Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Terapkan model untuk inferensi waktu nyata
penting
Kebijakan IAM khusus yang memungkinkan Amazon SageMaker Studio atau Amazon SageMaker Studio Classic membuat SageMaker sumber daya Amazon juga harus memberikan izin untuk menambahkan tag ke sumber daya tersebut. Izin untuk menambahkan tag ke sumber daya diperlukan karena Studio dan Studio Classic secara otomatis menandai sumber daya apa pun yang mereka buat. Jika kebijakan IAM memungkinkan Studio dan Studio Classic membuat sumber daya tetapi tidak mengizinkan penandaan, kesalahan "AccessDenied" dapat terjadi saat mencoba membuat sumber daya. Untuk informasi selengkapnya, lihat Berikan izin untuk menandai sumber daya AI SageMaker.
AWS kebijakan terkelola untuk Amazon SageMaker AIyang memberikan izin untuk membuat SageMaker sumber daya sudah menyertakan izin untuk menambahkan tag saat membuat sumber daya tersebut.
Ada beberapa opsi untuk menerapkan model menggunakan layanan hosting SageMaker AI. Anda dapat menerapkan model secara interaktif dengan SageMaker Studio. Atau, Anda dapat menerapkan model secara terprogram menggunakan AWS SDK, seperti SDK Python atau SDK for SageMaker Python (Boto3). Anda juga dapat menerapkan dengan menggunakan. AWS CLI
Sebelum Anda mulai
Sebelum Anda menerapkan model SageMaker AI, cari dan catat hal-hal berikut:
-
Wilayah AWS Tempat bucket Amazon S3 Anda berada
-
Jalur URI Amazon S3 tempat artefak model disimpan
-
Peran IAM untuk AI SageMaker
-
Jalur registri URI ECR Docker Amazon untuk gambar kustom yang berisi kode inferensi, atau kerangka kerja dan versi gambar Docker bawaan yang didukung dan oleh AWS
Untuk daftar yang Layanan AWS tersedia di masing-masing Wilayah AWS, lihat Peta Wilayah dan Jaringan Tepi
penting
Bucket Amazon S3 tempat artefak model disimpan harus Wilayah AWS sama dengan model yang Anda buat.
Pemanfaatan sumber daya bersama dengan beberapa model
Anda dapat menerapkan satu atau beberapa model ke titik akhir dengan Amazon SageMaker AI. Ketika beberapa model berbagi titik akhir, mereka bersama-sama memanfaatkan sumber daya yang di-host di sana, seperti instance komputasi, CPU, dan akselerator. Cara paling fleksibel untuk menerapkan beberapa model ke titik akhir adalah dengan mendefinisikan setiap model sebagai komponen inferensi.
Komponen inferensi
Komponen inferensi adalah objek hosting SageMaker AI yang dapat Anda gunakan untuk menerapkan model ke titik akhir. Dalam pengaturan komponen inferensi, Anda menentukan model, titik akhir, dan bagaimana model memanfaatkan sumber daya yang dihosting titik akhir. Untuk menentukan model, Anda dapat menentukan objek Model SageMaker AI, atau Anda dapat langsung menentukan artefak model dan gambar.
Dalam pengaturan, Anda dapat mengoptimalkan pemanfaatan sumber daya dengan menyesuaikan bagaimana inti CPU, akselerator, dan memori yang diperlukan dialokasikan ke model. Anda dapat menerapkan beberapa komponen inferensi ke titik akhir, di mana setiap komponen inferensi berisi satu model dan kebutuhan pemanfaatan sumber daya untuk model itu.
Setelah menerapkan komponen inferensi, Anda dapat langsung memanggil model terkait saat menggunakan InvokeEndpoint tindakan di API. SageMaker
Komponen inferensi memberikan manfaat sebagai berikut:
- Fleksibilitas
-
Komponen inferensi memisahkan detail hosting model dari titik akhir itu sendiri. Ini memberikan lebih banyak fleksibilitas dan kontrol atas bagaimana model di-host dan disajikan dengan titik akhir. Anda dapat meng-host beberapa model pada infrastruktur yang sama, dan Anda dapat menambahkan atau menghapus model dari titik akhir sesuai kebutuhan. Anda dapat memperbarui setiap model secara independen.
