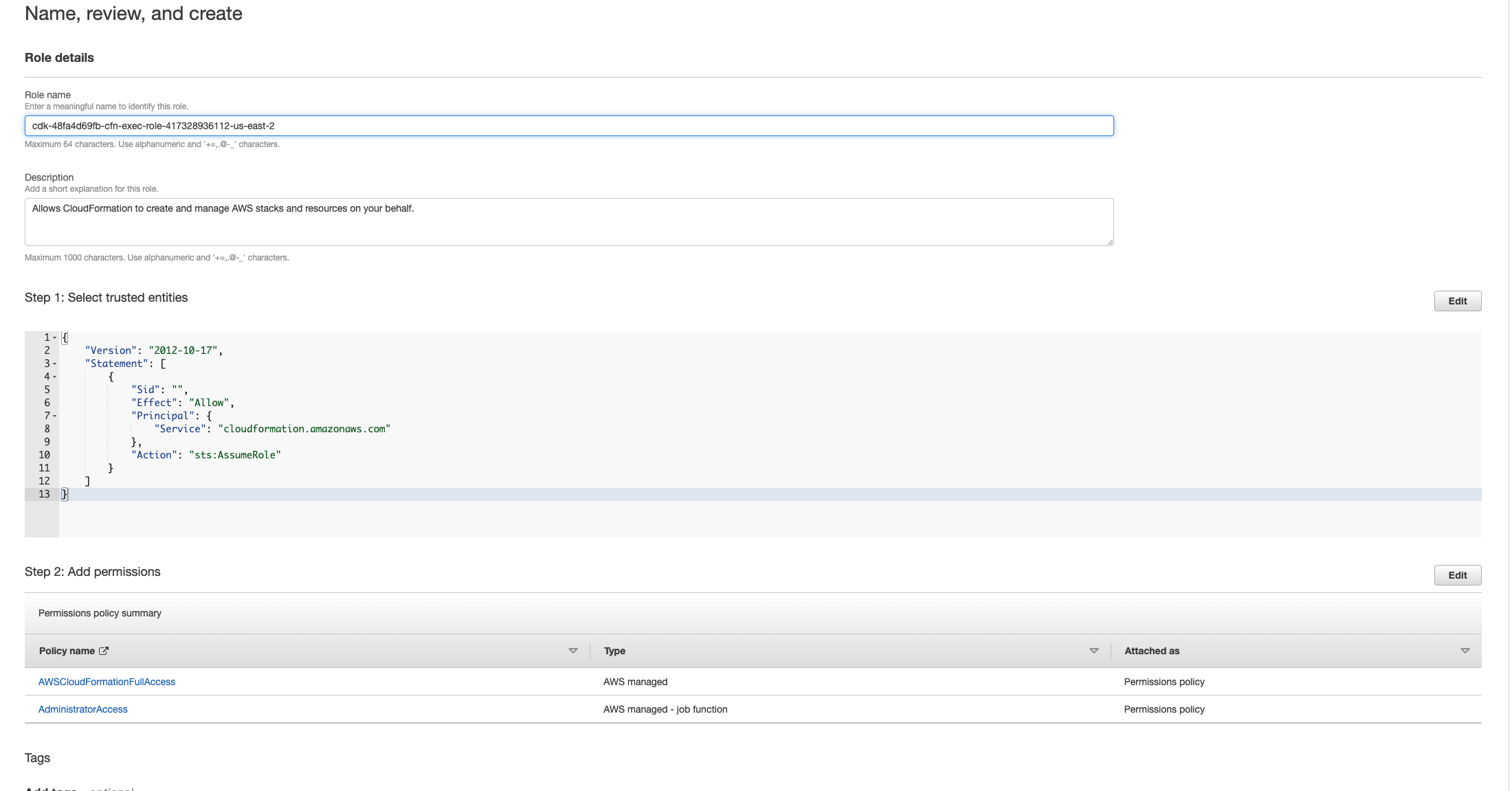
Kemudian kembali ke CloudFormation konsol dan hapus tumpukan. Anda sekarang harus dapat menghapusnya sejak Anda membuat peran. Terakhir, buka konsol IAM dan hapus peran yang Anda buat.
........................
Mengumpulkan Log
Masuk ke EC2 instance dari EC2 konsol
-
Ikuti petunjuk ini untuk masuk ke EC2 instans Linux Anda.
-
Ikuti petunjuk ini untuk masuk ke EC2 instans Windows Anda. Kemudian buka Windows PowerShell untuk menjalankan perintah apa pun.
Mengumpulkan log host Infrastruktur
-
Cluster-manager: Dapatkan log untuk pengelola klaster dari tempat-tempat berikut dan lampirkan ke tiket.