- Skalabilitas
-
Anda dapat menentukan berapa banyak salinan dari setiap model untuk dihosting, dan Anda dapat mengatur jumlah minimum salinan untuk memastikan bahwa model memuat dalam jumlah yang Anda butuhkan untuk melayani permintaan. Anda dapat menskalakan salinan komponen inferensi apa pun ke nol, yang memberi ruang bagi salinan lain untuk ditingkatkan.
SageMaker AI mengemas model Anda sebagai komponen inferensi saat Anda menerapkannya dengan menggunakan:
-
SageMaker Studio Klasik.
-
SDK SageMaker Python untuk menyebarkan objek Model (tempat Anda menyetel tipe titik akhir ke).
EndpointType.INFERENCE_COMPONENT_BASED -
AWS SDK untuk Python (Boto3) Untuk mendefinisikan
InferenceComponentobjek yang Anda terapkan ke titik akhir.
Menyebarkan model dengan Studio SageMaker
Selesaikan langkah-langkah berikut untuk membuat dan menerapkan model Anda secara interaktif melalui SageMaker Studio. Untuk informasi selengkapnya tentang Studio, lihat dokumentasi Studio. Untuk penelusuran lebih lanjut tentang berbagai skenario penerapan, lihat Package blog dan terapkan model dan LLM klasik dengan mudah menggunakan Amazon
Siapkan artefak dan izin Anda
Lengkapi bagian ini sebelum membuat model di SageMaker Studio.
Anda memiliki dua opsi untuk membawa artefak Anda dan membuat model di Studio:
-
Anda dapat membawa
tar.gzarsip pra-paket, yang harus menyertakan artefak model Anda, kode inferensi kustom apa pun, dan dependensi apa pun yang tercantum dalam file.requirements.txt -
SageMaker AI dapat mengemas artefak Anda untuk Anda. Anda hanya perlu membawa artefak model mentah dan dependensi apa pun dalam sebuah
requirements.txtfile, dan SageMaker AI dapat memberikan kode inferensi default untuk Anda (atau Anda dapat mengganti kode default dengan kode inferensi kustom Anda sendiri). SageMaker AI mendukung opsi ini untuk kerangka kerja berikut: PyTorch, XGBoost.
Selain membawa model Anda, peran AWS Identity and Access Management (IAM) Anda, dan wadah Docker (atau kerangka kerja dan versi yang diinginkan yang SageMaker AI memiliki wadah pra-bangun), Anda juga harus memberikan izin untuk membuat dan menerapkan model melalui AI Studio. SageMaker
Anda harus memiliki AmazonSageMakerFullAccesskebijakan yang melekat pada peran IAM Anda sehingga Anda dapat mengakses SageMaker AI dan layanan terkait lainnya. Untuk melihat harga jenis instans di Studio, Anda juga harus melampirkan AWS PriceListServiceFullAccesskebijakan (atau jika Anda tidak ingin melampirkan seluruh kebijakan, lebih khusus lagi, pricing:GetProducts tindakan).
Jika Anda memilih untuk mengunggah artefak model saat membuat model (atau mengunggah file payload sampel untuk rekomendasi inferensi), Anda harus membuat bucket Amazon S3. Nama bucket harus diawali dengan kataSageMaker AI. Kapitalisasi alternatif SageMaker AI juga dapat diterima: Sagemaker atau. sagemaker
Kami menyarankan Anda menggunakan konvensi penamaan embersagemaker-{. Bucket ini digunakan untuk menyimpan artefak yang Anda unggah.Region}-{accountID}
Setelah membuat bucket, lampirkan kebijakan CORS (cross-origin resource sharing) berikut ke bucket:
[ { "AllowedHeaders": ["*"], "ExposeHeaders": ["Etag"], "AllowedMethods": ["PUT", "POST"], "AllowedOrigins": ['https://*.sagemaker.aws'], } ]
Anda dapat melampirkan kebijakan CORS ke bucket Amazon S3 dengan menggunakan salah satu metode berikut:
-
Melalui halaman Edit cross-origin resource sharing (CORS)
di konsol Amazon S3 -
Menggunakan Amazon S3 API PutBucketCors
-
Menggunakan perintah put-bucket-cors AWS CLI :
aws s3api put-bucket-cors --bucket="..." --cors-configuration="..."
Buat model yang dapat diterapkan
Pada langkah ini, Anda membuat versi model yang dapat diterapkan di SageMaker AI dengan menyediakan artefak Anda bersama dengan spesifikasi tambahan, seperti wadah dan kerangka kerja yang Anda inginkan, kode inferensi khusus apa pun, dan pengaturan jaringan.
Buat model deployable di SageMaker Studio dengan melakukan hal berikut:
-
Buka aplikasi SageMaker Studio.
-
Di panel navigasi kiri, pilih Model.
-
Pilih tab Model Deployable.
-
Pada halaman Model Deployable, pilih Buat.
-
Pada halaman Buat model deployable, untuk bidang Nama model, masukkan nama untuk model.
Ada beberapa bagian lagi untuk Anda isi di halaman Create deployable model.
Bagian definisi Container terlihat seperti tangkapan layar berikut:
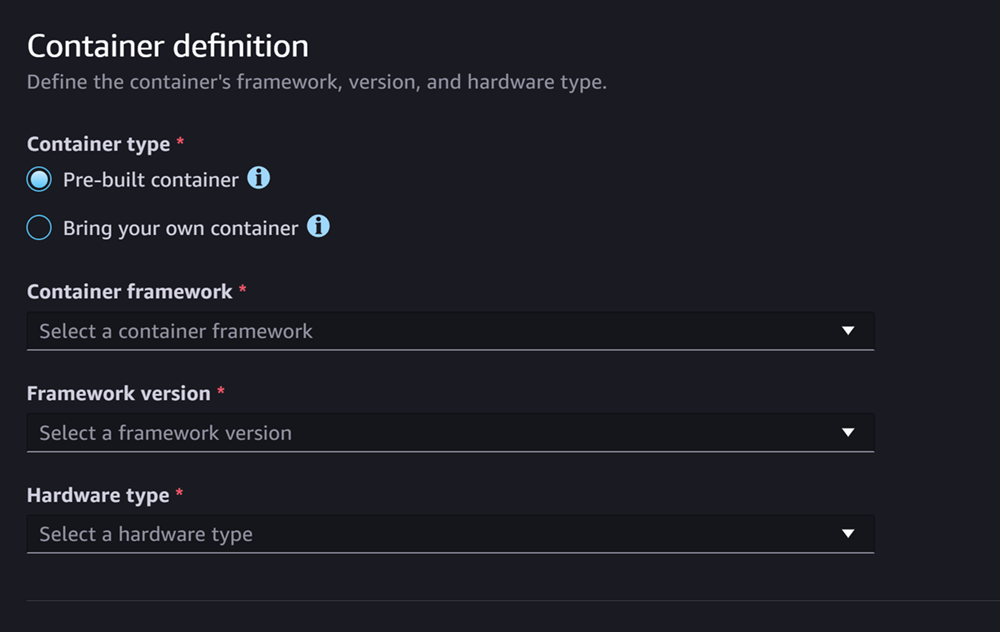
Untuk Definisi kontainer bagian, lakukan hal berikut:
-
Untuk jenis Kontainer, pilih Pre-builtkontainer jika Anda ingin menggunakan kontainer terkelola SageMaker AI, atau pilih Bawa kontainer Anda sendiri jika Anda memiliki kontainer sendiri.
-
Jika Anda memilih Pre-built container, pilih framework Container, versi Framework, dan jenis Hardware yang ingin Anda gunakan.
-
Jika Anda memilih Bawa penampung Anda sendiri, masukkan jalur ECR Amazon untuk jalur ECR ke image kontainer.
Kemudian, isi bagian Artefak, yang terlihat seperti tangkapan layar berikut:

Untuk Artifacts bagian, lakukan hal berikut:
-
Jika Anda menggunakan salah satu kerangka kerja yang didukung SageMaker AI untuk artefak model kemasan (PyTorch atau XGBoost), maka untuk Artefak, Anda dapat memilih opsi Unggah artefak. Dengan opsi ini, Anda cukup menentukan artefak model mentah Anda, kode inferensi kustom apa pun yang Anda miliki, dan file requirements.txt Anda, dan SageMaker AI menangani pengemasan arsip untuk Anda. Lakukan hal-hal berikut:
-
Untuk Artefak, pilih Unggah artefak untuk terus menyediakan file Anda. Jika tidak, jika Anda sudah memiliki
tar.gzarsip yang berisi file model, kode inferensi, danrequirements.txtfile, lalu pilih Input S3 URI ke artefak pra-paket. -
Jika Anda memilih untuk mengunggah artefak Anda, maka untuk bucket S3, masukkan jalur Amazon S3 ke ember tempat Anda SageMaker ingin AI menyimpan artefak Anda setelah mengemasnya untuk Anda. Kemudian, selesaikan langkah-langkah berikut.