-
Semua log dari grup CloudWatch log
<env-name>/cluster-manager. -
Semua log di bawah
/root/bootstrap/logsdirektori pada<env-name>-cluster-managerEC2 instance. Ikuti petunjuk yang ditautkan dari “Masuk ke EC2 instance dari EC2 konsol” di awal bagian ini untuk masuk ke instans Anda.
-
-
VDC-controller: Dapatkan log untuk vdc-controller dari tempat-tempat berikut dan lampirkan ke tiket.
-
Semua log dari grup CloudWatch log
<env-name>/vdc-controller. -
Semua log di bawah
/root/bootstrap/logsdirektori pada<env-name>-vdc-controllerEC2 instance. Ikuti petunjuk yang ditautkan dari “Masuk ke EC2 instance dari EC2 konsol” di awal bagian ini untuk masuk ke instans Anda.
-
Salah satu cara untuk mendapatkan log dengan mudah adalah dengan mengikuti instruksi di Mengunduh log dari EC2 instance Linux bagian. Nama modul akan menjadi nama instance.
Mengumpulkan log VDI
- Identifikasi EC2 instans Amazon yang sesuai
-
Jika pengguna meluncurkan VDI dengan nama sesi
VDI1, nama instance yang sesuai di EC2 konsol Amazon adalah.<env-name>-VDI1-<user name> - Kumpulkan log VDI Linux
-
Masuk ke EC2 instans Amazon yang sesuai dari EC2 konsol Amazon dengan mengikuti instruksi yang ditautkan ke “Masuk ke EC2 instance dari EC2 konsol” di awal bagian ini. Dapatkan semua log di bawah
/var/log/dcv/direktori/root/bootstrap/logsdan pada instance VDI Amazon EC2 .Salah satu cara untuk mendapatkan log adalah dengan mengunggahnya ke s3 dan kemudian mengunduhnya dari sana. Untuk itu, Anda dapat mengikuti langkah-langkah ini untuk mendapatkan semua log dari satu direktori dan kemudian mengunggahnya:
-
Ikuti langkah-langkah ini untuk menyalin log dcv di bawah
/root/bootstrap/logsdirektori:sudo su - cd /root/bootstrap mkdir -p logs/dcv_logs cp -r /var/log/dcv/* logs/dcv_logs/ -
Sekarang, ikuti langkah-langkah yang tercantum di bagian berikutnya- Mengunduh VDI Logs untuk mengunduh log.
-
- Kumpulkan log Windows VDI
-
Masuk ke EC2 instans Amazon yang sesuai dari EC2 konsol Amazon dengan mengikuti instruksi yang ditautkan ke “Masuk ke EC2 instance dari EC2 konsol” di awal bagian ini. Dapatkan semua log di bawah
$env:SystemDrive\Users\Administrator\RES\Bootstrap\Log\direktori pada EC2 instance VDI.Salah satu cara untuk mendapatkan log adalah dengan mengunggahnya ke S3 dan kemudian mengunduhnya dari sana. Untuk melakukan itu, ikuti langkah-langkah yang tercantum di bagian berikutnya-Mengunduh VDI Logs.
........................
Mengunduh VDI Logs
Perbarui peran IAM EC2 instance VDI untuk memungkinkan akses S3.
Buka EC2 konsol dan pilih instance VDI Anda.
Pilih peran IAM yang digunakannya.
-
Di bagian Kebijakan Izin dari menu tarik-turun Tambahkan izin, pilih Lampirkan Kebijakan lalu pilih kebijakan AmazonS3. FullAccess
Pilih Tambahkan izin untuk melampirkan kebijakan tersebut.
-
Setelah itu, ikuti langkah-langkah yang tercantum di bawah ini berdasarkan jenis VDI Anda untuk mengunduh log. Nama modul akan menjadi nama instance.
-
Mengunduh log dari EC2 instance Linuxuntuk Linux.
-
Mengunduh log dari EC2 instance Windowsuntuk Windows.
-
-
Terakhir, edit peran untuk menghapus
AmazonS3FullAccesskebijakan.
catatan
Semua VDIs menggunakan peran IAM yang sama yaitu <env-name>-vdc-host-role-<region>
........................
Mengunduh log dari EC2 instance Linux
Masuk ke EC2 instance tempat Anda ingin mengunduh log dan jalankan perintah berikut untuk mengunggah semua log ke bucket s3:
sudo su - ENV_NAME=<environment_name>REGION=<region>ACCOUNT=<aws_account_number>MODULE=<module_name>cd /root/bootstrap tar -czvf ${MODULE}_logs.tar.gz logs/ --overwrite aws s3 cp ${MODULE}_logs.tar.gz s3://${ENV_NAME}-cluster-${REGION}-${ACCOUNT}/${MODULE}_logs.tar.gz
Setelah ini, buka konsol S3, pilih ember dengan nama <environment_name>-cluster-<region>-<aws_account_number> dan unduh file yang diunggah <module_name>_logs.tar.gz sebelumnya.