-
Untuk Unggah artefak model, unggah file model Anda.
-
Untuk kode Inferensi, pilih Gunakan kode inferensi default jika Anda ingin menggunakan kode default yang disediakan SageMaker AI untuk menyajikan inferensi. Jika tidak, pilih Unggah kode inferensi yang disesuaikan untuk menggunakan kode inferensi Anda sendiri.
-
Untuk Upload requirements.txt, unggah file teks yang mencantumkan dependensi apa pun yang ingin Anda instal saat runtime.
-
-
Jika Anda tidak menggunakan kerangka kerja yang didukung SageMaker AI untuk artefak model kemasan, maka Studio menunjukkan opsi Pre-packagedartefak, dan Anda harus menyediakan semua artefak yang sudah dikemas sebagai arsip.
tar.gzLakukan hal-hal berikut:-
Untuk Pre-packaged artefak, pilih Masukan URI S3 untuk artefak model pra-paket jika
tar.gzarsip Anda sudah diunggah ke Amazon S3. Pilih Unggah artefak model pra-paket jika Anda ingin langsung mengunggah arsip Anda ke AI. SageMaker -
Jika Anda memilih URI Input S3 untuk artefak model pra-paket, masukkan jalur Amazon S3 ke arsip Anda untuk URI S3. Jika tidak, pilih dan unggah arsip dari mesin lokal Anda.
-
Bagian selanjutnya adalah Keamanan, yang terlihat seperti tangkapan layar berikut:
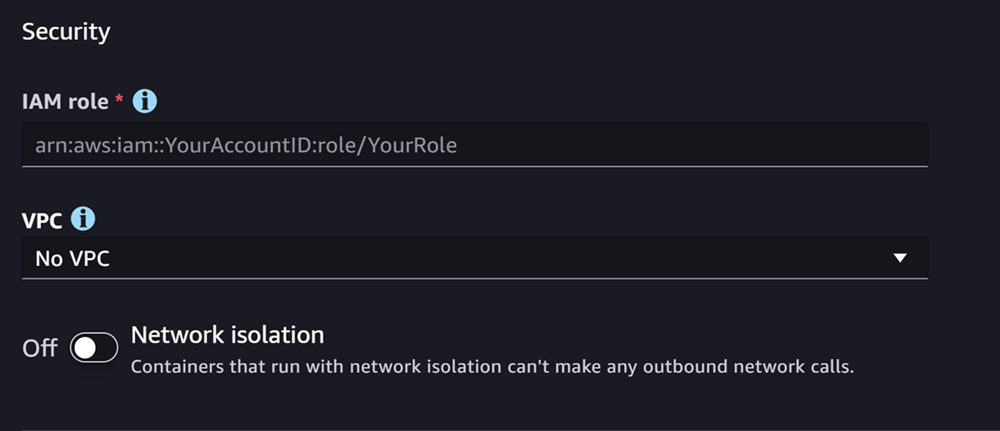
Untuk Keamanan bagian, lakukan hal berikut:
-
Untuk peran IAM, masukkan ARN untuk peran IAM.
-
(Opsional) Untuk Virtual Private Cloud (VPC), Anda dapat memilih Amazon VPC untuk menyimpan konfigurasi model dan artefak Anda.
-
(Opsional) Aktifkan sakelar Isolasi jaringan jika Anda ingin membatasi akses internet kontainer Anda.
Terakhir, Anda dapat secara opsional mengisi bagian Opsi lanjutan, yang terlihat seperti tangkapan layar berikut:
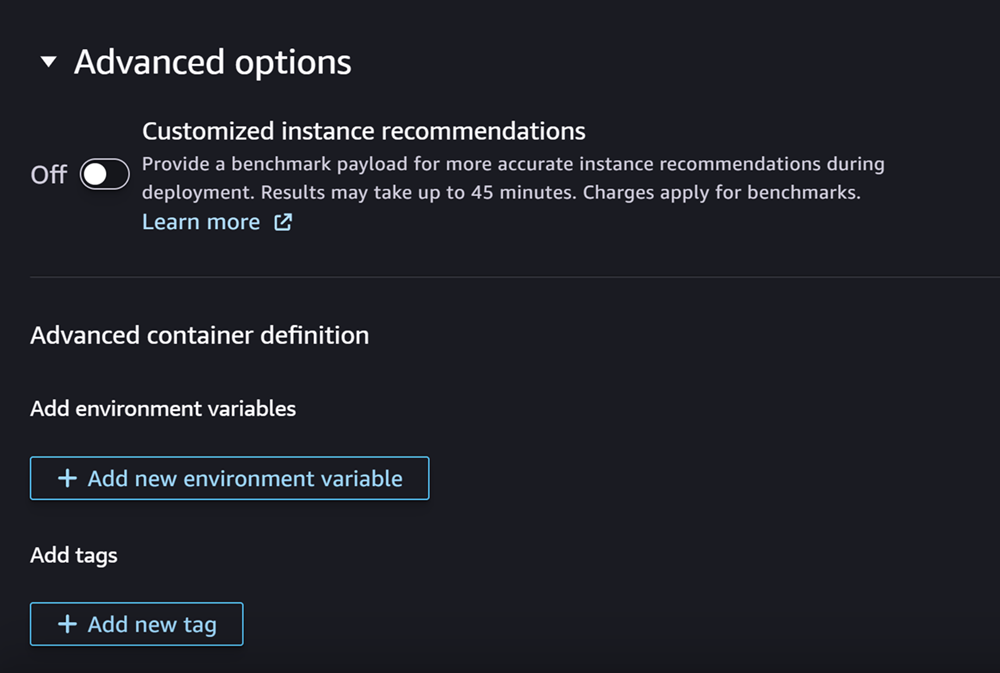
(Opsional) Untuk Opsi lanjutan bagian, lakukan hal berikut:
-
Aktifkan toggle Rekomendasi instans yang disesuaikan jika Anda ingin menjalankan pekerjaan Amazon SageMaker Inference Recommender pada model Anda setelah pembuatannya. Inference Recommender adalah fitur yang memberi Anda jenis instans yang direkomendasikan untuk mengoptimalkan kinerja dan biaya inferensi. Anda dapat melihat rekomendasi instance ini saat mempersiapkan penerapan model Anda.
-
Untuk Tambahkan variabel lingkungan, masukkan variabel lingkungan untuk wadah Anda sebagai pasangan nilai kunci.
-
Untuk Tag, masukkan tag apa pun sebagai pasangan nilai kunci.
-
Setelah menyelesaikan konfigurasi model dan kontainer Anda, pilih Create deployable model.
Anda sekarang harus memiliki model di SageMaker Studio yang siap untuk penerapan.
Terapkan model Anda
Terakhir, Anda menerapkan model yang Anda konfigurasikan pada langkah sebelumnya ke titik akhir HTTPS. Anda dapat menerapkan satu model atau beberapa model ke titik akhir.
Kompatibilitas model dan titik akhir
Sebelum Anda dapat menerapkan model ke titik akhir, model dan titik akhir harus kompatibel dengan memiliki nilai yang sama untuk pengaturan berikut:
-
Peran IAM
-
Amazon VPC, termasuk subnet dan grup keamanannya
-
Isolasi jaringan (diaktifkan atau dinonaktifkan)
Studio mencegah Anda menerapkan model ke titik akhir yang tidak kompatibel dengan cara berikut:
-
Jika Anda mencoba menerapkan model ke titik akhir baru, SageMaker AI mengonfigurasi titik akhir dengan pengaturan awal yang kompatibel. Jika Anda merusak kompatibilitas dengan mengubah pengaturan ini, Studio akan menampilkan peringatan dan mencegah penerapan Anda.
-
Jika Anda mencoba menerapkan ke titik akhir yang ada, dan titik akhir tersebut tidak kompatibel, Studio akan menampilkan peringatan dan mencegah penerapan Anda.
-
Jika Anda mencoba menambahkan beberapa model ke penerapan, Studio mencegah Anda menerapkan model yang tidak kompatibel satu sama lain.
Saat Studio menampilkan peringatan tentang ketidakcocokan model dan titik akhir, Anda dapat memilih Lihat detail di peringatan untuk melihat pengaturan mana yang tidak kompatibel.
Salah satu cara untuk menerapkan model adalah dengan melakukan hal berikut di Studio:
-
Buka aplikasi SageMaker Studio.