........................
Mengunduh log dari EC2 instance Windows
Masuk ke EC2 instance tempat Anda ingin mengunduh log dan jalankan perintah berikut untuk mengunggah semua log ke bucket S3:
$ENV_NAME="<environment_name>" $REGION="<region>" $ACCOUNT="<aws_account_number>" $MODULE="<module_name>" $logDirPath = Join-Path -Path $env:SystemDrive -ChildPath "Users\Administrator\RES\Bootstrap\Log" $zipFilePath = Join-Path -Path $env:TEMP -ChildPath "logs.zip" Remove-Item $zipFilePath Compress-Archive -Path $logDirPath -DestinationPath $zipFilePath $bucketName = "${ENV_NAME}-cluster-${REGION}-${ACCOUNT}" $keyName = "${MODULE}_logs.zip" Write-S3Object -BucketName $bucketName -Key $keyName -File $zipFilePath
Setelah ini, buka konsol S3, pilih ember dengan nama <environment_name>-cluster-<region>-<aws_account_number> dan unduh file yang diunggah <module_name>_logs.zip sebelumnya.
........................
Mengumpulkan log ECS untuk kesalahan WaitCondition
-
Buka tumpukan yang digunakan dan pilih tab Sumber Daya.
-
Perluas Deploy → ResearchAndEngineeringStudio→ Installer → Tasks → CreateTaskDef→ CreateContainer→ LogGroup, dan pilih grup log untuk membuka CloudWatch log.
-
Ambil log terbaru dari grup log ini.
........................
Lingkungan demo
Topik
........................
Kesalahan login lingkungan demo saat menangani permintaan otentikasi ke penyedia identitas
Masalah
Jika Anda mencoba masuk dan mendapatkan 'Kesalahan tak terduga saat menangani permintaan otentikasi ke penyedia identitas', kata sandi Anda mungkin kedaluwarsa. Ini bisa berupa kata sandi untuk pengguna yang Anda coba masuk sebagai atau Active Directory Service Account Anda.
Mitigasi
-
Setel ulang kata sandi akun pengguna dan layanan di konsol layanan direktori
. -
Perbarui kata sandi Akun Layanan di Secrets Manager
agar sesuai dengan kata sandi baru yang Anda masukkan di atas: -
untuk tumpukan Keycloak: PasswordSecret-... - RESExternal-... - DirectoryService-... dengan Deskripsi: Kata Sandi untuk Microsoft Active Directory
-
untuk RES: res- ServiceAccountPassword -... dengan Deskripsi: Active Directory Service Account Password
-
-
Buka EC2 konsol
dan hentikan instance cluster-manager. Aturan Auto Scaling akan secara otomatis memicu penerapan instance baru.
........................
Demo stack keycloak tidak berfungsi
Masalah
Jika server keycloak Anda mogok dan, ketika Anda memulai ulang server, IP instance berubah, ini mungkin mengakibatkan kerusakan keycloak— halaman login portal RES Anda gagal memuat atau macet dalam status pemuatan yang tidak pernah diselesaikan.
Mitigasi
Anda harus menghapus infrastruktur yang ada dan menerapkan kembali tumpukan Keycloak untuk mengembalikan Keycloak ke keadaan sehat. Ikuti langkah-langkah ini:
-
Pergi ke Cloudformation. Anda akan melihat dua tumpukan terkait keycloak di sana:
-
<env-name>-RESSsoKeycloak-<random characters><env-name>-RESSsoKeycloak-<random characters>-RESSsoKeycloak-*
-
-
Hapus Stack1. Jika diminta untuk menghapus tumpukan bersarang, pilih Ya untuk menghapus tumpukan bersarang.
Pastikan tumpukan telah dihapus sepenuhnya.
-
Terapkan tumpukan ini secara manual dengan nilai parameter yang sama persis dengan tumpukan yang dihapus. Menyebarkannya dari CloudFormation konsol dengan pergi ke Create Stack → Dengan sumber daya baru (standar) → Pilih template yang ada → Upload file template. Isi parameter yang diperlukan menggunakan input yang sama dengan tumpukan yang dihapus. Anda dapat menemukan input ini di tumpukan yang dihapus dengan mengubah filter di CloudFormation konsol dan pergi ke tab Parameter. Pastikan bahwa nama lingkungan, key pair, dan parameter lainnya cocok dengan parameter stack asli.
-
Setelah tumpukan dikerahkan, lingkungan Anda siap digunakan lagi. Anda dapat menemukan ApplicationUrl di tab Output dari tumpukan yang digunakan.
........................