-
Di panel navigasi kiri, pilih Model.
-
Pada halaman Model, pilih satu atau beberapa model dari daftar model SageMaker AI.
-
Pilih Deploy.
-
Untuk nama Endpoint, buka menu dropdown. Anda dapat memilih titik akhir yang ada atau Anda dapat membuat titik akhir baru yang Anda gunakan model.
-
Untuk tipe Instance, pilih jenis instance yang ingin Anda gunakan untuk titik akhir. Jika sebelumnya Anda menjalankan tugas Inference Recommender untuk model tersebut, jenis instans yang Anda rekomendasikan akan muncul di daftar di bawah judul Recommended. Jika tidak, Anda akan melihat beberapa contoh Prospektif yang mungkin cocok untuk model Anda.
Kompatibilitas tipe instans untuk JumpStart
Jika Anda menerapkan JumpStart model, Studio hanya menampilkan tipe instance yang didukung model.
-
Untuk jumlah instans awal, masukkan jumlah awal instance yang ingin Anda berikan untuk titik akhir Anda.
-
Untuk jumlah instans Maksimum, tentukan jumlah maksimum instans yang dapat disediakan oleh titik akhir saat ditingkatkan untuk mengakomodasi peningkatan lalu lintas.
-
Jika model yang Anda terapkan adalah salah satu JumpStart LLM yang paling sering digunakan dari hub model, maka opsi Konfigurasi alternatif muncul setelah bidang jenis instance dan jumlah instance.
Untuk JumpStart LLM paling populer, AWS memiliki jenis instans pra-benchmark untuk mengoptimalkan biaya atau kinerja. Data ini dapat membantu Anda memutuskan jenis instans mana yang akan digunakan untuk menerapkan LLM Anda. Pilih Konfigurasi alternatif untuk membuka kotak dialog yang berisi data pra-benchmark. Panel terlihat seperti tangkapan layar berikut:
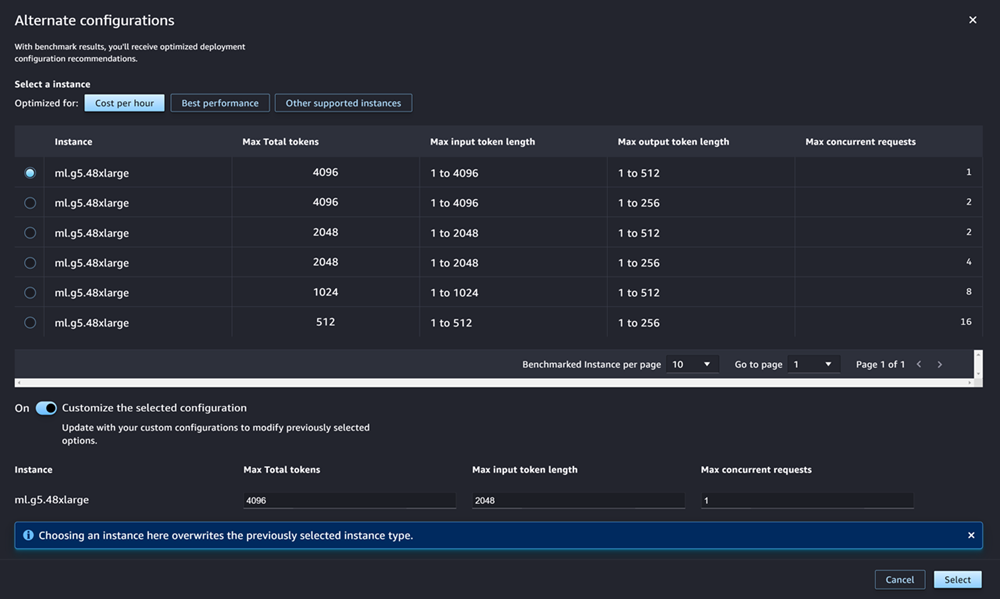
Di kotak Konfigurasi alternatif, lakukan hal berikut:
-
Pilih jenis instance. Anda dapat memilih Biaya per jam atau Kinerja terbaik untuk melihat jenis instans yang mengoptimalkan biaya atau kinerja untuk model yang ditentukan. Anda juga dapat memilih Instance lain yang didukung untuk melihat daftar jenis instans lain yang kompatibel dengan JumpStart model. Perhatikan bahwa memilih jenis instance di sini menimpa pemilihan instance sebelumnya yang ditentukan dalam Langkah 6.
-
(Opsional) Aktifkan sakelar Sesuaikan konfigurasi yang dipilih untuk menentukan total token Maks (jumlah maksimum token yang ingin Anda izinkan, yang merupakan jumlah token masukan Anda dan output yang dihasilkan model), Panjang token masukan maksimum (jumlah maksimum token yang ingin Anda izinkan untuk masukan setiap permintaan), dan Permintaan bersamaan Max (jumlah maksimum permintaan yang dapat diproses model sekaligus).
-
Pilih Pilih untuk mengonfirmasi jenis instans dan pengaturan konfigurasi Anda.
-
-
Bidang Model seharusnya sudah diisi dengan nama model atau model yang Anda gunakan. Anda dapat memilih Tambahkan model untuk menambahkan lebih banyak model ke penerapan. Untuk setiap model yang Anda tambahkan, isi kolom berikut:
-
Untuk Jumlah inti CPU, masukkan inti CPU yang ingin Anda dedikasikan untuk penggunaan model.
-
Untuk jumlah salinan Min, masukkan jumlah minimum salinan model yang ingin Anda host di titik akhir pada waktu tertentu.
-
Untuk memori CPU Min (MB), masukkan jumlah minimum memori (dalam MB) yang dibutuhkan model.
-
Untuk memori CPU Max (MB), masukkan jumlah maksimum memori (dalam MB) yang ingin Anda izinkan model untuk digunakan.
-
-
(Opsional) Untuk opsi Lanjutan, lakukan hal berikut:
-
Untuk peran IAM, gunakan peran eksekusi SageMaker AI IAM default, atau tentukan peran Anda sendiri yang memiliki izin yang Anda butuhkan. Perhatikan bahwa peran IAM ini harus sama dengan peran yang Anda tentukan saat membuat model deployable.
-
Untuk Virtual Private Cloud (VPC), Anda dapat menentukan VPC tempat Anda ingin meng-host endpoint Anda.
-
Untuk kunci Encryption KMS, pilih AWS KMS kunci untuk mengenkripsi data pada volume penyimpanan yang dilampirkan ke instance komputasi ML yang menghosting titik akhir.
-
Aktifkan sakelar Aktifkan isolasi jaringan untuk membatasi akses internet kontainer Anda.
-
Untuk konfigurasi Timeout, masukkan nilai untuk kolom batas waktu pengunduhan data Model (detik) dan batas waktu pemeriksaan kesehatan startup Container (detik). Nilai-nilai ini menentukan jumlah waktu maksimum yang memungkinkan SageMaker AI untuk mengunduh model ke wadah dan memulai wadah, masing-masing.
-
Untuk Tag, masukkan tag apa pun sebagai pasangan nilai kunci.
catatan
SageMaker AI mengonfigurasi pengaturan peran IAM, VPC, dan isolasi jaringan dengan nilai awal yang kompatibel dengan model yang Anda gunakan. Jika Anda merusak kompatibilitas dengan mengubah pengaturan ini, Studio akan menampilkan peringatan dan mencegah penerapan Anda.
-
Setelah mengonfigurasi opsi Anda, halaman akan terlihat seperti tangkapan layar berikut.
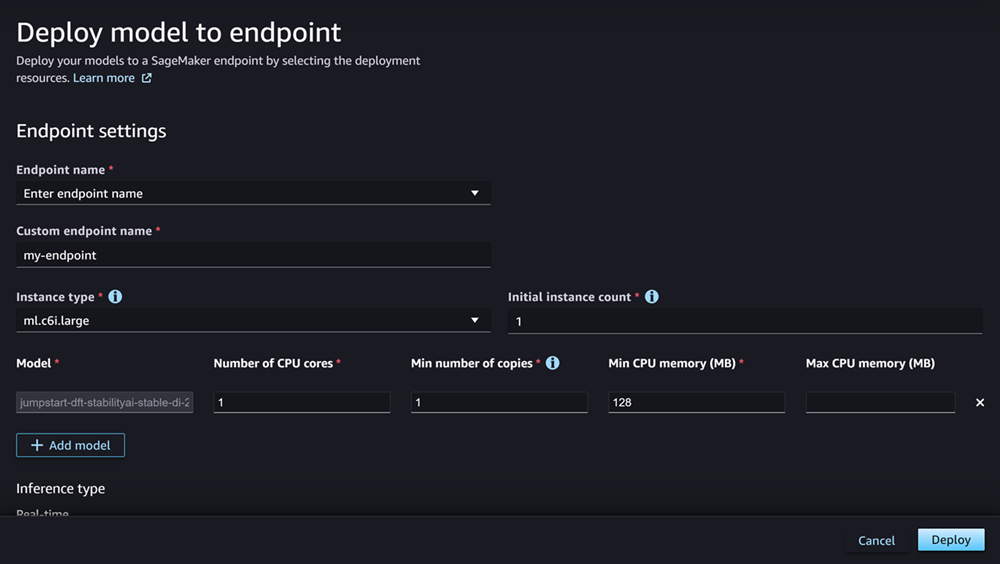
Setelah mengonfigurasi penerapan Anda, pilih Deploy untuk membuat titik akhir dan menerapkan model Anda.
Terapkan model dengan SDK Python
Menggunakan SageMaker Python SDK, Anda dapat membangun model Anda dengan dua cara. Yang pertama adalah membuat objek model dari ModelBuilder kelas Model atau. Jika Anda menggunakan Model kelas untuk membuat Model objek, Anda perlu menentukan paket model atau kode inferensi (tergantung pada server model Anda), skrip untuk menangani serialisasi dan deserialisasi data antara klien dan server, dan dependensi apa pun yang akan diunggah ke Amazon S3 untuk konsumsi. Cara kedua untuk membangun model Anda adalah dengan menggunakan ModelBuilder artefak model atau kode inferensi yang Anda berikan. ModelBuildersecara otomatis menangkap dependensi Anda, menyimpulkan fungsi serialisasi dan deserialisasi yang diperlukan, dan mengemas dependensi Anda untuk membuat objek Anda. Model Untuk informasi selengkapnya tentang ModelBuilder, lihat Buat model di Amazon SageMaker AI dengan ModelBuilder.
Bagian berikut menjelaskan kedua metode untuk membuat model Anda dan menyebarkan objek model Anda.
Penyiapan
Contoh-contoh berikut mempersiapkan proses penyebaran model. Mereka mengimpor perpustakaan yang diperlukan dan menentukan URL S3 yang menempatkan artefak model.
contoh URL artefak model
Kode berikut membangun contoh URL Amazon S3. URL menempatkan artefak model untuk model yang telah dilatih sebelumnya di bucket Amazon S3.
# Create a variable w/ the model S3 URL # The name of your S3 bucket: s3_bucket = "amzn-s3-demo-bucket" # The directory within your S3 bucket your model is stored in: bucket_prefix = "sagemaker/model/path" # The file name of your model artifact: model_filename = "my-model-artifact.tar.gz" # Relative S3 path: model_s3_key = f"{bucket_prefix}/"+model_filename # Combine bucket name, model file name, and relate S3 path to create S3 model URL: model_url = f"s3://{s3_bucket}/{model_s3_key}"
URL Amazon S3 lengkap disimpan dalam variabelmodel_url, yang digunakan dalam contoh berikut.
Ikhtisar
Ada beberapa cara Anda dapat menerapkan model dengan SageMaker Python SDK atau SDK for Python (Boto3). Bagian berikut merangkum langkah-langkah yang Anda selesaikan untuk beberapa kemungkinan pendekatan. Langkah-langkah ini ditunjukkan oleh contoh-contoh berikut.
Konfigurasi
Contoh berikut mengonfigurasi sumber daya yang Anda perlukan untuk menerapkan model ke titik akhir.
Deploy
Contoh berikut menyebarkan model ke titik akhir.
Menyebarkan model dengan AWS CLI
Anda dapat menerapkan model ke titik akhir dengan menggunakan. AWS CLI
Ikhtisar
Saat Anda menerapkan model dengan AWS CLI, Anda dapat menerapkannya dengan atau tanpa menggunakan komponen inferensi. Bagian berikut merangkum perintah yang Anda jalankan untuk kedua pendekatan. Perintah-perintah ini ditunjukkan oleh contoh-contoh berikut.
Konfigurasi
Contoh berikut mengonfigurasi sumber daya yang Anda perlukan untuk menerapkan model ke titik akhir.
Deploy
Contoh berikut menyebarkan model ke titik akhir.
